【算法导论之五】散列表
2013-05-29 16:09
387 查看
1. 直接寻址表的局限,散列表的产生
直接寻址表:当关键字的全域U比较小时,直接寻址是一种简单有效的技术。假设某应用用到一个动态集合,其中每个元素都有一个取自全域U={0,1,... ,m-1}的关键字,此处的m是一个不很大的数。另外假设,没有两个元素具有相同的关键字。
为表示动态集合,我们用一个数组(或称直接寻址表)T[0..m-1],其中每个位置(或称为槽)对应全域U中的一个关键字。即:槽 k 指向一个关键字为 k 的元素,如果该集合中没有关键字为 k 的元素,则 T[ k ] = NIL 。对于它的字典操作:insert() , search() , delete()执行很快,只需要O( 1 ) 的时间。
但是直接寻址技术存在一个很大的问题:如果域U很大,在一台典型计算机的可用内存容量限制下,要在机器中存储大小为|U|的一张表 T 就有点不实际了。而当存储在字典中的关键字集合K比所有可能的关键字域U要小很多时,散列表需要的存储空间要比直接寻址表少很多。
散列表(Hash table),使用具有m个槽位的数组来存储大小为n的动态集合。α=n/m被定义为散列表的装载因子。在散列表中,具有关键字k的元素的下标为h(k),即利用散列函数h,根据关键字k计算出槽的位置。散列函数h将关键字域[0..p]映射到散列表[0..m-1]的槽位上,这里,m可以远小于p,从而缩小了需要处理的下标范围,并相应地降低了空间开销。散列表带来的问题是:两个关键字可能映射到同一个槽上,这种情形称为碰撞。因此,散列函数h应当将每个关键字等可能地散列到m个槽位的任何一个中去,并与其它关键字已被散列到哪一个槽位中无关,从而避免或者至少最小化碰撞。
2. 散列函数
多数散列函数都假定关键字域为自然数集。如果所给关键字不是自然数,则必须有一种方法将它们解释为自然数。这里,介绍三种主要的散列函数:
除法散列法:通过取k除以m的余数,来将关键字k映射到m个槽的某一个中去,即散列函数为:
h(k) = k mod m
当应用除法散列法时,要注意m的选择,这也是除法散列法的主要缺点。m不应是2的幂,因为如果m=2p,则h(k)就是k的p个最低有效位。相反,散列函数应该考虑关键字的所有位。可以选作m的值通常是与2的整数幂不太接近的质数。
乘法散列法:首先,用关键字k乘上常数A(0<A<1),并抽取kA的小数部分;然后,用m乘以这个值,再取结果的底(即整数部分)。散列函数可表达为:h(k)
= ⌊m(kA mod 1)⌋
乘法方法的一个优点是对m的选择没有特别的要求,一般选择它为2的某个幂次(m=2p)。该方法对任何的A值都适用,但对某些值效果更好。A=(sqrt(5)-1)/2=0.6180339…是一个比较理想的值。
全域散列(universal hashing):在执行开始时,从一族仔细设计的函数中,随机地选择一个作为散列函数。这里的随机选择针对的是一次对散列表的应用,而不是一次简单的插
入或查找操作。散列函数的确定性,是查找操作正确执行的保证。全域散列法确保,当k!=l时,两者发生碰撞的概率不大于1/m。设计一个全域散列函数类的方法如下,该方法
中,散列表大小m的大小是任意的。
选择一个足够大的质数p,使得每一个可能的关键字都落在0到p-1的范围内。设Zp表示集合{0, 1, …, p-1},Zp*表示集合{1, 2, …, p-1}。对于任何a∈Zp*和任何b∈Zp,定义散列函数ha,b
