转 实时数据管理 eXtremeDB内存数据库评测
2012-10-31 15:09
197 查看
原址如下:
http://tech.it168.com/a2012/1030/1415/000001415603_all.shtml
【IT168 专稿】eXtremeDB是一款高速内存实时数据库系统,该数据库用于各种需要高性能、小尺寸、紧密存储、零内存分配或几种属性兼有的应用领域。eXtremeDB内存实时数据库以其高性能、低开销、稳定可靠的实时数据管理能力在实时数据管理领域和嵌入式数据管理领域及服务器有着广泛的应用。
eXtremeDB能为各种平台、操纵系统下各类应用程序提供高性能和可靠性。这些应用程序不同于工资单或库存等普通数据库商业应用程序。这些程序的业务逻辑对性能要求非常高。简单查询和事务不超过几毫秒,并且需要存储的数据可能是复杂的,实际上它差不多总是动态变化的。因此,eXtremeDB有几点特性:
保持极小的必要堆空间:在某些配置上eXtremeDB只需要不到1K的堆空间;
不同于普通数据库,eXtremeDB与目的程序一同编译,不单独成为与目的程序通讯的独立进程,使用内部API,性能大幅提升;
通过紧密的集成持久存储和宿主应用程序语言消除额外的代码层。通常目标应用程序使用大量小规模的数据库操作而非大数据量的操作。这意味着通过指向对象的指针或引用来从对象中获得数据的操作必须非常迅速快捷,否则额外开销(例如发送一个消息的开销)会高得让人无法接受。eXtremeDB的数据存取方法使得对持久对象的引用能够和引用临时数据一样快速。
eXtremeDB数据库的实时数据管理应用使用者包括Boeing, Motorola, JVC, F5 Networks, Tyco Thermal Controls, Genesis Microchip, EFJohnson, Peiker acustic其他军工、石油、IT企业等。
安装配置
安装过程描述:
1. 获取eXtremeDB安装包文件
用户可以通过从McObject公司网站上下载eXtremeDB安装文件。
eXtremeDB在Linux平台下的安装包为扩展名是tar.gz的文件,它是一种压缩格式的文件。如下图:

通过McObject公司主页下载下来的试用版存在每次运行时100万个事务的数量限制。
2. 在linux平台中解压
在linux控制台下,输入命令,进行解压:
tar -xf extremedb_4.5_fusion_linux_x86_ha_sql_log_obj.tar.gz
如下图:

解压后,会出现一个eXtremeDB的文件夹,此文件夹即为eXtremeDB开发包。
3. 验证安装说明
安装完成后,在安装目录会产生eXtremeDB的文件夹,此为数据库的开发包。如图:

4. 目录说明
进入eXtremeDB文件夹,输入ls浏览文件,如图:

各个目录说明如下:
docs:数据库帮助文档文件夹,pdf格式。其中包括了eXtremeDB用户手册和参考手册,JNI接口用户手册,HA帮助文档和eXtremeSQL用户手册和参考手册。如下图:

host:工具目录,保存DDL(Data Definition Language)‘mcocomp’和‘mcorcomp’编译器,以及‘sql2mco’工具。
mcocomp工具是模式编译器,用来根据schema文件生成数据库操作的动态API接口。其命令选项含义如下:
mcorcomp工具是远程连接模式下的模式编译器。其命令选项含义如下:
sql2mco工具的功能是将sql脚本转换成schema文件。参数如下:
include:数据库所需头文件目录。此目录保存了数据库使用过程中需要用到的所有头文件。
·mco.h是最重要的一个头文件,所有使用数据库的程序必须包含。mco.h文件中包含了数据库错误码的定义、使用的枚举常量、宏定义、结构体定义以及数据库基本API的声明。
