OpenCL 学习step by step (5) 使用二维NDRange workgroup
2012-09-07 19:48
375 查看
在本教程中,我们使用二维NDRange来设置workgroup,这样在opencl中,workitme的组织形式是二维的,Kernel中 的代码也要做相应的改变,我们先看一下clEnqueueNDRangeKernel函数的变化。首先我们指定了workgroup size为localx*localy,通常这个值为64的倍数,但最好不要超过256。
//执行kernel,Range用2维,work itmes size为width*height,
cl_event ev;
size_t globalThreads[] = {width, height};
size_t localx, localy;
if(width/8 > 4)
localx = 16;
else if(width < 8)
localx = width;
else localx = 8;
if(height/8 > 4)
localy = 16;
else if (height < 8)
localy = height;
else localy = 8;
size_t localThreads[] = {localx, localy}; // localx*localy应该是64的倍数
printf("global_work_size =(%d,%d), local_work_size=(%d, %d)\n",width,height,localx,localy);
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
2,
NULL,
globalThreads,
localThreads, 0, NULL, &ev);
注意:在上面代码中,定义global threads以及local threads数量,都是通过二维数组的方式进行的。
新的Kernel代码如下:
我们在kernel中增加了#pragma OPENCL EXTENSION cl_amd_printf : enable,以便在kernel中通过printf函数进行debug,这是AMD的一个扩展。printf还可以直接打印出float4这样的向量,比如printf(“%v4f”, vec)。
另外,在main.cpp中增加一行代码:
//告诉driver dump il和isa文件
_putenv("GPU_DUMP_DEVICE_KERNEL=3");
我们可以在程序目录dump出il和isa形式的kernel文件,对于熟悉isa汇编的人,这是一个很好的调试performance的方法。
在最新的app sdk 2.7中,在kernel中使用printf的时候,这个程序会hang在哪儿,以前没这种情况。
程序执行界面。

完整的代码请参考:
工程文件gclTutorial4
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
//执行kernel,Range用2维,work itmes size为width*height,
cl_event ev;
size_t globalThreads[] = {width, height};
size_t localx, localy;
if(width/8 > 4)
localx = 16;
else if(width < 8)
localx = width;
else localx = 8;
if(height/8 > 4)
localy = 16;
else if (height < 8)
localy = height;
else localy = 8;
size_t localThreads[] = {localx, localy}; // localx*localy应该是64的倍数
printf("global_work_size =(%d,%d), local_work_size=(%d, %d)\n",width,height,localx,localy);
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
2,
NULL,
globalThreads,
localThreads, 0, NULL, &ev);
注意:在上面代码中,定义global threads以及local threads数量,都是通过二维数组的方式进行的。
新的Kernel代码如下:
#pragma OPENCL EXTENSION cl_amd_printf : enable
__kernel void vecadd(__global const float* a, __global const float* b, __global float* c)
{
int x = get_global_id(0);
int y = get_global_id(1);
int width = get_global_size(0);
int height = get_global_size(1);
if(x == 1 && y ==1)
printf("%d, %d,%d,%d,%d,%d\n",get_local_size(0),get_local_size(1),get_local_id(0),get_local_id(1),get_group_id(0),get_group_id(1));
c[x + y * width] = a[x + y * width] + b[x + y * width];
}我们在kernel中增加了#pragma OPENCL EXTENSION cl_amd_printf : enable,以便在kernel中通过printf函数进行debug,这是AMD的一个扩展。printf还可以直接打印出float4这样的向量,比如printf(“%v4f”, vec)。
另外,在main.cpp中增加一行代码:
//告诉driver dump il和isa文件
_putenv("GPU_DUMP_DEVICE_KERNEL=3");
我们可以在程序目录dump出il和isa形式的kernel文件,对于熟悉isa汇编的人,这是一个很好的调试performance的方法。
在最新的app sdk 2.7中,在kernel中使用printf的时候,这个程序会hang在哪儿,以前没这种情况。
程序执行界面。
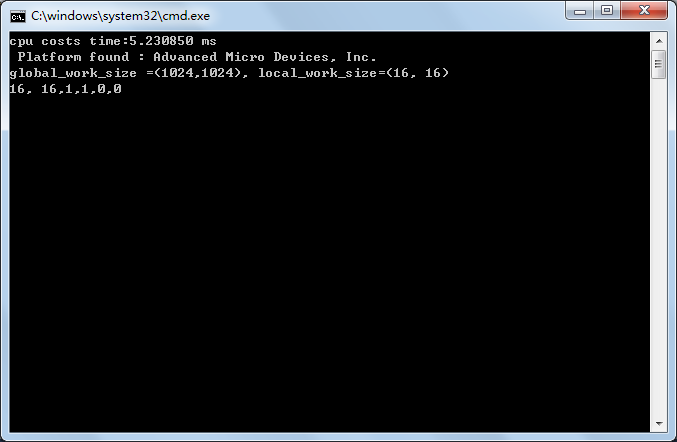
完整的代码请参考:
工程文件gclTutorial4
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip

相关文章推荐
- OpenCL 学习step by step (5) 使用二维NDRange workgroup
- OpenCL 学习step by step (5) 使用二维NDRange workgroup
- OpenCL 学习step by step (7) 灰度图Histogram计算(1)
- OpenCL 学习step by step (1) 安装AMD OpenCL APP
- OpenCL 学习step by step (8) 灰度图Histogram计算(2)
- OpenCL 学习step by step
- OpenCL 学习step by step (1) 安装AMD OpenCL APP
- 【神经网络与深度学习】Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
- OpenCL 学习step by step (11) 数组求和(reduction)
- cocos2d-x 3.1.1 step by step 学习笔记4 标签使用
- OpenCL 学习step by step (2) 一个简单的OpenCL的程序
- OpenCL 学习step by step (2) 一个简单的OpenCL的程序
- OpenCL 学习step by step (3) 存储kernel文件为二进制
- OpenCL 学习step by step (3) 存储kernel文件为二进制
- OpenCL 学习step by step (2) 一个简单的OpenCL的程序
- OpenCL 学习step by step (4) 读入二进制kernel文件
- OpenCL 学习step by step (4) 读入二进制kernel文件
- OpenCL 学习step by step (3) 存储kernel文件为二进制
- OpenCL 学习step by step (6) 旋转图像
- cocos2d-x 3.1.1 step by step 学习笔记5 菜单使用