Python练手之6种经典排序算法
2013-04-23 23:42
561 查看
在入手了python之后,确实被它简单的特性和上手容易度震惊过。不过python和c语言什么的又确实存在很大的差别,习惯了c语言,使用python的时候多少还是有些不习惯。
入手python一周左右了,为了熟悉和深化对python的理解,就把几种经典的排序算法拿来练手,顺便强化一下自己的基础知识。开始写了,才发现自己写出来的代码问题还真不少,排序的结果总是有各种问题,看来真的是很久没有用这些算法写过东西了,都忘了一些细节的东西了,汗哪。。。
废话不多说,开始练手吧。
排序前需要给定一个数据集,这个用随机数生成就好:
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename:randata.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import random
'''''
随机生成0~10000000之间的数值
'''
def getrandata(num):
a=[]
i=0
while i<num:
a.append(random.randint(0,10000000))
i+=1
return a
经典算法之直接插入排序(Insert sort):
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename: insert_sort.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import randata
'''''
被注释掉的部分是c语言数组普通的插入方式
未被注释的部分则是使用python列表的插入和删除特性改善的
'''
def insertSort(arr):
for i in range(1,len(arr)):
'''''
tmp=arr[i]
j=i
while j>0 and tmp<arr[j-1]:
arr[j]=arr[j-1]
j-=1
arr[j]=tmp
'''
j=i
while j>0
and arr[j-1]>arr[i]:
j-=1
arr.insert(j,arr[i])
arr.pop(i+1)
希尔排序的名称源于它的发明者Donald Shell,该算法是冲破二次时间屏障的第一批算法之一,不过,直到它最初被发现的若干年后才被证明了它的亚二次时间界。它通过比较相距一定间隔的元素来工作;各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
经典算法之归并排序(Merge sort):
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename: merge_sort.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import randata
'''''
使用新分配的空间存储合并得到的新列表
arr: 原始列表(数组)
s: 需合并的第一段空间起始点
m: 需合并的第二段空间起始点
e: 需合并的第二段空间结束点
'''
def mergeWithNewSpace(arr,s,m,e):
i,j=s,m
t=0
newArr=[]
while i<m and j<=e:
if(arr[i]<arr[j]):
newArr.append(arr[i])
i+=1
t+=1
else:
newArr.append(arr[j])
j+=1
t+=1
if i>=m:
t=0
for i in range(s,j):
arr[i]=newArr[t]
t+=1
else:
t=0
for i in range(i,m):
newArr.append(arr[i])
for i in range(s,e+1):
arr[i]=newArr[t]
t+=1
del newArr
def mergePassWithNewSpace(arr, n, d):
i=0
while i<(n-d) and i<(n+1-2*d):
mergeWithNewSpace(arr,i,i+d,i+2*d-1)
i=i+2*d
if i<n-d:
mergeWithNewSpace(arr,i,i+d,n-1)
else:
mergeWithNewSpace(arr,i-2*d,i,n-1)
def mergeSortWithNewSpace(arr):
d=1
while d<len(arr):
mergePassWithNewSpace(arr,len(arr),d)
d*=2
'''''
不分配新的空间存储合并得到的列表
而是使用原列表使用插入方式存储
arr: 原始列表(数组)
s: 需合并的第一段空间起始点
m: 需合并的第二段空间起始点
e: 需合并的第二段空间结束点
被注释掉的部分是c语言数组普通的插入方式
未被注释的部分则是使用python列表的插入和删除特性改善的
'''
def mergeWithoutNewSpace(arr,s,m,e):
i,j=s,m
while i<m and j<=e:
if arr[i]>arr[j]:
'''''
tmp=arr[j]
k=j
while k>i:
arr[k]=arr[k-1]
k-=1
arr[i]=tmp
'''
arr.insert(i,arr[j])
arr.pop(j+1)
j+=1
m+=1
else:
i+=1
'''''
arr: 原始列表(数组)
n: 数组大小
d: 区间大小
'''
def mergePassWithoutNewSpace(arr, n, d):
i=0
while i<(n-d)
and i<(n+1-2*d):
mergeWithoutNewSpace(arr,i,i+d,i+2*d-1)
i=i+2*d
if i<n-d:
mergeWithoutNewSpace(arr,i,i+d,n-1)
