SGI STL 学习笔记三 heap
2012-12-20 16:31
260 查看
http://www.cnblogs.com/studentdeng/archive/2011/01/08/1930950.html
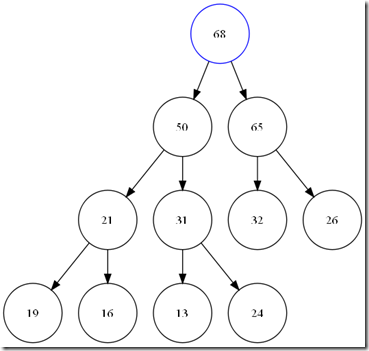
在插入之前,首先确定的是,我们已经构成了一个完整的堆,为了保证完全二叉树的要求,我们只能在数组最后一个元素位置后增加元素。这个新家伙,显然有可能破坏了我们整个堆的结构。那么我们需要给这个新来的找到他的位置。
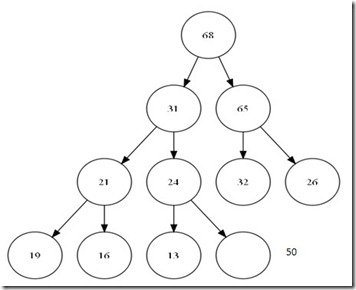
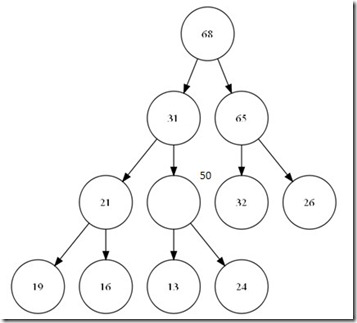
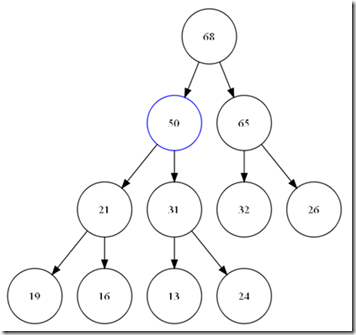
总结这个过程。其实就是在整个树中增加一个叶子节点,然后,一直到比较到跟或是比父节点小为止。可以看出,整个这次比较最大次数为树的深度,O(logN)。
View
Code
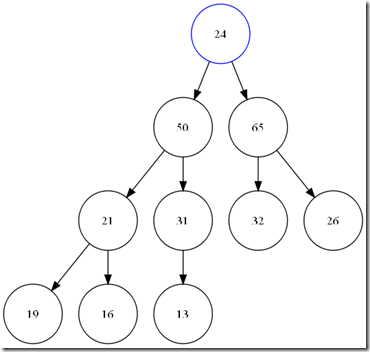
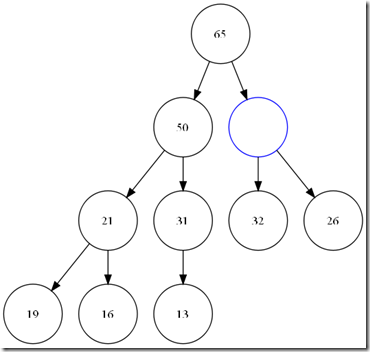
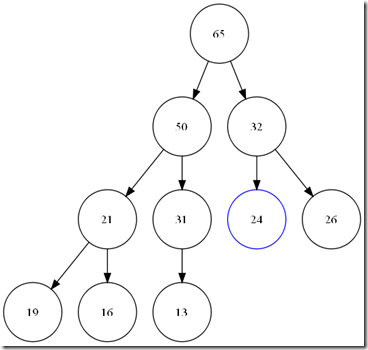
Pop_heap用来将最大值从堆中取走,当将顶部元素移动走之后,在根部就产生了一个hole。我们需要找到合适的数据将这个hole添上,而且我们还要尽可能的保存堆的性质(大小关系,和完全二叉树),所以,我们将顶部元素和最后一个元素交换。并将堆的大小减一。那么我们的新的根元素,显然违反了堆中大小关系的约定。所以,我们需要重新调整堆。而且,我们更爽的是,这个错误的堆的左右二个子树分别满足堆的性质,那么我需要找到hole节点的2个子节点中最大的和我们的hole 比较,并沿着大的子节点方向,直到叶子或是我们的这个hole满足大小关系。
View
Code
比如如下例子。