ha,b = ((ak+b) mod p) mod m
所有这样的散列函数构成的函数族为:Hp,m = {ha,b : a∈Zp*和b∈Zp}
由于对a来说有p-1种选择,对于b来说有p种选择,因而,Hp,m中共有p(p-1)个散列函数。
3. 解决碰撞的方法
链接法(chaining):把散列到同一槽中的所有元素都存放在一个链表中。每个槽中有一个指针,指向由所有散列到该槽的元素构成的链表的头。如果不存在这样的元素,则指针为空。如果链接法使用的是双向链表,那么删除操作的最坏情况运行时间与插入操作相同,都为O(1),而平均情况下一次成功的查找需要Θ(1+α)时间。
开放寻址法(open addressing):所有的元素都存放在散列表中。因此,适用于动态集合大小n不大于散列表大小的情况,即装载因子不超过1。否则,可能发生散列表溢出。在开放寻址中,当要插入一个元素时,可以连续地探查散列表的各项,直到找到一个空槽来放置待插入的关键字。探查的顺序不一定是0, 1, …, m-1,而是要依赖于待插入的关键字k。于是,将探查号作为散列函数的第二个输入参数。为了使所有的槽位都能够被探查到,探查序列<h(k,0), h(k,1),
…, h(k,m-1)>必须是<0, 1, …, m-1>的一个排列。有三种技术常用来计算开放寻址法中的探查序列:线性探查、二次探查,以及双重探查。
线性探查(linear probing):使用的散列函数如下:h(k,i) = (h’(k) + i) mod m, i=0, 1, …, m-1
h’为一个普通的散列函数,见前面的介绍。线性探查存在一个称为一次群集的问题,即随着时间的推移,连续被占用的槽不断增加,平均查找时间也随着不断增加。但是,线性探查的优点在于,对m的取值没有特殊的要求。
二次探查(quadratic probing):使用的散列函数如下:h(k,i) = (h’(k) +c1 i + c2 i2) mod m, i=0, 1, …, m-1
为了能够充分利用散列表,c1、c2和m的值要受到限制。一种好的选择是,m为2的某个幂次(m=2p),c1=c2=1/2。二次探查,不会顺序地探查每一个槽位,解决了一次群集问题。但是,如果两个关键字的初始探查位置相同,那么它们的探查序列也是相同的,这一性质导致一种程度较轻的群集现象,称为二次群集。
双重散列(double hashing):使用的散列函数如下:h(k,i) = (h1(k) + i h2(k)) mod m, i=0, 1, …, m-1
为能查找整个散列表,值h2(k)要与表的大小m互质。确保这一条件成立的一种方法是取m为2的幂,并设计一个总能产生奇数的h2。另一种方法是取m为质数,并设计一个总是产生较m小的正整数的h2。例如,可以取m为质数,h2(k)=1+(k mod m’),m’=m-1。
4. 采用乘法散列作为哈希函数以及链接法实现散列表的代码:
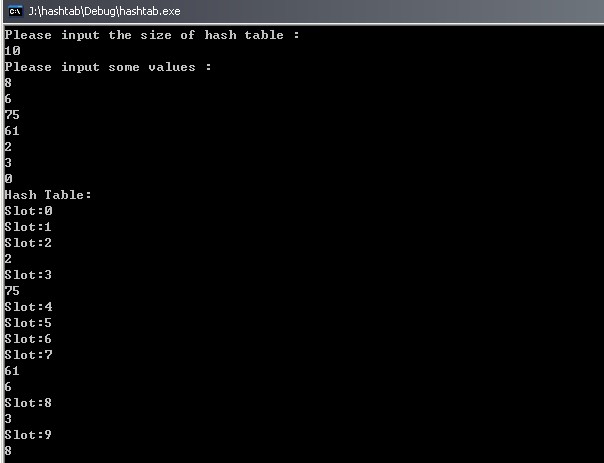
运行结果:
5. 采用乘法散列作为哈希函数和线性探测作为碰撞检测实现的散列表:
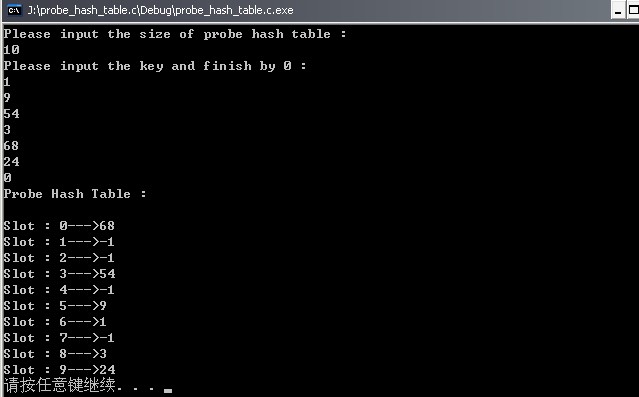
运行结果:
6. 参考链接:http://blog.csdn.net/intrepyd/article/details/4359818
坚持每天的学习,加油!!
