muduo网络编程库学习
2013-03-27 16:10
260 查看
muduo网络编程库介绍:http://blog.csdn.net/solstice/article/details/5848547
连接的建立,包括服务端接受 (accept) 新连接和客户端成功发起 (connect) 连接。
连接的断开,包括主动断开 (close 或 shutdown) 和被动断开 (read 返回 0)。
消息到达,文件描述符可读。这是最为重要的一个事件,对它的处理方式决定了网络编程的风格(阻塞还是非阻塞,如何处理分包,应用层的缓冲如何设计等等)。
消息发送完毕,这算半个。对于低流量的服务,可以不必关心这个事件;另外,这里“发送完毕”是指将数据写入操作系统的缓冲区,将由 TCP 协议栈负责数据的发送与重传,不代表对方已经收到数据。
这其中有很多难点,也有很多细节需要注意,比方说:
如果要主动关闭连接,如何保证对方已经收到全部数据?如果应用层有缓冲(这在非阻塞网络编程中是必须的,见下文),那么如何保证先发送完缓冲区中的数据,然后再断开连接。直接调用 close(2) 恐怕是不行的。
如果主动发起连接,但是对方主动拒绝,如何定期 (带 back-off) 重试?
非阻塞网络编程该用边沿触发(edge trigger)还是电平触发(level trigger)?(这两个中文术语有其他译法,我选择了一个电子工程师熟悉的说法。)如果是电平触发,那么什么时候关注 EPOLLOUT 事件?会不会造成 busy-loop?如果是边沿触发,如何防止漏读造成的饥饿?epoll 一定比 poll 快吗?
在非阻塞网络编程中,为什么要使用应用层缓冲区?假如一次读到的数据不够一个完整的数据包,那么这些已经读到的数据是不是应该先暂存在某个地方,等剩余的数据收到之后再一并处理?见 lighttpd 关于/r/n/r/n 分包的 bug。假如数据是一个字节一个字节地到达,间隔 10ms,每个字节触发一次文件描述符可读 (readable) 事件,程序是否还能正常工作?lighttpd 在这个问题上出过安全漏洞。
在非阻塞网络编程中,如何设计并使用缓冲区?一方面我们希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。另一方面,我们系统减少内存占用。如果有 10k 个连接,每个连接一建立就分配 64k 的读缓冲的话,将占用 640M 内存,而大多数时候这些缓冲区的使用率很低。muduo 用 readv 结合栈上空间巧妙地解决了这个问题。
如果使用发送缓冲区,万一接收方处理缓慢,数据会不会一直堆积在发送方,造成内存暴涨?如何做应用层的流量控制?
如何设计并实现定时器?并使之与网络 IO 共用一个线程,以避免锁。
C10k 问题的页面介绍了五种 IO 策略,把线程也纳入考量。(现在 C10k 已经不是什么问题,C100k 也不是大问题,C1000k 才算得上挑战)。
在这个多核时代,线程是不可避免的。那么服务端网络编程该如何选择线程模型呢?我赞同 libev 作者的观点:one loop per thread is usually a good model。之前我也不止一次表述过这个观点,见《多线程服务器的常用编程模型》《多线程服务器的适用场合》。
如果采用 one loop per thread 的模型,多线程服务端编程的问题就简化为如何设计一个高效且易于使用的 event loop,然后每个线程 run 一个 event loop 就行了(当然、同步和互斥是不可或缺的)。在“高效”这方面已经有了很多成熟的范例(libev、libevent、memcached、varnish、lighttpd、nginx),在“易于使用”方面我希望 muduo 能有所作为。(muduo 可算是用现代 C++ 实现了 Reactor 模式,比起原始的 Reactor 来说要好用得多。)
event loop 是 non-blocking 网络编程的核心,在现实生活中,non-blocking 几乎总是和 IO-multiplexing 一起使用,原因有两点:
没有人真的会用轮询 (busy-pooling) 来检查某个 non-blocking IO 操作是否完成,这样太浪费 CPU cycles。
IO-multiplex 一般不能和 blocking IO 用在一起,因为 blocking IO 中 read()/write()/accept()/connect() 都有可能阻塞当前线程,这样线程就没办法处理其他 socket 上的 IO 事件了。见 UNPv1 第 16.6 节“nonblocking accept”的例子。