当push_heap的时候,如果直接*(__first + __holeIndex) = VALUE,那么就会成为这个样子。
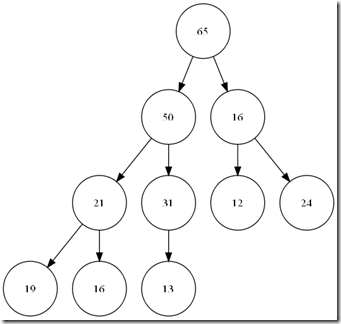
所以,必须要再一次经过__push_heap,再一次修正 24->16->65这条路径。保证真正的顺序。
而SGI这样实现是为了减少一些不必要的比较。
在搞定这些基本操作之后,我们发现,我们只需要执行一次次的pop_heap,我们就可以把数据按照一定的顺序跑列出来。而这也就是堆排序。
template <class _RandomAccessIterator>
void sort_heap(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
while (__last - __first > 1)
pop_heap(__first, __last--);
}
我们发现,每一次pop_heap操作是O(logN)。整个数列排序结果是O(n*logN)。这已经达到比较方法的极限。而且是原地排序,而且最坏情况依然不变。heap sort的确是一个非常出色的算法。
哦,扯了这么多,我们heap的好处不少,可是如何构造heap呢?
还记得__adjust_heap, 这个函数,可以在左右子树满足条件情况下调整树,那么我们完全可以从下到上逐渐构造成一个符合我们要求的树。而且,树的叶子节点是没有孩子的。所以,我们可以更快的只是从中间开始。 初略的估算下,每一次__adjust_heap,O(logN),一半的节点,O(n*logN),但其实我们可以做的更快。 建堆的复杂度可以达到O(n)的线性。
heap,大家都非常了解。大学学的时候必须会的内容,要不考试很难过关。只是当时并没有学习明白。只是被老师和考试强了。完全是机械的记忆。觉得真是太对不起自己这个专业了。最近再看STL,也就有了这一篇老生重弹。
在很多情况下,我们非常关心一个集合中的最大元素。并希望能够从集合中最快速度找到并删除。为了整体的效率,我们需要在这个集合中插入元素,查找最大元素,删除最大元素能够综合最快。使用binary heap便是一种不错的选择之一。而且能够在O(logN)插入,删除元素,查找最大元素在常数时间下。
Binary heap 是一种complete binary tree(完全二叉树)。所以我们可以放心的使用简单的数组来保存数据而不需要担心浪费空间。维持树的父子关系也简单快速,而且整个过程都在原地进行。
Heap 可以按照排列顺序分为大顶堆,小顶堆。 这里讨论的堆默认为大顶堆。每个节点的值大于等于其子节点的值。
一个典型的大顶堆。
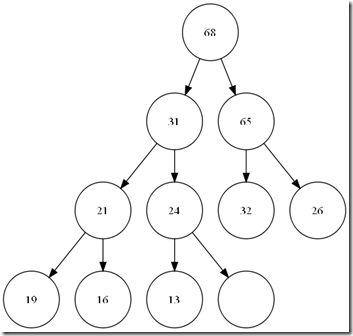
了解heap,让我们从最简单的插入开始。
push_heap
在插入之前,首先确定的是,我们已经构成了一个完整的堆,为了保证完全二叉树的要求,我们只能在数组最后一个元素位置后增加元素。这个新家伙,显然有可能破坏了我们整个堆的结构。那么我们需要给这个新来的找到他的位置。
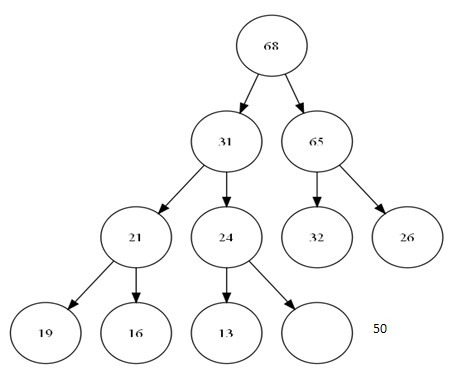

总结这个过程。其实就是在整个树中增加一个叶子节点,然后,一直到比较到跟或是比父节点小为止。可以看出,整个这次比较最大次数为树的深度,O(logN)。
View
Code
Pop_heap
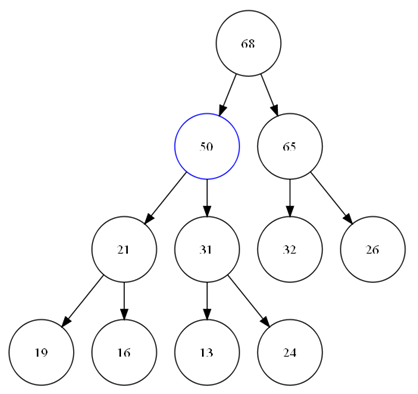
Pop_heap用来将最大值从堆中取走,当将顶部元素移动走之后,在根部就产生了一个hole。我们需要找到合适的数据将这个hole添上,而且我们还要尽可能的保存堆的性质(大小关系,和完全二叉树),所以,我们将顶部元素和最后一个元素交换。并将堆的大小减一。那么我们的新的根元素,显然违反了堆中大小关系的约定。所以,我们需要重新调整堆。而且,我们更爽的是,这个错误的堆的左右二个子树分别满足堆的性质,那么我需要找到hole节点的2个子节点中最大的和我们的hole 比较,并沿着大的子节点方向,直到叶子或是我们的这个hole满足大小关系。