·Sql目录中包含了与SQL组件相关的头文件。
·Ha目录中包含了与HA组件相关的头文件。
odbc:ODBC文件夹。此文件夹中包含了使用ODBC编译程序时所需要链接的动态库与静态库,以及使用ODBC做数据库操作的例子程序。
·bin目录包含了ODBC驱动的静态库文件。
·bin.so目录包含了ODBC驱动的动态库文件。
·sample目录包含了使用ODBC创建使用eXtrmeDB数据库的两个例子。
samples:demo示例文件夹。此文件夹各个例子的说明间附录一。
target:目标文件夹,保存eXtremeDB库文件和编译产生的目标文件。其中bin和bin.so文件夹分别保存了eXtremeDB的静态库和动态库文件。Fs文件夹包含了不同文件系统相关的源代码和make文件,可以直接编译成所需要的静态库和动态库文件,产生库文件的目录分别为bin和bin.so。jni目录包含了对数据库访问的JNI接口的java源代码。
·bin目录包含了eXtremeDB数据库所用到的静态库文件,以及编译samples时所产生的可执行文件。
·bin.so目录包含了eXtremeDB数据库所用到的动态库文件。
·fs目录包含了不同文件系统相关的源代码,可以直接编译成所需要的静态库和动态库文件,产生库文件的目录分别为bin和bin.so。
·jni目录包含了对数据库访问的JNI接口的java源代码。
·sync目录包含了同步的接口文件,用户可以使用自己的方法来实现任务间的同步功能,可直接编译成动态库或静态库文件,产生库文件的目录分别为bin和bin.so。
5. 开发流程
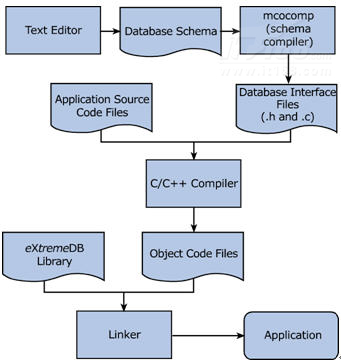
Benchmark测试
·测试环境
本次测试使用的软硬件环境如下:
硬件配置:Intel(R) Core(TM) i7
CPU 860 @ 2.80GHz,4核8线程, 内存8GB。
操作系统: Redhat Enterprise Linux 6.0 X64。
·测试假定
本次测试为充分展示内存数据库的性能,使用eXtremeDB的纯内存方式,并且使用eXtremeDB最快的接口――本地API接口以本地嵌入直连方式完成测试。
·数据结构
class Record
{
uint4 id;
uint4 i1;
uint4 i2;
double d1;
double d2;
char<30> s1;
char<30> s2;
list;
unique hash <id> hkey[10000000];
tree <id> tkey;
};
插入测试
·单线程
首先进行单线程的插入测试,向数据库中插入10000000条记录,性能如下:
单线程插入10000000条记录的耗时为27秒,每条记录的花费时间为2.7微秒,每秒处理的记录数为36万。
·4线程
之后我们增加线程数为4.
四个线程同时插入10000000条记录,性能如下:
四个线程插入10000000条记录的总耗时为12.8秒,平均每条记录耗时1.28微秒,每秒处理77万条数据。
·8线程
最后是8个线程的插入测试。
插入测试是通过8个线程,向数据库中添加10000000条记录,每个线程的性能和总体性能如下:
可以看到8个并发写入10000000条记录所花费的时间大概为14秒,平均每秒可以添加70万条记录。
·总结
插入操作的总体吞吐率:
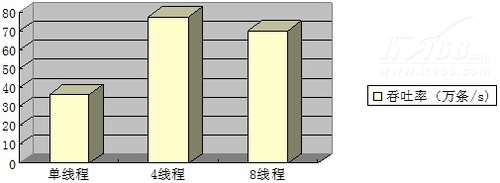
可以看到,插入操作的性能,4个线程并发操作时,吞吐率最大。
更新测试
·单线程
首先进行单线程的更新测试,在数据库中进行10000000次更新,每次更新一条记录的所有字段,性能如下:
单线程更新10000000条记录的耗时为57秒,每条记录的更新花费时间为5.7微秒,每秒处理的记录数为17.3万。
·4线程
之后我们增加线程数为4.
