我的Java开发学习之旅------>Java字符编码解析
2013-05-11 14:49
387 查看
Java开发中,常常会遇到乱码的问题,一旦遇到这种问题,常常就很扯蛋,每个人都不愿意承认是自己的代码有问题。其实编码问题并没有那么神秘,那么不可捉摸,搞清Java的编码本质过程就真相大白了。

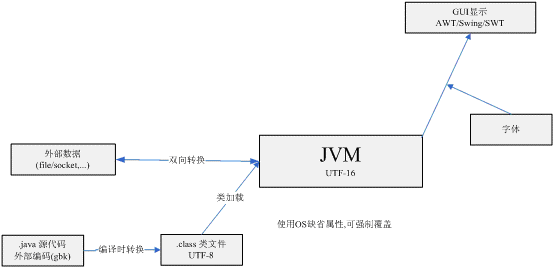
其实,编码问题存在两个方面:JVM之内和JVM之外。
1、Java文件编译后形成class
这里Java文件的编码可能有多种多样,但Java编译器会自动将这些编码按照Java文件的编码格式正确读取后产生class文件,这里的class文件编码是Unicode编码(具体说是UTF-16编码)。
因此,在Java代码中定义一个字符串:
String s="汉字";
不管在编译前java文件使用何种编码,在编译后成class后,他们都是一样的----Unicode编码表示。
2、JVM中的编码
JVM加载class文件读取时候使用Unicode编码方式正确读取class文件,那么原来定义的String s="汉字";在内存中的表现形式是Unicode编码。
当调用String.getBytes()的时候,其实已经为乱码买下了祸根。因为此方法使用平台默认的字符集来获取字符串对应的字节数组。在WindowsXP中文版中,使用的默认编码是GBK,不信运行下:
运行结果如下:
当不同的系统、数据库经过多次编码后,如果对其中的原理不理解,就容易导致乱码。因此,在一个系统中,有必要对字符串的编码做一个统一,这个统一模糊点说,就是对外统一。比如方法字符串参数,IO流,在中文系统中,可以统一使用GBK、GB13080、UTF-8、UTF-16等等都可以,只是要选择有些更大字符集,以保证任何可能用到的字符都可以正常显示,避免乱码的问题。(假设对所有的文件都用ASCII码)那么就无法实现双向转换了。
要特别注意的是,UTF-8并非能容纳了所有的中文字符集编码,因此,在特殊情况下,UTF-8转GB18030可能会出现乱码,然而一群傻B常常在做中文系统喜欢用UTF-8编码而不说不出个所以然出来!最傻B的是,一个系统多个人做,源代码文件有的人用GBK编码,有人用UTF-8,还有人用GB18030。FK,都是中国人,也不是外包项目,用什么UTF-8啊,神经!源代码统统都用GBK18030就OK了,免得ANT脚本编译时候提示不可认的字符编码。
因此,对于中文系统来说,最好选择GBK或GB18030编码(其实GBK是GB18030的子集),以便最大限度的避免乱码现象。
3、内存中字符串的编码
内存中的字符串不仅仅局限于从class代码中直接加载而来的字符串,还有一些字符串是从文本文件中读取的,还有的是通过数据库读取的,还有可能是从字节数组构建的,然而他们基本上都不是Unicode编码的,原因很简单,存储优化。
因此就需要处理各种各样的编码问题,在处理之前,必须明确“源”的编码,然后用指定的编码方式正确读取到内存中。如果是一个方法的参数,实际上必须明确该字符串参数的编码,因为这个参数可能是另外一个日文系统传递过来的。当明确了字符串编码时候,就可以按照要求正确处理字符串,以避免乱码。
在对字符串进行解码编码的时候,应该调用下面的方法:
(以上内容引用自:http://lavasoft.blog.51cto.com/62575/273608)
Java中文&编码问题小结
user.language,user.region,file.encoding等。 可以使用System.getProperties()详细查看所有的系统属性。
如在英文操作系统(如UNIX)下,可以使用如下属性定义强制指定JVM为中文环境 -Dclient.encoding.override=GBK
-Dfile.encoding=GBK -Duser.language=zh -Duser.region=CN
错误可能:
1 gbk编码源文件在英文环境下编译,javac不能正确转换.曾见于java/jsp在英文unix下. 检测方法:写\u4e00格式的汉字,绕开javac编码,再在jvm中,将汉字作为int打印,看值是否相等;或直接以UTF-8编码打开.class文件,看看常量字符串是否正确保存汉字。
1 文件读写转换由java.io.Reader/Writer执行;输入输出流 InputStream/OutputStream 处理汉字不合适,应该首选使用Reader/Writer,如FileReader/FileWriter。
2 FileReader/FileWriter使用JVM当前编码读写文件.如果有其它编码格式,使用InputStreamReader/OutputStreamWriter
3 PrintStream有点特殊,它自动使用jvm缺省编码进行转换。
–encoding GBK inputfile outputfile
2 javax.xml.SAXParser类接受InputStream作为输入参数,对于Reader,需要用org.xml.sax.InputSource包装一下,再给SAXParser。
3 对于UTF-8编码 XML,注意防止编辑器自动加上\uFFFE BOM头,
xml parser会报告content is not allowed in prolog。
text = new String( text.getBytes(“iso8859-1”),”gbk”);
1 对于ORACLE数据库,需要数据库创建时指定编码方式为gbk,否则会出现汉字转码错误
2 对于SQLServer 2000,最好以nvarchar/nchar类型存放文本,即不存在中文/编码转换问题。
3 连接 Mysql,将 connectionString 设置成 encoding 为 gb2312:
String connectionString = "jdbc:mysql://localhost/test?useUnicode=true&characterEncoding=gb2312";
2 对于Servlet,确定 设置setContentType (“text/html; charset=gb2312”),以上两条用于使得输出汉字没有问题。
3 为输出HTML head中加一个 <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> ,让浏览器正确确定HTML编码。