所以,当我提到 non-blocking 的时候,实际上指的是 non-blocking + IO-muleiplexing,单用其中任何一个是不现实的。
当然,non-blocking 编程比 blocking 难得多。基于 event loop 的网络编程跟直接用 C/C++ 编写单线程 Windows 程序颇为相像:程序不能阻塞,否则窗口就失去响应了;在 event handler 中,程序要尽快交出控制权,返回窗口的事件循环。
对于应用程序而言,它只管生成数据,它不应该关心到底数据是一次性发送还是分成几次发送,这些应该由网络库来操心,程序只要调用 TcpConnection::send() 就行了,网络库会负责到底。网络库应该接管这剩余的 20k 字节数据,把它保存在该 TCP connection 的 output buffer 里,然后注册 POLLOUT 事件,一旦 socket 变得可写就立刻发送数据。当然,这第二次 write() 也不一定能完全写入 20k 字节,如果还有剩余,网络库应该继续关注 POLLOUT 事件;如果写完了 20k 字节,网络库应该停止关注 POLLOUT,以免造成 busy loop。
如果程序又写入了 50k 字节,而这时候 output buffer 里还有待发送的 20k 数据,那么网络库不应该直接调用 write(),而应该把这 50k 数据 append 在那 20k 数据之后,等 socket 变得可写的时候再一并写入。
如果 output buffer 里还有待发送的数据,而程序又想关闭连接(对程序而言,调用 TcpConnection::send() 之后他就认为数据迟早会发出去),那么这时候网络库不能立刻关闭连接,而要等数据发送完毕。
综上,要让程序在 write 操作上不阻塞,网络库必须要给每个 tcp connection 配置 output buffer。
一次性收到 20k 数据
分两次收到,第一次 5k,第二次 15k
分两次收到,第一次 15k,第二次 5k
分两次收到,第一次 10k,第二次 10k
分三次收到,第一次 6k,第二次 8k,第三次 6k
其他任何可能
网络库在处理“socket 可读”事件的时候,必须一次性把 socket 里的数据读完(从操作系统 buffer 搬到应用层 buffer),否则会反复触发 POLLIN 事件,造成 busy-loop。
那么网络库必然要应对“数据不完整”的情况,收到的数据先放到 input buffer 里,等构成一条完整的消息再通知程序的业务逻辑。这通常是 codec 的职责。所以,在 tcp 网络编程中,网络库必须要给每个 tcp connection 配置 input buffer。
对于网络程序来说,一个简单的验收测试是:输入数据每次收到一个字节(200 字节的输入数据会分 200 次收到,每次间隔 10 ms),程序的功能不受影响。
如果某个网络库只提供相当于 char buf[8192] 的缓冲,或者根本不提供缓冲区,而仅仅通知程序“某 socket 可读/某 socket 可写”,要程序自己操心 IO buffering,这样的网络库用起来就很不方便了。
随着 2000 年前后第一次互联网浪潮的兴起,业界对高并发 http 服务器的强烈需求大大推动了这一领域的研究,目前高性能 httpd 普遍采用的是单线程 reactor 方式。另外一个说法是 IBM Lotus 使用 TCP 长连接协议,而把 Lotus 服务端移植到 Linux 的过程中 IBM 的工程师们大大提高了 Linux 内核在处理并发连接方面的可伸缩性,因为一个公司可能有上万人同时上线,连接到同一台跑着 Lotus server 的 Linux 服务器。
可伸缩网络编程这个领域其实近十年来没什么新东西,POSA2 已经作了相当全面的总结,另外以下几篇文章也值得参考。
http://bulk.fefe.de/scalable-networking.pdf
http://www.kegel.com/c10k.html
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
下表是陈硕总结的 10 种常见方案。其中“多连接互通”指的是如果开发 chat 服务,多个客户连接之间是否能方便地交换数据(chat 也是《谈一谈网络编程学习经验》中举的三大 TCP 网络编程案例之一)。对于 echo/http/sudoku 这类“连接相互独立”的服务程序,这个功能无足轻重,但是对于 chat 类服务至关重要。“顺序性”指的是在 http/sudoku 这类请求-响应服务中,如果客户连接顺序发送多个请求,那么计算得到的多个响应是否按相同的顺序发还给客户(这里指的是在自然条件下,不含刻意同步)。
