WEBUS2.0 In Action - 开始搜索 [代码示例]
2013-09-07 18:18
176 查看
上一篇:WEBUS2.0 In Action - 编制索引 |
下一篇:WEBUS2.0 In Action - 解析索引文件结构(1)
当索引建好之后,要利用WEBUS2.0实现基本搜索功能,至少需要用到如下几个类和接口:
Webus.Index.IQueriable (接口)
Webus.Index.IndexManager (类,实现IQueriable)
Webus.Analysis.IAnalyzer (接口)
Webus.Analysis.MyWordAnalyzer (类,实现IAnalyzer)
Webus.Search.ISearcher (接口)
Webus.Search.IndexSearcher (类,实现ISearcher)
Webus.Search.Query (类,用于构造搜索表达式)
下面我用一个文件搜索的小例程来说明如何开发搜索功能:
FileSearcher.exe
× 首先选择要编制索引的文件(文本文件,源代码等等皆可):
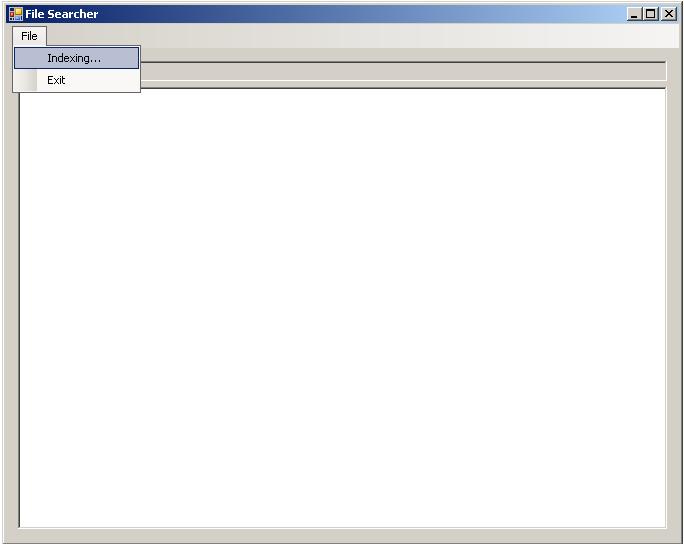
× 直接输入关键词(多个关键词用空格区分)进行搜索:
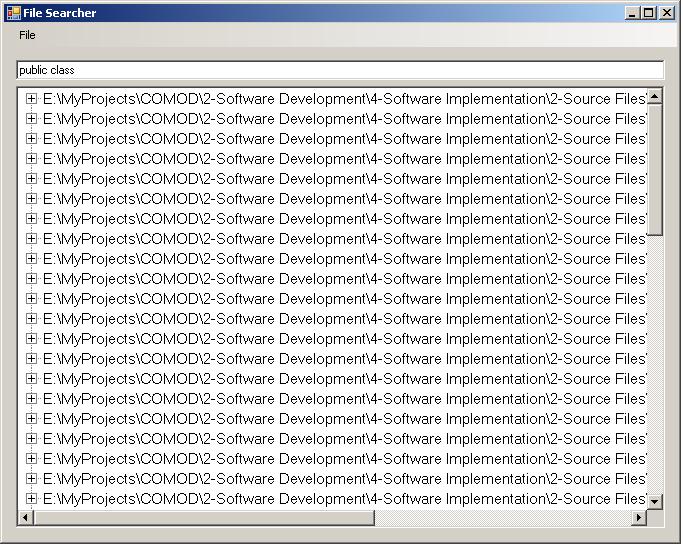
要实现如上功能其实很简单,首先我们要声明几个需要用到的对象:

IIndexer writer; //索引writer
ISearcher searcher; //搜索器
并在窗体构造函数中构造它们:
public frmMain()



{

InitializeComponent();
writer = new IndexManager(new MyWordAnalyzer());
searcher = new IndexSearcher(writer);

}
注意这里使用了SimpleWordAnalyzer去构造writer,这是因为WEBUS在编制索引时需要将文件内容分切成多个语汇单元(token)再对每个语汇单元编制索引。利用不同的分析器(Analyzer)可以分切出不同的语汇单元,从而实现各种各样的分析效果。我们这里使用的最简单的内置分析器SimpleWordAnalyzer,它会将英文分割成单词,将中文分割成字,并将所有语汇单元转换成小写形式。
当对象构造完成之后,我们读取选定的文件内容并将其添加到索引中:
writer.New(indexPath);
foreach (string file in openFileDialog1.FileNames)
{
using (StreamReader sr = new StreamReader(file))


{
Document doc = new Document();
doc.Fields.Add(new Field("FileName", file));
doc.Fields.Add(new Field("Content", sr.ReadToEnd(),
FieldAttributes.Analyse | FieldAttributes.Index | FieldAttributes.Compress));
writer.Add(doc);