直接寻址表:当关键字的全域U比较小时,直接寻址是一种简单有效的技术。假设某应用用到一个动态集合,其中每个元素都有一个取自全域U={0,1,... ,m-1}的关键字,此处的m是一个不很大的数。另外假设,没有两个元素具有相同的关键字。
为表示动态集合,我们用一个数组(或称直接寻址表)T[0..m-1],其中每个位置(或称为槽)对应全域U中的一个关键字。即:槽 k 指向一个关键字为 k 的元素,如果该集合中没有关键字为 k 的元素,则 T[ k ] = NIL 。对于它的字典操作:insert() , search() , delete()执行很快,只需要O( 1 ) 的时间。
但是直接寻址技术存在一个很大的问题:如果域U很大,在一台典型计算机的可用内存容量限制下,要在机器中存储大小为|U|的一张表 T 就有点不实际了。而当存储在字典中的关键字集合K比所有可能的关键字域U要小很多时,散列表需要的存储空间要比直接寻址表少很多。
散列表(Hash table),使用具有m个槽位的数组来存储大小为n的动态集合。α=n/m被定义为散列表的装载因子。在散列表中,具有关键字k的元素的下标为h(k),即利用散列函数h,根据关键字k计算出槽的位置。散列函数h将关键字域[0..p]映射到散列表[0..m-1]的槽位上,这里,m可以远小于p,从而缩小了需要处理的下标范围,并相应地降低了空间开销。散列表带来的问题是:两个关键字可能映射到同一个槽上,这种情形称为碰撞。因此,散列函数h应当将每个关键字等可能地散列到m个槽位的任何一个中去,并与其它关键字已被散列到哪一个槽位中无关,从而避免或者至少最小化碰撞。
2. 散列函数
多数散列函数都假定关键字域为自然数集。如果所给关键字不是自然数,则必须有一种方法将它们解释为自然数。这里,介绍三种主要的散列函数:
除法散列法:通过取k除以m的余数,来将关键字k映射到m个槽的某一个中去,即散列函数为:
h(k) = k mod m
当应用除法散列法时,要注意m的选择,这也是除法散列法的主要缺点。m不应是2的幂,因为如果m=2p,则h(k)就是k的p个最低有效位。相反,散列函数应该考虑关键字的所有位。可以选作m的值通常是与2的整数幂不太接近的质数。
乘法散列法:首先,用关键字k乘上常数A(0<A<1),并抽取kA的小数部分;然后,用m乘以这个值,再取结果的底(即整数部分)。散列函数可表达为:h(k)
= ⌊m(kA mod 1)⌋
乘法方法的一个优点是对m的选择没有特别的要求,一般选择它为2的某个幂次(m=2p)。该方法对任何的A值都适用,但对某些值效果更好。A=(sqrt(5)-1)/2=0.6180339…是一个比较理想的值。
全域散列(universal hashing):在执行开始时,从一族仔细设计的函数中,随机地选择一个作为散列函数。这里的随机选择针对的是一次对散列表的应用,而不是一次简单的插
入或查找操作。散列函数的确定性,是查找操作正确执行的保证。全域散列法确保,当k!=l时,两者发生碰撞的概率不大于1/m。设计一个全域散列函数类的方法如下,该方法
中,散列表大小m的大小是任意的。
选择一个足够大的质数p,使得每一个可能的关键字都落在0到p-1的范围内。设Zp表示集合{0, 1, …, p-1},Zp*表示集合{1, 2, …, p-1}。对于任何a∈Zp*和任何b∈Zp,定义散列函数ha,b
ha,b = ((ak+b) mod p) mod m
所有这样的散列函数构成的函数族为:Hp,m = {ha,b : a∈Zp*和b∈Zp}
由于对a来说有p-1种选择,对于b来说有p种选择,因而,Hp,m中共有p(p-1)个散列函数。
3. 解决碰撞的方法
链接法(chaining):把散列到同一槽中的所有元素都存放在一个链表中。每个槽中有一个指针,指向由所有散列到该槽的元素构成的链表的头。如果不存在这样的元素,则指针为空。如果链接法使用的是双向链表,那么删除操作的最坏情况运行时间与插入操作相同,都为O(1),而平均情况下一次成功的查找需要Θ(1+α)时间。
开放寻址法(open addressing):所有的元素都存放在散列表中。因此,适用于动态集合大小n不大于散列表大小的情况,即装载因子不超过1。否则,可能发生散列表溢出。在开放寻址中,当要插入一个元素时,可以连续地探查散列表的各项,直到找到一个空槽来放置待插入的关键字。探查的顺序不一定是0, 1, …, m-1,而是要依赖于待插入的关键字k。于是,将探查号作为散列函数的第二个输入参数。为了使所有的槽位都能够被探查到,探查序列<h(k,0), h(k,1),
…, h(k,m-1)>必须是<0, 1, …, m-1>的一个排列。有三种技术常用来计算开放寻址法中的探查序列:线性探查、二次探查,以及双重探查。
线性探查(linear probing):使用的散列函数如下:h(k,i) = (h’(k) + i) mod m, i=0, 1, …, m-1
h’为一个普通的散列函数,见前面的介绍。线性探查存在一个称为一次群集的问题,即随着时间的推移,连续被占用的槽不断增加,平均查找时间也随着不断增加。但是,线性探查的优点在于,对m的取值没有特殊的要求。