else:
mergeWithoutNewSpace(arr,i-2*d,i,n-1)
def mergeSortWithoutNewSpace(arr):
d=1
while d<len(arr):
mergePassWithoutNewSpace(arr,len(arr),d)
d*=2
堆排序的思路是建立在大根堆和小根堆的基础上,具体步骤可以参见网上解释以及上面的源码。
经典算法之快速排序:
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename:quick_sort.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import randata
import sys
'''''
这个函数的作用是,从区间的第一个,最后一个和最中间的位置上选出一个中间大小的值,并把它放置在区间的第一个位置上
这样有效消除预排序的最坏情况
'''
def median(a,start,end):
center=(start+end)/2
if a[start]>a[center]:
a[start],a[center]=a[center],a[start]
if a[start]>a[end]:
a[start],a[end]=a[end],a[start]
if a[center]>a[end]:
a[center],a[end]=a[end],a[center]
a[start],a[center]=a[center],a[start]
def doSwap(a,start,end):
if start>=end:
return
i,j=start,end
median(a,start,end)
tmp=a[start]
while(True):
while(a[j]>tmp and i<j):
j-=1
if i<j:
a[i]=a[j]
i+=1
while(a[i]<tmp
and i<j):
i+=1
if i<j:
a[j]=a[i]
j-=1
else:
break
a[i]=tmp
doSwap(a,start,i-1)
doSwap(a,j+1,end)
def quickSort(a):
#设置递归深度为10000000,放置数据量过大时超出递归最大深度发生exception
sys.setrecursionlimit(1000000)
doSwap(a,0,len(a)-1)
这是某次执行的结果:
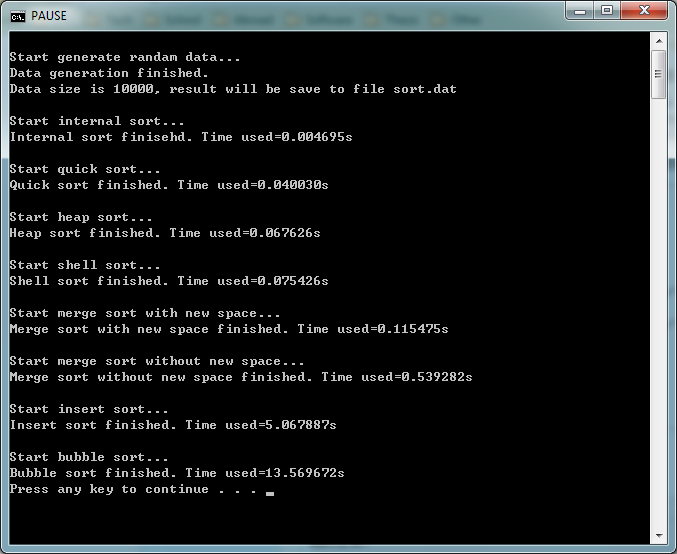
输出结果被保存在当前目录的sort.dat文件中,用记事本打开即可看到。
(看看人家python内置的timSort排序算法,根本就不是一个数量级的,真牛,好快呀。。。)
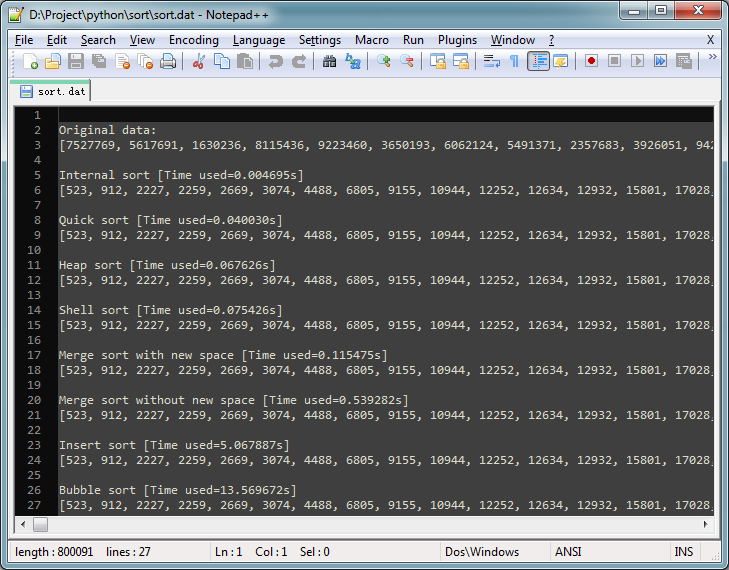
这就是输出文件的内容显示:
入手python一周左右了,为了熟悉和深化对python的理解,就把几种经典的排序算法拿来练手,顺便强化一下自己的基础知识。开始写了,才发现自己写出来的代码问题还真不少,排序的结果总是有各种问题,看来真的是很久没有用这些算法写过东西了,都忘了一些细节的东西了,汗哪。。。
废话不多说,开始练手吧。
排序前需要给定一个数据集,这个用随机数生成就好:
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename:randata.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import random
'''''
随机生成0~10000000之间的数值
'''
def getrandata(num):
a=[]
i=0
while i<num:
a.append(random.randint(0,10000000))
i+=1
return a
[python] view plaincopyprint? #-*- coding: utf-8 -*- #!/usr/bin/python #Filename:bubble_sort.py #Author: Boyce #Email: boyce.ywr@gmail.com import randata ''''' 算法思想:每次从最后开始往前滚,邻接元素两两相比,小元素交换到前面 第一轮循环把最小的元素上浮至第一个位置,第二小的元素上浮至第二个位置,依次类推 ''' def bubbleSort(a): l=len(a)-2 i=0 while i<l: j=l while j>=i: if(a[j+1]<a[j]): a[j],a[j+1]=a[j+1],a[j] j-=1 i+=1 #-*- coding: utf-8 -*- #!/usr/bin/python #Filename:bubble_sort.py #Author: Boyce #Email: boyce.ywr@gmail.com import randata ''' 算法思想:每次从最后开始往前滚,邻接元素两两相比,小元素交换到前面 第一轮循环把最小的元素上浮至第一个位置,第二小的元素上浮至第二个位置,依次类推 ''' def bubbleSort(a): l=len(a)-2 i=0 while i<l: j=l while j>=i: if(a[j+1]<a[j]): a[j],a[j+1]=a[j+1],a[j] j-=1 i+=1
经典算法之直接插入排序(Insert sort):
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename: insert_sort.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import randata
'''''
被注释掉的部分是c语言数组普通的插入方式
未被注释的部分则是使用python列表的插入和删除特性改善的
'''
