SQL处理层次型数据的策略对比:Adjacency list vs. nested sets: MySQL【转载】
2012-11-24 10:37
691 查看
原文地址:http://explainextended.com/2009/09/29/adjacency-list-vs-nested-sets-mysql/
For detailed explanations of the terms, see the first article in the series:
Adjacency list vs. nested sets: PostgreSQL
This is the last article of the series which covers MySQL.
MySQL differs from the other systems, since it is the only system of the big four that does not support recursion natively. It has neither recursive CTE‘s nor
MySQL supports a thing that all other systems either lack or implement inefficiently: session variables. They can be set in a
This of course is against the whole spirit of SQL, since SQL implies operations on whole sets and session variables operate on rows and are totally dependent on the order they are returned or processed. But if used properly, this behavior can be exploited to emulate some things that MySQL lacks: analytic functions, efficient random row sampling etc.
Hierarchical functions are among the things that need to be emulated in MySQL using session variables to keep the function state.
Here’s the old article in my blog that shows how to do this:
Hierarchical queries in MySQL
On the other hand, MySQL implements one more thing that is useful for nested sets model:
A spatial index is an R-Tree structure that allows indexing multidimensional values (though MySQL only indexes two-dimensional ones). Each value is represented by its minimal bounding box (minimal rectangle that contains the whole shape), and this is what is stored in the index.
The index allows to find an answer efficiently to the following question: given a point, what are the boxes that contain it?
Though this type of query is commonly used on geometrical or geographical data, like find all public toilets within 100 meters of my current location and for God’s sake don’t make it a fullscan. However, this index can be used on any type of query that requires searching a given point in a range defined by two columns just as well.
A plain B-Tree index is good for range queries: find all values within the range defined by two boundaries, like shown on this picture:
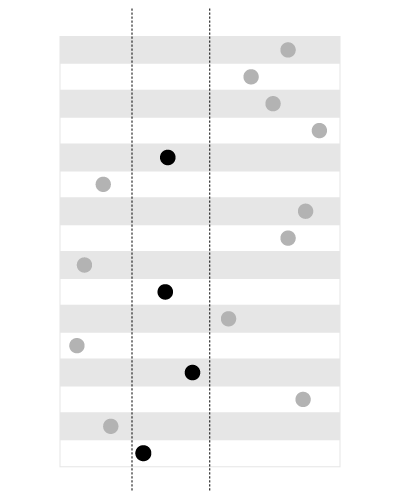
Black dots show values that fall inside the range (defined with two
constant boundaries). It’s easy to find these values if they are sorted:
all values will make a contiguous block. That’s what exactly the B-Tree index do: sort the values and return contiguous blocks.
But if we need to find variable ranges containing a constant point, like on this picture:
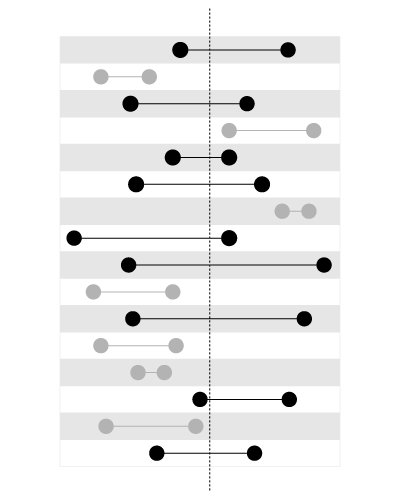
, a B-Tree index won’t help, since we have two values here which we just cannot sort using one sort order. An R-Tree index, on the contrary, is perfect for this type of query.
Tasks requiring seaching for a value inside a known range are very
common, that’s why almost all database management systems provide a way
to build and use a B-Tree index.
There is also a certain class of tasks that require searching for all ranges containing a known value:
Searching for an IP address in the IP range ban list
Searching for a given date within a date range
and several others. These tasks can be improved by using R-Tree capabilities of MySQL:
The nested sets model belongs to both classes of tasks. It
requires the first query (find variable values within a constant range)
to build the list of descendants, and the second query (find variable
ranges that contain a constant value) to build the list of ancestors.
That’s exactly why it’s so fast on building the list of descendants and so slow on building the list of ancestors.
Using an R-Tree index, nested sets model can be improved.