二次探查(quadratic probing):使用的散列函数如下:h(k,i) = (h’(k) +c1 i + c2 i2) mod m, i=0, 1, …, m-1
为了能够充分利用散列表,c1、c2和m的值要受到限制。一种好的选择是,m为2的某个幂次(m=2p),c1=c2=1/2。二次探查,不会顺序地探查每一个槽位,解决了一次群集问题。但是,如果两个关键字的初始探查位置相同,那么它们的探查序列也是相同的,这一性质导致一种程度较轻的群集现象,称为二次群集。
双重散列(double hashing):使用的散列函数如下:h(k,i) = (h1(k) + i h2(k)) mod m, i=0, 1, …, m-1
为能查找整个散列表,值h2(k)要与表的大小m互质。确保这一条件成立的一种方法是取m为2的幂,并设计一个总能产生奇数的h2。另一种方法是取m为质数,并设计一个总是产生较m小的正整数的h2。例如,可以取m为质数,h2(k)=1+(k mod m’),m’=m-1。
4. 采用乘法散列作为哈希函数以及链接法实现散列表的代码:
#include <iostream>
using namespace std;
#define HASH_CONSTANT 0.6180339
/*********** The struction of Hash node************/
typedef struct hash_node
{
int key ;
struct hash_node *prev ;
struct hash_node *next ;
}hash_node_list;
/*
* @function:create hash table of size
* @return: hash_node_list*
* @parameter:int hash_table_size
*/
hash_node_list* create_hash_table(int hash_table_size)
{
int i ;
hash_node_list* my_hash_table;
my_hash_table = (hash_node_list*)malloc(hash_table_size*sizeof(hash_node_list));
for(i=0 ; i<hash_table_size ; i++)
{
my_hash_table[i].key = 0;
my_hash_table[i].prev = NULL ;
my_hash_table[i].next = NULL ;
}
return my_hash_table;
}
/*
*@function:compute the value of hash by the hash_func
*@parameter:int hash_table_size , int key
*@return: int h(k)
*/
int hash_func(int hash_table_size,int key)
{
return (int)(hash_table_size*((key*HASH_CONSTANT)-(int)(key*HASH_CONSTANT)));
}
/*
*@function: insert a key to the hash table
*@parameter: int hash_table_size ; int key ; hash_node_list* hash_node_list
*@return: void
*/
void hash_table_insert(hash_node_list* hash_node_list,int hash_table_size,int key)
{
int index;
hash_node* node;
index = hash_func(hash_table_size,key);
node = (hash_node*)malloc(sizeof(hash_node_list));
node->key = key ;
node->next = NULL;
node->prev = &hash_node_list[index];
if(node->next!=NULL)
node->next->prev = node;
node->next = hash_node_list[index].next;
hash_node_list[index].next = node ;
}
/*
*@function:search key in hash table
*@parameter:...
*@return: the pointer of searchable node or NULL
*/
hash_node_list* hash_table_search(hash_node_list* hash_node_list,int hash_table_size,int key)
{
int index ;
hash_node* node;
index = hash_func(hash_table_size,key);
node = hash_node_list[index].next;
