最近工作中一次关于SEM服务器TIME_OUT状态过多的调查报告
2013-07-23 08:21
288 查看
本月SEM更新下载过慢事件我们对SEM服务器的网络状态进行了一次检查,发现了SEM 下9000端口上挂了许多TIME_WAIT连接。节选了一段,类似:Netstat –n | findstr TIME_WAIT
TCP 169.24.1.61:9000 10.11.25.92:4690 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4692 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4694 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4695 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4696 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4697 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4698 TIME_WAIT
观察的一会,使用powershell 的MEASURE-OBJECT方法进行测量,TIME_WAIT峰值数量近千个,而ESTABLISH的连接只有十几个。这个现象是不太正常的。虽然我们诊断的结论是有可能是刀箱交换机流量瓶颈,并将出口流量分流,还SEM的FTP更新服务迁走,最终解决了这个问题。但是以上的TIME_WAIT过多的现象还没有一个合理的解释:这么多TIME_WAIT连接的产生原因是什么,是否会对SEM的网络造成什么影响。从下图中,可以看到TIME_WAIT在TCP状态机中所表示的意义
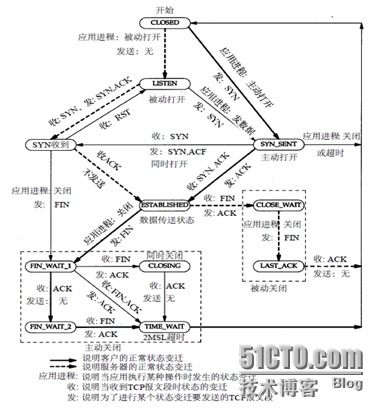
如图:TIME_WAIT 状态是主动断开连接的一方在关闭端口前最后一个状态。受到对端FIN状态后触发,经过2倍报文生存期(MSL)后,端口才会正式关闭。在端口关闭前,这个连接的tcb不会析构,会占用一定量的系统空间内存和tcp协议栈的时间片。同时,在socket 未通过setsockopt函数开启SO_REUSEADDR的情况下,这个端口无法被新的连接复用。理论上讲,在负载不是很严重的情况下,同一个客户端连接少于SOCKET的极限就不会存在严重问题。因为客户端可以再换一个端口,重试连接。这种行为也就造成了TIME_WAIT过多的现象。由此可以推断出,现象的解释背后就是客户端尝试连接SEM服务器,SEM服务器接受连接后主动断开,SEM客户端重试连接,服务器再重新接受,马上又断开,重复这个过程。解决这个问题的一个方式就是修正TIME_WAIT参数,加速TIME_WAIT到CLOSED的迁移。但是修改这个参数会不会有什么不良的副作用呢。
Tcp 中TIME_WAIT设计的目的是为了防止出现以下状况:
一.为了保证发送方最后一个确认报文能让接收端受到。因为这个报文有可能丢失导致接收端不断重传FIN报文,而发送方确已经将端口关闭,无法响应接收端的请求。二.防止报文因为不可预料的原因滞留在网络中,延时到达后给新同样端口新的连接造成干扰在稳定的局域网前提下,这个两个问题发生的概率非常低。而且即使发生了,第一种情况接收端会等到keepalive计时器超时再释放资源,第二种情况无非发起端再重试连接,问题不大。
WINDOW可以在TCP注册表:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters中添加DWORD类型值TcpTimeWaitDelay来修改超时时间,最低30s
还有一个问题,就是这个9000端口后监听的程序是什么。
通过netstat –vb可以看到这个端口是由system占有的,这个信息并没有什么意义。在互联网的端口查询数据库9000端口通常是被一个叫做cslistener的服务使用,但几乎找不到cslistener的任何有意义的信息。我又想到可以通过nmap指纹探测的方式来确定9000端口后面的服务,如果这个服务的指纹在nmap数据库中,我就可以确定他的身份。
C:\Users\inode>nmap -sV -p 9000169.24.1.61
Starting Nmap 6.01 ( http://nmap.org ) at2013-07-12 17:51 中国标准时间
Nmap scan report for 169.24.1.61
Host is up (0.00s latency).
PORT STATE SERVICE VERSION
9000/tcp open http Microsoft IIS httpd 6.0
Service Info: OS: Windows; CPE: cpe:/o:microsoft:windows
Service detection performed. Please reportany incorrect results at http://nmap. org/submit/ .
