Heterogeneous Parallel Programming—Week one part one
2012-11-29 17:32
507 查看
Heterogeneous Parallel Programming
Wen-mei Hwu (instructor), Gang Liao (editor) www.greenhat1016@gmail.com
high performance and energy-efficiency
functionality and maintainability
scalability across future generations
Technical subjects
principles and patterns of parallel algorithms
processor architecture features and constraints
programming API, tools and techniques
Instructor: Wen-mei Hwu w-hwu@illinois.edu, use [Coursera] to start your e-mail subject line
Teaching Assistants: John Stratton, I-Jui (Ray) Sung, Xiao-Long Wu, Hee-Seok Kim, Liwen Chang, Nasser Anssari, Izzat El Hajj, Abdul Dakkak, Steven Wu, Tom Jablin
Contributors: David Kirk, John Stratton, Issac Gelado, John Stone, Javier Cabezas, Michael Garland
Handouts and lecture slides/recordings
Sample textbook chapters, documentation, software resources
Web board discussions
Channel for electronic announcements
Forum for Q&A - the TAs and Professors read the board, and your classmates often have answers
Labs (Machine Problems): 50%
Any copying of code is unacceptable
Includes reading someone else's code and then going off to write your own.
Giving/receiving help on a quiz is unacceptable
We will be using an pre-public-release of the 2nd Edition, made available to Coursera students at a special discount: http://store.elsevier.com/specialOffer.jsp?offerId=EST_PROG
Lab assignments will have accompanying notes
NVIDIA, NVidia CUDA C Programming Guide, version 4.0, NVidia, 2011 (reference book)

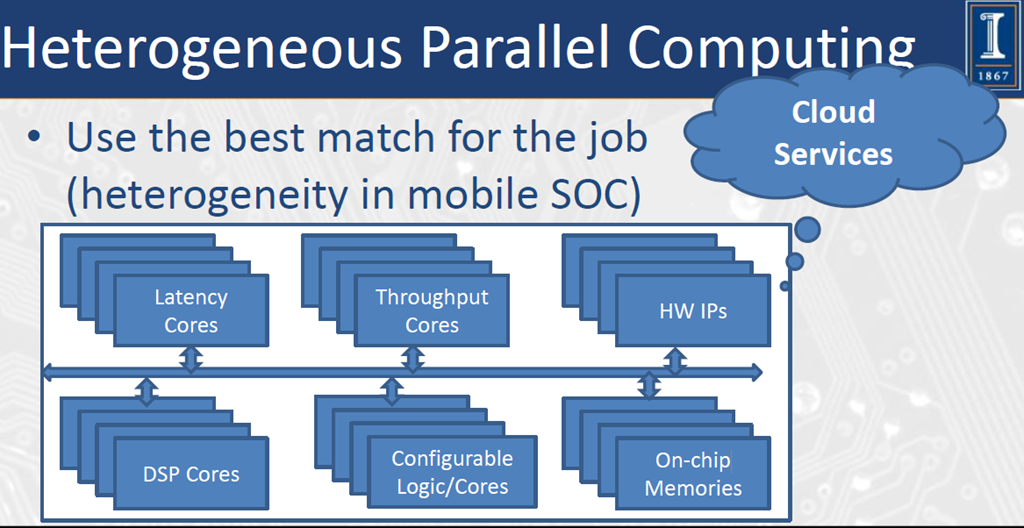
Use the best match for the job (heterogeneity in mobile SOC)

CPU and GPU have very different design philosophy

Sophisticated control
Branch prediction for reduced branch latency
Data forwarding for reduced data latency
Powerful ALU
Reduced operation latency

To boost memory throughput
Simple control
No branch prediction
No data forwarding
Energy efficient ALUs
Many, long latency but heavily pipelined for high throughput
Require massive number of threads to tolerate latencies

CPUs can be 10+X faster than GPUs for sequential code
GPUs for parallel parts where throughput wins
GPUs can be 10+X faster than CPUs for parallel code

Financial Analysis
Scientific Simulation
Engineering Simulation
Data Intensive Analytics
Medical Imaging
Digital Audio Processing
Computer Vision
Digital Video Processing
Biomedical Informatics
Electronic Design Automation
Statistical Modeling
Ray Tracing Rendering
Interactive Physics
Numerical Methods
HW gates per chip increases at 2x/18 months
Future system must minimize software redevelopment

The same application runs efficiently on new generations of cores

The same application runs efficiently on more of the same cores

Portability
The same application runs efficiently on different types of cores

The same application runs efficiently on systems with different organizations and interfaces