MySQL can only create an R-Tree index on a
We should represent out nested sets boundaries
This is not much of a stretch, actually, from the logical point of
view: the nested sets are usually graphically represented as big boxes
(parents) containing smaller boxes (children), and that’s exactly what
these predicates are designed for: searching for a boxes containing
other boxes.
Let’s create a sample table:
Table creation script
The table contains 8 levels of hierarchy, 5 children to each parent and 2,441,405 records. Hierarchical attributes are defined for both adjacency list model (
The field
box of each record. All children’s boxes are contained within the parent
box. This field is indexed with an R-Tree (
To query the adjacency list, we also need to create a pair of special functions as described in the article about hierarchical queries in MySQL:
The hierarchical functions
These functions are described in more detail in this and this article.
Now, let’s run the queries.
We don’t use any spatial columns or indexes here.
Since this query requiries searching for all records with values of
View query details
The query completes in 300 ms.
Since MySQL does not support recursive queries
natively, we use the function to iterate the trees and a set of session
variables to maintain the state of the function between calls.
To provide the results as a resultset, we call the function it
View query details
This query runs for 7 seconds.
This query uses the R-Tree index. To do that, we convert
View query details
The query completes in 15 ms. This result is by far
faster than everything we saw before. The same queries issued by the
other systems are not assisted or poorly assisted by B-Tree indexes, and usually this query is a matter of seconds.
Not that we don’t even use a function for this query.
Each record has only one
To iterate the linked list, we can use an approach describe in this article:
Sorting lists
, which requires no function, just a correlated subquery.
View query details
This query completes in 600 ms, which is much longer than the nested sets solution.
This query is adjusted for better usage of the R-Tree indexes.
We find all descendents of the item in question and then calculate
the total number of parents (which gives us the depth level of each of
the children). Then we just compare it with the level of the item.
This solution depends on the number of item’s children too, however, let’s see the performance:
View query for item 42
View query for item 42
The query for item 42 (which has about 20,000 descendants) took minutes in the other systems. Now it completes in less than 5 seconds.
The same query for item 31,415 is over in just 10 ms.
This query imitates recursion, so performance does not directly depend on the number of descendants.
View query for item 42
View query for item 31,415
Both queries complete in 600 ms
On one hand, it lacks a native way to do recursive queries which
makes traversing the hierarchy trees harder. It can be emulated using a
custom function and session variables to maintain the recursion stack,
but this solution is more slow.
On the other hand, MySQL supports R-Tree indexes which can be used to query the ranges containing a given value. This type of search is required for the nested sets queries and R-Tree index is faster.
However, adjacency list is still faster for retrieving all descendants up to the given level.
Both adjacency lists and nested sets require extra maintenance in MySQL: adjacency lists require building a custom function to query each table, nested sets require a function to update it.
Updating a nested sets model can be slow too since R-Tree indexes take much longer time to add to them than B-Tree indexes.
However, using R-Tree indexes, nested sets model is
extra fast for searching for all descendants and all ancestors, and
shows decent performance in determining the item’s levels and filtering
on them.
In MySQL, it is advisable to add the
It should also be noted that the only storage engine that allows R-Tree indexes is MyISAM.
In case of an update (which can affect millions of rows even to insert a
single record), all table will be locked and will not be able to be
queried.
should be preferred if the updates to the hierarhical structure are
infrequent and it is affordable to lock the table for the duration of an
update (which can take minutes on a long table).
This implies creating the table using MyISAM storage engine, creating the bounding box of a
If the updates to the table are frequent or it is inaffordable to
lock the table for a long period of time implied by an update, then the adjacency list model should be used to store the hierarchical data.
This requires creating a function to query the table.
MySQL is the only system of the big four (MySQL, Oracle, SQL Server, PostgreSQL) for which the nested sets model shows decent performance and can be considered to stored hierarchical data.
For detailed explanations of the terms, see the first article in the series:
Adjacency list vs. nested sets: PostgreSQL
This is the last article of the series which covers MySQL.
MySQL differs from the other systems, since it is the only system of the big four that does not support recursion natively. It has neither recursive CTE‘s nor
CONNECT BYclause, not even rowset returning functions that help to emulate recursion in PostgreSQL 8.3.
