机器学习的概率与统计知识复习总结
2013-04-25 11:03
295 查看
机器学习中,很多算法的推导,需要概率和统计的很多知识。学校里学的时候,基本是囫囵吞枣,也忘得差不离了。
现在复习一下,找一些概率与统计这门课的感觉。主要理解下什么是随机变量,与概率的关系,要样本干什么,等等。
几何分布,是描述的n重伯努利实验成功的概率。前n-1次失败,第n次成功,才叫几何分布。或者说,首次成功的实验 的概率分布。
超几何分布,其实是二项分布的变体,二项分布是同一事件,重复n次的概率分布;而超几何分布,是一个事情只在每个维度上,都做一次。
放回抽样,很好理解,每次情景相同,概率都相同。
而不放回抽样,每次抽样,都是与前些次的抽样相关的。这其实是一个排列组合问题。有的书采用对称性进行分析,每次事件相互独立,且具有对称性,其基本事件:抽样的序列,仍是排列。
从相关性上,前面的人抽中,与抽不中,对后面都有影响,但是这种影响又相互抵消。除非,前面有人知道如何抽中指定的。这个采用全概率公式,推导比较合理。
如当抽过i-1次后,仍剩下m个红球,n个白球。第i次抽取白球的概率为
n/(m+n).
则第i+1次抽取白球的概率为: 全概率公式: n/(m+n) * (n-1)/(m+n-1) + m/(m+n) * n/(m+n-1) = n/(m+n) 递推下去,每次抽取的概率都是相同的。
更进一步,这个问题,可变体为:蒙提霍尔问题,出自美国的电视游戏节目Let's Make a Deal。汽车与山羊,三扇门,选中汽车的概率,在开启一扇门后,有没有变化。
若主持人不知情,则概率无变化。剩余两门:1/2,1/2,无放回抽样类似。
若主持人知情,概率就会发生变化。剩余两门:未开门的概率为2/3,1/3,非概率事件。
利用排列组合的知识,0-1分布,二项分布/n重伯努利分布 都比较好理解。
而泊松分布 是一种指数分布的形式。基本上是泰勒展开式的形式。为什么会有泊松分布的形式?
它也是一个单峰值函数,n无穷大时,可以近似二项分布。 因为二项分布的计算不如泊松分布方便。
以平均值,就能表征一个群体的特征的分布。n*lambda。围绕中心分布,两边衰减极快。
其主要描述一种稀有事件发生的概率。n很大,p很小。 而且其 期望与方差 都是lambda。 适合描述 单位时间、空间内 随机发生的事情。
-->> 随机变量,从离散型至连续型。离散型的随机变量,比较好理解,而连续型的随机变量,某一点的概率是为0.所以,连续型的随机变量,利用区间来表示。
而连续型的随机变量,即是一个连续型的函数。其用某区间内的概率表示,就比较合适。用区间概率表示的函数,就是随机变量的分布函数F(x)。而区间的概率表示:
P(x1 <x<=x2) = F(x2) - F(x1).
推导出随机变量的概率密度函数 f(x)。
1)均匀分布、平均分布
2)指数分布
这个分布的形式很重要,它是一般线性回归的分布的主要形式。
对于可靠性分析,排队论中有广泛应用。
3)高斯分布、正态分布
也可以说是指数分布的一种特殊表现形式。拥有对称性,极大值等特性。 噪声的分布经常都是正态分布,在应用中,基本上都假设是这种分布,在大部分的统计中,也确实符合这种分布。
其方差与置信区间的关系,3sigma法则 99.74%
正态分布的线性变换,仍然是正态分布,且性质保持不变。所以,任何随机变量正态分布,都可以转换为标准正态分布,进行求值,查询。分位点的概念,就是随便变量转换为标准正态后的对应的值。
已知随机变量X的分布,Y与X的关系,推导Y的分布。很重要。
F(Y) = P(Y<y) = P(X < g(y)).即可
相互独立的随机变量:性质 F(X, Y) = F(X) * F(Y)
X,Y非独立情况下,X在Y限制下的条件分布?