四个线程同时更新10000000条记录,性能如下:
四个线程更新10000000条记录的总耗时为28秒,平均每条记录耗时2.8微秒,每秒处理35万条数据。
·8线程
更新测试是通过八个线程,同时更新数据库中记录,共10000000次操作,每个线程的性能和总体性能如下:
可以看到8个并发同时更新10000000条记录所花费的时间大概为28.5秒,平均每秒可以更新35万条记录。此处的更新为涉及到了每条记录的每个字段。
·总结
更新操作的总体吞吐率:
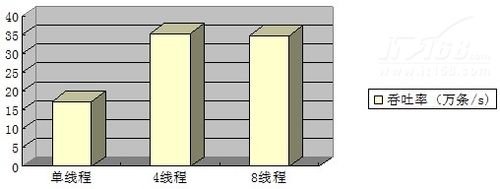
可以看到,更新操作的性能,同样也是4个线程并发操作时,吞吐率最大,但仅仅比8线程性能略高。
查询测试
·单线程
首先进行单线程的查询测试,在数据库中进行10000000次查找,性能如下:
单线程进行10000000次查询的耗时为8.5秒,每次查询花费时间为0.85微秒,每秒处理的操作数为116万。
·4线程
之后我们增加线程数为4.
四个线程进行10000000次查找操作,性能如下:
四个线程进行10000000次查找操作的总耗时为5秒,平均每条记录耗时0.5微秒,每秒处理197万次查询操作。
·8线程
查询测试是通过八个线程,同时查询数据库中记录,共10000000次查询,每个线程的性能和总体性能如下:
可以看到8个并发同时查询10000000条记录所花费的时间大概为6秒,平均每秒可以进行167万次查询。
·总结
查询操作的总体吞吐率:
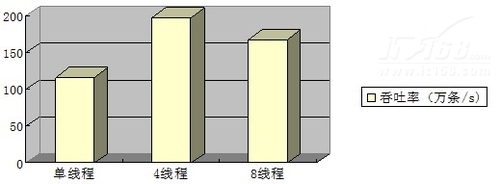
可以看到,查询操作的性能,同样也是4个线程并发操作时,吞吐率最大。
1:1读写测试
·4线程
首先进行四线程的读写测试,其中2个线程做更新操作,另外两个线程做查询操作,持续运行10秒钟,每个线程的性能和总体性能如下:
在四个线程进行读写测试时,平均每秒可以进行71万次查询,23万次更新,总体吞吐率为94万。
·8线程
读写测试是通过八个线程,其中四个线程持续做更新操作,另外四个线程做查询操作,持续运行10秒钟,每个线程的性能和总体性能如下:
可以看到同时进行读写测试时,平均每秒可以进行59万次查询,23万次更新,总体吞吐率为82万。
·总结
1:1读写操作的总体吞吐率:
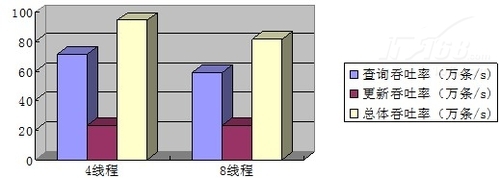
可以看到,1:1读写操作的性能,4线程比8线程的查询吞吐率和总体吞吐率高,而更新吞吐率几乎一致。
删除测试
·单线程
首先进行单线程的删除测试,在数据库中进行10000000次删除,每次删除一条记录,性能如下:
单线程进行10000000次删除操作的耗时为28.6秒,每次查询花费时间为2.86微秒,每秒处理的操作数为35万。
·4线程
之后我们增加线程数为4.
