论文读书笔记-TAO:Facebook’s distributed data store for social graph
2013-08-05 15:49
429 查看
说明:本文主要介绍了Facebook的分布式数据存储框架,作为全球最大的社交网站,facebook提出了处理社交图谱的一个简单的数据模型和API,TAO就是依据这种模型实现的地理上分布式的数据存储。
本文要点如下:
1、TAO’s goal:针对大量数据读取进行优化,和一致性相比更注重效率和可用性
2、Data model:facebook中直接针对现实中的物体进行建模,其社交图谱包括用户、他们之间的联系、他们的行动、物理地址等等,下图为一个例子:
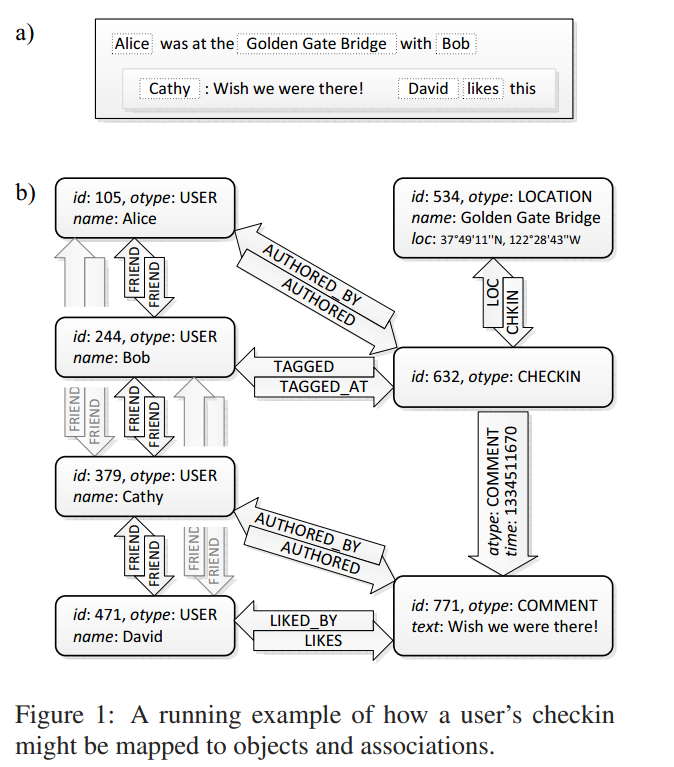
3、TAO objects为具有类型的节点,TAO associations为objects直接具有类型的有向边。Objects都是以一个全局唯一的64位的整型标识,association以source object,association type,destination object构成的三元组标识,在两个objects之间最多只能存在一种association,objects和association其中都可能包含键值对。
Object:(id)->(otype,(key->value)*)
Assoc.:(id1,atype,id2)->(time,(key->value)*)
注意,由于关系是相对的,association一般都包含一条回边
4、object API:包括分配一个新的object和id,检索,更新,删除object和id
5、Association API:TAO在处理联系时能同步更新其逆关系(反映在图上为一条回边)
Assoc_add(id1,atype,id2,time,(k->v)*):插入或者改写联系(id1,atype,id2),同时更新(id1,inv(atype),id2)
Assoc_delete(id1,atype,id2):删除联系(id1,atype,id2),逆关系也被删除
Assoc_change_type(id1,atype,id2,newtype):改变联系(id1,atype,id2)为(id1,newtype,id2)
6、association query API:社交图谱的一个特点是很多数据都是过时的旧数据,查询主要针对的是最新的数据子集,我们定义一个针对id1和atype的association list按照时间降序排列:
Association list:(id1,atype)->[anew...aold]
TAO针对association list的查询有下面这些函数:
Assoc_get(id1,atype,id2set,high?,low?):返回所有(id1,atype,id2)和该联系的时间和数据,其中id2∈id2set,high≥time≥low
Assoc_count(id1,atype):返回(id1,atype) association list的大小,反映在图上也就是id1节点的出度
Assoc_range(id1,atype,pos,limit):返回(id1,atype)association list中满足i∈[pos,pos+limit)的元素
Assoc_time_range(id1,atype,high,low,limit):返回(id1,atype)association list中满足low≤time≤high.