MySQL supports a thing that all other systems either lack or implement inefficiently: session variables. They can be set in a
SELECTclause and can be used to keep some kind of a state between the rows as they are processed and returned in a rowset.
This of course is against the whole spirit of SQL, since SQL implies operations on whole sets and session variables operate on rows and are totally dependent on the order they are returned or processed. But if used properly, this behavior can be exploited to emulate some things that MySQL lacks: analytic functions, efficient random row sampling etc.
Hierarchical functions are among the things that need to be emulated in MySQL using session variables to keep the function state.
Here’s the old article in my blog that shows how to do this:
Hierarchical queries in MySQL
On the other hand, MySQL implements one more thing that is useful for nested sets model:
SPATIALindexes.
Spatial indexes and nested sets model
Unlike most other systems, MySQL allows creating indexes of different types, one of them beingSPATIAL.
A spatial index is an R-Tree structure that allows indexing multidimensional values (though MySQL only indexes two-dimensional ones). Each value is represented by its minimal bounding box (minimal rectangle that contains the whole shape), and this is what is stored in the index.
The index allows to find an answer efficiently to the following question: given a point, what are the boxes that contain it?
Though this type of query is commonly used on geometrical or geographical data, like find all public toilets within 100 meters of my current location and for God’s sake don’t make it a fullscan. However, this index can be used on any type of query that requires searching a given point in a range defined by two columns just as well.
A plain B-Tree index is good for range queries: find all values within the range defined by two boundaries, like shown on this picture:
Black dots show values that fall inside the range (defined with two
constant boundaries). It’s easy to find these values if they are sorted:
all values will make a contiguous block. That’s what exactly the B-Tree index do: sort the values and return contiguous blocks.
But if we need to find variable ranges containing a constant point, like on this picture:
, a B-Tree index won’t help, since we have two values here which we just cannot sort using one sort order. An R-Tree index, on the contrary, is perfect for this type of query.
Tasks requiring seaching for a value inside a known range are very
common, that’s why almost all database management systems provide a way
to build and use a B-Tree index.
There is also a certain class of tasks that require searching for all ranges containing a known value:
Searching for an IP address in the IP range ban list
Searching for a given date within a date range
and several others. These tasks can be improved by using R-Tree capabilities of MySQL:
The nested sets model belongs to both classes of tasks. It
requires the first query (find variable values within a constant range)
to build the list of descendants, and the second query (find variable
ranges that contain a constant value) to build the list of ancestors.
That’s exactly why it’s so fast on building the list of descendants and so slow on building the list of ancestors.
Using an R-Tree index, nested sets model can be improved.
MySQL can only create an R-Tree index on a
GEOMETRYtype in a MyISAM table and use it in two special predicates,
MBRContainsand
MBRWithin.
We should represent out nested sets boundaries
(lft, rgt)as a
LineString(Point(-1, lft), Point(1, rgt)), and search for a
Point(0, value)using any of the predicates above.
This is not much of a stretch, actually, from the logical point of
view: the nested sets are usually graphically represented as big boxes
(parents) containing smaller boxes (children), and that’s exactly what
these predicates are designed for: searching for a boxes containing
other boxes.
Let’s create a sample table:
Table creation script
The table contains 8 levels of hierarchy, 5 children to each parent and 2,441,405 records. Hierarchical attributes are defined for both adjacency list model (
parent) and nested sets model (
lft,
rgt). All these fields are indexed with plain B-Tree indexes.
The field
setsrepresents the diagonal of the bounding
box of each record. All children’s boxes are contained within the parent
box. This field is indexed with an R-Tree (
SPATIAL) index.
To query the adjacency list, we also need to create a pair of special functions as described in the article about hierarchical queries in MySQL:
The hierarchical functions
These functions are described in more detail in this and this article.
Now, let’s run the queries.
All descendants
Nested sets
view sourceprint?1.
SELECT
SUM
(LENGTH(hc.stuffing))
2.
FROM
t_hierarchy hp
3.
JOIN
t_hierarchy hc
4.
ON
hc.lft
BETWEEN
hp.lft
AND
hp.rgt
5.
WHERE
hp.id = 42
We don’t use any spatial columns or indexes here.
Since this query requiries searching for all records with values of
lftlying within the given range (that between
lftand
rgtof the parent record), a plain B-Tree index on a plain
INTcolumn is just fine.