Performance growth with HW generations
Increasing number of compute units
Increasing number of threads
Increasing vector length
Increasing pipeline depth
Increasing DRAM burst size
Increasing number of DRAM channels
Increasing data movement latency
Portability across many different HW types
Multi-core CPUs vs. many-core GPUs
VLIW vs. SIMD vs. threading
Shared memory vs. distributed memory
The programming style we use in this course supports both scalability and portability through advanced tools.
Wen-mei Hwu (instructor), Gang Liao (editor) www.greenhat1016@gmail.com
Lecture 0: Course Overview
Course OverviewPeople
Learn how to program heterogeneous parallel computing systems and achievehigh performance and energy-efficiency
functionality and maintainability
scalability across future generations
Technical subjects
principles and patterns of parallel algorithms
processor architecture features and constraints
programming API, tools and techniques
Instructor: Wen-mei Hwu w-hwu@illinois.edu, use [Coursera] to start your e-mail subject line
Teaching Assistants: John Stratton, I-Jui (Ray) Sung, Xiao-Long Wu, Hee-Seok Kim, Liwen Chang, Nasser Anssari, Izzat El Hajj, Abdul Dakkak, Steven Wu, Tom Jablin
Contributors: David Kirk, John Stratton, Issac Gelado, John Stone, Javier Cabezas, Michael Garland
Web Resources
Website: https://www.coursera.org/course/heteroHandouts and lecture slides/recordings
Sample textbook chapters, documentation, software resources
Web board discussions
Channel for electronic announcements
Forum for Q&A - the TAs and Professors read the board, and your classmates often have answers
Grading
Quizzes: 50%Labs (Machine Problems): 50%
Academic Honesty
You are allowed and encouraged to discuss assignments with other students in the class. Getting verbal advice/help from people who've already taken the course is also fine.Any copying of code is unacceptable
Includes reading someone else's code and then going off to write your own.
Giving/receiving help on a quiz is unacceptable
Recommended Textbook/Notes
D. Kirk and W. Hwu, "Programming Massively Parallel Processors -- A Hands-on Approach," Morgan Kaufman Publisher, 2010, ISBN 978-0123814722We will be using an pre-public-release of the 2nd Edition, made available to Coursera students at a special discount: http://store.elsevier.com/specialOffer.jsp?offerId=EST_PROG
Lab assignments will have accompanying notes
NVIDIA, NVidia CUDA C Programming Guide, version 4.0, NVidia, 2011 (reference book)
ECE498AL -- ECE408/CS483 - Coursera
Tentative Schedule
| Week 1 | Week 4 |
| Lecture 0: Course Overview | Lecture 7: Tiled Convolution |
| Lecture 1: Intro to Hetero Computing | Lecture 8: Reduction Trees |
| Lecture 2: Intro to CUDA C | Lab-3: Tiled matrix multiplication |
| Lab-1: installation, vector addition | |
| Week 2 | Week 5 |
| Lecture 3: Data Parallelism Model | Lecture 9: Streams and Contexts |
| Lecture 4: CUDA Memory Model | Lecture 10: Hetero Clusters |
| Lab-2: simple matrix multiplication | Lab 4: Tiled convolution |
| Week 3 | Week 6 |
| Lecture 5: Tiling and Locality | Lecture 11: OpenCL, OpenACC |
| Lecture 6: Convolution | Lecture 12: Thrust, C++AMP |
| Lab-3: Tiled matrix multiplication | Lecture 13: Summary |
| Lab 4: Tiled convolution |
Lecture 1.1: Introduction to Heterogeneous Parallel Computing
Heterogeneous Parallel ComputingUse the best match for the job (heterogeneity in mobile SOC)
UIUC Blue Waters Supercomputer
| Cray System & Storage cabinets | >300 |
| Compute nodes | >25,000 |
| Usable Storage Bandwidth | >1 TB/s |
| System Memory | >1.5 Petabytes |
| Memory per core module | 4 GB |
| Gemin Interconnect Topology | 3D Torus |
| Usable Storage | >25 Petabytes |
| Peak performance | >11.5 Petaflops |
| Number of AMD Interlogos processors | >49,000 |
| Number of AMD x86 core modules | >380,000 |
| Number of NVIDIA Kepler GPUs: | >3,000 |
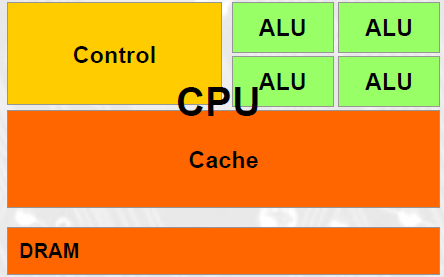
CPU and GPU have very different design philosophy

