大规模网页去重系统的简单设计和实现
2013-08-26 23:01
323 查看
网页去重算法应用到了很多领域,例如:spam,推荐系统等,目前工作中需要用到网页的去重算法,量级大概是每天60W左右,但是由于是线上的系统,对系统能快速查找重复文章的性能要求较高,这里简单记下我们的思路和方法。
算法调研:其实网页去重算法本质上都是提取网页的特征集合,然后根据这些特征来计算网页的相似度,我们主要调研了以下两种方法:
1.yahoo的shingle算法:来源于yahoo的一篇论文,算法主要是将文档计算成m个64bit整数,计算两篇文档中相同的整数的个数b,一般b=1的时候两篇文档就非常相似了。利用此算法构建的去重系统计算效率较低,1s可以计算300篇作用的文档,但是查重的效率很高,评估的准确率在98%左右。
2.google的SImHash算法:之前找工作面试的时候看过这个算法,算法大概是:首先将文档转成特征的集合,并且特征都有一定的权重,然后利用lsh算法将特征转换为m位的fingerprint,最后计算每一个fingerprint的海明距离,一般m为64.这个算法计算fingerprint的效率很快,可以达到1的10倍以上,但是查询的效率很低,并且准确率不如1
以上两种算法都需要对网页进行预处理,比如去除html标签,去除标点符号等,比较短的内容效果会比较差,建议采用MD5算法替代,1算法中正文理想中的长度大于66Bytes效果不错。
系统设计:
处理能力:算法计算效率:300~400篇文档/s,内存占用:1000W篇文档占用内存约500M,系统会定期的将比较老的数据清除,查询基本能满足线上的需求。
系统框架:
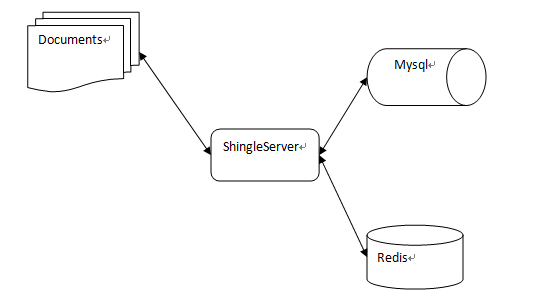
系统组成:
ShingleServer主要计算文档的shingles,并查询Redis,如果Redis中没有,将该文档的shingles写入Redis和和Mysql,如果有重复,返回重复的文档。
Redis主要用来存储文档的shingles,之所以采用Redis,可以利用其单线程的优势,省去加锁等控制的麻烦,而且redis的数据结构很适合查找运算。
Mysql主要用于作为Redis的备份,当Redis挂了,可以从Mysql中读取历史数据进行恢复。
需要注意的地方:对Mysql的读操作需要加锁,防止Redis挂了对Mysql数据库的负载忽然增大。
思考:去重算法中很多都是提取特征和将特征进行数值化的,1中主要考虑了词之间的顺序,并没有考虑词频等信息,之前面试的时候有问到如何计算字符串的相似度,想到这样一种方法不知道可不可行?比如:abcdef 可以利用n-gram生成该文章的(1-4)gram作为该文章的特征,然后将对这些特征计算fingerprint,之后利用这些fingerprint来计算文章的相似读,这个方法跟1比较类似,也主要考虑了词的顺序问题,4的长度是从一篇文献中看到的,是n-gram效果还可以的上限值,有机会可以试试这个算法。
算法调研:其实网页去重算法本质上都是提取网页的特征集合,然后根据这些特征来计算网页的相似度,我们主要调研了以下两种方法:
1.yahoo的shingle算法:来源于yahoo的一篇论文,算法主要是将文档计算成m个64bit整数,计算两篇文档中相同的整数的个数b,一般b=1的时候两篇文档就非常相似了。利用此算法构建的去重系统计算效率较低,1s可以计算300篇作用的文档,但是查重的效率很高,评估的准确率在98%左右。
2.google的SImHash算法:之前找工作面试的时候看过这个算法,算法大概是:首先将文档转成特征的集合,并且特征都有一定的权重,然后利用lsh算法将特征转换为m位的fingerprint,最后计算每一个fingerprint的海明距离,一般m为64.这个算法计算fingerprint的效率很快,可以达到1的10倍以上,但是查询的效率很低,并且准确率不如1
以上两种算法都需要对网页进行预处理,比如去除html标签,去除标点符号等,比较短的内容效果会比较差,建议采用MD5算法替代,1算法中正文理想中的长度大于66Bytes效果不错。
系统设计:
处理能力:算法计算效率:300~400篇文档/s,内存占用:1000W篇文档占用内存约500M,系统会定期的将比较老的数据清除,查询基本能满足线上的需求。
系统框架:
系统组成:
ShingleServer主要计算文档的shingles,并查询Redis,如果Redis中没有,将该文档的shingles写入Redis和和Mysql,如果有重复,返回重复的文档。
Redis主要用来存储文档的shingles,之所以采用Redis,可以利用其单线程的优势,省去加锁等控制的麻烦,而且redis的数据结构很适合查找运算。
Mysql主要用于作为Redis的备份,当Redis挂了,可以从Mysql中读取历史数据进行恢复。
需要注意的地方:对Mysql的读操作需要加锁,防止Redis挂了对Mysql数据库的负载忽然增大。
思考:去重算法中很多都是提取特征和将特征进行数值化的,1中主要考虑了词之间的顺序,并没有考虑词频等信息,之前面试的时候有问到如何计算字符串的相似度,想到这样一种方法不知道可不可行?比如:abcdef 可以利用n-gram生成该文章的(1-4)gram作为该文章的特征,然后将对这些特征计算fingerprint,之后利用这些fingerprint来计算文章的相似读,这个方法跟1比较类似,也主要考虑了词的顺序问题,4的长度是从一篇文献中看到的,是n-gram效果还可以的上限值,有机会可以试试这个算法。

相关文章推荐
- 网页设计,本页面内左侧菜单导航右侧显示内容简单实现方法
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- python实现一个简单的图书馆借阅系统(不涉及数据库和界面设计)
- 简单测控系统的设计与实现
- ICE笔记(06):简单文件系统的设计、实现
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- 简单旅游景点咨询系统的设计与实现
- 20155322 2017-2018-1《信息安全系统设计》第九周 Linux命令:pwd命令学习与简单实现
- 简单哈夫曼 编/译码系统的设计与实现
- 一个简单仓库管理系统的设计与实现--需求篇
- Linux下一个简单的日志系统的设计及其C代码实现
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- red5+adobe flash media live(或OBS) +酷播播放器实现简单的直播及回看(三)------简单分析直播及回放系统的设计
- 杭州电子科技大学操作系统课程设计:简单文件系统的实现
- 设计与实现简单而经常使用的权限系统(四):无需维护level,递归构建树
- 简单虚拟文件系统的设计与实现
- 用C#实现一个简单的图书管理系统(课程设计)
- 操作系统课程设计(二)简单文件系统实现
- 简单的asp.net模拟邮箱系统基础实现(一 总体功能版块的设计,与简单数据库的设计)
- 用JSP+Servlet+JavaBean模式实现一个简单的登录网页设计(JSP+Tomcat+MySQL)