4 为Web应用加一个Filter,确保每个Request明确调用setCharacterEncoding方法,让输入汉字能够正确解析。
web.xml中加入:
5 用于Weblogic(vedor-specific):
其一:在web.xml里加上如下脚本:
其二(可选)在weblogic.xml里加上如下脚本:
, 需要检查是否映射缺省字体到中文字体如宋体。
在Swing中,Java自行解释TTF字体,渲染显示;对于AWT,SWT显示部分交由操作系统。首先需要确定系统装有中文字体。
1 汉字显示为”□”,一般为显示字体没有使用中文字体,因为Java对于当前字体显示不了的字符,不会像Windows一样再采用缺省字体显示。
2 部分不常见汉字不能显示,一般为显示字库中汉字不全,可以换另外的中文字体试试。
3 对于AWT/SWT,首先确定JVM运行环境的区域设置为中文,因为此处设计JVM与操作系统api调用的转换问题,再检查其它问题。
这里从SUN jdk 1.4 源代码中找到一段使用jvm String 对象的getBytes的转换方式,相对简单和跨平台,不需要第三方库,但速度稍慢。函数原型如下:
附件jni_util.h,jni_util.c
TUXEDO/JOLT
JOLT对于传递的字符串需要用如下进行转码
new String(ls_tt.getBytes("GBK"),"iso8859-1")
对于返回的字符串
new String(error_message.getBytes("iso8859-1"),"GBK");
jolt 的系统属性 bea.jolt.encoding不应该设置,如果设置,JSH会报告说错误的协议.
常用功能:
1 列出jvm所支持字符集:Charset.availableCharsets()
2 能否对看某个Unicode字符编码,CharsetEncoder.canEncode()
EXT B区汉字,范围大于\U20000,则需要采用2个char方能表示,此即Unicode Surrogate。这2个char的值范围 落在Character.SURROGATE 区域内,用Character.getType()来判断。
jdk 1.4尚不能在Swing中正确处理surrogate区的Unicode字符,jdk1.5可以。对于CJK
EXT B区汉字,目前可以使用的字库为”宋体-方正超大字符集”,随Office安装。
即gbk文本à(iso8859-1转码)àjvm char(iso8859-1编码汉字)à (iso8859-1转码)à输出。
gbk汉字经过两次错误转码,原封不动的被传递到输出,但是在jvm中,并未以正确的unicode编码表示,而是以一个汉字字节一个char的方式表示,从而导致此类错误。
GB2312-80 是在国内计算机汉字信息技术发展初始阶段制定的,其中包含了大部分常用的一、二级汉字,和 9 区的符号。该字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,这也是最基本的中文字符集。其编码范围是高位0xa1-0xfe,低位也是 0xa1-0xfe;汉字从 0xb0a1 开始,结束于 0xf7fe;
GBK 是 GB2312-80 的扩展,是向上兼容的。它包含了 20902 个汉字,其编码范围是 0x8140-0xfefe,剔除高位 0x80 的字位。其所有字符都可以一对一映射到 Unicode
2.0,也就是说 JAVA 实际上提供了 GBK 字符集的支持。这是现阶段 Windows 和其它一些中文操作系统的缺省字符集,但并不是所有的国际化软件都支持该字符集,感觉是他们并不完全知道 GBK 是怎么回事。值得注意的是它不是国家标准,而只是规范。随着 GB18030-2000国标的发布,它将在不久的将来完成它的历史使命。
GB18030-2000(GBK2K) 在 GBK 的基础上进一步扩展了汉字,增加了藏、蒙等少数民族的字形。GBK2K 从根本上解决了字位不够,字形不足的问题。它有几个特点,
它并没有确定所有的字形,只是规定了编码范围,留待以后扩充。
编码是变长的,其二字节部分与 GBK 兼容;四字节部分是扩充的字形、字位,其编码范围是首字节 0x81-0xfe、二字节0x30-0x39、三字节 0x81-0xfe、四字节0x30-0x39。
UTF,即Unicode Transformer Format,是Unicode代码点(code point)的实际表示方式,按其基本长度所用位数分为UTF-8/16/32。它也可以认为是一种特殊的外部数据编码,但能够与Unicode代码点做一一对应。
UTF-8是变长编码,每个Unicode代码点按照不同范围,可以有1-3字节的不同长度。
UTF-16长度相对固定,只要不处理大于\U200000范围的字符,每个Unicode代码点使用16位即2字节表示,超出部分使用两个UTF-16即4字节表示。按照高低位字节顺序,又分为UTF-16BE/UTF-16LE。
UTF-32长度始终固定,每个Unicode代码点使用32位即4字节表示。按照高低位字节顺序,又分为UTF-32BE/UTF-32LE。
UTF编码有个优点,即尽管编码字节数不等,但是不像gb2312/gbk编码一样,需要从文本开始寻找,才能正确对汉字进行定位。在UTF编码下,根据相对固定的算法,从当前位置就能够知道当前字节是否是一个代码点的开始还是结束,从而相对简单的进行字符定位。不过定位问题最简单的还是UTF-32,它根本不需要进行字符定位,但是相对的大小也增加不少。
(以上内容引自:http://www.blogjava.net/zhugf000/archive/2005/10/09/15068.html)
最后写一个java程序来实现java转换字符串编码
运行结果为:
------------------------------------------------------------------------------------------------------------------
java中的String类是按照unicode进行编码的,当使用String(byte[] bytes, String encoding)构造字符串时,encoding所指的是bytes中的数据是按照那种方式编码的,而不是最后产生的String是什么编码方式,换句话说,是让系统把bytes中的数据由encoding编码方式转换成unicode编码。如果不指明,bytes的编码方式将由jdk根据操作系统决定。