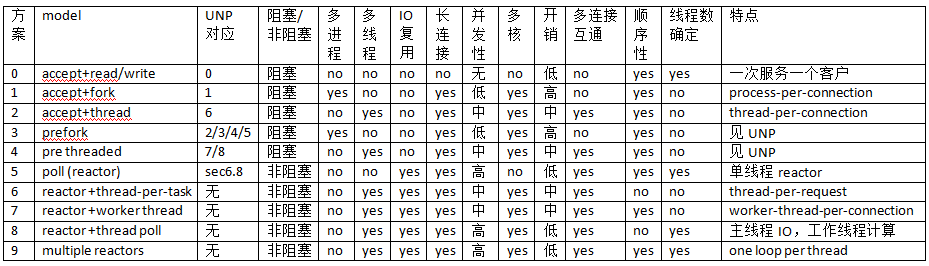
UNP CSDA 方案归入 0~5。5 也是目前用得很多的单线程 reactor 方案,muduo 对此提供了很好的支持。6 和 7 其实不是实用的方案,只是作为过渡品。8 和 9 是本文重点介绍的方案,其实这两个方案已经在《多线程服务器的常用编程模型》一文中提到过,只不过当时我还没有写 muduo,无法用具体的代码示例来说明。
在对比各方案之前,我们先看看基本的 micro benchmark 数据(前三项由 lmbench 测得):
fork()+exit(): 160us
pthread_create()+pthread_join(): 12us
context switch : 1.5us
sudoku resolve: 100us (根据题目难度不同,浮动范围 20~200us)
方案 0:这其实不是并发服务器,而是 iterative 服务器,因为它一次只能服务一个客户。代码见 UNP figure 1.9,UNP 以此为对比其他方案的基准点。这个方案不适合长连接,到是很适合 daytime 这种 write-only 服务。
方案 1:这是传统的 Unix 并发网络编程方案,UNP 称之为 child-per-client 或 fork()-per-client,另外也俗称 process-per-connection。这种方案适合并发连接数不大的情况。至今仍有一些网络服务程序用这种方式实现,比如 PostgreSQL 和 Perforce 的服务端。这种方案适合“计算响应的工作量远大于 fork() 的开销”这种情况,比如数据库服务器。这种方案适合长连接,但不太适合短连接,因为 fork() 开销大于求解 sudoku 的用时。
方案 2:这是传统的 Java 网络编程方案 thread-per-connection,在 Java 1.4 引入 NIO 之前,Java 网络服务程序多采用这种方案。它的初始化开销比方案 1 要小很多。这种方案的伸缩性受到线程数的限制,一两百个还行,几千个的话对操作系统的 scheduler 恐怕是个不小的负担。
方案 3:这是针对方案 1 的优化,UNP 详细分析了几种变化,包括对 accept 惊群问题的考虑。
方案 4:这是对方案 2 的优化,UNP 详细分析了它的几种变化。
以上几种方案都是阻塞式网络编程,程序(thread-of-control)通常阻塞在 read() 上,等待数据到达。但是 TCP 是个全双工协议,同时支持 read() 和 write() 操作,当一个线程/进程阻塞在 read() 上,但程序又想给这个 TCP 连接发数据,那该怎么办?比如说 echo client,既要从 stdin 读,又要从网络读,当程序正在阻塞地读网络的时候,如何处理键盘输入?又比如 proxy,既要把连接 a 收到的数据发给连接 b,又要把从连接 b 收到的数据发给连接 a,那么到底读哪个?(proxy 是《谈一谈网络编程学习经验》中举的三大 TCP 网络编程案例之一。)
一种方法是用两个线程/进程,一个负责读,一个负责写。UNP 也在实现 echo client 时介绍了这种方案。另外见 Python Pinhole 的代码:http://code.activestate.com/recipes/114642/
另一种方法是使用 IO multiplexing,也就是 select/poll/epoll/kqueue 这一系列的“多路选择器”,让一个 thread-of-control 能处理多个连接。“IO 复用”其实复用的不是 IO 连接,而是复用线程。使用 select/poll 几乎肯定要配合 non-blocking IO,而使用 non-blocking IO 肯定要使用应用层 buffer,原因见《Muduo 设计与实现之一:Buffer 类的设计》。这就不是一件轻松的事儿了,如果每个程序都去搞一套自己的 IO multiplexing 机制(本质是 event-driven 事件驱动),这是一种很大的浪费。感谢 Doug Schmidt 为我们总结出了 Reactor 模式,让 event-driven 网络编程有章可循。继而出现了一些通用的 reactor 框架/库,比如 libevent、muduo、Netty、twisted、POE 等等,有了这些库,我想基本不用去编写阻塞式的网络程序了(特殊情况除外,比如 proxy 流量限制)。
单线程 reactor 的程序结构是(图片取自 Doug Lea 的演讲):
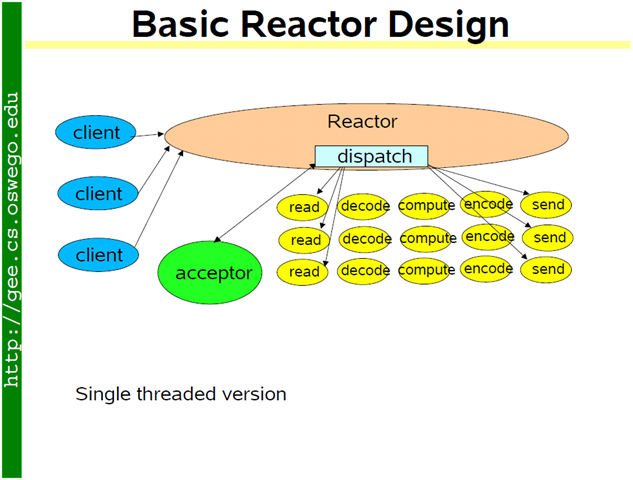