Nmap done: 1 IP address (1 host up) scannedin 14.48 seconds
果然,9000端口后台真实的服务被IIS6.0所匹配。打开II6.0的管理端,找到9000端口属于SEMService,查看该网站的配置,采用120s超时的http keepalive连接。查看用户访问日志,并无异常。只是同一个ip会有几次连续的post操作。
结合不断出现TIME_WAIT的现象,可以推测出问题的起因有可能是由于虽然SEM服务支持keepalive,但是sem客户端在请求的时候并没有在自己的http header中添加keepalive的请求标志,造成所有传输数据都是socket短连接.连续的post操作每次都会新增加一个socket连接,导致TIME_WAIT过多。
如果推断属实的话,这个问题在并发小,吞吐量要求不高的情况下不会产生什么问题。一旦并发增大到一定程度,或者吞吐量有一定要求的时候,可能就会产生性能瓶颈。因为tcp流量控制通过滑动窗口算法。而一个连接的吞吐量和窗口大小直接相关,吞吐量等于窗口大小除以报文往返时间。滑动窗口算法的拥塞窗口在小于ssthresh阈值之前每次传输都会以指数级增长。但是短连接连接时间过短,导致窗口来不及增长,连接就断开了,握手报文比重过大。从而限制传输的吞吐量。
这个问题,可能还是需要注意一下的。
结论:
虽然TIME_WAIT状态过多的情况对目前的sem使用来说并没有太多影响,但是这个问题背后的原因还是值得SEM管理人员注意。
注:sem是我们公司的erp系统。本来不由我们负责管理,而是由开发直接负责。因为前一天该服务器所在刀箱交换机坏了一台,给它换了台交换机,第二天所有人抱怨没法更新,sem管理员直接就找过来了。只好帮着看一看,顺便发现了这个问题,就顺便调查了一下
TCP 169.24.1.61:9000 10.11.25.92:4690 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4692 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4694 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4695 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4696 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4697 TIME_WAIT TCP 169.24.1.61:9000 10.11.25.92:4698 TIME_WAIT
观察的一会,使用powershell 的MEASURE-OBJECT方法进行测量,TIME_WAIT峰值数量近千个,而ESTABLISH的连接只有十几个。这个现象是不太正常的。虽然我们诊断的结论是有可能是刀箱交换机流量瓶颈,并将出口流量分流,还SEM的FTP更新服务迁走,最终解决了这个问题。但是以上的TIME_WAIT过多的现象还没有一个合理的解释:这么多TIME_WAIT连接的产生原因是什么,是否会对SEM的网络造成什么影响。从下图中,可以看到TIME_WAIT在TCP状态机中所表示的意义
如图:TIME_WAIT 状态是主动断开连接的一方在关闭端口前最后一个状态。受到对端FIN状态后触发,经过2倍报文生存期(MSL)后,端口才会正式关闭。在端口关闭前,这个连接的tcb不会析构,会占用一定量的系统空间内存和tcp协议栈的时间片。同时,在socket 未通过setsockopt函数开启SO_REUSEADDR的情况下,这个端口无法被新的连接复用。理论上讲,在负载不是很严重的情况下,同一个客户端连接少于SOCKET的极限就不会存在严重问题。因为客户端可以再换一个端口,重试连接。这种行为也就造成了TIME_WAIT过多的现象。由此可以推断出,现象的解释背后就是客户端尝试连接SEM服务器,SEM服务器接受连接后主动断开,SEM客户端重试连接,服务器再重新接受,马上又断开,重复这个过程。解决这个问题的一个方式就是修正TIME_WAIT参数,加速TIME_WAIT到CLOSED的迁移。但是修改这个参数会不会有什么不良的副作用呢。
Tcp 中TIME_WAIT设计的目的是为了防止出现以下状况:
一.为了保证发送方最后一个确认报文能让接收端受到。因为这个报文有可能丢失导致接收端不断重传FIN报文,而发送方确已经将端口关闭,无法响应接收端的请求。二.防止报文因为不可预料的原因滞留在网络中,延时到达后给新同样端口新的连接造成干扰在稳定的局域网前提下,这个两个问题发生的概率非常低。而且即使发生了,第一种情况接收端会等到keepalive计时器超时再释放资源,第二种情况无非发起端再重试连接,问题不大。
WINDOW可以在TCP注册表:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters中添加DWORD类型值TcpTimeWaitDelay来修改超时时间,最低30s
还有一个问题,就是这个9000端口后监听的程序是什么。
通过netstat –vb可以看到这个端口是由system占有的,这个信息并没有什么意义。在互联网的端口查询数据库9000端口通常是被一个叫做cslistener的服务使用,但几乎找不到cslistener的任何有意义的信息。我又想到可以通过nmap指纹探测的方式来确定9000端口后面的服务,如果这个服务的指纹在nmap数据库中,我就可以确定他的身份。
C:\Users\inode>nmap -sV -p 9000169.24.1.61
Starting Nmap 6.01 ( http://nmap.org ) at2013-07-12 17:51 中国标准时间
Nmap scan report for 169.24.1.61
Host is up (0.00s latency).