当我们从文件中读数据时,最好使用InputStream方式,然后采用String(byte[] bytes, String encoding)指明文件的编码方式。不要使用Reader方式,因为Reader方式会自动根据jdk指明的编码方式把文件内容转换成unicode编码。
当我们从数据库中读文本数据时,采用ResultSet.getBytes()方法取得字节数组,同样采用带编码方式的字符串构造方法即可。
ResultSet rs;
bytep[] bytes = rs.getBytes();
String str = new String(bytes, "gb2312");
不要采取下面的步骤。
ResultSet rs;
String str = rs.getString();
str = new String(str.getBytes("iso8859-1"), "gb2312");
这种编码转换方式效率底。之所以这么做的原因是,ResultSet在getString()方法执行时,默认数据库里的数据编码方式为iso8859-1。系统会把数据依照iso8859-1的编码方式转换成unicode。使用str.getBytes("iso8859-1")把数据还原,然后利用new String(bytes, "gb2312")把数据从gb2312转换成unicode,中间多了好多步骤。
从HttpRequest中读参数时,利用reqeust.setCharacterEncoding()方法设置编码方式,读出的内容就是正确的了。
附注:给一篇介绍java字符的文章 点击下载
==================================================================================================
作者:欧阳鹏 欢迎转载,与人分享是进步的源泉!
转载请保留原文地址:http://blog.csdn.net/ouyang_peng
==================================================================================================
其实,编码问题存在两个方面:JVM之内和JVM之外。
1、Java文件编译后形成class
这里Java文件的编码可能有多种多样,但Java编译器会自动将这些编码按照Java文件的编码格式正确读取后产生class文件,这里的class文件编码是Unicode编码(具体说是UTF-16编码)。
因此,在Java代码中定义一个字符串:
String s="汉字";
不管在编译前java文件使用何种编码,在编译后成class后,他们都是一样的----Unicode编码表示。
2、JVM中的编码
JVM加载class文件读取时候使用Unicode编码方式正确读取class文件,那么原来定义的String s="汉字";在内存中的表现形式是Unicode编码。
当调用String.getBytes()的时候,其实已经为乱码买下了祸根。因为此方法使用平台默认的字符集来获取字符串对应的字节数组。在WindowsXP中文版中,使用的默认编码是GBK,不信运行下:
public class Test {
public static void main(String[] args) {
System.out.println("当前JRE:" + System.getProperty("java.version"));
System.out.println("当前JVM的默认字符集:" + Charset.defaultCharset());
}
}运行结果如下:
当前JRE:1.6.0_10-rc2 当前JVM的默认字符集:GBK
当不同的系统、数据库经过多次编码后,如果对其中的原理不理解,就容易导致乱码。因此,在一个系统中,有必要对字符串的编码做一个统一,这个统一模糊点说,就是对外统一。比如方法字符串参数,IO流,在中文系统中,可以统一使用GBK、GB13080、UTF-8、UTF-16等等都可以,只是要选择有些更大字符集,以保证任何可能用到的字符都可以正常显示,避免乱码的问题。(假设对所有的文件都用ASCII码)那么就无法实现双向转换了。
要特别注意的是,UTF-8并非能容纳了所有的中文字符集编码,因此,在特殊情况下,UTF-8转GB18030可能会出现乱码,然而一群傻B常常在做中文系统喜欢用UTF-8编码而不说不出个所以然出来!最傻B的是,一个系统多个人做,源代码文件有的人用GBK编码,有人用UTF-8,还有人用GB18030。FK,都是中国人,也不是外包项目,用什么UTF-8啊,神经!源代码统统都用GBK18030就OK了,免得ANT脚本编译时候提示不可认的字符编码。
因此,对于中文系统来说,最好选择GBK或GB18030编码(其实GBK是GB18030的子集),以便最大限度的避免乱码现象。
3、内存中字符串的编码
内存中的字符串不仅仅局限于从class代码中直接加载而来的字符串,还有一些字符串是从文本文件中读取的,还有的是通过数据库读取的,还有可能是从字节数组构建的,然而他们基本上都不是Unicode编码的,原因很简单,存储优化。
因此就需要处理各种各样的编码问题,在处理之前,必须明确“源”的编码,然后用指定的编码方式正确读取到内存中。如果是一个方法的参数,实际上必须明确该字符串参数的编码,因为这个参数可能是另外一个日文系统传递过来的。当明确了字符串编码时候,就可以按照要求正确处理字符串,以避免乱码。
在对字符串进行解码编码的时候,应该调用下面的方法:
getBytes(String charsetName) String(byte[] bytes, String charsetName)而不要使用那些不带字符集名称的方法签名,通过上面两个方法,可以对内存中的字符进行重新编码
(以上内容引用自:http://lavasoft.blog.51cto.com/62575/273608)
Java中文&编码问题小结
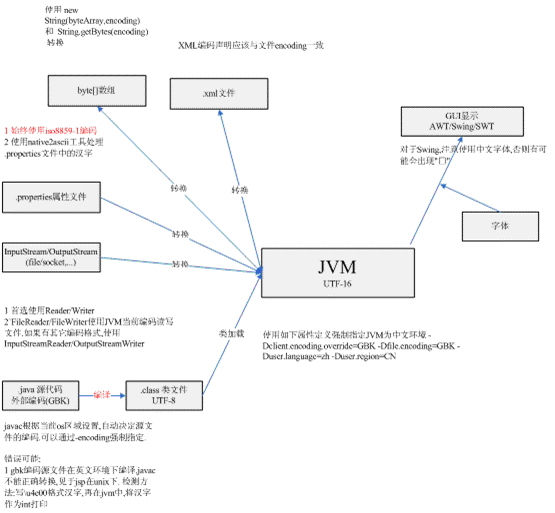
Java字符编码转换过程说明
常见问题
JVM