def insertSort(arr):
for i in range(1,len(arr)):
'''''
tmp=arr[i]
j=i
while j>0 and tmp<arr[j-1]:
arr[j]=arr[j-1]
j-=1
arr[j]=tmp
'''
j=i
while j>0
and arr[j-1]>arr[i]:
j-=1
arr.insert(j,arr[i])
arr.pop(i+1)
[python] view plaincopyprint? #-*- coding: utf-8 -*- #!/usr/bin/python #Filename: shell_sort.py #Author: Boyce #Email: boyce.ywr@gmail.com import randata def shellSort(arr): dist=len(arr)/2 while dist>0: for i in range(dist,len(arr)): tmp=arr[i] j=i while j>=dist and tmp<arr[j-dist]: arr[j]=arr[j-dist] j-=dist arr[j]=tmp dist/=2 #-*- coding: utf-8 -*- #!/usr/bin/python #Filename: shell_sort.py #Author: Boyce #Email: boyce.ywr@gmail.com import randata def shellSort(arr): dist=len(arr)/2 while dist>0: for i in range(dist,len(arr)): tmp=arr[i] j=i while j>=dist and tmp<arr[j-dist]: arr[j]=arr[j-dist] j-=dist arr[j]=tmp dist/=2
希尔排序的名称源于它的发明者Donald Shell,该算法是冲破二次时间屏障的第一批算法之一,不过,直到它最初被发现的若干年后才被证明了它的亚二次时间界。它通过比较相距一定间隔的元素来工作;各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
经典算法之归并排序(Merge sort):
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename: merge_sort.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import randata
'''''
使用新分配的空间存储合并得到的新列表
arr: 原始列表(数组)
s: 需合并的第一段空间起始点
m: 需合并的第二段空间起始点
e: 需合并的第二段空间结束点
'''
def mergeWithNewSpace(arr,s,m,e):
i,j=s,m
t=0
newArr=[]
while i<m and j<=e:
if(arr[i]<arr[j]):
newArr.append(arr[i])
i+=1
t+=1
else:
newArr.append(arr[j])
j+=1
t+=1
if i>=m:
t=0
for i in range(s,j):
arr[i]=newArr[t]
t+=1
else:
t=0
for i in range(i,m):
newArr.append(arr[i])
for i in range(s,e+1):
arr[i]=newArr[t]
t+=1
del newArr
def mergePassWithNewSpace(arr, n, d):
i=0
while i<(n-d) and i<(n+1-2*d):
mergeWithNewSpace(arr,i,i+d,i+2*d-1)
i=i+2*d
if i<n-d:
mergeWithNewSpace(arr,i,i+d,n-1)
else:
mergeWithNewSpace(arr,i-2*d,i,n-1)
def mergeSortWithNewSpace(arr):
d=1
while d<len(arr):
mergePassWithNewSpace(arr,len(arr),d)
d*=2
'''''
不分配新的空间存储合并得到的列表
而是使用原列表使用插入方式存储
arr: 原始列表(数组)
s: 需合并的第一段空间起始点
m: 需合并的第二段空间起始点
e: 需合并的第二段空间结束点
被注释掉的部分是c语言数组普通的插入方式
未被注释的部分则是使用python列表的插入和删除特性改善的
'''
def mergeWithoutNewSpace(arr,s,m,e):
i,j=s,m
while i<m and j<=e:
if arr[i]>arr[j]:
'''''
tmp=arr[j]
k=j
while k>i:
arr[k]=arr[k-1]
k-=1
arr[i]=tmp
'''
arr.insert(i,arr[j])
arr.pop(j+1)
j+=1
m+=1
else:
i+=1
'''''
arr: 原始列表(数组)
n: 数组大小
d: 区间大小
'''
def mergePassWithoutNewSpace(arr, n, d):
i=0
while i<(n-d)
and i<(n+1-2*d):
mergeWithoutNewSpace(arr,i,i+d,i+2*d-1)
i=i+2*d
if i<n-d:
mergeWithoutNewSpace(arr,i,i+d,n-1)
else:
mergeWithoutNewSpace(arr,i-2*d,i,n-1)
def mergeSortWithoutNewSpace(arr):
d=1
while d<len(arr):
mergePassWithoutNewSpace(arr,len(arr),d)
d*=2