CPUs: Latency Oriented Design
Large caches: Convert long latency memory accesses to short latency cache accessesSophisticated control
Branch prediction for reduced branch latency
Data forwarding for reduced data latency
Powerful ALU
Reduced operation latency
GPUs: Throughput Oriented Design
Small cachesTo boost memory throughput
Simple control
No branch prediction
No data forwarding
Energy efficient ALUs
Many, long latency but heavily pipelined for high throughput
Require massive number of threads to tolerate latencies

Winning Applications Use Both CPU and GPU
CPUs for sequential parts where latency mattersCPUs can be 10+X faster than GPUs for sequential code
GPUs for parallel parts where throughput wins
GPUs can be 10+X faster than CPUs for parallel code
Heterogeneous parallel computing is catching on
280 submissions to GPU Computing Gems and 90 articles included in two volumes.
Financial Analysis
Scientific Simulation
Engineering Simulation
Data Intensive Analytics
Medical Imaging
Digital Audio Processing
Computer Vision
Digital Video Processing
Biomedical Informatics
Electronic Design Automation
Statistical Modeling
Ray Tracing Rendering
Interactive Physics
Numerical Methods
Lecture 1.2: Software Cost in Heterogeneous Parallel Computing
Software Dominates System Cost
SW lines per chip increases at 2x/10 monthsHW gates per chip increases at 2x/18 months
Future system must minimize software redevelopment

| the Fig. published by IBM in 2010 |
Keys to Software Cost Control
ScalabilityThe same application runs efficiently on new generations of cores

The same application runs efficiently on more of the same cores

Portability
The same application runs efficiently on different types of cores

The same application runs efficiently on systems with different organizations and interfaces
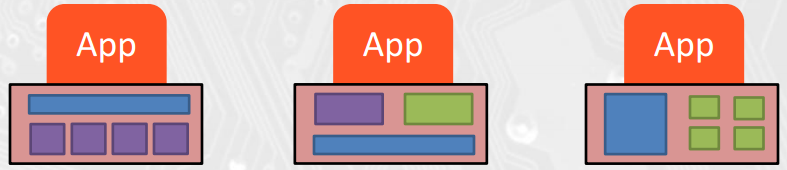
Scalability and Portability
Performance growth with HW generationsIncreasing number of compute units
Increasing number of threads
Increasing vector length
Increasing pipeline depth
Increasing DRAM burst size
Increasing number of DRAM channels
Increasing data movement latency
Portability across many different HW types
Multi-core CPUs vs. many-core GPUs
VLIW vs. SIMD vs. threading
Shared memory vs. distributed memory
The programming style we use in this course supports both scalability and portability through advanced tools.

相关文章推荐
- 【2014-11-24】Heterogeneous Parallel Programming – Section 2
- [大规模并行处理器编程实战]读书笔记_Heterogeneous Parallel Programming_CHAPTER_02
- An Introduction to Interactive Programming in Python (Part 1) -- Week 2_2 练习
- PatentTips - Heterogeneous Parallel Primitives Programming Model
- Heterogeneous Parallel Programming(异构并行编程)学习笔记(一)
- Heterogeneous Parallel Programming(异构并行编程)学习笔记(六)
- Heterogeneous Parallel Programming(异构并行编程)学习笔记(五)
- 4.3 Reduction代码(Heterogeneous Parallel Programming class lab)
- An Introduction to Interactive Programming in Python (Part 1) -- Week 2_3 练习
- Heterogeneous Parallel Programming(异构并行编程)学习笔记(七)
- 【读书笔记】.NET本质论第四章-Programming with Type(Part One)
- Parallel Port Programming (Part 1): with C
- Parallel Port Programming (Part 2): with Visual C++
- [大规模并行处理器编程实战]读书笔记_Heterogeneous Parallel Programming_CHAPTER_01
- [大规模并行处理器编程实战]读书笔记_Heterogeneous Parallel Programming_CHAPTER_03
- An Introduction to Interactive Programming in Python (Part 1) - Week 0
- 【2014-11-23】Heterogeneous Parallel Programming – Section 1
- An Introduction to Interactive Programming in Python (Part 1) - Week 1
- Machine Learning week 4 programming exercise One vs All and Neural network
- Some thought about "The Parallel ADT and Algorithms"(part one)