JVM启动后,JVM会设置一些系统属性以表明JVM的缺省区域。user.language,user.region,file.encoding等。 可以使用System.getProperties()详细查看所有的系统属性。
如在英文操作系统(如UNIX)下,可以使用如下属性定义强制指定JVM为中文环境 -Dclient.encoding.override=GBK
-Dfile.encoding=GBK -Duser.language=zh -Duser.region=CN
.java-->.class编译
说明:一般javac根据当前os区域设置,自动决定源文件的编码.可以通过-encoding强制指定.错误可能:
1 gbk编码源文件在英文环境下编译,javac不能正确转换.曾见于java/jsp在英文unix下. 检测方法:写\u4e00格式的汉字,绕开javac编码,再在jvm中,将汉字作为int打印,看值是否相等;或直接以UTF-8编码打开.class文件,看看常量字符串是否正确保存汉字。
文件读写
外部数据如文件经过读写和转换两个步骤,转为jvm所使用字符。InputStream/OutputStream用于读写原始外部数据,Reader/Writer执行读写和转换两个步骤。1 文件读写转换由java.io.Reader/Writer执行;输入输出流 InputStream/OutputStream 处理汉字不合适,应该首选使用Reader/Writer,如FileReader/FileWriter。
2 FileReader/FileWriter使用JVM当前编码读写文件.如果有其它编码格式,使用InputStreamReader/OutputStreamWriter
3 PrintStream有点特殊,它自动使用jvm缺省编码进行转换。
读取.properties文件
.propeties文件由Properties类以iso8859-1编码读取,因此不能在其中直接写汉字,需要使用JDK 的native2ascii工具转换汉字为\uXXXX格式。命令行:native2ascii–encoding GBK inputfile outputfile
读取XML文件
1 XML文件读写同于文件读写,但应注意确保XML头中声明如<? xml version=”1.0” encoding=”gb2312” ?>与文件编码保持一致。2 javax.xml.SAXParser类接受InputStream作为输入参数,对于Reader,需要用org.xml.sax.InputSource包装一下,再给SAXParser。
3 对于UTF-8编码 XML,注意防止编辑器自动加上\uFFFE BOM头,
xml parser会报告content is not allowed in prolog。
字节数组
1 使用 new String(byteArray,encoding) 和 String.getBytes(encoding) 在字节数组和字符串之间进行转换也可以用ByteArrayInputStream/ByteArrayOutputStream转为流后再用InputStreamReader/OutputStreamWriter转换。错误编码的字符串(iso8859-1转码gbk)
如果我们得到的字符串是由错误的转码方式产生的,例如:对于gbk中文,由iso8859-1方式转换,此时如果用调试器看到的字符串一般是的样子,长度一般为文本的字节长度,而非汉字个数。可以采用如下方式转为正确的中文:text = new String( text.getBytes(“iso8859-1”),”gbk”);
JDBC
转换过程由JDBC Driver执行,取决于各JDBC数据库实现。对此经验尚积累不够。1 对于ORACLE数据库,需要数据库创建时指定编码方式为gbk,否则会出现汉字转码错误
2 对于SQLServer 2000,最好以nvarchar/nchar类型存放文本,即不存在中文/编码转换问题。
3 连接 Mysql,将 connectionString 设置成 encoding 为 gb2312:
String connectionString = "jdbc:mysql://localhost/test?useUnicode=true&characterEncoding=gb2312";
WEB/Servlet/JSP
1 对于JSP,确定头部加上 <%@ page contentType="text/html;charset=gb2312"%>这样的标签。2 对于Servlet,确定 设置setContentType (“text/html; charset=gb2312”),以上两条用于使得输出汉字没有问题。
3 为输出HTML head中加一个 <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> ,让浏览器正确确定HTML编码。
4 为Web应用加一个Filter,确保每个Request明确调用setCharacterEncoding方法,让输入汉字能够正确解析。
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.UnavailableException;
import javax.servlet.http.HttpServletRequest;
/**
* Example filter that sets the character encoding to be used in parsing the
* incoming request
*/
public class SetCharacterEncodingFilter
implements Filter {
public SetCharacterEncodingFilter()
{}
protected boolean debug = false;
protected String encoding = null;
protected FilterConfig filterConfig = null;
public void destroy() {
this.encoding = null;
this.filterConfig = null;
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
// if (request.getCharacterEncoding() == null)
// {