[python] view plaincopyprint? #-*- coding: utf-8 -*- #!/usr/bin/python #Filename:heap_sort.py #Author: Boyce #Email: boyce.ywr@gmail.com ''''' 大根堆:在一棵完全二叉树中,对于任意节点,满足性质arr[i]>=arr[2*i], arr[i]>=arr[2*i+1] 小根堆:在一棵完全二叉树中,对于任意节点,满足性质arr[i]<=arr[2*i], arr[i]<=arr[2*i+1] ''' import randata ''''' 假定除了start位置的顶点外,以start位置为root的这棵二叉树是一个大根堆 向下调整start位置的节点至合适的位置,是的这棵树重新恢复为一个大根堆 ''' def adjust(arr,start,size): tmp=arr[start] j=2*start+1 while j<size: if j<size-1 and arr[j]<arr[j+1]: j+=1 if tmp>=arr[j]: break arr[start]=arr[j] start=j j=2*j+1 arr[start]=tmp ''''' 从一堆乱序的元素列表中建立大根堆 ''' def buildHeap(arr): size=len(arr) for i in range(size/2-1,-1,-1): adjust(arr,i,size) def heapSort(arr): size=len(arr) buildHeap(arr) ''''' 建立大根堆后,第一个元素为列表的最大元素,将它跟最后一个元素交换,列表大小-1 重新调整列表为大根堆,重复此操作直到最后一个元素 ''' for i in range(size-1,0,-1): arr[i],arr[0]=arr[0],arr[i] adjust(arr,0,i) #-*- coding: utf-8 -*- #!/usr/bin/python #Filename:heap_sort.py #Author: Boyce #Email: boyce.ywr@gmail.com ''' 大根堆:在一棵完全二叉树中,对于任意节点,满足性质arr[i]>=arr[2*i], arr[i]>=arr[2*i+1] 小根堆:在一棵完全二叉树中,对于任意节点,满足性质arr[i]<=arr[2*i], arr[i]<=arr[2*i+1] ''' import randata ''' 假定除了start位置的顶点外,以start位置为root的这棵二叉树是一个大根堆 向下调整start位置的节点至合适的位置,是的这棵树重新恢复为一个大根堆 ''' def adjust(arr,start,size): tmp=arr[start] j=2*start+1 while j<size: if j<size-1 and arr[j]<arr[j+1]: j+=1 if tmp>=arr[j]: break arr[start]=arr[j] start=j j=2*j+1 arr[start]=tmp ''' 从一堆乱序的元素列表中建立大根堆 ''' def buildHeap(arr): size=len(arr) for i in range(size/2-1,-1,-1): adjust(arr,i,size) def heapSort(arr): size=len(arr) buildHeap(arr) ''' 建立大根堆后,第一个元素为列表的最大元素,将它跟最后一个元素交换,列表大小-1 重新调整列表为大根堆,重复此操作直到最后一个元素 ''' for i in range(size-1,0,-1): arr[i],arr[0]=arr[0],arr[i] adjust(arr,0,i)
堆排序的思路是建立在大根堆和小根堆的基础上,具体步骤可以参见网上解释以及上面的源码。
经典算法之快速排序:
[python]
view plaincopyprint?
#-*- coding: utf-8 -*-
#!/usr/bin/python
#Filename:quick_sort.py
#Author: Boyce
#Email: boyce.ywr@gmail.com
import randata
import sys
'''''
这个函数的作用是,从区间的第一个,最后一个和最中间的位置上选出一个中间大小的值,并把它放置在区间的第一个位置上
这样有效消除预排序的最坏情况
'''
def median(a,start,end):
center=(start+end)/2
if a[start]>a[center]:
a[start],a[center]=a[center],a[start]
if a[start]>a[end]:
a[start],a[end]=a[end],a[start]
if a[center]>a[end]:
a[center],a[end]=a[end],a[center]
a[start],a[center]=a[center],a[start]
def doSwap(a,start,end):
if start>=end:
return
i,j=start,end
median(a,start,end)
tmp=a[start]
while(True):
while(a[j]>tmp and i<j):
j-=1
if i<j:
a[i]=a[j]
i+=1
while(a[i]<tmp
and i<j):
i+=1
if i<j:
a[j]=a[i]
j-=1
else:
break
a[i]=tmp
doSwap(a,start,i-1)
doSwap(a,j+1,end)
def quickSort(a):
#设置递归深度为10000000,放置数据量过大时超出递归最大深度发生exception
sys.setrecursionlimit(1000000)
