进程的创建与可执行程序的加载
2013-05-30 16:58
309 查看
ID **超 学号:SA*****256
实验内容:
1.参考进程初探 编程实现fork(创建一个进程实体) -> exec(将ELF可执行文件内容加载到进程实体) -> running program
2.参照C代码中嵌入汇编代码示例及用汇编代码使用系统调用time示例分析fork和exec系统调用在内核中的执行过程
3.注意task_struct进程控制块,ELF文件格式与进程地址空间的联系,注意Exec系统调用返回到用户态时EIP指向的位置。
4.动态链接库在ELF文件格式中与进程地址空间中的表现形式
实验目的:加深理解Linux工作原理
实验环境:Ubuntu12.10 内核版本3.5.0-17-generic
实验分析及过程:
第一部分:fork() 和 exec()
在linux中,有三种方式可以启动新进程
1.使用system调用
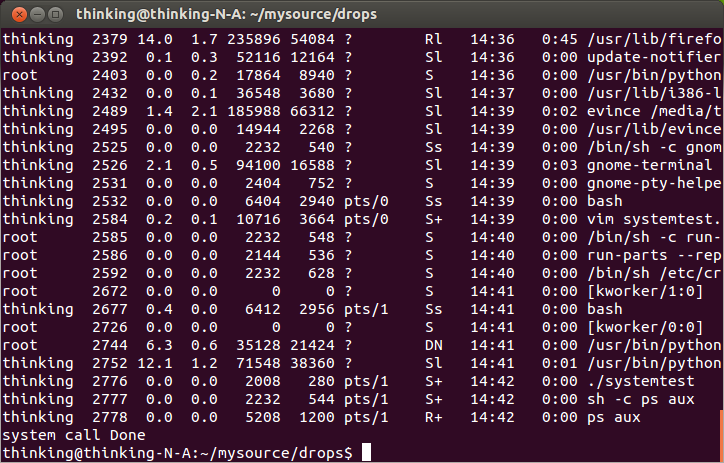
在这里,我们相当于在shell中 输入了 ps aux 命令
2.使用fork()
这个系统调用复制当前进程,在进程表中创建一个新的表项,新表项中的许多属性与当前进程相同。但是新进程有自己的数据空间(堆和栈),环境和文件描述符。在父进程中的fork调用返回的是新的子进程的PID,而新进程返回的是0.程序代码也靠这一点来区分父子进程。创建失败返回-1.这边在之前看到过有这么一个解释,相当与是一个链状的进程序列,子进程没有儿子了,所以0相当于指向为空,是不是和链表结构很像呢?具体的linux是怎么实现的,待我之后考证。
说了这么多,我们来看下面的例子来加深下理解吧。
3.使用exec()
exec() 系列函数有一组相关的函数组成 ,exec函数可以把当前进程替换为另一个新进程,新进程由path 或者file 参数指定。我们可以使用exec函数将程序的执行从一个程序切换到另一个程序。在新的程序启动后,原来的程序就不再运行了。
这些函数通常都是用execve实现的。我们来看下面的一个例子,在这个例子当中,我直接指定了各个变量,并没有从shell中读入。
我们发现一个很有趣的现象,
printf("After Runing ps wiht execlp,after_pid=%d\n",after_pid);
并没有被执行。这是由于exec函数取代了原先的进程,一般情况下,exec函数是不会返回的,除非发生错误。出现错误时,exec函数返回-1,并设置错误变量errno。
特别要注意的一点,在原进程中已打开的文件描述符在新进程中仍将保持打开,除非它们的执行时关闭标志被置位。
第二部分:fork和exec系统调用在内核中的执行过程
对fork函数进行反汇编
汇编的时候要注意设置断点
如下:
fork()函数在系统调用中,会执行do_fork()函数,其关键步骤如下:
1)查找pidmap_array位图,为子进程获取一个新的PID;
2)调用copy_process()函数,这个函数会将子进程的各个数据结构进行分配并初始化,它返回子进程描述符,即task_struct结构的指针;
3)返回并返回子进程的PID;
copy_process()函数的执行过程:
1)为子进程分配一个task_struct结构,将其指针暂存在局部变量tsk中,并继续分配一个thread_info结构,将其指针暂存在局部变量ti中;
2)将current进程描述符地址复制到tsk指向的task_struct结构,将ti描述父地址复制到tsk指向的thread_info结构,并将当前进程的thread_info结构内容拷贝到ti指向结构中;(子进程复制父进程的进程描述符以及thread_info描述符)
3)用子进程PID更新task_struct中的pid字段;