}
}
writer.Close();
对于FileName字段,我们采用Default(Default=Index|Sort)的方式编制索引;对于Content字段,我们需要首先分析(Analyse)然后编制索引(Index)并且要压缩保存(Compress)。
当索引编制完成之后,我们需要关闭writer(writer.Close())才能够用reader读取它:
writer.Open(indexPath, IndexOpenMode.Read);
OK,一切就绪,现在我们来为TextBox控件的TextChanged事件添加搜索代码,如此一来就可以实现一输入关键词立马显示相关搜索结果的功能:
//用空格分割用户输入的关键词
tvResult.Nodes.Clear();
char[] keys = txtKeyword.Text.ToCharArray();
//构造一个 "key1 AND key2 AND key3
" 类型的Query
Query query = null;
foreach (char key in keys)
{
Query q = new TermQuery(new Term("Content", key.ToString()));
if (query == null)
{
query = q;
}
else
{
query &= q; //用"&"
(AND)操作符对两个Query进行计算,结果为一个新的Query对象
}
}
Hits hits = searcher.Search(query);//搜索
这里需要注意的是Query的运算。目前在WEBUS中有7种Query:
TermQuery 基本Term搜索
PrefixQuery 前缀搜索
PostfixQuery 后缀搜索
WildcardQuery 通配符搜索
RegexQuery 正则表达式搜索
RangeQuery 范围搜索
BooleanQuery 布尔搜索
它们之间可以支持如下运算符:
+ - ! & |
其中 !a 就是非 a 的意思;
a + b 就是 a AND b 的意思;
a - b 就是 a AND !b 的意思;
a | b 就是 a OR b 的意思;
& 和 + 是相同的效果。
任何两个Query之间通过运算之后的结果都将是一个BooleanQuery对象,通过这种方式,我们可以实现十分复杂的搜索效果!
到此为止,绝大部分代码我们已经完成了,只需要将搜索结果显示出来这个程序就OK了:
for (int i = 0; i < hits.Count; i++)
{
Document doc = hits.GetDoc(i);
//获取Document对象
TreeNode node = tvResult.Nodes.Add([b]doc.GetField("FileName").Value.ToString()[/b]);
//从Doc中获取FileName字段的值
string content = doc.GetField("Content").Value.ToString();
//获取Content字段的值
foreach (Position pos in hits[i].Positions)
{
int h = content.LastIndexOf("
", pos.Start);
int t = content.IndexOf("
", pos.Start + pos.Length);
h = h >= 0 ? h : 0;
int l = t - h;
l = l >= 0 ? l : 0;
node.Nodes.Add(string.Format("[Position: {0}] {1}", pos.Start, content.Substring(h, l).Trim()));
}
}
完整代码下载:FileSearch c# .Net4.0
相关信息及WEBUS2.0 SDK下载:继续我的代码,分享我的快乐 - WEBUS2.0
下一篇:WEBUS2.0 In Action - 解析索引文件结构(1)
当索引建好之后,要利用WEBUS2.0实现基本搜索功能,至少需要用到如下几个类和接口:
Webus.Index.IQueriable (接口)
Webus.Index.IndexManager (类,实现IQueriable)
Webus.Analysis.IAnalyzer (接口)
Webus.Analysis.MyWordAnalyzer (类,实现IAnalyzer)
Webus.Search.ISearcher (接口)
Webus.Search.IndexSearcher (类,实现ISearcher)
Webus.Search.Query (类,用于构造搜索表达式)
下面我用一个文件搜索的小例程来说明如何开发搜索功能:
FileSearcher.exe
× 首先选择要编制索引的文件(文本文件,源代码等等皆可):
× 直接输入关键词(多个关键词用空格区分)进行搜索:
要实现如上功能其实很简单,首先我们要声明几个需要用到的对象:
IIndexer writer; //索引writer
ISearcher searcher; //搜索器
并在窗体构造函数中构造它们:
public frmMain()
{
InitializeComponent();
writer = new IndexManager(new MyWordAnalyzer());
searcher = new IndexSearcher(writer);
}
注意这里使用了SimpleWordAnalyzer去构造writer,这是因为WEBUS在编制索引时需要将文件内容分切成多个语汇单元(token)再对每个语汇单元编制索引。利用不同的分析器(Analyzer)可以分切出不同的语汇单元,从而实现各种各样的分析效果。我们这里使用的最简单的内置分析器SimpleWordAnalyzer,它会将英文分割成单词,将中文分割成字,并将所有语汇单元转换成小写形式。
当对象构造完成之后,我们读取选定的文件内容并将其添加到索引中:
writer.New(indexPath);
foreach (string file in openFileDialog1.FileNames)
{
using (StreamReader sr = new StreamReader(file))
{
Document doc = new Document();
doc.Fields.Add(new Field("FileName", file));
doc.Fields.Add(new Field("Content", sr.ReadToEnd(),
FieldAttributes.Analyse | FieldAttributes.Index | FieldAttributes.Compress));
writer.Add(doc);
}
}
writer.Close();
对于FileName字段,我们采用Default(Default=Index|Sort)的方式编制索引;对于Content字段,我们需要首先分析(Analyse)然后编制索引(Index)并且要压缩保存(Compress)。
当索引编制完成之后,我们需要关闭writer(writer.Close())才能够用reader读取它:
writer.Open(indexPath, IndexOpenMode.Read);
OK,一切就绪,现在我们来为TextBox控件的TextChanged事件添加搜索代码,如此一来就可以实现一输入关键词立马显示相关搜索结果的功能:
//用空格分割用户输入的关键词
tvResult.Nodes.Clear();
char[] keys = txtKeyword.Text.ToCharArray();
//构造一个 "key1 AND key2 AND key3
" 类型的Query
Query query = null;
foreach (char key in keys)
{
Query q = new TermQuery(new Term("Content", key.ToString()));
if (query == null)
{
query = q;
}
else
{
query &= q; //用"&"
(AND)操作符对两个Query进行计算,结果为一个新的Query对象
}
}
Hits hits = searcher.Search(query);//搜索
这里需要注意的是Query的运算。目前在WEBUS中有7种Query:
TermQuery 基本Term搜索
PrefixQuery 前缀搜索
PostfixQuery 后缀搜索
WildcardQuery 通配符搜索
RegexQuery 正则表达式搜索
RangeQuery 范围搜索
BooleanQuery 布尔搜索
它们之间可以支持如下运算符:
+ - ! & |
其中 !a 就是非 a 的意思;
a + b 就是 a AND b 的意思;
a - b 就是 a AND !b 的意思;
a | b 就是 a OR b 的意思;
& 和 + 是相同的效果。
任何两个Query之间通过运算之后的结果都将是一个BooleanQuery对象,通过这种方式,我们可以实现十分复杂的搜索效果!
到此为止,绝大部分代码我们已经完成了,只需要将搜索结果显示出来这个程序就OK了:
for (int i = 0; i < hits.Count; i++)
{
Document doc = hits.GetDoc(i);
//获取Document对象
TreeNode node = tvResult.Nodes.Add([b]doc.GetField("FileName").Value.ToString()[/b]);
//从Doc中获取FileName字段的值
string content = doc.GetField("Content").Value.ToString();
//获取Content字段的值
foreach (Position pos in hits[i].Positions)
{
int h = content.LastIndexOf("
", pos.Start);
int t = content.IndexOf("
", pos.Start + pos.Length);
h = h >= 0 ? h : 0;
int l = t - h;
l = l >= 0 ? l : 0;
node.Nodes.Add(string.Format("[Position: {0}] {1}", pos.Start, content.Substring(h, l).Trim()));
}
}
完整代码下载:FileSearch c# .Net4.0
相关信息及WEBUS2.0 SDK下载:继续我的代码,分享我的快乐 - WEBUS2.0