doSwap(a,0,len(a)-1)
[python] view plaincopyprint? #-*- coding: utf-8 -*- #!/usr/bin/python #Filename:sort.py #Author: Boyce #Email: boyce.ywr@gmail.com import time import randata import bubble_sort import quick_sort import heap_sort import shell_sort import merge_sort import insert_sort fileName='sort.dat' size=10000 print '/nStart generate randam data...' arr=randata.getrandata(size) print 'Data generation finished.' print 'Data size is %d, result will be save to file %s'%(size,fileName) f=file(fileName,'w') f.write("/nOriginal data:/n") f.write(str(arr)) #使用python内置的timSort排序算法 a=arr[:] print '/nStart internal sort...' t1=time.clock() a.sort() t2=time.clock() print 'Internal sort finisehd. Time used=%fs'%(t2-t1) f.write('/n/nInternal sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart quick sort...' t1=time.clock() quick_sort.quickSort(a) t2=time.clock() print 'Quick sort finished. Time used=%fs'%(t2-t1) f.write('/n/nQuick sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart heap sort...' t1=time.clock() heap_sort.heapSort(a) t2=time.clock() print 'Heap sort finished. Time used=%fs'%(t2-t1) f.write('/n/nHeap sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart shell sort...' t1=time.clock() shell_sort.shellSort(a) t2=time.clock() print 'Shell sort finished. Time used=%fs'%(t2-t1) f.write('/n/nShell sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart merge sort with new space...' t1=time.clock() merge_sort.mergeSortWithNewSpace(a) t2=time.clock() print 'Merge sort with new space finished. Time used=%fs'%(t2-t1) f.write('/n/nMerge sort with new space [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart merge sort without new space...' t1=time.clock() merge_sort.mergeSortWithoutNewSpace(a) t2=time.clock() print 'Merge sort without new space finished. Time used=%fs'%(t2-t1) f.write('/n/nMerge sort without new space [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart insert sort...' t1=time.clock() insert_sort.insertSort(a) t2=time.clock() print 'Insert sort finished. Time used=%fs'%(t2-t1) f.write('/n/nInsert sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart bubble sort...' t1=time.clock() bubble_sort.bubbleSort(a) t2=time.clock() print 'Bubble sort finished. Time used=%fs'%(t2-t1) f.write('/n/nBubble sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a f.close() #-*- coding: utf-8 -*- #!