边缘分布 fy = 积分f(x,y)dx
条件分布 f(x,y) / fy
求证X+Y <=Z 的概率密度函数, 备用系统
将x+y<z的积分, 转换为x =u-y,将积分转换为dy与dx次序无关的积分。
Z=XY, 或Z=X/Y的分布
积分,变换,次序无关,求导
Z=min(x, y) Z=max(x, y)的分布, 串联、并联系统
max(x,y ) <=z 等同于 x<=z, y<=z
min(x, y) <=z 等同于 1-( max(x, y) > z) = 1-( x>z, y>z)
以上都是随机变量、概率的联系和推导。
期望:又称均值。对于连续型随机变量,就是积分了。一阶矩。这个可以用来衡量偏差。E(|X-EX|)
方差:衡量离散的程度。与二阶矩相关。EX^2 - (EX)^2
与期望、方差及概率相关的一个定理:
切比雪夫不等式 P(|x -u| > m) < D(x)/m
协方差,这个概念在机器学习,统计学中跟方差的概念同样重要。因为两个随机变量不可能任何时候都是相互独立的。
不相关是针对线性关系而言,而相互独立是对一般关系而言,包括非线性关系。
矩:随机变量的各阶的数字特征
协方差矩阵:多维随机变量的联合数字特征。一个对称阵。半正定矩阵,对角元素为各随机变量的方差。在PCA中,协方差矩阵是求特征值的首要构成。
辛钦定理的描述的概率事件。 小概率事件,一件事重复发生n次。
试验次数很大时,可以用频率代替事件的概率。频率与概率的偏差非常小。
中心极限定理,随机序列足够大时,拟合正态分布,求具体事件发生的概率
1)同分布,同方差,期望。 所有随机变量序列的和(期望、方差和),服从正态分布
2)已知方差,期望。分布不知,所有随机变量的和(期望、方差和),服从正态分布
3)二项分布,n重复大时,重复次数足够大时,二项分布与正态分布相似。可以用正态分布来计算二项分布。
这类问题,先知道基本事件发生的概率,然后求期望,方差,拟合正态分布,再求具体事件发生的概率。
概率论都是研究 概率、随机变量分布,及其关系。但这些都是理论,未与实际应用结合。而且实际的随机变量是不可完全精确测的。
----------------
所以,统计,就是如何估计,拟合这些随机变量的。或者,判断某随机变量与某分布的拟合程度,或关系。
观测,获取样本,由样本进行统计、推断。
而样本除了自身的值,还可以扩展出各种统计量,就由样本值计算的高阶数据:均值、方差、高阶矩。
什么是样本?与总体的关系?
实际应用中总体的随机分布是未知的,一个总体对应一个随机变量,而从总体中抽取一个个体,就是样本,样本就是与总体有相同分布的随机变量。即样本与总体,都是随机变量,而且服从相同分布。样本间是相互独立的。
当测量或观察完成, 样本随机变量就会得到一个实数值,这就是样本值。
反过来,服从同一分布函数,且相互独立的随机变量序列,就是同一总体中的样本。
通过样本值来估计样本和总体的分布,就是统计的事。
抽样分布,又叫统计量分布。当总体的精确的分布函数确定时,其统计量分布(抽样分布)就确定了,然后,统计量的精确分布的求解是很困难的。所以,只能从样本中计算。
常用抽样分布:
1)卡方分布
统计量:来自N(0, 1)的样本的平方和
服从自由度为n的卡方分布。 EX = n, DX = 2n
2)t分布、student分布
卡方分布,自由度为n
3)F分布
与卡方分布相关,自由度n1,n2
当总体分布N(u,DX)已知,则抽样的统计量分布是:
服从正态总体的、样本均值的 分布
N(u, DX/n)
抽样(样本均值、样本方差)与卡方分布的关系
抽样(抽样期望与抽样方差)与t分布的关系
两个正态分布的抽样统计量与 F分布,t分布的关系。
由假设的正态分布的样本,到样本的函数分布,正态样本的统计量的分布函数形式。应该说是重点关注的正态样本的统计量。
一个总体,是一个随机变量
而每个样本,也是一个随机变量,是对总体的一次观察,每个样本的值,是一个实数。
区别:样本、样本值
估计量的定义: 以样本为自变量的函数/统计量。
因此,常用的估计量有:
1)矩估计量
比较好理解,均值,方差,n阶矩
2)最大似然估计量
概率密度函数f(x; theta), theta是估计量
那么所有样本的联合概率密度函数就是:
f(xi, theta)的连乘。
为什么要构造这个形式?有什么理论依据?