PORT STATE SERVICE VERSION
9000/tcp open http Microsoft IIS httpd 6.0
Service Info: OS: Windows; CPE: cpe:/o:microsoft:windows
Service detection performed. Please reportany incorrect results at http://nmap. org/submit/ .
Nmap done: 1 IP address (1 host up) scannedin 14.48 seconds
果然,9000端口后台真实的服务被IIS6.0所匹配。打开II6.0的管理端,找到9000端口属于SEMService,查看该网站的配置,采用120s超时的http keepalive连接。查看用户访问日志,并无异常。只是同一个ip会有几次连续的post操作。
结合不断出现TIME_WAIT的现象,可以推测出问题的起因有可能是由于虽然SEM服务支持keepalive,但是sem客户端在请求的时候并没有在自己的http header中添加keepalive的请求标志,造成所有传输数据都是socket短连接.连续的post操作每次都会新增加一个socket连接,导致TIME_WAIT过多。
如果推断属实的话,这个问题在并发小,吞吐量要求不高的情况下不会产生什么问题。一旦并发增大到一定程度,或者吞吐量有一定要求的时候,可能就会产生性能瓶颈。因为tcp流量控制通过滑动窗口算法。而一个连接的吞吐量和窗口大小直接相关,吞吐量等于窗口大小除以报文往返时间。滑动窗口算法的拥塞窗口在小于ssthresh阈值之前每次传输都会以指数级增长。但是短连接连接时间过短,导致窗口来不及增长,连接就断开了,握手报文比重过大。从而限制传输的吞吐量。
这个问题,可能还是需要注意一下的。
结论:
虽然TIME_WAIT状态过多的情况对目前的sem使用来说并没有太多影响,但是这个问题背后的原因还是值得SEM管理人员注意。
注:sem是我们公司的erp系统。本来不由我们负责管理,而是由开发直接负责。因为前一天该服务器所在刀箱交换机坏了一台,给它换了台交换机,第二天所有人抱怨没法更新,sem管理员直接就找过来了。只好帮着看一看,顺便发现了这个问题,就顺便调查了一下

相关文章推荐
- 最近想发起一次服务器合租,有米有人有兴趣
- 关于最近的工作总结
- 最近的工作,关于wap方面
- 最近工作有点不在状态,笔记也没状态
- CN上没有关于IBM的Initiate的文章,由于最近在做这方面的工作,分享下Initiate的开发心得~
- 关于自己最近的状态
- TIME_WAIT状态的连接过多导致系统端口资源耗尽问题(2)
- 服务器tcp连接timewait过多优化及详细分析
- 关于net 提交出现 ”此页的状态信息无效,可能已损坏 应用程序中的服务器错误“
- TCP 协议状态分解---服务器TIME_WAIT和CLOSE_WAIT详解和解决办法
- 说说最近的工作状态
- TCP连接状态详解及TIME_WAIT过多的解决方法
- Android 关于后台杀死App之后改变服务器状态的一些尝试
- Linux服务器web相关内核参数注解及TIME_WAIT状态的连接过多解决办法
- NGINX服务器工作状态NGX_HTTP_STUB_STATUS_MODULE 模块
- nfsstat命令_Linux nfsstat 命令用法详解:列出NFS客户端和服务器的工作状态
- 关于web服务器TIME_WAIT值高的问答 推荐
- Linux服务器web相关内核参数注解及TIME_WAIT状态的连接过多解决办法
- 最近的一些思考(关于学业,职业,工作等等)
- 最近在Bilibili做的一次关于个人网站搭建的分享