下面给出针对上图的两个例子:
50 most recent comments on Alice’s checkin=>assoc_range(632,COMMENT,0,50)
How many checkins at the GG bridge=>assoc_count(534,CHECKIN)
7、TAO architecture
Storage layer:在存储层,数据被划分为逻辑片段(logical shards),object id中包含一个嵌入的shard_id用来指明它的主分区。Objects在其整个生命过程中都被束缚在一个分区上,association存储在id1的分区上,这样就能保证查询某个object的所有联系只需要访问一个服务器即可。
Caching layer:多个cache servers构成一个tier,一个tier作为一个整体相应每一个TAO请求。TAO in-memory cache objects,association lists,association counts
Client communication stack:use a protocol with out-of-order responses
Leaders and followers:cache被分为两层,一个leader tier和多个follower tiers,leaders主要是读写存储层,followers处理读丢失和把写操作传递给一个leader。TAO处理最后的一致性是通过异步方式从leader到followers传递包括版本号的缓冲维护消息,follower收到leader发来的回应后处理读操作。
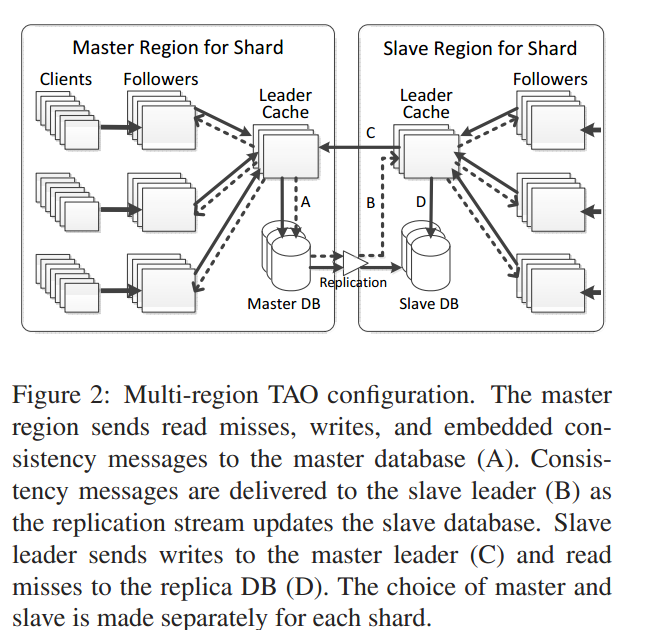
Scaling geographically:follower tiers可以在地理上分隔较远,由于读操作的次数是写操作的25倍,我们可以采用master/slave结构,将写操作发给master,而读操作能够在本地被处理。
本文要点如下:
1、TAO’s goal:针对大量数据读取进行优化,和一致性相比更注重效率和可用性
2、Data model:facebook中直接针对现实中的物体进行建模,其社交图谱包括用户、他们之间的联系、他们的行动、物理地址等等,下图为一个例子:
3、TAO objects为具有类型的节点,TAO associations为objects直接具有类型的有向边。Objects都是以一个全局唯一的64位的整型标识,association以source object,association type,destination object构成的三元组标识,在两个objects之间最多只能存在一种association,objects和association其中都可能包含键值对。
Object:(id)->(otype,(key->value)*)
Assoc.:(id1,atype,id2)->(time,(key->value)*)
注意,由于关系是相对的,association一般都包含一条回边
4、object API:包括分配一个新的object和id,检索,更新,删除object和id
5、Association API:TAO在处理联系时能同步更新其逆关系(反映在图上为一条回边)
Assoc_add(id1,atype,id2,time,(k->v)*):插入或者改写联系(id1,atype,id2),同时更新(id1,inv(atype),id2)
Assoc_delete(id1,atype,id2):删除联系(id1,atype,id2),逆关系也被删除
Assoc_change_type(id1,atype,id2,newtype):改变联系(id1,atype,id2)为(id1,newtype,id2)
6、association query API:社交图谱的一个特点是很多数据都是过时的旧数据,查询主要针对的是最新的数据子集,我们定义一个针对id1和atype的association list按照时间降序排列:
Association list:(id1,atype)->[anew...aold]
TAO针对association list的查询有下面这些函数:
Assoc_get(id1,atype,id2set,high?,low?):返回所有(id1,atype,id2)和该联系的时间和数据,其中id2∈id2set,high≥time≥low
Assoc_count(id1,atype):返回(id1,atype) association list的大小,反映在图上也就是id1节点的出度
Assoc_range(id1,atype,pos,limit):返回(id1,atype)association list中满足i∈[pos,pos+limit)的元素
Assoc_time_range(id1,atype,high,low,limit):返回(id1,atype)association list中满足low≤time≤high.