4)分别创建并复制父进程的打开文件列表、文件系统描述符、信号描述符、内存描述符、命名空间等结构;
5)初始化子进程的内核栈,并将eax寄存器对应字段的值设为0(这样子进程返回时,系统调用返回值便为0);
6)结束并返回子进程描述符指针tsk;
对exec函数进行反汇编
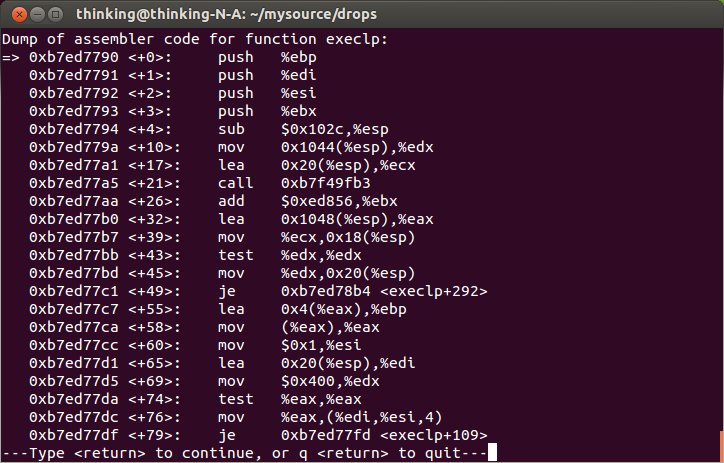
execlp分析
系统中存在一个formats链表,其链表结构分别对应一种可执行文件的执行方法,execlp()函数对应的系统调用sys_exece()函数会分配一个linux_binprm数据结构并将可执行文件的数据拷贝到其中,并依次扫描formats链表试图执行这个可执行文件,一旦找到了就执行链表结构中的load_binary方法,其主要步骤为:
1)将可执行文件的首部拷贝至内存;
2)根据动态链接程序路径名将共享库对应函数映射到内存;
3)释放原进程的内存描述符、线性区描述符、所有页框;
4)选择线性区的布局;
5)为可执行文件的代码段、数据段以及动态链接程序的代码段、数据段分别进行内存映射;
6)修改内核态堆栈中eip、esp寄存器的值,使其分别指向程序的入口点以及新的用户态堆栈顶并返回;
动态链接执行程序的过程
在传统的静态链接中,程序中用到的每个库函数,都会在链接器的链接过程中,将全部代码复制到文本段中,这种方式的原理十分简单,但是会使得程序的文本段过于庞大,对于紧缺的内存资源来说,是一种巨大的浪费。
而动态链接的过程,并不需要将各个库函数的代码分别进行复制,只需要在程序中静态指明其链接的目标库函数在库文件的位置就可以了,在程序真正开始执行之前,动态链接器会根据文件中的重定位信息将其链接的库函数映射到内存中。而库文件因为是被“映射”到内存中的,所以每个库只有一个库文件,且可以同时被几个不同的程序进行映射。其过程基本如下:
1)参照图五中各个段的信息,其中.interp段存放了动态链接器的路径,程序运行之前,会首先通过这里找到动态链接器,并加载和运行这个动态链接器。
2).got中存放了全局偏移量表GOT,每个被此程序链接到的全局数据都有一个对应的条目,静态编译时会在其中存放各个重定位记录,在加载过程中,链接器会对其中的各个记录依次进行重定位,使其含有固定的地址,从此不再变化。
3).plt存放了过程链接表PLT,每个被此程序链接到的全局函数都有一个对应的条目,此外,每个全局函数在GOT表中也有一个对应条目。执行过程中,每当初次调用其中的某个函数,则会通过PLT表跳转到GOT表,计算出函数地址后,会重定位GOT表中的条目。之后便不再计算函数地址,直接跳转得到函数地址。
在链接器加载程序运行时,会在一个3GB的用户虚拟内存空间中进行内存映射(3GB-4GB为内核空间),链接器会根据ELF文件的头部与段头部表中的信息,分别对各个段进行处理,并将程序的代码段从地址0x08048000开始向上映射,紧随其后的是数据段,堆紧随数据段之后,以供malloc进行动态内存分配,而用户态堆栈从最大合法用户态空间地址向下增长,在堆栈与堆之间是共享库的链接函数内存映射空间,此时内存空间的影响基本如下所示:
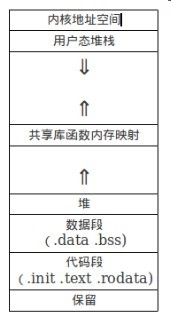
图六
之后加载器转到程序的入口点,即.text中的_start的位置,这里的几行汇编代码在所有程序加载过程中都是一样的,它们分别会进行一些初始化例程,并注册一些退出程序时应执行的例程,最后会执行callmain命令,此时开始执行程序正文。
实验内容:
1.参考进程初探 编程实现fork(创建一个进程实体) -> exec(将ELF可执行文件内容加载到进程实体) -> running program
2.参照C代码中嵌入汇编代码示例及用汇编代码使用系统调用time示例分析fork和exec系统调用在内核中的执行过程