// String encoding = getEncoding();
// if (encoding != null)
// request.setCharacterEncoding(encoding);
//
// }
request.setCharacterEncoding(encoding);
if ( debug ){
System.out.println( ((HttpServletRequest)request).getRequestURI()+"setted to "+encoding );
}
chain.doFilter(request, response);
}
public void init(FilterConfig filterConfig) throws ServletException {
this.filterConfig = filterConfig;
this.encoding = filterConfig.getInitParameter("encoding");
this.debug = "true".equalsIgnoreCase( filterConfig.getInitParameter("debug") );
}
protected String getEncoding() {
return (this.encoding);
}
}web.xml中加入:
<filter> <filter-name>LocalEncodingFilter</filter-name> <display-name>LocalEncodingFilter</display-name> <filter-class>com.ccb.ectipmanager.request.SetCharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>gb2312</param-value> </init-param> <init-param> <param-name>debug</param-name> <param-value>false</param-value> </init-param> </filter> <filter-mapping> <filter-name>LocalEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
5 用于Weblogic(vedor-specific):
其一:在web.xml里加上如下脚本:
<context-param> <param-name>weblogic.httpd.inputCharset./*</param-name> <param-value>GBK</param-value> </context-param>
其二(可选)在weblogic.xml里加上如下脚本:
<charset-params> <input-charset> <resource-path>/*</resource-path> <java-charset-name>GBK</java-charset-name> </input-charset> </charset-params>
SWING/AWT/SWT
对于SWING/AWT,Java会有些缺省字体如Dialog/San Serif,这些字体到系统真实字体的映射在$JRE_HOME/lib/font.properties.XXX文件中指定。排除字体显示问题时,首先需要确定JVM的区域为zh_CN,这样font.properties.zh_CN文件才会发生作用。对于 font.properties.zh_CN, 需要检查是否映射缺省字体到中文字体如宋体。
在Swing中,Java自行解释TTF字体,渲染显示;对于AWT,SWT显示部分交由操作系统。首先需要确定系统装有中文字体。
1 汉字显示为”□”,一般为显示字体没有使用中文字体,因为Java对于当前字体显示不了的字符,不会像Windows一样再采用缺省字体显示。
2 部分不常见汉字不能显示,一般为显示字库中汉字不全,可以换另外的中文字体试试。
3 对于AWT/SWT,首先确定JVM运行环境的区域设置为中文,因为此处设计JVM与操作系统api调用的转换问题,再检查其它问题。
JNI
JNI中jstring以UTF-8编码给我们,需要我们自行转为本地编码。对于Windows,可以采用WideCharToMultiByte/MultiByteToWideChar函数进行转换,对于Unix,可以采用iconv库。这里从SUN jdk 1.4 源代码中找到一段使用jvm String 对象的getBytes的转换方式,相对简单和跨平台,不需要第三方库,但速度稍慢。函数原型如下:
/* Convert between Java strings and i18n C strings */ JNIEXPORT jstring NewStringPlatform(JNIEnv *env, const char *str); JNIEXPORT const char * GetStringPlatformChars(JNIEnv *env, jstring jstr, jboolean *isCopy); JNIEXPORT jstring JNICALL JNU_NewStringPlatform(JNIEnv *env, const char *str); JNIEXPORT const char * JNICALL JNU_GetStringPlatformChars(JNIEnv *env, jstring jstr, jboolean *isCopy); JNIEXPORT void JNICALL JNU_ReleaseStringPlatformChars(JNIEnv *env, jstring jstr, const char *str);
附件jni_util.h,jni_util.c
TUXEDO/JOLT
JOLT对于传递的字符串需要用如下进行转码
new String(ls_tt.getBytes("GBK"),"iso8859-1")
对于返回的字符串
new String(error_message.getBytes("iso8859-1"),"GBK");
jolt 的系统属性 bea.jolt.encoding不应该设置,如果设置,JSH会报告说错误的协议.