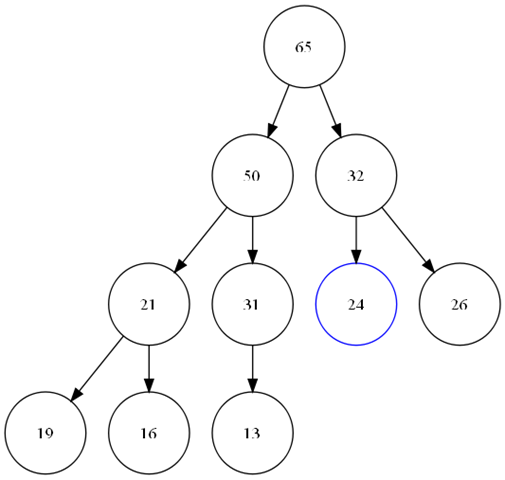
View
Code
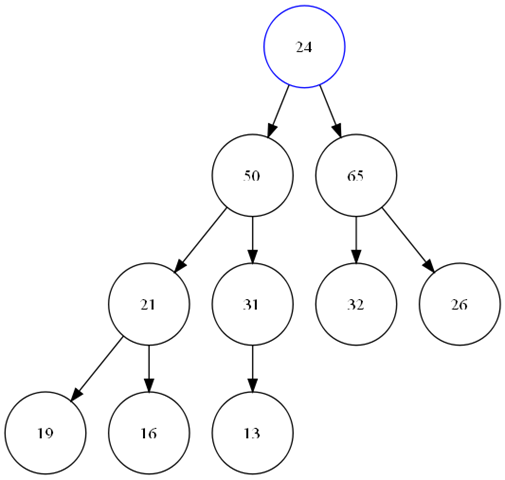
比如如下例子。

当push_heap的时候,如果直接*(__first + __holeIndex) = VALUE,那么就会成为这个样子。

所以,必须要再一次经过__push_heap,再一次修正 24->16->65这条路径。保证真正的顺序。
而SGI这样实现是为了减少一些不必要的比较。
Sort_heap
在搞定这些基本操作之后,我们发现,我们只需要执行一次次的pop_heap,我们就可以把数据按照一定的顺序跑列出来。而这也就是堆排序。template <class _RandomAccessIterator>
void sort_heap(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
while (__last - __first > 1)
pop_heap(__first, __last--);
}
我们发现,每一次pop_heap操作是O(logN)。整个数列排序结果是O(n*logN)。这已经达到比较方法的极限。而且是原地排序,而且最坏情况依然不变。heap sort的确是一个非常出色的算法。
哦,扯了这么多,我们heap的好处不少,可是如何构造heap呢?
Make_heap
还记得__adjust_heap, 这个函数,可以在左右子树满足条件情况下调整树,那么我们完全可以从下到上逐渐构造成一个符合我们要求的树。而且,树的叶子节点是没有孩子的。所以,我们可以更快的只是从中间开始。 初略的估算下,每一次__adjust_heap,O(logN),一半的节点,O(n*logN),但其实我们可以做的更快。 建堆的复杂度可以达到O(n)的线性。
相关文章推荐
- SGI STL 学习笔记三 heap
- SGI STL学习笔记(1):空间配置器(allocator)
- SGI-STL学习笔记之RB-tree part1
- C++ Standard Stl -- SGI STL源码学习笔记(01) auto_ptr
- SGI-STL学习笔记之list::sort()
- C++ Standard Stl -- SGI STL源码学习笔记(02) Concepts Check
- SGI-STL学习笔记之RB-tree part2
- C++ Standard Stl -- SGI STL源码学习笔记(04) stl_deque && 初涉STL内存管理
- C++ Standard Stl -- SGI STL源码学习笔记(05) stl_vector 与 一些问题的细化 1
- SGI-STL学习笔记之allocator
- SGI STL 学习笔记二 vector
- 学习笔记 -- 关于 STL 中的 heap ( 堆 )
- C++ sgi STL学习笔记之non-mutating algorithm
- C++ Standard Stl -- SGI STL源码学习笔记(03) STL中的模板编译期检查与偏特化编译期检查
- STL源码剖析学习笔记之具备次配置力(sub-allocation)的SGI空间配置器
- SGI-STL学习笔记之IntroSort
- SGI-STL学习笔记之allocator .
- SGI-STL学习笔记之heap算法
- SGI STL 学习笔记一 Iterator
- C++ Standard Stl -- SGI STL源码学习笔记(07) stl_vector 与 一些问题的细化 3 resize函数剖析