四个线程进行10000000次删除操作,性能如下:
四个线程进行10000000次删除操作的总耗时为17.7秒,平均删除每条记录耗时1.77微秒,每秒处理56万次删除操作。
·8线程
删除测试是通过八个线程,按照记录ID,同时删除数据库中记录,共10000000个对象,每个线程的性能和总体性能如下:
可以看到8个并发同时删除10000000条记录所花费的时间大概为21.5秒,平均每秒可以进行46.5万次删除。
·总结
查询操作的总体吞吐率:

可以看到,删除操作的性能,同样也是4个线程并发操作时,吞吐率最大。
以上测试都是每次操作都为一个事务,每次操作只涉及一条记录。
本文总结
从测试结果上来看,在性能上,eXtremeDB能够达到个位的微秒级响应速度,这个性能表现在业界也是领先的。但是在某些方面,eXtremeDB也略显不足,比如无压缩功能,缺少外围工具的支持,管理界面缺乏等等。同时它也具有通用内存数据库的共同缺点:内存数据库中的数据不总是永久的,数据量的大小受物理内存的限制,大数据量需要大量的内存开销等。eXtremeDB的优势也非常明显。低开销和高性能稳定可靠的特性,让eXtremeDB广泛应用于网络设备、消费电子、国防、航空航天、工业控制、轨道交通、能源电力、医疗设备,地理信息、汽车电子,以及金融实时交易、通信技术、互联网行业及领域等,得到了国内外许多知名客户的好评与青睐。
http://tech.it168.com/a2012/1030/1415/000001415603_all.shtml
【IT168 专稿】eXtremeDB是一款高速内存实时数据库系统,该数据库用于各种需要高性能、小尺寸、紧密存储、零内存分配或几种属性兼有的应用领域。eXtremeDB内存实时数据库以其高性能、低开销、稳定可靠的实时数据管理能力在实时数据管理领域和嵌入式数据管理领域及服务器有着广泛的应用。
eXtremeDB能为各种平台、操纵系统下各类应用程序提供高性能和可靠性。这些应用程序不同于工资单或库存等普通数据库商业应用程序。这些程序的业务逻辑对性能要求非常高。简单查询和事务不超过几毫秒,并且需要存储的数据可能是复杂的,实际上它差不多总是动态变化的。因此,eXtremeDB有几点特性:
保持极小的必要堆空间:在某些配置上eXtremeDB只需要不到1K的堆空间;
不同于普通数据库,eXtremeDB与目的程序一同编译,不单独成为与目的程序通讯的独立进程,使用内部API,性能大幅提升;
通过紧密的集成持久存储和宿主应用程序语言消除额外的代码层。通常目标应用程序使用大量小规模的数据库操作而非大数据量的操作。这意味着通过指向对象的指针或引用来从对象中获得数据的操作必须非常迅速快捷,否则额外开销(例如发送一个消息的开销)会高得让人无法接受。eXtremeDB的数据存取方法使得对持久对象的引用能够和引用临时数据一样快速。
eXtremeDB数据库的实时数据管理应用使用者包括Boeing, Motorola, JVC, F5 Networks, Tyco Thermal Controls, Genesis Microchip, EFJohnson, Peiker acustic其他军工、石油、IT企业等。
安装配置
安装过程描述:
1. 获取eXtremeDB安装包文件
用户可以通过从McObject公司网站上下载eXtremeDB安装文件。
eXtremeDB在Linux平台下的安装包为扩展名是tar.gz的文件,它是一种压缩格式的文件。如下图:
通过McObject公司主页下载下来的试用版存在每次运行时100万个事务的数量限制。
2. 在linux平台中解压
在linux控制台下,输入命令,进行解压:
tar -xf extremedb_4.5_fusion_linux_x86_ha_sql_log_obj.tar.gz
如下图:
解压后,会出现一个eXtremeDB的文件夹,此文件夹即为eXtremeDB开发包。
3. 验证安装说明
安装完成后,在安装目录会产生eXtremeDB的文件夹,此为数据库的开发包。如图:
4. 目录说明
进入eXtremeDB文件夹,输入ls浏览文件,如图:
各个目录说明如下:
docs:数据库帮助文档文件夹,pdf格式。其中包括了eXtremeDB用户手册和参考手册,JNI接口用户手册,HA帮助文档和eXtremeSQL用户手册和参考手册。如下图:
host:工具目录,保存DDL(Data Definition Language)‘mcocomp’和‘mcorcomp’编译器,以及‘sql2mco’工具。
mcocomp工具是模式编译器,用来根据schema文件生成数据库操作的动态API接口。其命令选项含义如下:
| mcocomp | |
| -o, -O | 优化实现文件 |
| -p, -P<path> | 设置输出文件路径 |
| -I<path> | 指定include路径 |
| -hpp | 产生C++接口 |
| -sa [typename] | 对指定的class或struct不产生API |
| -si | 指定详细的结构体初始化 |
| -c, -C | 指定“compact”选项 |
| -s, -S | 禁止版权记录 |
| -x, -X | 产生XML方法 |
| -sql | 添加sql选项 |
| -persistent | 未指定的表指定为persistent |
| -transient | 未指定的表指定为transient |
| -prefix | 指定schema中所有结构体/表/方法名的前缀 |
| -help | 帮助 |
| mcorcomp | |
| -I <include_path> | 指定include路径 |
| -D <SYMBOL>[=<VALUE>] | 定义一个SYMBOL,并给附初值(可选) |