方案 5:基本的单线程 reactor 方案,即前面的 server_basic.cc 程序。本文以它作为对比其他方案的基准点。这种方案的优点是由网络库搞定数据收发,程序只关心业务逻辑;缺点在前面已经谈了:适合 IO 密集的应用,不太适合 CPU 密集的应用,因为较难发挥多核的威力。
方案 6:这是一个过渡方案,收到 Sudoku 请求之后,不在 reactor 线程计算,而是创建一个新线程去计算,以充分利用多核 CPU。这是非常初级的多线程应用,因为它为每个请求(而不是每个连接)创建了一个新线程。这个开销可以用线程池来避免,即方案 8。这个方案还有一个特点是 out-of-order,即同时创建多个线程去计算同一个连接上收到的多个请求,那么算出结果的次序是不确定的,可能第 2 个 Sudoku 比较简单,比第 1 个先算出结果。这也是为什么我们在一开始设计协议的时候使用了 id,以便客户端区分 response 对应的是哪个 request。
方案 7:为了让返回结果的顺序确定,我们可以为每个连接创建一个计算线程,每个连接上的请求固定发给同一个线程去算,先到先得。这也是一个过渡方案,因为并发连接数受限于线程数目,这个方案或许还不如直接使用阻塞 IO 的 thread-per-connection 方案2。方案 7 与方案 6 的另外一个区别是一个 client 的最大 CPU 占用率,在方案 6 中,一个 connection 上发来的一长串突发请求(burst requests) 可以占满全部 8 个 core;而在方案 7 中,由于每个连接上的请求固定由同一个线程处理,那么它最多占用 12.5% 的 CPU 资源。这两种方案各有优劣,取决于应用场景的需要,到底是公平性重要还是突发性能重要。这个区别在方案 8 和方案 9 中同样存在,需要根据应用来取舍。
方案 8:为了弥补方案 6 中为每个请求创建线程的缺陷,我们使用固定大小线程池,程序结构如下图。全部的 IO 工作都在一个 reactor 线程完成,而计算任务交给 thread pool。如果计算任务彼此独立,而且 IO 的压力不大,那么这种方案是非常适用的。Sudoku Solver 正好符合。代码见:http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/server_threadpool.cc 后文给出了它与方案 9 的区别。
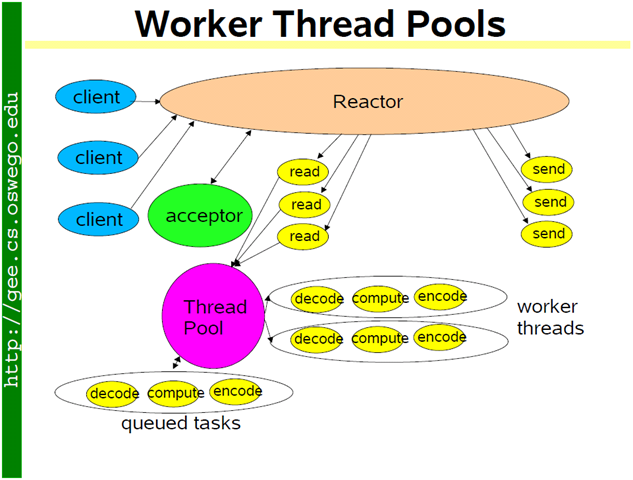
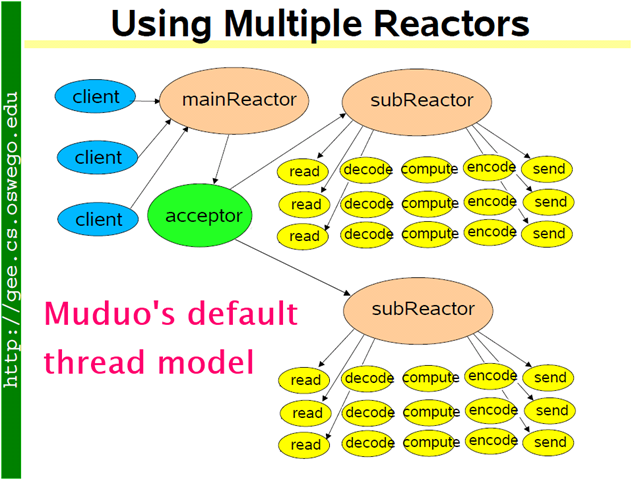
如果 IO 的压力比较大,一个 reactor 忙不过来,可以试试 multiple reactors 的方案 9。
方案 9:这是 muduo 内置的多线程方案,也是 Netty 内置的多线程方案。这种方案的特点是 one loop per thread,有一个 main reactor 负责 accept 连接,然后把连接挂在某个 sub reactor 中(muduo 采用 round-robin 的方式来选择 sub reactor),这样该连接的所有操作都在那个 sub reactor 所处的线程中完成。多个连接可能被分派到多个线程中,以充分利用 CPU。Muduo 采用的是固定大小的 reactor pool,池子的大小通常根据 CPU 核数确定,也就是说线程数是固定的,这样程序的总体处理能力不会随连接数增加而下降。另外,由于一个连接完全由一个线程管理,那么请求的顺序性有保证,突发请求也不会占满全部 8 个核(如果需要优化突发请求,可以考虑方案 10)。这种方案把 IO 分派给多个线程,防止出现一个 reactor 的处理能力饱和。与方案 8 的线程池相比,方案 9 减少了进出 thread pool 的两次上下文切换。我认为这是一个适应性很强的多线程 IO 模型,因此把它作为 muduo 的默认线程模型。
TCP 网络编程本质论
我认为,TCP 网络编程最本质的是处理三个半事件:连接的建立,包括服务端接受 (accept) 新连接和客户端成功发起 (connect) 连接。
连接的断开,包括主动断开 (close 或 shutdown) 和被动断开 (read 返回 0)。
消息到达,文件描述符可读。这是最为重要的一个事件,对它的处理方式决定了网络编程的风格(阻塞还是非阻塞,如何处理分包,应用层的缓冲如何设计等等)。
消息发送完毕,这算半个。对于低流量的服务,可以不必关心这个事件;另外,这里“发送完毕”是指将数据写入操作系统的缓冲区,将由 TCP 协议栈负责数据的发送与重传,不代表对方已经收到数据。
这其中有很多难点,也有很多细节需要注意,比方说:
如果要主动关闭连接,如何保证对方已经收到全部数据?如果应用层有缓冲(这在非阻塞网络编程中是必须的,见下文),那么如何保证先发送完缓冲区中的数据,然后再断开连接。直接调用 close(2) 恐怕是不行的。
如果主动发起连接,但是对方主动拒绝,如何定期 (带 back-off) 重试?
非阻塞网络编程该用边沿触发(edge trigger)还是电平触发(level trigger)?(这两个中文术语有其他译法,我选择了一个电子工程师熟悉的说法。)如果是电平触发,那么什么时候关注 EPOLLOUT 事件?会不会造成 busy-loop?如果是边沿触发,如何防止漏读造成的饥饿?epoll 一定比 poll 快吗?
在非阻塞网络编程中,为什么要使用应用层缓冲区?假如一次读到的数据不够一个完整的数据包,那么这些已经读到的数据是不是应该先暂存在某个地方,等剩余的数据收到之后再一并处理?见 lighttpd 关于/r/n/r/n 分包的 bug。假如数据是一个字节一个字节地到达,间隔 10ms,每个字节触发一次文件描述符可读 (readable) 事件,程序是否还能正常工作?lighttpd 在这个问题上出过安全漏洞。
在非阻塞网络编程中,如何设计并使用缓冲区?一方面我们希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。另一方面,我们系统减少内存占用。如果有 10k 个连接,每个连接一建立就分配 64k 的读缓冲的话,将占用 640M 内存,而大多数时候这些缓冲区的使用率很低。muduo 用 readv 结合栈上空间巧妙地解决了这个问题。
如果使用发送缓冲区,万一接收方处理缓慢,数据会不会一直堆积在发送方,造成内存暴涨?如何做应用层的流量控制?
如何设计并实现定时器?并使之与网络 IO 共用一个线程,以避免锁。
非阻塞IO,BUFFER的重要性
UNPv1 第 6.2 节总结了 Unix/Linux 上的五种 IO 模型:阻塞(blocking)、非阻塞(non-blocking)、IO 复用(IO multiplexing)、信号驱动(signal-driven)、异步(asynchronous)。这些都是单线程下的 IO 模型。C10k 问题的页面介绍了五种 IO 策略,把线程也纳入考量。(现在 C10k 已经不是什么问题,C100k 也不是大问题,C1000k 才算得上挑战)。
在这个多核时代,线程是不可避免的。那么服务端网络编程该如何选择线程模型呢?我赞同 libev 作者的观点:one loop per thread is usually a good model。之前我也不止一次表述过这个观点,见《多线程服务器的常用编程模型》《多线程服务器的适用场合》。
如果采用 one loop per thread 的模型,多线程服务端编程的问题就简化为如何设计一个高效且易于使用的 event loop,然后每个线程 run 一个 event loop 就行了(当然、同步和互斥是不可或缺的)。在“高效”这方面已经有了很多成熟的范例(libev、libevent、memcached、varnish、lighttpd、nginx),在“易于使用”方面我希望 muduo 能有所作为。(muduo 可算是用现代 C++ 实现了 Reactor 模式,比起原始的 Reactor 来说要好用得多。)
event loop 是 non-blocking 网络编程的核心,在现实生活中,non-blocking 几乎总是和 IO-multiplexing 一起使用,原因有两点:
没有人真的会用轮询 (busy-pooling) 来检查某个 non-blocking IO 操作是否完成,这样太浪费 CPU cycles。
IO-multiplex 一般不能和 blocking IO 用在一起,因为 blocking IO 中 read()/write()/accept()/connect() 都有可能阻塞当前线程,这样线程就没办法处理其他 socket 上的 IO 事件了。见 UNPv1 第 16.6 节“nonblocking accept”的例子。
所以,当我提到 non-blocking 的时候,实际上指的是 non-blocking + IO-muleiplexing,单用其中任何一个是不现实的。
当然,non-blocking 编程比 blocking 难得多。基于 event loop 的网络编程跟直接用 C/C++ 编写单线程 Windows 程序颇为相像:程序不能阻塞,否则窗口就失去响应了;在 event handler 中,程序要尽快交出控制权,返回窗口的事件循环。
为什么 non-blocking 网络编程中应用层 buffer 是必须的?