首先,要假设,或已知带参数的分布函数
然后,构造联合概率分布函数,因为每个样本也都是随机变量
最后,求极值。计算出估计量。
极大似然函数,或者对数极大似然函数构造 是关键。 理解样本X是随机变量。
机器学习中,常用的解法是梯度下降法,或牛顿法。
估计量的性质:
1)无偏性、针对期望
无偏估计量:估计量的期望 等于 真实值
如样本方差S^2是总体方差的估计量,而不是二阶中心矩;
除以n-1,而不是n,是因为 样本均值的影响,样本均值也是一个随机变量。
所有样本平方和 减去 样本均值的平方,就是样本方差。而样本均值的方差是总体方差的1/n。
2)有效性:针对方差
比较两个估计量,相同无偏性的性质下,哪个散度小,即D(theta),就选哪个。
3)相合性
样本无穷大,估计量等于真实值。极大似然估计法,满足这个特性。
求满足某个概率的区间。 即可以理解为,在这个范围内,达到某种可信度,可信概率。
计算出样本均值,样本方差。然后,由统计量的分布,进行计算置信区间。
常见问题
正态分布:
1)求期望的置信区间
总体方差已知:正态分布
总体方差未知:应用样本方差,t分布
2)求方差的置信区间
利用样本方差,和卡方分布,进行计算
3)两个总体是正态分布的情况
求期望差的置信区间:
总体方差已知:正态分布
总体方差未知:t分布
求方差比的置信区间
F分布,样本方差
单侧置信区间:
上限或下限,与双侧置信区间相比,需要查不同的表,但是计算方法相同。
解决的问题:
在整个总体分布未知或仅知道形式,但各种参数未知,仅有一些测试的样本数据的场景下,提出某种假设。利用样本,验证假设的合理性。
一个判断的标准,需要一个接受假设的概率。
利用这个概率,去查询对应的分布的区间。
计算样本的统计量,看是否在其分布的接受区间内。
因此,由接收概率,提出接收域,拒绝域。双边检验,单边检验。
相当于,求出置信区间,然后判断统计量,是否在置信区间内。
置信水平 + 显著性检验水平 = 1
再接下来,就能过度到方差分析与回归分析了。
只不过,统计学中的回归分析,在拟合出模型后,还要做假设检验等等。
-----------------------------
后验概率的计算,是以先验概率为前提条件的。如果只知道事情结果,而不知道先验概率(没有以往数据统计),是无法计算后验概率的。
后验概率的计算需要应用到贝叶斯公式
贝叶斯公式,事情已经发生,计算引起结果的各因素的概率,由果寻因。同后验概率。
但条件概率不一定就是后验概率。
如 P(y|x),P(x|y)都是条件概率,二者表示的含义却不同。这里x表示因,y表示果。或者说x是特征,y是模型结果。
则P(y)是先验概率,而P(x|y)是后验概率。
而P(y|x)是一个条件概率,而不是后验概率。
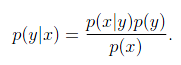
P(xy) = P(x|y)*P(y)
而一般分析问题时,已知的是特征x,需要判别结果y。
这里由推出一个判别模型。
常见的判别模型:线性回归、对数回归/逻辑回归、SVM、boosting、条件随机场、神经网络、最近邻算法Nearest neighbor等。 这些 模型都是通过计算 条件概率的 最大似然估计推导出来。
它是在有限样本的条件下,寻找最优的分类面,关注判别模型的边缘分布。目标函数大部分直接对应 分类准确率。
生成模型 有无限的样本,可以得到其 概率密度模型, 然后可以进行预测了。
常见生成模型: 隐式马尔科夫模型、朴素贝叶斯模型、高斯混合模型、有限波兹曼机等。
因其有无限的样本,可以采用增量的方式学习模型,对于单类问题比判别模型强,信息量比判别模型丰富。主要是对后验概率建模,关注自身,而不关注边界。
由判别模型得不到生成模型,而从生成模型可以得到判别模型。
2)类别的个数是一定的
已知先验概率、和 采集的数据特征(这个因素在每个分类上的后验概率)
就可以对该数据进行分类。原理就是条件概率,贝叶斯决策。
最小错误率的贝叶斯决策与最小风险的贝叶斯决策 的区别和联系?