| -U <SYMBOL> | 取消定义指定的SYMBOL |
| -P<PATH> | 设置输出文件路径 |
| -p<PATH> | 设置输出文件路径 |
| sql2mco | |
| <input-sql-file> | 输入的sql文件路径及文件名 |
| <output-mco-file> | 输出的schema文件路径及文件名 |
·mco.h是最重要的一个头文件,所有使用数据库的程序必须包含。mco.h文件中包含了数据库错误码的定义、使用的枚举常量、宏定义、结构体定义以及数据库基本API的声明。
·Sql目录中包含了与SQL组件相关的头文件。
·Ha目录中包含了与HA组件相关的头文件。
odbc:ODBC文件夹。此文件夹中包含了使用ODBC编译程序时所需要链接的动态库与静态库,以及使用ODBC做数据库操作的例子程序。
·bin目录包含了ODBC驱动的静态库文件。
·bin.so目录包含了ODBC驱动的动态库文件。
·sample目录包含了使用ODBC创建使用eXtrmeDB数据库的两个例子。
samples:demo示例文件夹。此文件夹各个例子的说明间附录一。
target:目标文件夹,保存eXtremeDB库文件和编译产生的目标文件。其中bin和bin.so文件夹分别保存了eXtremeDB的静态库和动态库文件。Fs文件夹包含了不同文件系统相关的源代码和make文件,可以直接编译成所需要的静态库和动态库文件,产生库文件的目录分别为bin和bin.so。jni目录包含了对数据库访问的JNI接口的java源代码。
·bin目录包含了eXtremeDB数据库所用到的静态库文件,以及编译samples时所产生的可执行文件。
·bin.so目录包含了eXtremeDB数据库所用到的动态库文件。
·fs目录包含了不同文件系统相关的源代码,可以直接编译成所需要的静态库和动态库文件,产生库文件的目录分别为bin和bin.so。
·jni目录包含了对数据库访问的JNI接口的java源代码。
·sync目录包含了同步的接口文件,用户可以使用自己的方法来实现任务间的同步功能,可直接编译成动态库或静态库文件,产生库文件的目录分别为bin和bin.so。
5. 开发流程
Benchmark测试
·测试环境
本次测试使用的软硬件环境如下:
硬件配置:Intel(R) Core(TM) i7
CPU 860 @ 2.80GHz,4核8线程, 内存8GB。
操作系统: Redhat Enterprise Linux 6.0 X64。
·测试假定
本次测试为充分展示内存数据库的性能,使用eXtremeDB的纯内存方式,并且使用eXtremeDB最快的接口――本地API接口以本地嵌入直连方式完成测试。
·数据结构
class Record
{
uint4 id;
uint4 i1;
uint4 i2;
double d1;
double d2;
char<30> s1;
char<30> s2;
list;
unique hash <id> hkey[10000000];
tree <id> tkey;
};
插入测试
·单线程
首先进行单线程的插入测试,向数据库中插入10000000条记录,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 10000000 | 27286 |
| 每条记录所花费的时间(微秒) | 2.7286 | |
| 每秒吞吐率(object/s) | 366488.3090 |
·4线程
之后我们增加线程数为4.
四个线程同时插入10000000条记录,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 2500000 | 12324 |
| 2 | 2500000 | 12929 |
| 3 | 2500000 | 13082 |
| 4 | 2500000 | 13158 |
| 插入10000000条记录所花费的总时间(秒) | 12.87325 | |
| 每条记录所花费的时间(微秒) | 1.287325 | |
| 每秒吞吐率(object/s) | 776804.6142 |
·8线程
最后是8个线程的插入测试。
插入测试是通过8个线程,向数据库中添加10000000条记录,每个线程的性能和总体性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 1250000 | 13641 |
| 2 | 1250000 | 14134 |
| 3 | 1250000 | 14173 |
| 4 | 1250000 | 14189 |
| 5 | 1250000 | 14214 |
| 6 | 1250000 | 14398 |
| 7 | 1250000 | 14407 |
| 8 | 1250000 | 14423 |
| 插入10000000条记录所花费的总时间(秒) | 14.19738 | |
| 每条记录所花费的时间(微秒) | 1.419738 | |
| 每秒吞吐率(object/s) | 704355.5587 |
·总结
插入操作的总体吞吐率:
可以看到,插入操作的性能,4个线程并发操作时,吞吐率最大。
更新测试
·单线程
首先进行单线程的更新测试,在数据库中进行10000000次更新,每次更新一条记录的所有字段,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 10000000 | 57740 |
| 每条记录所花费的时间(微秒) | 5.7740 | |
| 每秒吞吐率(object/s) | 173190.2 |
·4线程
之后我们增加线程数为4.