Non-blocking IO 的核心思想是避免阻塞在 read() 或 write() 或其他 IO 系统调用上,这样可以最大限度地复用 thread-of-control,让一个线程能服务于多个 socket 连接。IO 线程只能阻塞在 IO-multiplexing 函数上,如 select()/poll()/epoll_wait()。这样一来,应用层的缓冲是必须的,每个 TCP socket 都要有 stateful 的 input buffer 和 output buffer。TcpConnection 必须要有 output buffer
考虑一个常见场景:程序想通过 TCP 连接发送 100k 字节的数据,但是在 write() 调用中,操作系统只接受了 80k 字节(受 TCP advertised window 的控制,细节见 TCPv1),你肯定不想在原地等待,因为不知道会等多久(取决于对方什么时候接受数据,然后滑动 TCP 窗口)。程序应该尽快交出控制权,返回 event loop。在这种情况下,剩余的 20k 字节数据怎么办?对于应用程序而言,它只管生成数据,它不应该关心到底数据是一次性发送还是分成几次发送,这些应该由网络库来操心,程序只要调用 TcpConnection::send() 就行了,网络库会负责到底。网络库应该接管这剩余的 20k 字节数据,把它保存在该 TCP connection 的 output buffer 里,然后注册 POLLOUT 事件,一旦 socket 变得可写就立刻发送数据。当然,这第二次 write() 也不一定能完全写入 20k 字节,如果还有剩余,网络库应该继续关注 POLLOUT 事件;如果写完了 20k 字节,网络库应该停止关注 POLLOUT,以免造成 busy loop。
如果程序又写入了 50k 字节,而这时候 output buffer 里还有待发送的 20k 数据,那么网络库不应该直接调用 write(),而应该把这 50k 数据 append 在那 20k 数据之后,等 socket 变得可写的时候再一并写入。
如果 output buffer 里还有待发送的数据,而程序又想关闭连接(对程序而言,调用 TcpConnection::send() 之后他就认为数据迟早会发出去),那么这时候网络库不能立刻关闭连接,而要等数据发送完毕。
综上,要让程序在 write 操作上不阻塞,网络库必须要给每个 tcp connection 配置 output buffer。
TcpConnection 必须要有 input buffer
TCP 是一个无边界的字节流协议,接收方必须要处理“收到的数据尚不构成一条完整的消息”和“一次收到两条消息的数据”等等情况。一个常见的场景是,发送方 send 了两条 10k 字节的消息(共 20k),接收方收到数据的情况可能是:一次性收到 20k 数据
分两次收到,第一次 5k,第二次 15k
分两次收到,第一次 15k,第二次 5k
分两次收到,第一次 10k,第二次 10k
分三次收到,第一次 6k,第二次 8k,第三次 6k
其他任何可能
网络库在处理“socket 可读”事件的时候,必须一次性把 socket 里的数据读完(从操作系统 buffer 搬到应用层 buffer),否则会反复触发 POLLIN 事件,造成 busy-loop。
那么网络库必然要应对“数据不完整”的情况,收到的数据先放到 input buffer 里,等构成一条完整的消息再通知程序的业务逻辑。这通常是 codec 的职责。所以,在 tcp 网络编程中,网络库必须要给每个 tcp connection 配置 input buffer。
对于网络程序来说,一个简单的验收测试是:输入数据每次收到一个字节(200 字节的输入数据会分 200 次收到,每次间隔 10 ms),程序的功能不受影响。
如果某个网络库只提供相当于 char buf[8192] 的缓冲,或者根本不提供缓冲区,而仅仅通知程序“某 socket 可读/某 socket 可写”,要程序自己操心 IO buffering,这样的网络库用起来就很不方便了。
常见的并发网络服务程序设计方案
W. Richard Stevens 的 UNP2e 第 27 章 Client-Server Design Alternatives 介绍了十来种当时(90 年代末)流行的编写并发网络程序的方案。UNP3e 第 30 章,内容未变,还是这几种。以下简称 UNP CSDA 方案。UNP 这本书主要讲解阻塞式网络编程,在非阻塞方面着墨不多,仅有一章。正确使用 non-blocking IO 需要考虑的问题很多,不适宜直接调用 Sockets API,而需要一个功能完善的网络库支撑。随着 2000 年前后第一次互联网浪潮的兴起,业界对高并发 http 服务器的强烈需求大大推动了这一领域的研究,目前高性能 httpd 普遍采用的是单线程 reactor 方式。另外一个说法是 IBM Lotus 使用 TCP 长连接协议,而把 Lotus 服务端移植到 Linux 的过程中 IBM 的工程师们大大提高了 Linux 内核在处理并发连接方面的可伸缩性,因为一个公司可能有上万人同时上线,连接到同一台跑着 Lotus server 的 Linux 服务器。