相关文章推荐
- WEBUS2.0 In Action - 开始搜索 [代码示例]
- WEBUS2.0 In Action - 开始搜索 [代码示例]
- WEBUS2.0 In Action - 搜索操作指南 - (2)
- WEBUS2.0 In Action - 搜索操作指南 - (3)
- WEBUS2.0 In Action - 搜索操作指南 - (3)
- WEBUS2.0 In Action - 搜索操作指南 - (4)
- WEBUS2.0 In Action - 搜索操作指南 - (2)
- WEBUS2.0 In Action - [源代码] - C#代码搜索器
- WEBUS2.0 In Action - 搜索操作指南 - (1)
- WEBUS2.0 In Action - [源代码] - C#代码搜索器
- WEBUS2.0 In Action - 搜索操作指南 - (4)
- WEBUS2.0 In Action - [源代码] - C#代码搜索器
- WEBUS2.0 In Action - 搜索操作指南 - (1)
- Ajax 实现在WebForm中拖动控件并即时在服务端保存状态数据 (Asp.net 2.0)(示例代码下载)
- AjaxPro.NET框架生成高效率的Tree(Asp.net 2.0)(示例代码下载)
- 发布:Visual Studio 2010 一站式示例代码搜索扩展
- Asp.net 2.0 自定义控件开发专题[详细探讨页面状态(视图状态和控件状态)机制及其使用场景](示例代码下载)
- AjaxPro.NET框架生成高效率的Tree(Asp.net 2.0)(示例代码下载)
- AjaxPro.NET完成TextBox智能获取服务端数据功能(Asp.net 2.0)(示例代码下载)
- Asp.net 2.0 自定义控件开发[创建自定义浮动菜单FloadMenu控件][示例代码下载]