while(node!=NULL)
{
if(node->key == key)
return node;
node = node->next;
}
return NULL ;
}
/*
*@function:Exit of hash_table
*/
void exit_of_hash_table(hash_node_list* hash_node)
{
hash_node->prev->next = hash_node->next;
if(hash_node->next!=NULL)
hash_node->next->prev = hash_node->prev;
}
/*
*@function: free the hash table
*@parameter: hash_node_list , hash_table_size
*@return: null
*/
void free_hash_node(hash_node_list* hash_node_list , int hash_table_size)
{
int i ;
hash_node* node;
for(i=0 ; i< hash_table_size ; i++)
{
while(hash_node_list[i].next!=NULL)
{
node = hash_node_list[i].next;
exit_of_hash_table(hash_node_list[i].next);
free(node);
node = NULL ;
}
}
free(hash_node_list);
hash_node_list = NULL ;
}
void print_hash_table(hash_node_list* hash_node_list , int hash_table_size)
{
int i ;
hash_node* node ;
printf("Hash Table:");
for(i=0 ; i<hash_table_size ; i++)
{
printf("\nSlot:%d",i);
node = &hash_node_list[i];
while(node->next!=NULL)
{
printf("\n%d ",node->next->key);
node = node->next;
}
}
printf("\n\n");
}
void main()
{
int hash_table_size ;
int key ;
hash_node_list* hash_table;
printf("Please input the size of hash table :\n");
//scanf("%d",&hash_table_size);
cin >> hash_table_size;
hash_table = create_hash_table(hash_table_size);
printf("Please input some values :\n");
//scanf("%d",&key);
cin >> key;
while(key!=0)
{
hash_table_insert(hash_table,hash_table_size,key);
//scanf("%d",&key);
cin >> key ;
}
print_hash_table(hash_table,hash_table_size);
free_hash_node(hash_table,hash_table_size);
system("pause");
}运行结果:
5. 采用乘法散列作为哈希函数和线性探测作为碰撞检测实现的散列表:
#include <iostream>
using namespace std;
#define NIL -1
#define HASH_CONSTANT 0.6180339
/*
* 创建线性探测哈希表
*/
int* create_probe_hash_table(int hash_table_size)
{
int* hash_table ;
int i ;
hash_table = (int*)malloc(hash_table_size*sizeof(int));
for(i=0 ; i<hash_table_size ; i++)
hash_table[i] = NIL ;
return hash_table ;
}
void free_hash_probe_table(int* hash_table)
{
free(hash_table);
}
int inner_hash_probe_func(int hash_table_size , int key)
{
return (int)(hash_table_size*((key*HASH_CONSTANT)-(int)(key*HASH_CONSTANT))) ;
}
int hash_probe_func(int hash_table_size , int key , int index)
{
return (key + index) % hash_table_size ;