3.注意task_struct进程控制块,ELF文件格式与进程地址空间的联系,注意Exec系统调用返回到用户态时EIP指向的位置。
4.动态链接库在ELF文件格式中与进程地址空间中的表现形式
实验目的:加深理解Linux工作原理
实验环境:Ubuntu12.10 内核版本3.5.0-17-generic
实验分析及过程:
第一部分:fork() 和 exec()
在linux中,有三种方式可以启动新进程
1.使用system调用
#include<stdlib.h> int system(const char* string);它的作用是,运行以字符串参数的形式传递给它的命令并等待该命令的完成。命令的执行情况如同在shell中执行如下命令:
$ sh -c string我们来看下面的一个例子吧:
#include<stdlib.h>
#include<stdio.h>
int main()
{
printf("Running ps with system call\n");
system("ps aux");
printf("system call Done\n");
exit(0);
}在这里,我们相当于在shell中 输入了 ps aux 命令
2.使用fork()
#include<sys/types.h> #include<unistd.h> pid_t fork(void);
这个系统调用复制当前进程,在进程表中创建一个新的表项,新表项中的许多属性与当前进程相同。但是新进程有自己的数据空间(堆和栈),环境和文件描述符。在父进程中的fork调用返回的是新的子进程的PID,而新进程返回的是0.程序代码也靠这一点来区分父子进程。创建失败返回-1.这边在之前看到过有这么一个解释,相当与是一个链状的进程序列,子进程没有儿子了,所以0相当于指向为空,是不是和链表结构很像呢?具体的linux是怎么实现的,待我之后考证。
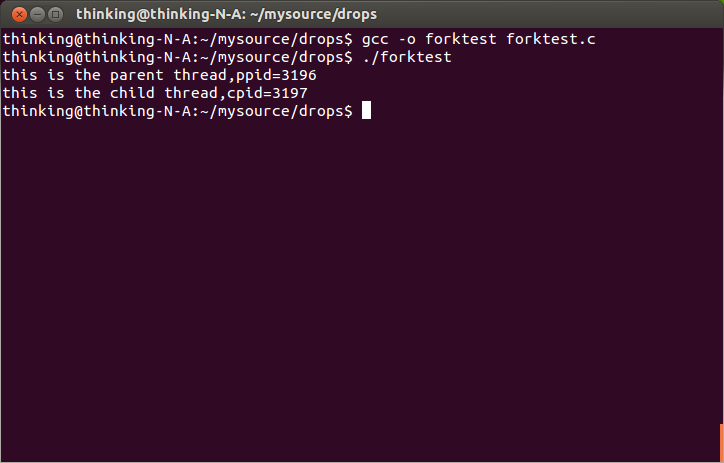
说了这么多,我们来看下面的例子来加深下理解吧。
#include<sys/types.h>
#include<unistd.h>
#include<stdlib.h>
#include<stdio.h>
int main()
{
pid_t pid;
pid=fork();
if(0==pid)
{
pid_t cpid=getpid();
printf("this is the child thread,cpid=%d\n",cpid);
}
else if(pid>0)
{
pid_t ppid=getpid();
printf("this is the parent thread,ppid=%d\n",ppid);
}
else
printf("fork error\n");
return 0;
}3.使用exec()
exec() 系列函数有一组相关的函数组成 ,exec函数可以把当前进程替换为另一个新进程,新进程由path 或者file 参数指定。我们可以使用exec函数将程序的执行从一个程序切换到另一个程序。在新的程序启动后,原来的程序就不再运行了。
#include<unistd.h> char ** environ; int execl(const char *path,const char *arg0,...,(char *)0); int execlp(const char *file,const char *arg0,...,(char *)0); int execle(const char *path,const char *arg0,...,(char *)0,char *const envp[]); int execv(const char *path,char *const argv[]); int execvp(const char *file,char *const argv[]); int execve(const char *path,char *const argv[],char *const envp[]);这些函数可以分为两大类。execl execlp execle 的参数个数可以变化,参数以一个空指针结束。execv execvp 的第二个参数是一个字符串数组。不管哪种情况,新程序在启动时会把argv数组中给定的参数传递给main函数。