/usr/bin/python #Filename:sort.py #Author: Boyce #Email: boyce.ywr@gmail.com import time import randata import bubble_sort import quick_sort import heap_sort import shell_sort import merge_sort import insert_sort fileName='sort.dat' size=10000 print '/nStart generate randam data...' arr=randata.getrandata(size) print 'Data generation finished.' print 'Data size is %d, result will be save to file %s'%(size,fileName) f=file(fileName,'w') f.write("/nOriginal data:/n") f.write(str(arr)) #使用python内置的timSort排序算法 a=arr[:] print '/nStart internal sort...' t1=time.clock() a.sort() t2=time.clock() print 'Internal sort finisehd. Time used=%fs'%(t2-t1) f.write('/n/nInternal sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart quick sort...' t1=time.clock() quick_sort.quickSort(a) t2=time.clock() print 'Quick sort finished. Time used=%fs'%(t2-t1) f.write('/n/nQuick sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart heap sort...' t1=time.clock() heap_sort.heapSort(a) t2=time.clock() print 'Heap sort finished. Time used=%fs'%(t2-t1) f.write('/n/nHeap sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart shell sort...' t1=time.clock() shell_sort.shellSort(a) t2=time.clock() print 'Shell sort finished. Time used=%fs'%(t2-t1) f.write('/n/nShell sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart merge sort with new space...' t1=time.clock() merge_sort.mergeSortWithNewSpace(a) t2=time.clock() print 'Merge sort with new space finished. Time used=%fs'%(t2-t1) f.write('/n/nMerge sort with new space [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart merge sort without new space...' t1=time.clock() merge_sort.mergeSortWithoutNewSpace(a) t2=time.clock() print 'Merge sort without new space finished. Time used=%fs'%(t2-t1) f.write('/n/nMerge sort without new space [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart insert sort...' t1=time.clock() insert_sort.insertSort(a) t2=time.clock() print 'Insert sort finished. Time used=%fs'%(t2-t1) f.write('/n/nInsert sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a a=arr[:] print '/nStart bubble sort...' t1=time.clock() bubble_sort.bubbleSort(a) t2=time.clock() print 'Bubble sort finished. Time used=%fs'%(t2-t1) f.write('/n/nBubble sort [Time used=%fs]/n'%(t2-t1)) f.write(str(a)) del a f.close()
这是某次执行的结果:
输出结果被保存在当前目录的sort.dat文件中,用记事本打开即可看到。
(看看人家python内置的timSort排序算法,根本就不是一个数量级的,真牛,好快呀。。。)
这就是输出文件的内容显示:

相关文章推荐
- Python练手之6种经典排序算法
- Python练手之6种经典排序算法
- Python练手之6种经典排序算法
- python实现经典排序算法
- Python:经典排序算法实现
- 经典排序算法:归并排序(python)
- Python实现经典排序算法(转载)
- 经典排序算法总结与实现 ---python
- Python实现经典排序算法
- python(三)6种排序算法性能比较(冒泡、选择、插入、希尔、快速、归并)
- 基于python的七种经典排序算法
- Python实现经典内部排序算法(归并排序)
- 经典排序算法python回顾之一 交换排序
- Python练手经典100例
- 十大经典排序算法python
- 经典排序算法python回顾之四 二叉查找树排序
- 基于python的七种经典排序算法
- 经典排序算法:堆排序(python)
- 经典排序算法的python实现
- 优雅的python 写排序算法