}
int probe_hash_table_insert(int* hash_table , int hash_table_size , int key)
{
int pos ;
int i ;
int ppos ;
pos = inner_hash_probe_func(hash_table_size,key);
for(i = 0 ; i<hash_table_size ; i++)
{
ppos = hash_probe_func(hash_table_size , pos , i);
if(hash_table[ppos] == NIL)
{
hash_table[ppos] = key ;
return ppos;
}
}
cout << "Hash Table Overflow ..." <<endl ;
}
int probe_hash_table_search(int* hash_table , int hash_table_size , int key)
{
int pos ;
int i ;
int ppos ;
pos = inner_hash_probe_func(hash_table_size , key);
for(i = 0 ; i<hash_table_size ; i++)
{
ppos = hash_probe_func(hash_table_size , pos , i);
if(hash_table[ppos] == NIL)
{
break ;
}
if(hash_table[ppos] == key)
{
return ppos;
}
}
cout << "This key not found ..." << endl ;
return NIL ;
}
void probe_hash_table_delete(int* hash_table , int hash_table_size , int key)
{
int pos ;
pos = probe_hash_table_search(hash_table , hash_table_size , key);
if(hash_table[pos]!=NIL)
hash_table[pos] = NIL ;
}
void print_probe_hash_table(int* hash_table , int hash_table_size)
{
int i ;
cout << "Probe Hash Table : \n" << endl ;
for(i=0 ; i<hash_table_size ; i++)
cout << "Slot : " << i << "--->" << hash_table[i] << endl ;
}
void main()
{
int* hash_table;
int hash_table_size ;
int key ;
cout << "Please input the size of probe hash table :" << endl ;
cin >> hash_table_size ;
hash_table = create_probe_hash_table(hash_table_size);
cout << "Please input the key and finish by 0 :" << endl ;
cin >> key ;
while(key != 0 )
{
probe_hash_table_insert(hash_table , hash_table_size , key);
cin >> key ;
}
print_probe_hash_table(hash_table , hash_table_size);
free_hash_probe_table(hash_table);
system("pause");
}运行结果:
6. 参考链接:http://blog.csdn.net/intrepyd/article/details/4359818
坚持每天的学习,加油!!

相关文章推荐
- 散列表(算法导论笔记)
- 算法导论 第三部分——基本数据结构——栈、队列、链表、散列表
- 【算法导论】十一章散列表11.1-4大数组实现直接寻址方式的字典操作
- 算法导论学习笔记-第十一章-散列表
- 算法导论11.2散列表Hash tables链式法解决碰撞11.3.1除法散列法
- 算法导论原理分析系列5:第11章 散列表
- 算法导论笔记:11散列表(哈希表)
- 【算法导论】散列表
- 【算法导论】第11章散列表
- 【算法导论】学习笔记——第11章 散列表
- 算法导论-归并排序
- 【算法导论】有向图的深度优先搜索遍历
- 【算法导论33】跳跃表(Skip list)原理与java实现
- 【算法导论】第二章 算法入门 重点摘要
- 推荐引擎算法学习导论
- 【算法导论】单源最短路径之Bellman-Ford算法
- 算法导论—快排及优化以及和STL sort 的比较
- 算法导论-第24章- 单源最短路径 - 24.3 Dijkstra 算法