快速找出数据库的性能问题之:缺失索引 &无用的索引
2013-01-09 09:40
387 查看
http://www.51testing.com/html/59/n-813259-3.html(原文有脚本下载)
我们通过减少查询中的不必要的读取操作从而使得查询的性能得到提升。一个查询在数据库中执行的读操作越多,那么就对磁盘,CPU,内存的压力越大。除非整个数据库的数据全在在内存中,否则每次的读操作都会把数据从磁盘读入到内存中,然后返回。
一个查询在读取一个资源的时候,通过加锁会阻止其他的查询对这个资源进行修改,此时其他要操作这个资源的查询就需要等待,从而导致了延时。
诚然,有些等待是必须的,读取操作也是必须的,但是一些因为我们代码或者设计导致的过度的读取操作和等待,那就会严重影响性能,尤其是当数据库的访问量开始变大的时候。
可以说在SQL Server中,最高效的读取数据方式就是通过索引去获取数据。如果在数据表中存在缺失索引的问题,结果可想而知。
在本篇中,我们将会讨论下面几个议题:
● 如何识别缺失索引性能问题
● 识别没有用的索引
● 如何解决上面的问题
确实本篇讲述的内容涉及到了一些与数据库性能调优的话题,对于调优而言,难点很多时候在于如何正确的找出性能问题。
下面,我们首先来看看缺失索引。
缺失索引
SQL Server可以在表字段上面建立索引,从而使得Where和Join这样的语句执行的更快。当查询优化器在优化一个查询的时候,它会保存一些来暗示哪些列上可能建立索引之后可能性能会更快的信息。我们可以通过动态管理视图sys.dm_db_missing_index_details来查看,运行如下查询

查询的结果如下:
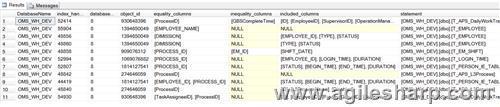
下面,我们就来稍微的解释一下结果中主要字段的含义:
当然,上面的DMV查询所得到的结果只是推荐结果,至于是否要去在相应的列上面建立索引,还需要进行综合的分析,不能单靠一方面来判断,例如,我们可以在去制定一些计划去运行SQL Profiler去跟踪数据库,然后分析跟踪的数据,并且分析这个列的数据的分布情况,分析数据的密度和差异性,而且还可以进一步的分析列的统计信息,然后决定是否要加索引。
说了这么多,可能大家感觉像是没有说,感觉有点虚。确实,我也感觉这样,因为就这分析缺失索引的问题要考虑的问题就N多。agilesharp的其他系列文章也在讨论SQL Server的性能问题,这里,我们就不多说,也不把问题搞复杂了。我再送朋友一段分析的代码,可以更好的帮助我们找到缺失索引的问题:

上面的查询比较不错,按照成本进行了分析,成本越大,就说明加了索引之后,收益就越大,可以看到如下的结果:

然后大家加了索引之后,可以多多的测试,可以查看执行计划,也可以查看查询的数据页的读取情况,I/O的情况:

没有用的索引
正如在上一小节所的讲的,创建一个索引是一个非常需要重视的问题,需要考虑很多的方面,因为,如果我们建立的索引没有发挥作用,甚至说,查询优化器不采用我们的索引,那么就会带来适得其反的效果。
索引的维护是需要成本,甚至使得数据库的性能变得很低,特别实在数据更新的时候。当在数据表上面进行数据的更新,删除,和插入的时候,都会导致索引页发生重新的调整,导致索引页中的数据重新的排序,从而导致数据表被锁定。
所以,我们很有必要找出没有发挥作用的索引,我们还是可以采用DMV来快速的查看:
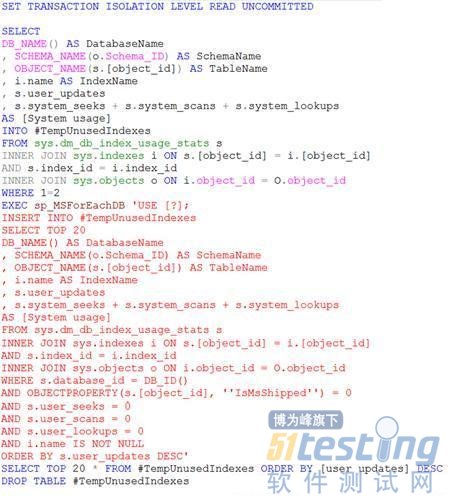
这里不否认,要完全明白上面的查询的意思却不是一件容易的事情,大家可以暂时不用懂,可以把这些脚本保存起来,作为一个小的工具使用。
查询结果如下:

因为我这里采用的是一个示例数据库,所以看到的结果不是很多,但是可以发现:这些索引一些在被不断的更新(user_updates),但是没有被用过(system usage)。
对无用索引的解决很简单:删除索引就OK了。
关于脚本,请大家在附件中下载,可以保留起来,并且大家还可以修改,查询指定的数据库的情况。
我们通过减少查询中的不必要的读取操作从而使得查询的性能得到提升。一个查询在数据库中执行的读操作越多,那么就对磁盘,CPU,内存的压力越大。除非整个数据库的数据全在在内存中,否则每次的读操作都会把数据从磁盘读入到内存中,然后返回。
一个查询在读取一个资源的时候,通过加锁会阻止其他的查询对这个资源进行修改,此时其他要操作这个资源的查询就需要等待,从而导致了延时。
诚然,有些等待是必须的,读取操作也是必须的,但是一些因为我们代码或者设计导致的过度的读取操作和等待,那就会严重影响性能,尤其是当数据库的访问量开始变大的时候。
可以说在SQL Server中,最高效的读取数据方式就是通过索引去获取数据。如果在数据表中存在缺失索引的问题,结果可想而知。
在本篇中,我们将会讨论下面几个议题:
● 如何识别缺失索引性能问题
● 识别没有用的索引
● 如何解决上面的问题
确实本篇讲述的内容涉及到了一些与数据库性能调优的话题,对于调优而言,难点很多时候在于如何正确的找出性能问题。
下面,我们首先来看看缺失索引。
缺失索引
SQL Server可以在表字段上面建立索引,从而使得Where和Join这样的语句执行的更快。当查询优化器在优化一个查询的时候,它会保存一些来暗示哪些列上可能建立索引之后可能性能会更快的信息。我们可以通过动态管理视图sys.dm_db_missing_index_details来查看,运行如下查询
查询的结果如下:
下面,我们就来稍微的解释一下结果中主要字段的含义:
| 字段名字 | 说明 |
| DatabaseName | 告诉我们是哪一个数据库上面存在缺失索引的问题 |
| equality_columns | 如果在某个字段上面进行了相等的操作,例如Name=’Agilesharp’,在Name字段上面进行了判等的操作,如果查询优化器认为这个Name上面缺失索引,那么这个Name就会出现在上述查询的结果中。 多个字段,用逗号分割 |
| inquality_columns | 在某个字段上进行了不等的操作,例如ID>1等,如果ID上面存在缺失索引,那么ID就会出现在这里 |
| Included_columns | 告诉我们那些数据列可以作为索引包含列放在索引中,从而减少书签查找的开销 |
| Statement | 告诉哪一个表上面存在缺失索引的问题 |
说了这么多,可能大家感觉像是没有说,感觉有点虚。确实,我也感觉这样,因为就这分析缺失索引的问题要考虑的问题就N多。agilesharp的其他系列文章也在讨论SQL Server的性能问题,这里,我们就不多说,也不把问题搞复杂了。我再送朋友一段分析的代码,可以更好的帮助我们找到缺失索引的问题:
上面的查询比较不错,按照成本进行了分析,成本越大,就说明加了索引之后,收益就越大,可以看到如下的结果:
然后大家加了索引之后,可以多多的测试,可以查看执行计划,也可以查看查询的数据页的读取情况,I/O的情况:
没有用的索引
正如在上一小节所的讲的,创建一个索引是一个非常需要重视的问题,需要考虑很多的方面,因为,如果我们建立的索引没有发挥作用,甚至说,查询优化器不采用我们的索引,那么就会带来适得其反的效果。
索引的维护是需要成本,甚至使得数据库的性能变得很低,特别实在数据更新的时候。当在数据表上面进行数据的更新,删除,和插入的时候,都会导致索引页发生重新的调整,导致索引页中的数据重新的排序,从而导致数据表被锁定。
所以,我们很有必要找出没有发挥作用的索引,我们还是可以采用DMV来快速的查看:
这里不否认,要完全明白上面的查询的意思却不是一件容易的事情,大家可以暂时不用懂,可以把这些脚本保存起来,作为一个小的工具使用。
查询结果如下:
因为我这里采用的是一个示例数据库,所以看到的结果不是很多,但是可以发现:这些索引一些在被不断的更新(user_updates),但是没有被用过(system usage)。
对无用索引的解决很简单:删除索引就OK了。
关于脚本,请大家在附件中下载,可以保留起来,并且大家还可以修改,查询指定的数据库的情况。

相关文章推荐
- 快速找出数据库的性能问题之:缺失索引 &无用的索引
- 快速找出数据库的性能问题之:缺失索引 &无用的索引
- (转摘)_《数据库设计入门经典》:构建快速执行的数据库模型_8.4 提高性能的高效索引
- 已解决:大量的全表扫描 "直接路径读" 引发的数据库性能问题
- 索引是从数据库中获取数据的最高效方式之一。95%的数据库性能问题都可以采用索引技术得到解决。
- 缺失索引 &无用的索引
- 数据库资源消耗高时两条简单管用、快速找出可能问题原因的SQL语句
- Oracle中找出无用的索引提高DML性能
- jsp数据库连接中"无效的描述符索引"问题的解决
- 03 找出性能问题
- 解决Visual studio"创建或打开C++浏览数据库文件***发生错误”的问题
- Sql Server 2008 出现"provider:命名管道提供程序,error:40"问题,无法登录数据库
- 数据库查询性能优化之利器—索引(二)
- aix下 maxperm设置引起数据库性能问题
- mysql快速分页-索引性能分析-索引-order by-limit-offset-covering-index
- 解决关系数据库的性能问题的几个思路
- 数据库学习一---------数据库查询索引和记录数,监控数据库性能
- 【学习摘记】马士兵bbs改良版_课时7&课时9_MySQL编码问题——数据库与客户端编码关系
- 数据库字段值相似性高导致的索引问题
- 数据库性能之索引