JDK1.4/1.5新增部分
字符集相关类(Charset/CharsetEncoder/CharsetDecoder)
jdk1.4开始,对字符集的支持在java.nio.charset包中实现。常用功能:
1 列出jvm所支持字符集:Charset.availableCharsets()
2 能否对看某个Unicode字符编码,CharsetEncoder.canEncode()
Unicode Surrogate/CJK EXT B
Unicode 范围一般所用为\U0000-\UFFFF范围,jvm使用1个char就可以表示,对于CJKEXT B区汉字,范围大于\U20000,则需要采用2个char方能表示,此即Unicode Surrogate。这2个char的值范围 落在Character.SURROGATE 区域内,用Character.getType()来判断。
jdk 1.4尚不能在Swing中正确处理surrogate区的Unicode字符,jdk1.5可以。对于CJK
EXT B区汉字,目前可以使用的字库为”宋体-方正超大字符集”,随Office安装。
常见问题
在JVM下,用System.out.println不能正确打印中文,显示为???
System.out.println是PrintStream,它采用jvm缺省字符集进行转码工作,如果jvm的缺省字符集为iso8859-1,则中文显示会有问题。此问题常见于Unix下,jvm的区域没有明确指定的情况。在英文UNIX环境下,用System.out.println能够正确打印汉字,但是内部处理错误
可能是汉字在输入转换时,就没有正确转码:即gbk文本à(iso8859-1转码)àjvm char(iso8859-1编码汉字)à (iso8859-1转码)à输出。
gbk汉字经过两次错误转码,原封不动的被传递到输出,但是在jvm中,并未以正确的unicode编码表示,而是以一个汉字字节一个char的方式表示,从而导致此类错误。
GB2312-80,GBK,GB18030-2000 汉字字符集
GB2312-80 是在国内计算机汉字信息技术发展初始阶段制定的,其中包含了大部分常用的一、二级汉字,和 9 区的符号。该字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,这也是最基本的中文字符集。其编码范围是高位0xa1-0xfe,低位也是 0xa1-0xfe;汉字从 0xb0a1 开始,结束于 0xf7fe;
GBK 是 GB2312-80 的扩展,是向上兼容的。它包含了 20902 个汉字,其编码范围是 0x8140-0xfefe,剔除高位 0x80 的字位。其所有字符都可以一对一映射到 Unicode
2.0,也就是说 JAVA 实际上提供了 GBK 字符集的支持。这是现阶段 Windows 和其它一些中文操作系统的缺省字符集,但并不是所有的国际化软件都支持该字符集,感觉是他们并不完全知道 GBK 是怎么回事。值得注意的是它不是国家标准,而只是规范。随着 GB18030-2000国标的发布,它将在不久的将来完成它的历史使命。
GB18030-2000(GBK2K) 在 GBK 的基础上进一步扩展了汉字,增加了藏、蒙等少数民族的字形。GBK2K 从根本上解决了字位不够,字形不足的问题。它有几个特点,
它并没有确定所有的字形,只是规定了编码范围,留待以后扩充。
编码是变长的,其二字节部分与 GBK 兼容;四字节部分是扩充的字形、字位,其编码范围是首字节 0x81-0xfe、二字节0x30-0x39、三字节 0x81-0xfe、四字节0x30-0x39。
UTF-8/UTF-16/UTF-32
UTF,即Unicode Transformer Format,是Unicode代码点(code point)的实际表示方式,按其基本长度所用位数分为UTF-8/16/32。它也可以认为是一种特殊的外部数据编码,但能够与Unicode代码点做一一对应。
UTF-8是变长编码,每个Unicode代码点按照不同范围,可以有1-3字节的不同长度。
UTF-16长度相对固定,只要不处理大于\U200000范围的字符,每个Unicode代码点使用16位即2字节表示,超出部分使用两个UTF-16即4字节表示。按照高低位字节顺序,又分为UTF-16BE/UTF-16LE。
UTF-32长度始终固定,每个Unicode代码点使用32位即4字节表示。按照高低位字节顺序,又分为UTF-32BE/UTF-32LE。
UTF编码有个优点,即尽管编码字节数不等,但是不像gb2312/gbk编码一样,需要从文本开始寻找,才能正确对汉字进行定位。在UTF编码下,根据相对固定的算法,从当前位置就能够知道当前字节是否是一个代码点的开始还是结束,从而相对简单的进行字符定位。不过定位问题最简单的还是UTF-32,它根本不需要进行字符定位,但是相对的大小也增加不少。
关于GCJ JVM
GCJ并未完全依照sun jdk的做法,对于区域和编码问题考虑尚不够周全。GCJ启动时,区域始终设为en_US,编码也缺省为iso8859-1。但是可以用Reader/Writer做正确编码转换。(以上内容引自:http://www.blogjava.net/zhugf000/archive/2005/10/09/15068.html)
最后写一个java程序来实现java转换字符串编码
package com.card;
import java.io.UnsupportedEncodingException;
import java.nio.charset.Charset;
public class ChangeCharset {
/** 7位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 */
public static final String US_ASCII = "US-ASCII";
/** ISO 拉丁字母表 No.1,也叫作 ISO-LATIN-1 */
public static final String ISO_8859_1 = "ISO-8859-1";
/** 8 位 UCS 转换格式 */
public static final String UTF_8 = "UTF-8";
/** 16 位 UCS 转换格式,Big Endian(最低地址存放高位字节)字节顺序 */
public static final String UTF_16BE = "UTF-16BE";
/** 16 位 UCS 转换格式,Little-endian(最高地址存放低位字节)字节顺序 */
public static final String UTF_16LE = "UTF-16LE";
/** 16 位 UCS 转换格式,字节顺序由可选的字节顺序标记来标识 */
public static final String UTF_16 = "UTF-16";
/** 中文超大字符集 */
public static final String GBK = "GBK";
/**
* 将字符编码转换成US-ASCII码
*/
public String toASCII(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, US_ASCII);