最小错误率的贝叶斯决策: 结果为 maxP(yi | x)
最小风险的贝叶斯决策:是考虑了各种错误造成不同的损失而提出的一种决策。
http://blog.sciencenet.cn/home.php?mod=space&uid=248173&do=blog&id=227964 http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971903.html
现在复习一下,找一些概率与统计这门课的感觉。主要理解下什么是随机变量,与概率的关系,要样本干什么,等等。
1. 什么是古典概率?
有限个可能事件,且每个事件都是等可能概率事件。这个与抽样问题,经常联系起来2. 什么是几何分布、超几何分布 ?
都是离散概率分布。是抽取问题的一种。几何分布,是描述的n重伯努利实验成功的概率。前n-1次失败,第n次成功,才叫几何分布。或者说,首次成功的实验 的概率分布。
超几何分布,其实是二项分布的变体,二项分布是同一事件,重复n次的概率分布;而超几何分布,是一个事情只在每个维度上,都做一次。
3. 放回抽样与不放回抽样的概率有什么不同?
其实是相同的。为什么?放回抽样,很好理解,每次情景相同,概率都相同。
而不放回抽样,每次抽样,都是与前些次的抽样相关的。这其实是一个排列组合问题。有的书采用对称性进行分析,每次事件相互独立,且具有对称性,其基本事件:抽样的序列,仍是排列。
从相关性上,前面的人抽中,与抽不中,对后面都有影响,但是这种影响又相互抵消。除非,前面有人知道如何抽中指定的。这个采用全概率公式,推导比较合理。
如当抽过i-1次后,仍剩下m个红球,n个白球。第i次抽取白球的概率为
n/(m+n).
则第i+1次抽取白球的概率为: 全概率公式: n/(m+n) * (n-1)/(m+n-1) + m/(m+n) * n/(m+n-1) = n/(m+n) 递推下去,每次抽取的概率都是相同的。
更进一步,这个问题,可变体为:蒙提霍尔问题,出自美国的电视游戏节目Let's Make a Deal。汽车与山羊,三扇门,选中汽车的概率,在开启一扇门后,有没有变化。
若主持人不知情,则概率无变化。剩余两门:1/2,1/2,无放回抽样类似。
若主持人知情,概率就会发生变化。剩余两门:未开门的概率为2/3,1/3,非概率事件。
4. 什么是随机变量?与概率什么关系?
一个单值实值函数,是一个函数X。而每个具体的实值x,会有一个出现的概率,这个概率能用这个函数(随机变量)能体现。随机变量的概念在机器学习的贝叶斯学习中、模式识别的贝叶斯分类中,是分析的基础。5. 离散随机变量,常见的有哪些
三种分布利用排列组合的知识,0-1分布,二项分布/n重伯努利分布 都比较好理解。
而泊松分布 是一种指数分布的形式。基本上是泰勒展开式的形式。为什么会有泊松分布的形式?
它也是一个单峰值函数,n无穷大时,可以近似二项分布。 因为二项分布的计算不如泊松分布方便。
以平均值,就能表征一个群体的特征的分布。n*lambda。围绕中心分布,两边衰减极快。
其主要描述一种稀有事件发生的概率。n很大,p很小。 而且其 期望与方差 都是lambda。 适合描述 单位时间、空间内 随机发生的事情。
-->> 随机变量,从离散型至连续型。离散型的随机变量,比较好理解,而连续型的随机变量,某一点的概率是为0.所以,连续型的随机变量,利用区间来表示。
而连续型的随机变量,即是一个连续型的函数。其用某区间内的概率表示,就比较合适。用区间概率表示的函数,就是随机变量的分布函数F(x)。而区间的概率表示:
P(x1 <x<=x2) = F(x2) - F(x1).
推导出随机变量的概率密度函数 f(x)。
6. 连续型随机变量,如何定义,如何表示?
