关于MYSQL的Replication的初步学习
2012-11-29 00:16
316 查看
简单说Replication实际上就是一种数据库间的同步机制,它通过主库上生成的二进制日志在从库上重放来实现主从库上的同步。
Replication is relatively good for scaling reads, which you can direct to a slave, but it’s not a good way to scale writes unless you design it right.
相对来说,Replication机制特别适合对读取进行水平伸缩(scale out),这也是很多系统通过Replication实现读写分离的目的。对于很多系统来说,读写比例是不对等的,很多时候是读操作要远远多于写操作,针对这种情况,通过Replication,将数据写入主库,而在读取数据时,散列到某个从库上,分散读取压力。也就是说,它为读操作实现负载均衡提供了条件。
从这一点来看,目前论坛系统的主从库设计并不能提升系统的整体性能。因为我们的写操作也是非常频繁的。这样,从库在不停地同步主库新抓取的数据时,还要被统计分析进程频繁读取,从而造成从库性能低下。
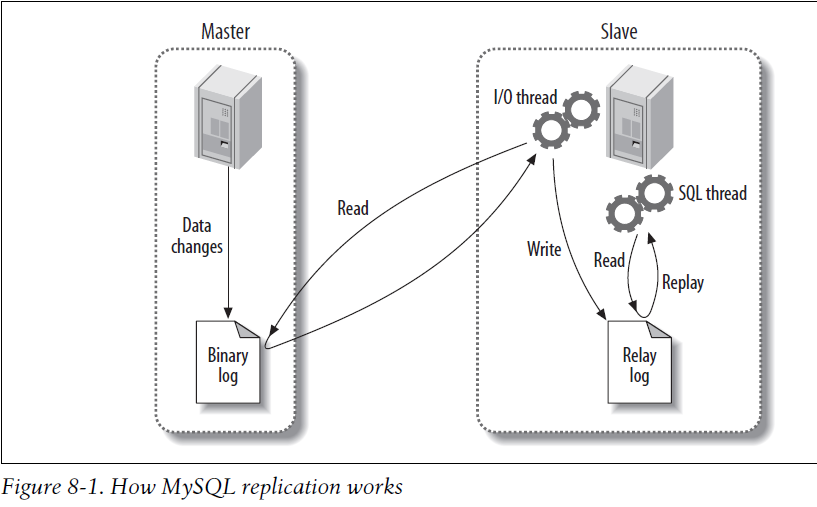
下图是Replication的工作机制:

相关文章推荐
- 关于MYSQL的Replication的初步学习
- MySQL学习笔记之九:MySQL Replication
- MySQL学习笔记(一)――关于MySQL 5
- MySQL学习笔记(五)扩展性设计之Replication
- MySQL初步学习2:常用命令与语法基础
- 关于spring AOP 的初步学习
- MySQL学习---->第二练:语句初步(SQL概述、数据定义、查询)
- 关于《MySQL 必知必会》的学习2
- javaweb学习笔记之关于分层结构的初步理解
- mysql--SQL编程(关于mysql中的日期) 学习笔记2
- 关于Linux下的mysql安装及配置学习笔记
- 关于学习Mat类中rowRange和colRange的初步认识
- Mysql DBA 高级运维学习笔记-初步增量恢复mysql数据库
- MySQL学习之——关于or的索引问题
- 初步学习 mysql
- Mysql学习笔记(九):关于典型的8小时问题
- 关于《MySQL 必知必会》的学习3
- mysql--SQL编程(关于mysql中的日期,实例,判断生日是否为闰年) 学习笔记2.1
- 关于mysql的sql语句的汇总(学习笔记)02 (三个字段查询)
- 网站学习初步1 关于控件