}
/**
* 将字符编码转换成ISO-8859-1码
*/
public String toISO_8859_1(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, ISO_8859_1);
}
/**
* 将字符编码转换成UTF-8码
*/
public String toUTF_8(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, UTF_8);
}
/**
* 将字符编码转换成UTF-16BE码
*/
public String toUTF_16BE(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, UTF_16BE);
}
/**
* 将字符编码转换成UTF-16LE码
*/
public String toUTF_16LE(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, UTF_16LE);
}
/**
* 将字符编码转换成UTF-16码
*/
public String toUTF_16(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, UTF_16);
}
/**
* 将字符编码转换成GBK码
*/
public String toGBK(String str) throws UnsupportedEncodingException {
return this.changeCharset(str, GBK);
}
/**
* 字符串编码转换的实现方法
*
* @param str
* 待转换编码的字符串
* @param newCharset
* 目标编码
* @return
* @throws UnsupportedEncodingException
*/
public String changeCharset(String str, String newCharset)
throws UnsupportedEncodingException {
if (str != null) {
// 用默认字符编码解码字符串。
byte[] bs = str.getBytes();
// 用新的字符编码生成字符串
return new String(bs, newCharset);
}
return null;
}
/**
* 字符串编码转换的实现方法
*
* @param str
* 待转换编码的字符串
* @param oldCharset
* 原编码
* @param newCharset
* 目标编码
* @return
* @throws UnsupportedEncodingException
*/
public String changeCharset(String str, String oldCharset, String newCharset)
throws UnsupportedEncodingException {
if (str != null) {
// 用旧的字符编码解码字符串。解码可能会出现异常。
byte[] bs = str.getBytes(oldCharset);
// 用新的字符编码生成字符串
return new String(bs, newCharset);
}
return null;
}
public static void main(String[] args) throws UnsupportedEncodingException {
// System.out.println("当前JRE:" + System.getProperty("java.version"));
// System.out.println("当前JVM的默认字符集:" + Charset.defaultCharset());
ChangeCharset test = new ChangeCharset();
String str = "This is a 中文的 String,正在进行charset转换!";
System.out.println("str: " + str);
String gbk = test.toGBK(str);
System.out.println("转换成GBK码: " + gbk);
System.out.println();
String ascii = test.toASCII(str);
System.out.println("转换成US-ASCII码: " + ascii);
gbk = test.changeCharset(ascii,ChangeCharset.US_ASCII, ChangeCharset.GBK);
System.out.println("再把ASCII码的字符串转换成GBK码: " + gbk);
System.out.println();
String iso88591 = test.toISO_8859_1(str);
System.out.println("转换成ISO-8859-1码: " + iso88591);
gbk = test.changeCharset(iso88591,ChangeCharset.ISO_8859_1, ChangeCharset.GBK);
System.out.println("再把ISO-8859-1码的字符串转换成GBK码: " + gbk);
System.out.println();
String utf8 = test.toUTF_8(str);
System.out.println("转换成UTF-8码: " + utf8);
gbk = test.changeCharset(utf8,ChangeCharset.UTF_8, ChangeCharset.GBK);
System.out.println("再把UTF-8码的字符串转换成GBK码: " + gbk);
System.out.println();
String utf16be = test.toUTF_16BE(str);
System.out.println("转换成UTF-16BE码:" + utf16be);
gbk = test.changeCharset(utf16be,ChangeCharset.UTF_16BE, ChangeCharset.GBK);
System.out.println("再把UTF-16BE码的字符串转换成GBK码: " + gbk);
System.out.println();
String utf16le = test.toUTF_16LE(str);
System.out.println("转换成UTF-16LE码:" + utf16le);
gbk = test.changeCharset(utf16le,ChangeCharset.UTF_16LE, ChangeCharset.GBK);
System.out.println("再把UTF-16LE码的字符串转换成GBK码: " + gbk);
System.out.println();
String utf16 = test.toUTF_16(str);