分布函数:1)均匀分布、平均分布
2)指数分布
这个分布的形式很重要,它是一般线性回归的分布的主要形式。
对于可靠性分析,排队论中有广泛应用。
3)高斯分布、正态分布
也可以说是指数分布的一种特殊表现形式。拥有对称性,极大值等特性。 噪声的分布经常都是正态分布,在应用中,基本上都假设是这种分布,在大部分的统计中,也确实符合这种分布。
其方差与置信区间的关系,3sigma法则 99.74%
正态分布的线性变换,仍然是正态分布,且性质保持不变。所以,任何随机变量正态分布,都可以转换为标准正态分布,进行求值,查询。分位点的概念,就是随便变量转换为标准正态后的对应的值。
已知随机变量X的分布,Y与X的关系,推导Y的分布。很重要。
F(Y) = P(Y<y) = P(X < g(y)).即可
7. 二维随机变量,是推广到高维随机变量的基础。
问题:X,Y相互独立情况下,其概率分布情况?相互独立的随机变量:性质 F(X, Y) = F(X) * F(Y)
X,Y非独立情况下,X在Y限制下的条件分布?
边缘分布 fy = 积分f(x,y)dx
条件分布 f(x,y) / fy
求证X+Y <=Z 的概率密度函数, 备用系统
将x+y<z的积分, 转换为x =u-y,将积分转换为dy与dx次序无关的积分。
Z=XY, 或Z=X/Y的分布
积分,变换,次序无关,求导
Z=min(x, y) Z=max(x, y)的分布, 串联、并联系统
max(x,y ) <=z 等同于 x<=z, y<=z
min(x, y) <=z 等同于 1-( max(x, y) > z) = 1-( x>z, y>z)
以上都是随机变量、概率的联系和推导。
8. 随机变量的数字特征,有哪些
转换到随机变量自身的性质。而且随机变量真正的分布是不知道的,只能通过其统计特征来估计其分布。期望:又称均值。对于连续型随机变量,就是积分了。一阶矩。这个可以用来衡量偏差。E(|X-EX|)
方差:衡量离散的程度。与二阶矩相关。EX^2 - (EX)^2
与期望、方差及概率相关的一个定理:
切比雪夫不等式 P(|x -u| > m) < D(x)/m
协方差,这个概念在机器学习,统计学中跟方差的概念同样重要。因为两个随机变量不可能任何时候都是相互独立的。
不相关是针对线性关系而言,而相互独立是对一般关系而言,包括非线性关系。
矩:随机变量的各阶的数字特征
协方差矩阵:多维随机变量的联合数字特征。一个对称阵。半正定矩阵,对角元素为各随机变量的方差。在PCA中,协方差矩阵是求特征值的首要构成。
9. 大数(高频重复试验)定理与概率的关系。
独立同分布随机变量序列的算术平均值是如何收敛到、接近其期望的。辛钦定理的描述的概率事件。 小概率事件,一件事重复发生n次。
试验次数很大时,可以用频率代替事件的概率。频率与概率的偏差非常小。
中心极限定理,随机序列足够大时,拟合正态分布,求具体事件发生的概率
1)同分布,同方差,期望。 所有随机变量序列的和(期望、方差和),服从正态分布
2)已知方差,期望。分布不知,所有随机变量的和(期望、方差和),服从正态分布
3)二项分布,n重复大时,重复次数足够大时,二项分布与正态分布相似。可以用正态分布来计算二项分布。
这类问题,先知道基本事件发生的概率,然后求期望,方差,拟合正态分布,再求具体事件发生的概率。
概率论都是研究 概率、随机变量分布,及其关系。但这些都是理论,未与实际应用结合。而且实际的随机变量是不可完全精确测的。
----------------
所以,统计,就是如何估计,拟合这些随机变量的。或者,判断某随机变量与某分布的拟合程度,或关系。
观测,获取样本,由样本进行统计、推断。
而样本除了自身的值,还可以扩展出各种统计量,就由样本值计算的高阶数据:均值、方差、高阶矩。
10. 经验分布函数、真实分布函数 关系
当样本个数足够大时,两者相等。什么是样本?与总体的关系?
