今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
2013-05-24 12:27
411 查看
原创书写,转载请注明此文出自:http://blog.csdn.net/xbinworld,Bin的专栏
今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
前面有朋友说写的东西太理论了,我想说我并不是在和很多其他博客一样做topic的入门介绍,配合很多示意图之类;而是在记录PRML这本经典教科书的内容。如果想好好学Pattern Recognition and Machine Learning,建议花半年时间看一本国外经典。(前面忙实验室的任务写的太慢了,这本书要吃透是要花点时间。)章节1.3-1.5都是介绍性质的,我先不写了后面有时间再补。
信息论,不用多说,在很多领域都得到了应用,应该算是一个相对成熟的主题。PRML这一节里将介绍信息论的一些基本概念,主要是为了明白这些概念是怎么来的(如gain,entropy),代表什么含义。在书里没有具体的应用结合,后面可以单独简介一节关于决策树的方法,需要的信息论知识基本在这一节里面可以覆盖到。
章节1.6 Information Theory
直观的一种理解,当我们听到一个不太可能发生的事件时我们所接收的信息量要比听到一件习以为常的事件所接收的信息量大,如果我们听到了一件必然发生的事情那么我们接收到的信息就是0。让我们考察对于一个离散随机变量x,类似的出现那些概率很低的x取值时我们得到的信息量要大。
通过上面的解释,首先,我们有理由认为信息量的大小和随机变量x的概率有关,我们用h(x)表示获得的信息量的大小,p(x)表示离散随机变量x取值的概率。我们相信h(x)和p(x)是单调负相关的(一个大另一个就小)。
再来考察这样一个情况,如果观察两个相互无关(独立)的事件x,y,我们得到的信息量可以写成:
h(x,y) = h(x)+h(y);
而两个相互独立事件的概率符合:
P(x,y) = p(x)*p(y);
由此可见啊,h应当和p成对数(log)关系,于是,我们结合上述两点观察,得出

可见,信息量是大于等于0的。这里我们先用2为对数的底,此时,h的单位是bits。(信息量大小由比特长度来衡量。)
好了,让我们考虑这样一个情况,一个信息发送者要发送一个随机变量的值给一个接收者,那么在传输过程中的平均信息量是(1.92)的h(x)的期望:

该值就称为一个随机变量的熵(Entropy),特别的,当p等于0的时候,p(x)logp(x)=0。接下来让我们看一个实际的例子,来体会一下熵这个概念:
========================================================================
例子:假如一个随机变量x有8种可能的状态,每一种都有相同的概率。传输该变量我们至少需要3个bits(2^3=8),或者我们可以用熵来刻画:

同样是3个bits,即平均信息量为3 bits,或者说我们平均需要3bits来传输。
考虑另外一种情况,如果x的8个状态(a-h)的概率分别为

,那么,熵为:

也就是说,不均匀分布的变量拥有较小的熵。在这个情况下,我们怎么才能做到平均2bits来传输呢?因为不均匀分布,我们可以用短bit来代表大概率的状态,长bit来代表小概率的状态,把上述8个状态编码成0, 10, 110, 1110, 111100, 111101, 111110, 111111,这个时候,平均的编码长度就是:

可见,我们可以用平均2bits长来传输变量x,和熵是等价的。
========================================================================
香农提出了noiseless coding theorem:熵是传输一个随机变量(所有状态or取值)所需编码长度的下限。(似乎很牛逼的样子- -)
上面我们是用2为log的底来考量的,接下来为了一些计算的方便,我们使用自然对数e为底来考虑熵。当用ln的时候,熵的单位是nats,很容易证明nats和bits相差一个常数倍数ln2。 Nat = ln2 Bit
随机变量X的熵可以定义为:

其中xi是X的一种取值(状态)。对于那些更sharp分布的变量,有较小的熵;而那些均匀分布的变量有较大的熵,图1.30说明了这个情况:

上面都考虑了离散变量的情况,接下来我们考虑连续变量的情况:
变量X取值落在一个小区段内的概率是:

上面用到了均值定理,在一个很小的区段(bin)里面(长度为

),总能找到一个xi使得上述等式成立。因此概率就用(1.101)的右边来表示了,这样就离散化了。类似前面熵的定义:

可见,离散变量的熵和连续变量的熵在定义上相差一个

,当

很小的时候,该项很大,因此得到符合常识的结论是:当我们需要很精细地刻画一个连续变量时,我们需要很长的bits。
根据

我们定义

为微分熵。相应的结论是,使得微分熵最大化的分布是高斯分布。微分熵是可以小于0的。
根据定义可以计算高斯分布的微分熵可以写成

当方差越大的时候,微分熵越大。
1.6.1 相对熵和互信息
相对熵也就是KL-divergence, 很多地方都有看到KL。它的含义是什么呢?下面来解释一下:对于一个未知的分布p(x),我们用q(x)来model它,那么我们需要的平均额外的信息量
是

上述式子很容易理解,就是两者平均需要信息量的差,定义为KL-divergence。KL-divergence是不对称的。
上述式子中的两个期望的表达也可用离散的形式去估计,就是用一个集合的平均值。另外,我们可以假设我们估计的分布q是受一些参数影响的,那么KL-D可以近似写成

其中求平均的常熟系数被略去了。因此可以看到,(1.119)的第二项是和theta无关的,不变的。那么最小化KL其实就等价于最大化似然方程了。
我们知道如果两个变量x,y独立,那么p(x,y) = p(x)p(y)。我们希望衡量两个变量相互独立的程度,就用到互信息了。互信息的定义是这样的:

从定义就很容易想到,互信息是在衡量联合p(x,y) 和p(x)p(y)相关性。可以知道,I是大于等于0的,且当x,y独立时取0.
今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
前面有朋友说写的东西太理论了,我想说我并不是在和很多其他博客一样做topic的入门介绍,配合很多示意图之类;而是在记录PRML这本经典教科书的内容。如果想好好学Pattern Recognition and Machine Learning,建议花半年时间看一本国外经典。(前面忙实验室的任务写的太慢了,这本书要吃透是要花点时间。)章节1.3-1.5都是介绍性质的,我先不写了后面有时间再补。
信息论,不用多说,在很多领域都得到了应用,应该算是一个相对成熟的主题。PRML这一节里将介绍信息论的一些基本概念,主要是为了明白这些概念是怎么来的(如gain,entropy),代表什么含义。在书里没有具体的应用结合,后面可以单独简介一节关于决策树的方法,需要的信息论知识基本在这一节里面可以覆盖到。
章节1.6 Information Theory
直观的一种理解,当我们听到一个不太可能发生的事件时我们所接收的信息量要比听到一件习以为常的事件所接收的信息量大,如果我们听到了一件必然发生的事情那么我们接收到的信息就是0。让我们考察对于一个离散随机变量x,类似的出现那些概率很低的x取值时我们得到的信息量要大。
通过上面的解释,首先,我们有理由认为信息量的大小和随机变量x的概率有关,我们用h(x)表示获得的信息量的大小,p(x)表示离散随机变量x取值的概率。我们相信h(x)和p(x)是单调负相关的(一个大另一个就小)。
再来考察这样一个情况,如果观察两个相互无关(独立)的事件x,y,我们得到的信息量可以写成:
h(x,y) = h(x)+h(y);
而两个相互独立事件的概率符合:
P(x,y) = p(x)*p(y);
由此可见啊,h应当和p成对数(log)关系,于是,我们结合上述两点观察,得出

可见,信息量是大于等于0的。这里我们先用2为对数的底,此时,h的单位是bits。(信息量大小由比特长度来衡量。)
好了,让我们考虑这样一个情况,一个信息发送者要发送一个随机变量的值给一个接收者,那么在传输过程中的平均信息量是(1.92)的h(x)的期望:
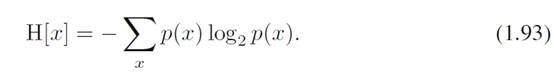
该值就称为一个随机变量的熵(Entropy),特别的,当p等于0的时候,p(x)logp(x)=0。接下来让我们看一个实际的例子,来体会一下熵这个概念:
========================================================================
例子:假如一个随机变量x有8种可能的状态,每一种都有相同的概率。传输该变量我们至少需要3个bits(2^3=8),或者我们可以用熵来刻画:
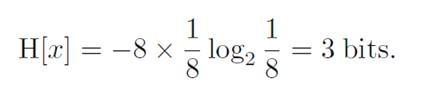
同样是3个bits,即平均信息量为3 bits,或者说我们平均需要3bits来传输。
考虑另外一种情况,如果x的8个状态(a-h)的概率分别为
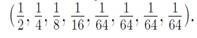
,那么,熵为:
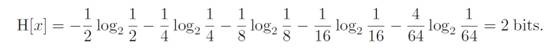
也就是说,不均匀分布的变量拥有较小的熵。在这个情况下,我们怎么才能做到平均2bits来传输呢?因为不均匀分布,我们可以用短bit来代表大概率的状态,长bit来代表小概率的状态,把上述8个状态编码成0, 10, 110, 1110, 111100, 111101, 111110, 111111,这个时候,平均的编码长度就是:

可见,我们可以用平均2bits长来传输变量x,和熵是等价的。
========================================================================
香农提出了noiseless coding theorem:熵是传输一个随机变量(所有状态or取值)所需编码长度的下限。(似乎很牛逼的样子- -)
上面我们是用2为log的底来考量的,接下来为了一些计算的方便,我们使用自然对数e为底来考虑熵。当用ln的时候,熵的单位是nats,很容易证明nats和bits相差一个常数倍数ln2。 Nat = ln2 Bit
随机变量X的熵可以定义为:

其中xi是X的一种取值(状态)。对于那些更sharp分布的变量,有较小的熵;而那些均匀分布的变量有较大的熵,图1.30说明了这个情况:

上面都考虑了离散变量的情况,接下来我们考虑连续变量的情况:
变量X取值落在一个小区段内的概率是:
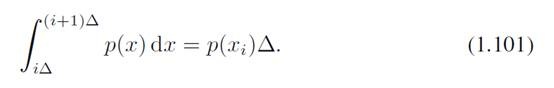
上面用到了均值定理,在一个很小的区段(bin)里面(长度为
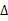
),总能找到一个xi使得上述等式成立。因此概率就用(1.101)的右边来表示了,这样就离散化了。类似前面熵的定义:

可见,离散变量的熵和连续变量的熵在定义上相差一个
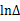
,当
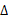
很小的时候,该项很大,因此得到符合常识的结论是:当我们需要很精细地刻画一个连续变量时,我们需要很长的bits。
根据

我们定义
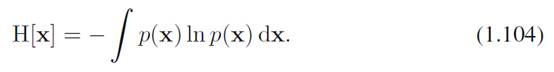
为微分熵。相应的结论是,使得微分熵最大化的分布是高斯分布。微分熵是可以小于0的。
根据定义可以计算高斯分布的微分熵可以写成
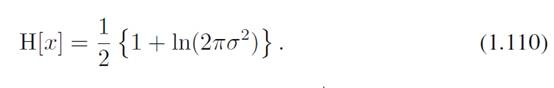
当方差越大的时候,微分熵越大。
1.6.1 相对熵和互信息
相对熵也就是KL-divergence, 很多地方都有看到KL。它的含义是什么呢?下面来解释一下:对于一个未知的分布p(x),我们用q(x)来model它,那么我们需要的平均额外的信息量
是

上述式子很容易理解,就是两者平均需要信息量的差,定义为KL-divergence。KL-divergence是不对称的。
上述式子中的两个期望的表达也可用离散的形式去估计,就是用一个集合的平均值。另外,我们可以假设我们估计的分布q是受一些参数影响的,那么KL-D可以近似写成

其中求平均的常熟系数被略去了。因此可以看到,(1.119)的第二项是和theta无关的,不变的。那么最小化KL其实就等价于最大化似然方程了。
我们知道如果两个变量x,y独立,那么p(x,y) = p(x)p(y)。我们希望衡量两个变量相互独立的程度,就用到互信息了。互信息的定义是这样的:
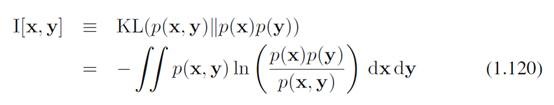
从定义就很容易想到,互信息是在衡量联合p(x,y) 和p(x)p(y)相关性。可以知道,I是大于等于0的,且当x,y独立时取0.

相关文章推荐
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML)书,章节1.2,Probability Theory (上)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML)书,章节1.2,Probability Theory (上)
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML)书,章节1.2,Probability Theory (上)
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.1,介绍与多项式曲线拟合(Polynomial Curve Fitting)
- 今天开始学Pattern Recognition and Machine Learning (PRML)书,章节1.2,Probability Theory (上)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节1.2,Probability Theory (下)
- 今天开始学习模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节5.1,Neural Networks神经网络-前向网络。
- 今天开始学Pattern Recognition and Machine Learning (PRML) ,章节1.1,介绍与多项式曲线拟合(Polynomial Curve Fitting)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节1.2,Probability Theory (下)
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.2,Probability Theory (下)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节1.2,Probability Theory (下)
- 今天开始学Pattern Recognition and Machine Learning (PRML)书,章节1.2,Probability Theory 概率论(上)
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.2,Probability Theory (下)
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)