下面给出针对上图的两个例子:
50 most recent comments on Alice’s checkin=>assoc_range(632,COMMENT,0,50)
How many checkins at the GG bridge=>assoc_count(534,CHECKIN)
7、TAO architecture
Storage layer:在存储层,数据被划分为逻辑片段(logical shards),object id中包含一个嵌入的shard_id用来指明它的主分区。Objects在其整个生命过程中都被束缚在一个分区上,association存储在id1的分区上,这样就能保证查询某个object的所有联系只需要访问一个服务器即可。
Caching layer:多个cache servers构成一个tier,一个tier作为一个整体相应每一个TAO请求。TAO in-memory cache objects,association lists,association counts
Client communication stack:use a protocol with out-of-order responses
Leaders and followers:cache被分为两层,一个leader tier和多个follower tiers,leaders主要是读写存储层,followers处理读丢失和把写操作传递给一个leader。TAO处理最后的一致性是通过异步方式从leader到followers传递包括版本号的缓冲维护消息,follower收到leader发来的回应后处理读操作。
Scaling geographically:follower tiers可以在地理上分隔较远,由于读操作的次数是写操作的25倍,我们可以采用master/slave结构,将写操作发给master,而读操作能够在本地被处理。

相关文章推荐
- TAO: Facebook's Distributed Data Store for the Social Graph论文阅读笔记
- 《A Distributed Graph Engine for Web Scale RDF Data》2013——笔记
- Google分布式系统三大论文(二)Bigtable: A Distributed Storage System for Structured Data
- A survey and Experimental Comparison of Distributed SPARQL Engines for Very Large RDF Data
- Note: Bigtable, A Distributed Storage System for Structured Data
- Could not store transport type data for Receive Location 'Recv.Loc' to config store. Primary SSO Server 'Sql-server' failed. The external credentials in the SSO database are more recent.
- Bigtable: A Distributed Storage System for Structured Data : part4 Building Blocks
- KDD 2014 Workshop on Data Science for Social Good论文阅读记录
- Bigtable: A Distributed Storage System for Structured Data : part5 Implementation
- Bigtable: A Distributed Storage System for Structured Data : part9 Lessons
- Lifetime-Based Memory Management for Distributed Data Processing Systems
- Bigtable: A Distributed Storage System for Structured Data : part6 Refinements
- Android facebook signin for Spring Social webapp
- bigtable: A Distributed Storage System for Structured Data
- Bigtable: A Distributed Storage System for Structured Data : part10 Related Work
- Hugegraph DistributedStoreManager Class Architecture
- SQL Server error "Xml data type is not supported in distributed queries" and workaround for it
- Large data graph database TAO database
- Project Soul: Toward Social Big Data Analytics for Information Discovery and Recommendation
- Bigtable: A Distributed Storage System for Structured Data : part1 Abstract and Introduction