实际应用中总体的随机分布是未知的,一个总体对应一个随机变量,而从总体中抽取一个个体,就是样本,样本就是与总体有相同分布的随机变量。即样本与总体,都是随机变量,而且服从相同分布。样本间是相互独立的。
当测量或观察完成, 样本随机变量就会得到一个实数值,这就是样本值。
反过来,服从同一分布函数,且相互独立的随机变量序列,就是同一总体中的样本。
通过样本值来估计样本和总体的分布,就是统计的事。
抽样分布,又叫统计量分布。当总体的精确的分布函数确定时,其统计量分布(抽样分布)就确定了,然后,统计量的精确分布的求解是很困难的。所以,只能从样本中计算。
常用抽样分布:
1)卡方分布
统计量:来自N(0, 1)的样本的平方和
服从自由度为n的卡方分布。 EX = n, DX = 2n
2)t分布、student分布
卡方分布,自由度为n
3)F分布
与卡方分布相关,自由度n1,n2
当总体分布N(u,DX)已知,则抽样的统计量分布是:
服从正态总体的、样本均值的 分布
N(u, DX/n)
抽样(样本均值、样本方差)与卡方分布的关系
抽样(抽样期望与抽样方差)与t分布的关系
两个正态分布的抽样统计量与 F分布,t分布的关系。
由假设的正态分布的样本,到样本的函数分布,正态样本的统计量的分布函数形式。应该说是重点关注的正态样本的统计量。
一个总体,是一个随机变量
而每个样本,也是一个随机变量,是对总体的一次观察,每个样本的值,是一个实数。
区别:样本、样本值
11. 参数估计:
机器学习中,最基本的推理基础。估计量的定义: 以样本为自变量的函数/统计量。
因此,常用的估计量有:
1)矩估计量
比较好理解,均值,方差,n阶矩
2)最大似然估计量
概率密度函数f(x; theta), theta是估计量
那么所有样本的联合概率密度函数就是:
f(xi, theta)的连乘。
为什么要构造这个形式?有什么理论依据?
首先,要假设,或已知带参数的分布函数
然后,构造联合概率分布函数,因为每个样本也都是随机变量
最后,求极值。计算出估计量。
极大似然函数,或者对数极大似然函数构造 是关键。 理解样本X是随机变量。
机器学习中,常用的解法是梯度下降法,或牛顿法。
估计量的性质:
1)无偏性、针对期望
无偏估计量:估计量的期望 等于 真实值
如样本方差S^2是总体方差的估计量,而不是二阶中心矩;
除以n-1,而不是n,是因为 样本均值的影响,样本均值也是一个随机变量。
所有样本平方和 减去 样本均值的平方,就是样本方差。而样本均值的方差是总体方差的1/n。
2)有效性:针对方差
比较两个估计量,相同无偏性的性质下,哪个散度小,即D(theta),就选哪个。
3)相合性
样本无穷大,估计量等于真实值。极大似然估计法,满足这个特性。
12. 置信区间
条件:已知总体分布、样本数据求满足某个概率的区间。 即可以理解为,在这个范围内,达到某种可信度,可信概率。
计算出样本均值,样本方差。然后,由统计量的分布,进行计算置信区间。
常见问题
正态分布:
1)求期望的置信区间
总体方差已知:正态分布
总体方差未知:应用样本方差,t分布
2)求方差的置信区间
利用样本方差,和卡方分布,进行计算
3)两个总体是正态分布的情况
求期望差的置信区间:
总体方差已知:正态分布
总体方差未知:t分布
求方差比的置信区间
F分布,样本方差
单侧置信区间:
上限或下限,与双侧置信区间相比,需要查不同的表,但是计算方法相同。
13. 假设检验:
线性回归,逻辑回归,一般回归的分析的基础。解决的问题:
在整个总体分布未知或仅知道形式,但各种参数未知,仅有一些测试的样本数据的场景下,提出某种假设。利用样本,验证假设的合理性。
一个判断的标准,需要一个接受假设的概率。
利用这个概率,去查询对应的分布的区间。
计算样本的统计量,看是否在其分布的接受区间内。
因此,由接收概率,提出接收域,拒绝域。双边检验,单边检验。
相当于,求出置信区间,然后判断统计量,是否在置信区间内。
置信水平 + 显著性检验水平 = 1
再接下来,就能过度到方差分析与回归分析了。
只不过,统计学中的回归分析,在拟合出模型后,还要做假设检验等等。
-----------------------------
1. 什么是先验概率?
事情未发生,只根据以往数据统计,分析事情发生的可能性,即先验概率。2. 什么是后验概率?与先验概率关系?
