提取日誌文本中特定的字段值(導入數據庫進行處理)
2013-09-22 19:02
169 查看
原始日誌文件(文件 D:\buff.txt)內容如下:
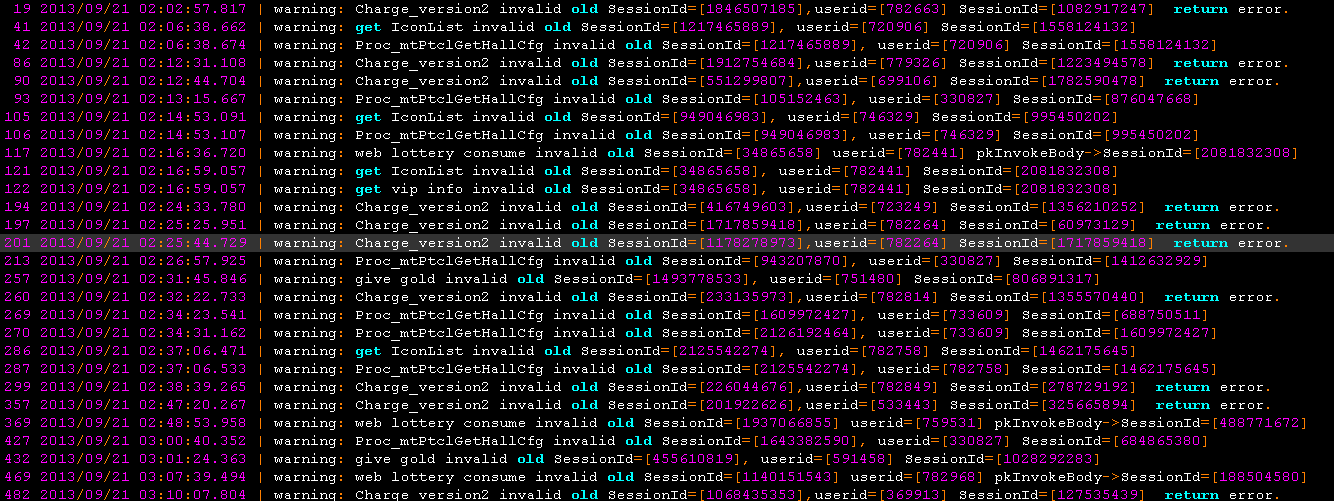
任務:提取出每行中的 Userid
第一步:導入數據庫
作為一列導入:
或作為兩列導入:
第二步:在數據庫中寫處理腳本
任務:提取出每行中的 Userid
第一步:導入數據庫
作為一列導入:
create table buff ( col1 varchar(1500) ) Bulk insert testdb.dbo.buff From 'D:\buff.txt' With ( RowTerminator = '\n' )
或作為兩列導入:
create table buff ( col1 varchar(1500), col2 varchar(1500) ) Bulk insert testdb.dbo.buff From 'D:\buff.txt' With ( FieldTerminator= '|', RowTerminator = '\n' ) -- 或 xp_cmdShell 'bcp testdb.dbo.buff in D:\buff.txt -c -t"|" -T'
第二步:在數據庫中寫處理腳本
select
col2,
substring(
col2,
charindex('userid',col2)+8,
charindex(']',col2,charindex(']',col2)+ 1) - charindex('userid=[',col2)-8
) userid
from buff

相关文章推荐
- 统计文本中的特定字段的信息
- 【教程】PDF开发工具Spire.PDF 教程:使用C#从PDF中的特定矩形区域中提取文本
- 从文本中提取特定信息
- [置顶] AS插件开发:根据特定格式的文本自动生成Java Bean文件或字段
- 文本有很多行,已知某行里面含有某特定字符,怎样提取出某行
- SQL MID()(文本字段中提取字符)
- JS提取网页中表格内容,将特定列内的html文本中id,href,onclick属性提取出来
- wireshark提取保存部分报文特定字段之tshark
- 获得sas程序的名称,及提取包含特定字段的行 Get then names of some programs and get rows which contain specify fields
- 截取文本里特定连续字段并去掉多余空格
- wireshark提取保存部分报文特定字段之tshark
- PDF开发工具Spire.PDF 教程:使用C#从PDF中的特定矩形区域中提取文本
- 简单的将一个html(xml)文本中的img标签(图片)提取出来的方法
- 查询整个数据库中某个特定值所在的表和字段的方法
- cut 命令 通过列来提取文本字符
- 用 python 进行文本预处理和提取特征
- 关于C/C++的txt文本文件提取问题
- PB 数据窗口DW处理图片等大文本字段
- 使用python提取html文件中的特定数据的实现代码
- 使用代码动态设置水晶报表中的文本,字段等对象