View query details
The query completes in 300 ms.
Adjacency list
view sourceprint?01.
SELECT
SUM
(LENGTH(stuffing))
02.
FROM
(
03.
SELECT
42
AS
id
04.
UNION
ALL
05.
SELECT
hierarchy_connect_by_parent_eq_prior_id(id)
AS
id
06.
FROM
(
07.
SELECT
@start_with := 42,
08.
@id:= @start_with,
09.
@
level
:= 0
10.
) vars, t_hierarchy
11.
WHERE
@id
IS
NOT
NULL
12.
) ho
13.
JOIN
t_hierarchy hi
14.
ON
hi.id = ho.id
Since MySQL does not support recursive queries
natively, we use the function to iterate the trees and a set of session
variables to maintain the state of the function between calls.
To provide the results as a resultset, we call the function it
SELECTclause of a query over the table, disregarding the input parameters. The table in the
FROMclause is used as a dummy rowsource.
View query details
This query runs for 7 seconds.
All ancestors
Nested sets
view sourceprint?1.
SELECT
hp.id, hp.parent, hp.lft, hp.rgt, hp.data
2.
FROM
t_hierarchy hc
3.
JOIN
t_hierarchy hp
4.
ON
MBRWithin(Point(0, hc.lft), hp.sets)
5.
WHERE
hc.id = 1000000
6.
ORDER
BY
7.
lft
This query uses the R-Tree index. To do that, we convert
lftto a point with coordinates
(0, lft)and search for all boxes containing this point using
MBRWithin.
View query details
The query completes in 15 ms. This result is by far
faster than everything we saw before. The same queries issued by the
other systems are not assisted or poorly assisted by B-Tree indexes, and usually this query is a matter of seconds.
Adjacency list
view sourceprint?01.
SELECT
hp.id, hp.parent, hp.lft, hp.rgt, hp.data
02.
FROM
(
03.
SELECT
@r
AS
_id,
04.
@
level
:= @
level
+ 1
AS
level
,
05.
(
06.
SELECT
@r:=
NULLIF
(parent, 0)
07.
FROM
t_hierarchy hn
08.
WHERE
id = _id
09.
)
10.
FROM
(
11.
SELECT
@r:= 1000000,
12.
@
level
:= 0
13.
) vars,
14.
t_hierarchy hc
15.
WHERE
@r
IS
NOT
NULL
16.
) hc
17.
JOIN
t_hierarchy hp
18.
ON
hp.id = hc._id
19.
ORDER
BY
20.
level
DESC
Not that we don’t even use a function for this query.
Each record has only one
parent, and
idis a
PRIMARY KEY, thus the ancestry chain can be represented as a linked list.
To iterate the linked list, we can use an approach describe in this article:
Sorting lists
, which requires no function, just a correlated subquery.
View query details
This query completes in 600 ms, which is much longer than the nested sets solution.
All descendants up to a certain level
Nested sets
view sourceprint?01.
SELECT
hc.id, hc.parent, hc.lft, hc.rgt, hc.data
02.
FROM
t_hierarchy hp
03.
JOIN
t_hierarchy hc
04.
ON
hc.lft
BETWEEN
hp.lft
AND
hp.rgt
05.
JOIN
t_hierarchy hr
06.
ON
MBRWithin(Point(0, hc.lft), hr.sets)
07.
WHERE
hp.id = ?
08.
GROUP
BY
09.
hc.id
10.
HAVING
COUNT
(*) <=
11.
(
12.
SELECT
COUNT
(*)
13.
FROM
t_hierarchy hp
14.
JOIN
t_hierarchy hrp
15.
ON
MBRWithin(Point(0, hp.lft), hrp.sets)
16.
WHERE
hp.id = ?
17.
) + 2
18.
ORDER
BY
19.
hc.lft
This query is adjusted for better usage of the R-Tree indexes.
We find all descendents of the item in question and then calculate
the total number of parents (which gives us the depth level of each of
the children). Then we just compare it with the level of the item.
This solution depends on the number of item’s children too, however, let’s see the performance:
View query for item 42
View query for item 42
The query for item 42 (which has about 20,000 descendants) took minutes in the other systems. Now it completes in less than 5 seconds.
The same query for item 31,415 is over in just 10 ms.