四个线程同时更新10000000条记录,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 2500000 | 28024 |
| 2 | 2500000 | 28070 |
| 3 | 2500000 | 28121 |
| 4 | 2500000 | 28724 |
| 插入10000000条记录所花费的总时间(秒) | 28.23475 | |
| 每条记录所花费的时间(微秒) | 2.823475 | |
| 每秒吞吐率(object/s) | 354173.5 |
·8线程
更新测试是通过八个线程,同时更新数据库中记录,共10000000次操作,每个线程的性能和总体性能如下:
| 线程ID | 操作次数 | 耗时(毫秒) |
| 1 | 1250000 | 27856 |
| 2 | 1250000 | 28172 |
| 3 | 1250000 | 28549 |
| 4 | 1250000 | 28587 |
| 5 | 1250000 | 28674 |
| 6 | 1250000 | 28795 |
| 7 | 1250000 | 28814 |
| 8 | 1250000 | 29209 |
| 更新10000000条记录的耗时(秒) | 28.582 | |
| 更新每条记录所的耗时(微秒) | 2.8582 | |
| 每秒吞吐率(object/s) | 349870.5 |
·总结
更新操作的总体吞吐率:
可以看到,更新操作的性能,同样也是4个线程并发操作时,吞吐率最大,但仅仅比8线程性能略高。
查询测试
·单线程
首先进行单线程的查询测试,在数据库中进行10000000次查找,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 10000000 | 8599 |
| 每条记录所花费的时间(微秒) | 0.8599 | |
| 每秒吞吐率(object/s) | 1162925.92 |
·4线程
之后我们增加线程数为4.
四个线程进行10000000次查找操作,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 2500000 | 4977 |
| 2 | 2500000 | 5037 |
| 3 | 2500000 | 5121 |
| 4 | 2500000 | 5164 |
| 插入10000000条记录所花费的总时间(秒) | 5.07475 | |
| 每条记录所花费的时间(微秒) | 0.507475 | |
| 每秒吞吐率(object/s) | 1970540.421 |
·8线程
查询测试是通过八个线程,同时查询数据库中记录,共10000000次查询,每个线程的性能和总体性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 1250000 | 5931 |
| 2 | 1250000 | 5962 |
| 3 | 1250000 | 5964 |
| 4 | 1250000 | 5966 |
| 5 | 1250000 | 5976 |
| 6 | 1250000 | 5987 |
| 7 | 1250000 | 5997 |
| 8 | 1250000 | 6000 |
| 查询10000000次的耗时(秒) | 5.972875 | |
| 每次查询的耗时(微秒) | 0.5972875 | |
| 每秒吞吐率(object/s) | 1674235.607 |
·总结
查询操作的总体吞吐率:
可以看到,查询操作的性能,同样也是4个线程并发操作时,吞吐率最大。
1:1读写测试
·4线程
首先进行四线程的读写测试,其中2个线程做更新操作,另外两个线程做查询操作,持续运行10秒钟,每个线程的性能和总体性能如下:
| 线程ID | 操作 | 操作次数 |
| 1 | 查询 | 3583497 |
| 2 | 查询 | 3562829 |
| 3 | 更新 | 1140404 |
| 4 | 更新 | 1164462 |
| 每秒查询吞吐率(完成次数/s) | 714632.6 | |
| 每秒更新吞吐率(完成次数/s) | 230486.6 | |
| 总吞吐率(完成次数/s) | 945119.2 |
·8线程
读写测试是通过八个线程,其中四个线程持续做更新操作,另外四个线程做查询操作,持续运行10秒钟,每个线程的性能和总体性能如下:
| 线程ID | 操作 | 操作次数 |
| 1 | 查询 | 1472087 |
| 2 | 查询 | 1473423 |
| 3 | 查询 | 1472310 |
| 4 | 查询 | 1466637 |
| 5 | 更新 | 569735 |
| 6 | 更新 | 572264 |
| 7 | 更新 | 580561 |
| 8 | 更新 | 576686 |
| 每秒查询吞吐率(完成次数/s) | 588445.7 | |
| 每秒更新吞吐率(完成次数/s) | 229924.6 | |
| 总吞吐率(完成次数/s) | 818370.3 |
·总结
1:1读写操作的总体吞吐率:
可以看到,1:1读写操作的性能,4线程比8线程的查询吞吐率和总体吞吐率高,而更新吞吐率几乎一致。
删除测试
·单线程
首先进行单线程的删除测试,在数据库中进行10000000次删除,每次删除一条记录,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 10000000 | 28658 |
| 每条记录所花费的时间(微秒) | 2.8658 | |
| 每秒吞吐率(object/s) | 348942.7 |
·4线程
之后我们增加线程数为4.