这些函数通常都是用execve实现的。我们来看下面的一个例子,在这个例子当中,我直接指定了各个变量,并没有从shell中读入。
#include<stdlib.h>
#include<unistd.h>
#include<stdio.h>
int main(int argc,char *argv[],char *envp[])
{
pid_t pre_pid=getpid();
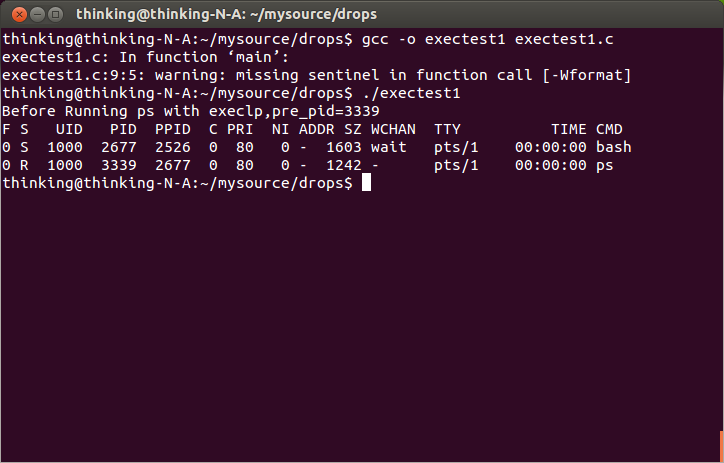
printf("Before Running ps with execlp,pre_pid=%d\n",pre_pid);
execlp("ps","ps","-l",0);
pid_t after_pid=getpid();
printf("After Runing ps wiht execlp,after_pid=%d\n",after_pid);
exit(0);
}我们发现一个很有趣的现象,
printf("After Runing ps wiht execlp,after_pid=%d\n",after_pid);
并没有被执行。这是由于exec函数取代了原先的进程,一般情况下,exec函数是不会返回的,除非发生错误。出现错误时,exec函数返回-1,并设置错误变量errno。
特别要注意的一点,在原进程中已打开的文件描述符在新进程中仍将保持打开,除非它们的执行时关闭标志被置位。
第二部分:fork和exec系统调用在内核中的执行过程
对fork函数进行反汇编
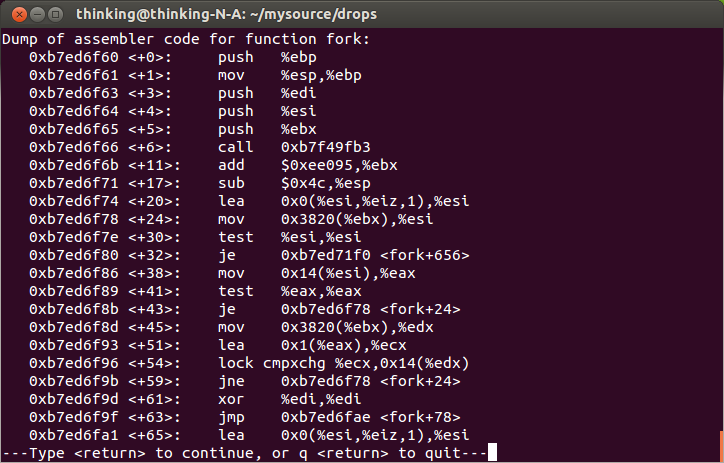
汇编的时候要注意设置断点
如下:
gcc -g forktest.c -o forktest gdb forktest b fork r disas fork
fork()函数在系统调用中,会执行do_fork()函数,其关键步骤如下:
1)查找pidmap_array位图,为子进程获取一个新的PID;
2)调用copy_process()函数,这个函数会将子进程的各个数据结构进行分配并初始化,它返回子进程描述符,即task_struct结构的指针;
3)返回并返回子进程的PID;
copy_process()函数的执行过程:
1)为子进程分配一个task_struct结构,将其指针暂存在局部变量tsk中,并继续分配一个thread_info结构,将其指针暂存在局部变量ti中;
2)将current进程描述符地址复制到tsk指向的task_struct结构,将ti描述父地址复制到tsk指向的thread_info结构,并将当前进程的thread_info结构内容拷贝到ti指向结构中;(子进程复制父进程的进程描述符以及thread_info描述符)
3)用子进程PID更新task_struct中的pid字段;
4)分别创建并复制父进程的打开文件列表、文件系统描述符、信号描述符、内存描述符、命名空间等结构;
5)初始化子进程的内核栈,并将eax寄存器对应字段的值设为0(这样子进程返回时,系统调用返回值便为0);
6)结束并返回子进程描述符指针tsk;
对exec函数进行反汇编
execlp分析
系统中存在一个formats链表,其链表结构分别对应一种可执行文件的执行方法,execlp()函数对应的系统调用sys_exece()函数会分配一个linux_binprm数据结构并将可执行文件的数据拷贝到其中,并依次扫描formats链表试图执行这个可执行文件,一旦找到了就执行链表结构中的load_binary方法,其主要步骤为:
1)将可执行文件的首部拷贝至内存;
2)根据动态链接程序路径名将共享库对应函数映射到内存;
3)释放原进程的内存描述符、线性区描述符、所有页框;
4)选择线性区的布局;
5)为可执行文件的代码段、数据段以及动态链接程序的代码段、数据段分别进行内存映射;
6)修改内核态堆栈中eip、esp寄存器的值,使其分别指向程序的入口点以及新的用户态堆栈顶并返回;
动态链接执行程序的过程
在传统的静态链接中,程序中用到的每个库函数,都会在链接器的链接过程中,将全部代码复制到文本段中,这种方式的原理十分简单,但是会使得程序的文本段过于庞大,对于紧缺的内存资源来说,是一种巨大的浪费。
而动态链接的过程,并不需要将各个库函数的代码分别进行复制,只需要在程序中静态指明其链接的目标库函数在库文件的位置就可以了,在程序真正开始执行之前,动态链接器会根据文件中的重定位信息将其链接的库函数映射到内存中。而库文件因为是被“映射”到内存中的,所以每个库只有一个库文件,且可以同时被几个不同的程序进行映射。其过程基本如下:
1)参照图五中各个段的信息,其中.interp段存放了动态链接器的路径,程序运行之前,会首先通过这里找到动态链接器,并加载和运行这个动态链接器。
2).got中存放了全局偏移量表GOT,每个被此程序链接到的全局数据都有一个对应的条目,静态编译时会在其中存放各个重定位记录,在加载过程中,链接器会对其中的各个记录依次进行重定位,使其含有固定的地址,从此不再变化。
3).plt存放了过程链接表PLT,每个被此程序链接到的全局函数都有一个对应的条目,此外,每个全局函数在GOT表中也有一个对应条目。执行过程中,每当初次调用其中的某个函数,则会通过PLT表跳转到GOT表,计算出函数地址后,会重定位GOT表中的条目。之后便不再计算函数地址,直接跳转得到函数地址。
在链接器加载程序运行时,会在一个3GB的用户虚拟内存空间中进行内存映射(3GB-4GB为内核空间),链接器会根据ELF文件的头部与段头部表中的信息,分别对各个段进行处理,并将程序的代码段从地址0x08048000开始向上映射,紧随其后的是数据段,堆紧随数据段之后,以供malloc进行动态内存分配,而用户态堆栈从最大合法用户态空间地址向下增长,在堆栈与堆之间是共享库的链接函数内存映射空间,此时内存空间的影响基本如下所示:
图六
之后加载器转到程序的入口点,即.text中的_start的位置,这里的几行汇编代码在所有程序加载过程中都是一样的,它们分别会进行一些初始化例程,并注册一些退出程序时应执行的例程,最后会执行callmain命令,此时开始执行程序正文。

相关文章推荐
- 进程的创建与可执行程序的加载
- 关于fork&exec之进程的创建和可执行程序的加载过程
- 进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- 【实验二】进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- Linux操作系统分析-(2)进程的创建与可执行程序的加载
- Linux操作系统分析(二)进程的创建与可执行程序的加载
- Linux进程的创建与可执行程序的加载
- 【实验二】进程的创建与可执行程序的加载
- 实验二:进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- Linux操作系统学习_用户进程之由新进程创建到可执行程序的加载
- 进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载
- Linux操作系统分析-lab2-进程的创建与可执行程序的加载
- 进程的创建与可执行程序的加载