Adjacency list
view sourceprint?01.
SELECT
hi.id, hi.parent, hi.lft, hi.rgt, hi.data
02.
FROM
(
03.
SELECT
?
AS
id
04.
UNION
ALL
05.
SELECT
hierarchy_connect_by_parent_eq_prior_id_with_level(id, 2)
AS
id
06.
FROM
(
07.
SELECT
@start_with := ?,
08.
@id:= @start_with,
09.
@
level
:= 0
10.
) vars, t_hierarchy
11.
WHERE
@id
IS
NOT
NULL
12.
) ho
13.
JOIN
t_hierarchy hi
14.
ON
hi.id = ho.id
This query imitates recursion, so performance does not directly depend on the number of descendants.
View query for item 42
View query for item 31,415
Both queries complete in 600 ms
Summary
MySQL differs from the other systems in its possibilities to handle hierarchical data.On one hand, it lacks a native way to do recursive queries which
makes traversing the hierarchy trees harder. It can be emulated using a
custom function and session variables to maintain the recursion stack,
but this solution is more slow.
On the other hand, MySQL supports R-Tree indexes which can be used to query the ranges containing a given value. This type of search is required for the nested sets queries and R-Tree index is faster.
However, adjacency list is still faster for retrieving all descendants up to the given level.
Both adjacency lists and nested sets require extra maintenance in MySQL: adjacency lists require building a custom function to query each table, nested sets require a function to update it.
Updating a nested sets model can be slow too since R-Tree indexes take much longer time to add to them than B-Tree indexes.
However, using R-Tree indexes, nested sets model is
extra fast for searching for all descendants and all ancestors, and
shows decent performance in determining the item’s levels and filtering
on them.
In MySQL, it is advisable to add the
levelcolumn into the nested sets model which will make it super fast for all three types of queries. However, this will make it even more harder to update.
It should also be noted that the only storage engine that allows R-Tree indexes is MyISAM.
In case of an update (which can affect millions of rows even to insert a
single record), all table will be locked and will not be able to be
queried.
Conclusion
In MySQL, the nested sets modelshould be preferred if the updates to the hierarhical structure are
infrequent and it is affordable to lock the table for the duration of an
update (which can take minutes on a long table).
This implies creating the table using MyISAM storage engine, creating the bounding box of a
GEOMETRYtype as described above, indexing it with a
SPATIALindex and persisting the
levelin the table.
If the updates to the table are frequent or it is inaffordable to
lock the table for a long period of time implied by an update, then the adjacency list model should be used to store the hierarchical data.
This requires creating a function to query the table.
MySQL is the only system of the big four (MySQL, Oracle, SQL Server, PostgreSQL) for which the nested sets model shows decent performance and can be considered to stored hierarchical data.

相关文章推荐
- 【直播课】数据事务处理技术MySQL/TDSQL与PostgreSQL
- 收集MYSQL与Oracle如何处理重复数据的SQL
- mysql+mybatis中只获取一个list(有多条数据)中某几条数据的sql语句
- Mysql源代码分析(7):MYISAM的数据文件处理--转载
- DB2 Vs MySQL系列 | MySQL与DB2的数据类型对比
- mysql如何处理亿级数据的SQL 注意事项
- mysql大数据高并发处理(转载)
- Mysql源代码分析(7): MYISAM的数据文件处理--转载
- MYSQL与Oracle如何处理重复数据的SQL
- 处理MYSQL主从库数据不一致的问题【Slave_SQL_Running: No】
- 处理MYSQL主从库数据不一致的问题【Slave_SQL_Running: No】
- 同期及上期数据对比处理示例.sql
- mysql如何处理亿级数据,第一个阶段——优化SQL语句
- DB2 Vs MySQL系列 | MySQL与DB2的数据类型对比
- DB2 Vs MySQL系列 | MySQL与DB2的数据类型对比
- mysql大数据高并发处理(转载)
- 处理分页的数据函数GetlistByPage(strSQL, PageSize, PageNo, PageCount, arrList)
- MySQL专题10之MySQL序列使用、MySQL处理重复数据、MySQL以及SQL的注入
- mysql命令行命令和SQL语句,MySQL修改删除增加字段类型,字段数据等。。
- orcle+mysql+sqlserver三者手工创建数据库对比