事情已发生,已有结果,但求引起这事发生的因素的可能性,有果求因,即后验概率。 后验概率,引起的原因,是测量可能错误。后验概率的计算,是以先验概率为前提条件的。如果只知道事情结果,而不知道先验概率(没有以往数据统计),是无法计算后验概率的。
后验概率的计算需要应用到贝叶斯公式
3. 贝叶斯公式与先验、后验概率的关系?
全概率公式,总结几种因素,事情发生的概率的并集。由因求果。贝叶斯公式,事情已经发生,计算引起结果的各因素的概率,由果寻因。同后验概率。
4. 什么是条件概率?
后验概率是一种条件概率。但条件概率不一定就是后验概率。
如 P(y|x),P(x|y)都是条件概率,二者表示的含义却不同。这里x表示因,y表示果。或者说x是特征,y是模型结果。
则P(y)是先验概率,而P(x|y)是后验概率。
而P(y|x)是一个条件概率,而不是后验概率。
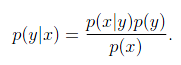
P(xy) = P(x|y)*P(y)
而一般分析问题时,已知的是特征x,需要判别结果y。
这里由推出一个判别模型。
5. 什么是判别模型?
计算判别模型P(y|x)时,需要 先验概率,后验概率作为基础。又称为条件概率模型。常见的判别模型:线性回归、对数回归/逻辑回归、SVM、boosting、条件随机场、神经网络、最近邻算法Nearest neighbor等。 这些 模型都是通过计算 条件概率的 最大似然估计推导出来。
它是在有限样本的条件下,寻找最优的分类面,关注判别模型的边缘分布。目标函数大部分直接对应 分类准确率。
6. 什么是生成模型?
主要是估计 联合概率分布。如P(x,y) = P(x|y)*P(y)生成模型 有无限的样本,可以得到其 概率密度模型, 然后可以进行预测了。
常见生成模型: 隐式马尔科夫模型、朴素贝叶斯模型、高斯混合模型、有限波兹曼机等。
因其有无限的样本,可以采用增量的方式学习模型,对于单类问题比判别模型强,信息量比判别模型丰富。主要是对后验概率建模,关注自身,而不关注边界。
由判别模型得不到生成模型,而从生成模型可以得到判别模型。
7. 高斯判别分析 与 逻辑回归的 关系
8. 贝叶斯决策理论的前提
1)各类别的概率分布是已知的,每个类别都有一类相同的特征数据,只不过相同条件下,每个类别概率不同。概率分布,概率密度分布2)类别的个数是一定的
已知先验概率、和 采集的数据特征(这个因素在每个分类上的后验概率)
就可以对该数据进行分类。原理就是条件概率,贝叶斯决策。
最小错误率的贝叶斯决策与最小风险的贝叶斯决策 的区别和联系?
最小错误率的贝叶斯决策: 结果为 maxP(yi | x)
最小风险的贝叶斯决策:是考虑了各种错误造成不同的损失而提出的一种决策。
http://blog.sciencenet.cn/home.php?mod=space&uid=248173&do=blog&id=227964 http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971903.html

相关文章推荐
- 机器学习的概率与统计知识复习总结
- 概率与统计知识复习
- MLAPP——机器学习的概率知识总结
- MLAPP——机器学习的概率知识总结
- 概率统计与机器学习:常见分布性质总结
- 机器学习笔记--概率与数理统计
- linux知识复习总结
- 概率、矩阵知识总结
- 概率统计与机器学习:期望,方差,数学期望,样本均值,样本方差之间的区别
- 关于概率和 统计的复习、思考
- 《黑马程序员》 正则表达式理论知识复习总结
- 2017 年 机器学习之数据挖据、数据分析,可视化,ML,DL,NLP等知识记录和总结
- 模式识别和机器学习中的概率知识
- 机器学习概念性知识总结
- [数学学习]数学知识回顾之概率统计与信息论
- TCP/IP相关知识复习与总结(https/网络程序性能分析)
- 【读书笔记】之概率统计知识梳理
- 机器学习(一)- 数学基础之统计概率
- 近期知识总结(计算台风面雨量及统计影响宁波的台风)
- C++指针知识的复习与简单总结