System.out.println("转换成UTF-16码:" + utf16);
gbk = test.changeCharset(utf16,ChangeCharset.UTF_16LE, ChangeCharset.GBK);
System.out.println("再把UTF-16码的字符串转换成GBK码: " + gbk);
String s = new String("中文".getBytes("UTF-8"),"UTF-8");
System.out.println(s);
}
}运行结果为:
str: This is a 中文的 String,正在进行charset转换! 转换成GBK码: This is a 中文的 String,正在进行charset转换! 转换成US-ASCII码: This is a ?????? String,????????charset????! 再把ASCII码的字符串转换成GBK码: This is a ?????? String,????????charset????! 转换成ISO-8859-1码: This is a ?????? String,????????charset×???! 再把ISO-8859-1码的字符串转换成GBK码: This is a 中文的 String,正在进行charset转换! 转换成UTF-8码: This is a ????? String,???????charset???! 再把UTF-8码的字符串转换成GBK码: This is a 锟斤拷锟侥碉拷 String,锟斤拷锟节斤拷锟斤拷charset转锟斤拷! 转换成UTF-16BE码:周楳?猠愠????瑲楮本????捨慲獥瓗?? 再把UTF-16BE码的字符串转换成GBK码: This is a 中文的 String,正在进行charset转换! 转换成UTF-16LE码:桔獩椠?????匠牴湩????档牡敳??? 再把UTF-16LE码的字符串转换成GBK码: This is a 中文的 String,正?行charset转换! 转换成UTF-16码:周楳?猠愠????瑲楮本????捨慲獥瓗?? 再把UTF-16码的字符串转换成GBK码: hTsii s a兄奈牡S rtni,g谠行hcraes譼华!? 中文
------------------------------------------------------------------------------------------------------------------
java中的String类是按照unicode进行编码的,当使用String(byte[] bytes, String encoding)构造字符串时,encoding所指的是bytes中的数据是按照那种方式编码的,而不是最后产生的String是什么编码方式,换句话说,是让系统把bytes中的数据由encoding编码方式转换成unicode编码。如果不指明,bytes的编码方式将由jdk根据操作系统决定。
当我们从文件中读数据时,最好使用InputStream方式,然后采用String(byte[] bytes, String encoding)指明文件的编码方式。不要使用Reader方式,因为Reader方式会自动根据jdk指明的编码方式把文件内容转换成unicode编码。
当我们从数据库中读文本数据时,采用ResultSet.getBytes()方法取得字节数组,同样采用带编码方式的字符串构造方法即可。
ResultSet rs;
bytep[] bytes = rs.getBytes();
String str = new String(bytes, "gb2312");
不要采取下面的步骤。
ResultSet rs;
String str = rs.getString();
str = new String(str.getBytes("iso8859-1"), "gb2312");
这种编码转换方式效率底。之所以这么做的原因是,ResultSet在getString()方法执行时,默认数据库里的数据编码方式为iso8859-1。系统会把数据依照iso8859-1的编码方式转换成unicode。使用str.getBytes("iso8859-1")把数据还原,然后利用new String(bytes, "gb2312")把数据从gb2312转换成unicode,中间多了好多步骤。
从HttpRequest中读参数时,利用reqeust.setCharacterEncoding()方法设置编码方式,读出的内容就是正确的了。
附注:给一篇介绍java字符的文章 点击下载
==================================================================================================
作者:欧阳鹏 欢迎转载,与人分享是进步的源泉!
转载请保留原文地址:http://blog.csdn.net/ouyang_peng
==================================================================================================

相关文章推荐
- 我的Java开发学习之旅------>Java ClassLoader解析二(转)
- 我的Java开发学习之旅------>Base64的编码思想以及Java实现
- 我的Java开发学习之旅------>Base64的编码思想以及Java实现
- 我的Java开发学习之旅------>Java ClassLoader解析一(转)
- 我的Java开发学习之旅------>Java NIO 报java.nio.charset.MalformedInputException: Input length = 1异常
- java字符编码原理解析
- 我的Java开发学习之旅------>Java经典排序算法之归并排序
- 我的Java开发学习之旅------>使用循环递归算法把数组里数据数组合全部列出
- 我的Java开发学习之旅------>使用Working Setst将Eclipse中的项目分类使项目一目了然
- <Python高级全栈开发工程师-1>学习过程笔记【181-184】正则表达式 <特殊字符><函数>
- WEB开发:WEB开发中的JAVA字符编码经验总结
- Java 完成水吧点饮品系统开发 集合List<E>的学习
- web开发-java实现读文件修改特定字符之后写入文件-学习笔记七
- 我的Java开发学习之旅------>Workspace in use or cannot be created, choose a different one.--错误解决办法
- 我的Java开发学习之旅------>Java经典排序算法之快速排序
- 我的Java开发学习之旅------>Java双重检查锁定及单例模式详解(转)
- WEB开发中的JAVA字符编码经验总结
- 我的Java开发学习之旅------>银行业务调度系统
- 我的Java开发学习之旅------>自己编写的Java数组操作工具
- 我的Java开发学习之旅------>Java经典排序算法之选择排序