可伸缩网络编程这个领域其实近十年来没什么新东西,POSA2 已经作了相当全面的总结,另外以下几篇文章也值得参考。
http://bulk.fefe.de/scalable-networking.pdf
http://www.kegel.com/c10k.html
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
下表是陈硕总结的 10 种常见方案。其中“多连接互通”指的是如果开发 chat 服务,多个客户连接之间是否能方便地交换数据(chat 也是《谈一谈网络编程学习经验》中举的三大 TCP 网络编程案例之一)。对于 echo/http/sudoku 这类“连接相互独立”的服务程序,这个功能无足轻重,但是对于 chat 类服务至关重要。“顺序性”指的是在 http/sudoku 这类请求-响应服务中,如果客户连接顺序发送多个请求,那么计算得到的多个响应是否按相同的顺序发还给客户(这里指的是在自然条件下,不含刻意同步)。
UNP CSDA 方案归入 0~5。5 也是目前用得很多的单线程 reactor 方案,muduo 对此提供了很好的支持。6 和 7 其实不是实用的方案,只是作为过渡品。8 和 9 是本文重点介绍的方案,其实这两个方案已经在《多线程服务器的常用编程模型》一文中提到过,只不过当时我还没有写 muduo,无法用具体的代码示例来说明。
在对比各方案之前,我们先看看基本的 micro benchmark 数据(前三项由 lmbench 测得):
fork()+exit(): 160us
pthread_create()+pthread_join(): 12us
context switch : 1.5us
sudoku resolve: 100us (根据题目难度不同,浮动范围 20~200us)
方案 0:这其实不是并发服务器,而是 iterative 服务器,因为它一次只能服务一个客户。代码见 UNP figure 1.9,UNP 以此为对比其他方案的基准点。这个方案不适合长连接,到是很适合 daytime 这种 write-only 服务。
方案 1:这是传统的 Unix 并发网络编程方案,UNP 称之为 child-per-client 或 fork()-per-client,另外也俗称 process-per-connection。这种方案适合并发连接数不大的情况。至今仍有一些网络服务程序用这种方式实现,比如 PostgreSQL 和 Perforce 的服务端。这种方案适合“计算响应的工作量远大于 fork() 的开销”这种情况,比如数据库服务器。这种方案适合长连接,但不太适合短连接,因为 fork() 开销大于求解 sudoku 的用时。
方案 2:这是传统的 Java 网络编程方案 thread-per-connection,在 Java 1.4 引入 NIO 之前,Java 网络服务程序多采用这种方案。它的初始化开销比方案 1 要小很多。这种方案的伸缩性受到线程数的限制,一两百个还行,几千个的话对操作系统的 scheduler 恐怕是个不小的负担。
方案 3:这是针对方案 1 的优化,UNP 详细分析了几种变化,包括对 accept 惊群问题的考虑。
方案 4:这是对方案 2 的优化,UNP 详细分析了它的几种变化。
以上几种方案都是阻塞式网络编程,程序(thread-of-control)通常阻塞在 read() 上,等待数据到达。但是 TCP 是个全双工协议,同时支持 read() 和 write() 操作,当一个线程/进程阻塞在 read() 上,但程序又想给这个 TCP 连接发数据,那该怎么办?比如说 echo client,既要从 stdin 读,又要从网络读,当程序正在阻塞地读网络的时候,如何处理键盘输入?又比如 proxy,既要把连接 a 收到的数据发给连接 b,又要把从连接 b 收到的数据发给连接 a,那么到底读哪个?(proxy 是《谈一谈网络编程学习经验》中举的三大 TCP 网络编程案例之一。)
一种方法是用两个线程/进程,一个负责读,一个负责写。UNP 也在实现 echo client 时介绍了这种方案。另外见 Python Pinhole 的代码:http://code.activestate.com/recipes/114642/
另一种方法是使用 IO multiplexing,也就是 select/poll/epoll/kqueue 这一系列的“多路选择器”,让一个 thread-of-control 能处理多个连接。“IO 复用”其实复用的不是 IO 连接,而是复用线程。使用 select/poll 几乎肯定要配合 non-blocking IO,而使用 non-blocking IO 肯定要使用应用层 buffer,原因见《Muduo 设计与实现之一:Buffer 类的设计》。这就不是一件轻松的事儿了,如果每个程序都去搞一套自己的 IO multiplexing 机制(本质是 event-driven 事件驱动),这是一种很大的浪费。感谢 Doug Schmidt 为我们总结出了 Reactor 模式,让 event-driven 网络编程有章可循。继而出现了一些通用的 reactor 框架/库,比如 libevent、muduo、Netty、twisted、POE 等等,有了这些库,我想基本不用去编写阻塞式的网络程序了(特殊情况除外,比如 proxy 流量限制)。