四个线程进行10000000次删除操作,性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 2500000 | 17556 |
| 2 | 2500000 | 17731 |
| 3 | 2500000 | 17826 |
| 4 | 2500000 | 17853 |
| 插入10000000条记录所花费的总时间(秒) | 17.7415 | |
| 每条记录所花费的时间(微秒) | 1.77415 | |
| 每秒吞吐率(object/s) | 563650.2 |
·8线程
删除测试是通过八个线程,按照记录ID,同时删除数据库中记录,共10000000个对象,每个线程的性能和总体性能如下:
| 线程ID | 记录数 | 耗时(毫秒) |
| 1 | 1250000 | 21352 |
| 2 | 1250000 | 21386 |
| 3 | 1250000 | 21414 |
| 4 | 1250000 | 21436 |
| 5 | 1250000 | 21454 |
| 6 | 1250000 | 21516 |
| 7 | 1250000 | 21541 |
| 8 | 1250000 | 21714 |
| 查询10000000次的耗时(秒) | 21.47663 | |
| 每次查询的耗时(微秒) | 2.147663 | |
| 每秒吞吐率(object/s) | 465622.5 |
·总结
查询操作的总体吞吐率:
可以看到,删除操作的性能,同样也是4个线程并发操作时,吞吐率最大。
以上测试都是每次操作都为一个事务,每次操作只涉及一条记录。
本文总结
从测试结果上来看,在性能上,eXtremeDB能够达到个位的微秒级响应速度,这个性能表现在业界也是领先的。但是在某些方面,eXtremeDB也略显不足,比如无压缩功能,缺少外围工具的支持,管理界面缺乏等等。同时它也具有通用内存数据库的共同缺点:内存数据库中的数据不总是永久的,数据量的大小受物理内存的限制,大数据量需要大量的内存开销等。eXtremeDB的优势也非常明显。低开销和高性能稳定可靠的特性,让eXtremeDB广泛应用于网络设备、消费电子、国防、航空航天、工业控制、轨道交通、能源电力、医疗设备,地理信息、汽车电子,以及金融实时交易、通信技术、互联网行业及领域等,得到了国内外许多知名客户的好评与青睐。

相关文章推荐
- 实时内存数据库的数据管理
- 实时内存数据库的数据管理
- 实时内存数据库的数据管理
- 实时数据管理的挑战和eXtremeDB实时数据库
- elasticsearch2.3.2服务搭建、管理及实时同步mysql数据
- 大数据管理:数据集成的技术、方法与最佳实践 读书笔记五之实时数据集成
- Android流量管理实时刷新流量数据
- Excel VBA高效办公应用-第十一章-教师员工数据管理-Part1 (教师考核评测数据处理)
- 实时内存数据库eXtremeDB 在linux系统下的java开发环境搭建
- 实时数据缓存管理的初步设计
- 实时数据缓存管理的初步设计
- (转)实时数据库内存数据管理
- oracle数据文件管理
- Android网络开发之实时获取最新数据
- 小娜老师的讲义-Docker基础知识-数据管理
- Lync Server 2013中央管理存储:自动收集配置数据失败
- DataWindow的数据管理与更新机制的研究与应用
- IOS数据管理工具CoreData入门之双向关系操作
- Docker数据管理:Named volume
- Java虚拟机管理划分的运行时数据区域