sql server 2008学习10 存储过程
2012-09-11 12:31
218 查看
输入输出参数:
给存储过程传参数,叫做输入参数,用户告诉存储过程需要 利用这个参数干些什么.
输出参数: 从存储过程得到那些数据.
创建一个可选参数的存储过程:
exec pa1

exec pa1 a

创建输出参数:
使用输出参数 传递 最后一次插入的标识列的值:
执行这个存储过程:
结果如下:

返回值:
执行:
结果:


错误处理:
可以使用 @@error
下面使用try/catch
什么是 内联错误: 那些能让sql server 继续运行,但是因为某种原因而不能 成功完成指定任务的错误.
手动引发错误:
raiserror(message_ID,级别,state)
可以查看 sql server 提供的所有错误消息: select * from master.sys.messages
存储过程的优点:
可复用
安全性.可以创建一个返回结果集的存储过程而不用赋予用户访问底层数据表的权限.
存储过程和性能
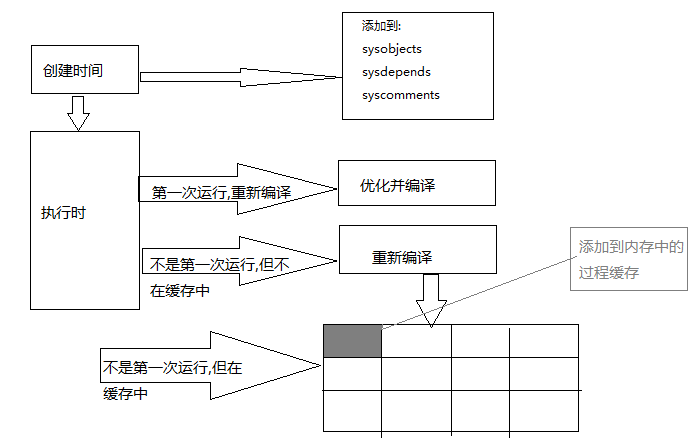
下面看一下存储过程是如何工作的:

首先运行 create proc过程,这回解析查询 以确保会实际运行这些代码.它与 直接运行脚本的区别在于:
create proc可以利用所谓的 延迟对象解析. 可以忽略一些对象还不存在的实施,这就可以稍后创建这些对象.
在创建存储过程之后,它将等待第一次执行.在那时,存储过程呗优化,而查询计划被 编译并且 缓存到系统上.
后续几次运行此过程时,除非使用 with recompile选项指定,否则都会使用缓存的查询计划. 意味着每次使用存储过程
时,存储过程都会跳过很多优化和编译工作.
如果想 在每次执行存储过程时都自动重新编译,那么可以这样做:
递归:
计算阶乘
执行此过程:
结果:

给存储过程传参数,叫做输入参数,用户告诉存储过程需要 利用这个参数干些什么.
输出参数: 从存储过程得到那些数据.
创建一个可选参数的存储过程:
create proc pa1 @name varchar(50)=NULL as if(@name is not null) select * from a where name like @name+'%'; else select * from a
exec pa1
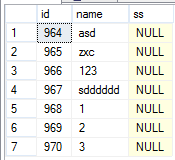
exec pa1 a

创建输出参数:
使用输出参数 传递 最后一次插入的标识列的值:
create proc pa2
@id int output
as
insert into a(name) values('5')
set @id=@@identity执行这个存储过程:
declare @id int exec pa2 @id out print @id
结果如下:
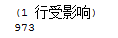
返回值:
创建有返回值的存储过程:
create proc pa5 as declare @mess varchar(50) set @mess='exit' print @mess; return;
执行:
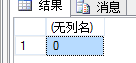
declare @result varchar(50) exec @result=pa5 select @result
结果:

错误处理:
可以使用 @@error
use test go if exists(select * from sysobjects where name='pa6') drop proc pa6 go create proc pa6 @name nvarchar(50), @ss int as declare @error int insert into b values(@name,@ss); set @error=@@error if @error=0 print 'new record is inserted' ; else begin if @error=547 print 'at least one provided parameter was not found,correct an retry'; else print ' unknown error occurred' end
下面使用try/catch
什么是 内联错误: 那些能让sql server 继续运行,但是因为某种原因而不能 成功完成指定任务的错误.
手动引发错误:
raiserror(message_ID,级别,state)
可以查看 sql server 提供的所有错误消息: select * from master.sys.messages
存储过程的优点:
可复用
安全性.可以创建一个返回结果集的存储过程而不用赋予用户访问底层数据表的权限.
存储过程和性能
下面看一下存储过程是如何工作的:
首先运行 create proc过程,这回解析查询 以确保会实际运行这些代码.它与 直接运行脚本的区别在于:
create proc可以利用所谓的 延迟对象解析. 可以忽略一些对象还不存在的实施,这就可以稍后创建这些对象.
在创建存储过程之后,它将等待第一次执行.在那时,存储过程呗优化,而查询计划被 编译并且 缓存到系统上.
后续几次运行此过程时,除非使用 with recompile选项指定,否则都会使用缓存的查询计划. 意味着每次使用存储过程
时,存储过程都会跳过很多优化和编译工作.
如果想 在每次执行存储过程时都自动重新编译,那么可以这样做:
create proc pa1 with recompile --这句可以实现 as select * from a
递归:
计算阶乘
create proc aa @vin int, @vout int out as declare @inv int declare @outv int if @vin !=1 begin select @inv=@vin-1; exec aa @inv,@outv out; select @vout=@vin*@outv; end else begin select @vout=1; end return ; go
执行此过程:
declare @inv int; declare @outv int; set @inv=5; exec aa @inv,@outv out; print cast(@outv as varchar(30))
结果:


相关文章推荐
- sql server 2008学习10 存储过程
- SQL Server 2008空间数据应用系列十:使用存储过程生成GeoRSS聚合空间信息
- sql server 2008学习(二)基本查询
- SSIS学习视频(SQL Server 2008)
- SQL Server 2008存储过程中使用另一个存储过程返回的记录集
- SQL_Server_2008完全学习之第九章存储过程
- 一、 使用存储过程实现数据分页(Sql Server 2008 R2)
- sql server 2008学习12 事务和锁
- SQL Server 2008编程入门经典笔记:存储过程
- sql server 2000/2005/2008 判断存储过程、触发器、视图是否存在并删除
- SQL SERVER 2008密码,凭证学习
- SQL Server 2008 R2 文件组学习笔记
- VMware从零开始学习之04 SQL Server 2008 R2 安装
- SQL Server 2008 Integration Services ETL 学习笔记
- sql server 2008学习12 事务和锁
- 我的IT学习笔记——SQL Server 2008
- SQL Server 2008 学习笔记(一) 数据库系统的基本结构
- 如何在SQL Server 2008下轻松调试T-SQL语句和存储过程
- 学习SQL SERVER的存储过程-之一认识存储过程语法
- Sql Server 2008 常用系统存储过程