LDA源码分析(matlab版)
2013-04-26 20:52
447 查看
LDA全称是Latent Dirichlet Allocation。关于LDA的理论知识,可以参见如下参考维基百科。这里具体讲解一下LDA的源码分析(matlab)
代码原作者:Daichi Mochihashi
源码下载地址:http://download.csdn.net/detail/nuptboyzhb/5305145
一.LDA源码在matlab环境下的执行
1.环境配置
将matlab的工作目录切换到代码所在目录
2.调用主函数
>> [alpha,beta] =ldamain(‘train’,20);%训练数据文件train
分类数20
二.训练数据train的数据格式
如:
<feature_id>:<count> 特征的标号:对应的个数
对于文档而言,特征id表征的是某个单词,数目则表示单词出现的次数
train中的每一行表示一个文档,如下:
1:1 2:4 5:2
1:2 3:3 5:1 6:1 7:1
2:4 5:1 7:1
注意:LDA中train的数据格式与SVM中的差异,在SVM中,训练数据的格式如下:
与svm的训练数据格式,相似但不同
<label> <index1>:<value1> <index2>:<value2> ...
也就是说,SVM中的训练数据,都有“标签”。SVM是一个监督学习的过程。而LDA是非监督学习。
三.代码中的变量意义
四.LDA的源码总览
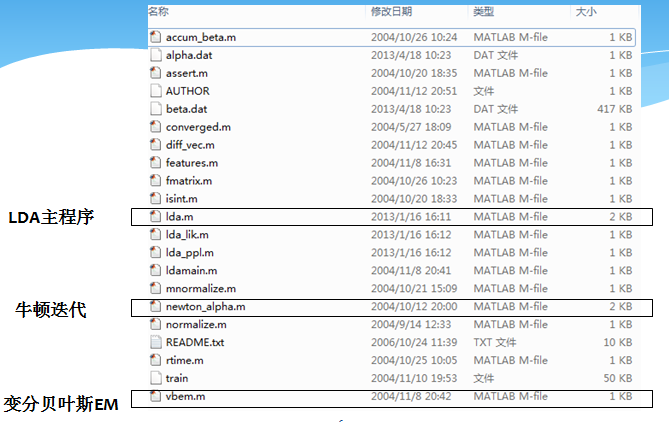
虽然LDA的源码有很多.m文件,但是主要的文件时lda.m vbem.m and newton_alpha.m三个文件。
五.核心代码分析
lda.m
function [alpha,beta] = lda(d,k,emmax,demmax)
% Latent Dirichlet Allocation, standard model.
% d : data of documents
% k : # of classes to assume
% emmax : # of maximum VB-EM iteration (default 100)
% demmax : # of maximum VB-EM iteration for a document (default 20)
if nargin < 4
demmax = 20;
if nargin < 3
emmax = 100;
end
end
n = length(d);
l = features(d);
%初始化
beta = mnormalize(rand(l,k),1);
alpha = normalize(fliplr(sort(rand(1,k))));%对应dirichlet分布的参数
gammas = zeros(n,k);
ppl = 0;
pppl = ppl;
tic;
fprintf(1,'number of documents = %d\n', n);
fprintf(1,'number of words = %d\n', l);
fprintf(1,'number of latent classes = %d\n', k);
for j = 1:emmax
fprintf(1,'iteration %d/%d..\t',j,emmax);
% vb-estep 输入alpha和beta计算gammas
betas = zeros(l,k);
for i = 1:n % 对每个文档进行计算
[gamma,q] = vbem(d{i},beta,alpha,demmax);
gammas(i,:) = gamma; %保存每个文档的值
betas = accum_beta(betas,q,d{i});
end
% vb-mstep 最大化似然函数(gammas),求解alpha和beta
alpha = newton_alpha(gammas);
beta = mnormalize(betas,1);
% converge?
ppl = lda_ppl(d,beta,gammas);
fprintf(1,'PPL = %g\t',ppl);
if (j > 1) && converged(ppl,pppl,1.0e-4)
if (j < 5)
fprintf(1,'\n');
% 迭代次数过少try again!
[alpha,beta] = lda(d,k,emmax,demmax); return;
end
fprintf(1,'\nconverged.\n');
return;
end
pppl = ppl;
% ETA
elapsed = toc;
fprintf(1,'ETA:%s (%d sec/step)\r', ...
rtime(elapsed * (emmax / j - 1)),round(elapsed / j));
end
fprintf(1,'\n');
未经允许,文章不得用于商业目的!!