单线程 reactor 的程序结构是(图片取自 Doug Lea 的演讲):
方案 5:基本的单线程 reactor 方案,即前面的 server_basic.cc 程序。本文以它作为对比其他方案的基准点。这种方案的优点是由网络库搞定数据收发,程序只关心业务逻辑;缺点在前面已经谈了:适合 IO 密集的应用,不太适合 CPU 密集的应用,因为较难发挥多核的威力。
方案 6:这是一个过渡方案,收到 Sudoku 请求之后,不在 reactor 线程计算,而是创建一个新线程去计算,以充分利用多核 CPU。这是非常初级的多线程应用,因为它为每个请求(而不是每个连接)创建了一个新线程。这个开销可以用线程池来避免,即方案 8。这个方案还有一个特点是 out-of-order,即同时创建多个线程去计算同一个连接上收到的多个请求,那么算出结果的次序是不确定的,可能第 2 个 Sudoku 比较简单,比第 1 个先算出结果。这也是为什么我们在一开始设计协议的时候使用了 id,以便客户端区分 response 对应的是哪个 request。
方案 7:为了让返回结果的顺序确定,我们可以为每个连接创建一个计算线程,每个连接上的请求固定发给同一个线程去算,先到先得。这也是一个过渡方案,因为并发连接数受限于线程数目,这个方案或许还不如直接使用阻塞 IO 的 thread-per-connection 方案2。方案 7 与方案 6 的另外一个区别是一个 client 的最大 CPU 占用率,在方案 6 中,一个 connection 上发来的一长串突发请求(burst requests) 可以占满全部 8 个 core;而在方案 7 中,由于每个连接上的请求固定由同一个线程处理,那么它最多占用 12.5% 的 CPU 资源。这两种方案各有优劣,取决于应用场景的需要,到底是公平性重要还是突发性能重要。这个区别在方案 8 和方案 9 中同样存在,需要根据应用来取舍。
方案 8:为了弥补方案 6 中为每个请求创建线程的缺陷,我们使用固定大小线程池,程序结构如下图。全部的 IO 工作都在一个 reactor 线程完成,而计算任务交给 thread pool。如果计算任务彼此独立,而且 IO 的压力不大,那么这种方案是非常适用的。Sudoku Solver 正好符合。代码见:http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/server_threadpool.cc 后文给出了它与方案 9 的区别。
如果 IO 的压力比较大,一个 reactor 忙不过来,可以试试 multiple reactors 的方案 9。
方案 9:这是 muduo 内置的多线程方案,也是 Netty 内置的多线程方案。这种方案的特点是 one loop per thread,有一个 main reactor 负责 accept 连接,然后把连接挂在某个 sub reactor 中(muduo 采用 round-robin 的方式来选择 sub reactor),这样该连接的所有操作都在那个 sub reactor 所处的线程中完成。多个连接可能被分派到多个线程中,以充分利用 CPU。Muduo 采用的是固定大小的 reactor pool,池子的大小通常根据 CPU 核数确定,也就是说线程数是固定的,这样程序的总体处理能力不会随连接数增加而下降。另外,由于一个连接完全由一个线程管理,那么请求的顺序性有保证,突发请求也不会占满全部 8 个核(如果需要优化突发请求,可以考虑方案 10)。这种方案把 IO 分派给多个线程,防止出现一个 reactor 的处理能力饱和。与方案 8 的线程池相比,方案 9 减少了进出 thread pool 的两次上下文切换。我认为这是一个适应性很强的多线程 IO 模型,因此把它作为 muduo 的默认线程模型。

相关文章推荐
- Proxy源代码分析--谈谈如何学习linux网络编程
- 网络编程学习笔记(gai_strerror函数)
- java学习日记(9)———socket,网络编程的学习
- 学习网络编程-第八天
- Java网络编程学习笔记(4)非阻塞通信
- 黑马程序员-java学习笔记-网络编程
- NodeJS学习笔记之网络编程
- 网络编程学习笔记-MAC地址和IP地址的关系
- 【深度学习会被可微分编程取代?】展望30年后的神经网络和函数编程
- java系统学习(十九) --------网络编程基础
- 黑马程序员——学习笔记10.Java网络编程
- 0-Linux 网络编程学习笔记导航
- 献给想深入学习网络编程的朋友
- 网络编程学习笔记之---WebClient
- 手把手教你学习网络编程(1)
- 谈一谈网络编程学习经验
- 【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第二周作业
- Linux网络编程(3):信号处理与定时机制简要学习
- python基础教程_学习笔记24:网络编程、Python和万维网
- Python学习第二十一天——线程进程续和网络编程