代码原作者:Daichi Mochihashi
源码下载地址:http://download.csdn.net/detail/nuptboyzhb/5305145
一.LDA源码在matlab环境下的执行
1.环境配置
将matlab的工作目录切换到代码所在目录
2.调用主函数
>> [alpha,beta] =ldamain(‘train’,20);%训练数据文件train
分类数20
二.训练数据train的数据格式
如:
<feature_id>:<count> 特征的标号:对应的个数
对于文档而言,特征id表征的是某个单词,数目则表示单词出现的次数
train中的每一行表示一个文档,如下:
1:1 2:4 5:2
1:2 3:3 5:1 6:1 7:1
2:4 5:1 7:1
注意:LDA中train的数据格式与SVM中的差异,在SVM中,训练数据的格式如下:
与svm的训练数据格式,相似但不同
<label> <index1>:<value1> <index2>:<value2> ...
也就是说,SVM中的训练数据,都有“标签”。SVM是一个监督学习的过程。而LDA是非监督学习。
三.代码中的变量意义
n 整数,表示文档数 L 整数,表示单词数 beta 二维数组,行代表单词,列代表主题,矩阵单元代表某主题生成某词的概率 alpha 数组,对应dirichlet分布的参数 k 整数,代表主题数,这个是由用户设置的值 gamma 一维数组,变分推理中后验dirichlet分布的参数 gammas 充分统计量一维数组,形式同gamma,用于在m-step估计alpha的值 q 二维数组,行代表文档里的单词,列代表主题,矩阵单元代表文档中某主题生成某词的概率 betas 充分统计量,二维数组,形式同q,该变量用于在e-step统计信息,供m-step估计beta使用。
四.LDA的源码总览
虽然LDA的源码有很多.m文件,但是主要的文件时lda.m vbem.m and newton_alpha.m三个文件。
五.核心代码分析
lda.m
function [alpha,beta] = lda(d,k,emmax,demmax)
% Latent Dirichlet Allocation, standard model.
% d : data of documents
% k : # of classes to assume
% emmax : # of maximum VB-EM iteration (default 100)
% demmax : # of maximum VB-EM iteration for a document (default 20)
if nargin < 4
demmax = 20;
if nargin < 3
emmax = 100;
end
end
n = length(d);
l = features(d);
%初始化
beta = mnormalize(rand(l,k),1);
alpha = normalize(fliplr(sort(rand(1,k))));%对应dirichlet分布的参数
gammas = zeros(n,k);
ppl = 0;
pppl = ppl;
tic;
fprintf(1,'number of documents = %d\n', n);
fprintf(1,'number of words = %d\n', l);
fprintf(1,'number of latent classes = %d\n', k);
for j = 1:emmax
fprintf(1,'iteration %d/%d..\t',j,emmax);
% vb-estep 输入alpha和beta计算gammas
betas = zeros(l,k);
for i = 1:n % 对每个文档进行计算
[gamma,q] = vbem(d{i},beta,alpha,demmax);
gammas(i,:) = gamma; %保存每个文档的值
betas = accum_beta(betas,q,d{i});
end
% vb-mstep 最大化似然函数(gammas),求解alpha和beta
alpha = newton_alpha(gammas);
beta = mnormalize(betas,1);
% converge?
ppl = lda_ppl(d,beta,gammas);
fprintf(1,'PPL = %g\t',ppl);
if (j > 1) && converged(ppl,pppl,1.0e-4)
if (j < 5)
fprintf(1,'\n');
% 迭代次数过少try again!
[alpha,beta] = lda(d,k,emmax,demmax); return;
end
fprintf(1,'\nconverged.\n');
return;
end
pppl = ppl;
% ETA
elapsed = toc;
fprintf(1,'ETA:%s (%d sec/step)\r', ...
rtime(elapsed * (emmax / j - 1)),round(elapsed / j));
end
fprintf(1,'\n');
未经允许,文章不得用于商业目的!!

相关文章推荐
- LDA(线性判别分析)及源码实现
- LDA理解以及源码分析(二)
- matlab工具箱TTSBOX源码中文分析
- Matlab 绘图全方位分析及源码
- LDA基本介绍以及LDA源码分析(BLEI)
- 使用随机梯度算法对高斯核模型进行最小二乘学习法的MATLAB程序源码分析
- Spark MLlib LDA 基于GraphX实现原理及源码分析
- LDA模型简介、源码分析及实验
- LDA基本介绍以及LDA源码分析(BLEI)
- LDA基本介绍以及LDA源码分析(BLEI)
- LDA理解以及源码分析(一)
- LDA基本介绍以及LDA源码分析(BLEI)
- 稀疏度MATLAB源码分析
- Heritrix源码分析(二) 配置文件order.xml介绍(转)
- Backbone.js源码分析(珍藏版)
- 【android】Monkey源码分析、事件注入
- MR-2.输入格式(InputFormat)FileInputFormat源码分析
- JDK AtomicInteger 源码分析
- Handler机制的源码分析
- [转载]openwrt源码目录分析