数据结构大总结系列之从HASH谈到set/map再到hashtable/hash_map/hash_set
2012-08-06 15:07
525 查看
前言:
今天又看了July的博文教你如何迅速秒杀掉:99%的海量数据处理面试题,其中有介绍到set/map与hashtable/hash_map/hash_set,本文就是对其做的一些总结。
第一部分:什么是HASH
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:

左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素
散列表:
一个具有关键字k的元素被被散列到h(k)上,h(k)是关键字k的散列值。采用散列函数的目的就在于缩小需要处理的下标范围,即我们要处理的值就从U降到m了
碰撞:
通过链接法解决碰撞:
链接法的最坏情况下的查找时间为O(n),
假定可以再O(1)时间内计算出散列值h(k),从而查找具有关键字为k的元素的时间线性的依赖于表T[h(k)]的长度n
全部字典操作在平均情况下都可以再O(1)时间内完成。
散列函数:
除法散列法:
h(k)=
k mod m;
乘法散列法:
h(k) = 下底(m(kAmod1))
用关键字k成乘上常数k,并抽取kA的小数部分。然后,用m乘以这个值,再取结果的底。
第二部分:HASH表的查找
我们由一个简单的问题逐步入手:有一个庞大的字符串数组,然后给你一个单独的字符串,让你从这个数组中查找是否有这个字符串并找到它,你会怎么做?有一个方法最简单,老老实实从头查到尾,一个一个比较,直到找到为止,我想只要学过程序设计的人都能把这样一个程序作出来,但要是有程序员把这样的程序交给用户,我只能用无语来评价,或许它真的能工作,但...也只能如此了。
是不是把第一个算法改进一下,改成逐个比较字符串的Hash值就可以了呢,答案是,远远不够,要想得到最快的算法,就不能进行逐个的比较,通常是构造一个哈希表(Hash Table)来解决问题,哈希表是一个大数组,这个数组的容量根据程序的要求来定义,例如1024,每一个Hash值通过取模运算 (mod) 对应到数组中的一个位置,这样,只要比较这个字符串的哈希值对应的位置有没有被占用,就可以得到最后的结果了,想想这是什么速度?是的,是最快的O(1)。
hash表的一个简单的实现,具体函数参见/article/8713418.html
struct HashNode
{
char* sKey; //键
int nValue; //值
HashNode* pNext; //当Hash值冲突时,指向HASH值相同的下一个节点。
}
HashNode* hashTable[HASH_TABLE_MAX_SIZE]; //哈希表的数组
int hash_table_size; //哈希表中元素的个数
第三部分:强大的MPQ
这里先介绍一下MPQ,MPQ,也称MoPaQ,是Mike O'Brien发明的一种压缩文件格式。在1996作为,MPQ应用在Diablo(暗黑破坏神)游戏中。
回到刚才的查找,我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”,感谢大学里学的数据结构教会了这个百试百灵的法宝,我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。事情到此似乎有了完美的结局, 然而Blizzard的程序员使用的方法则是更精妙的方法。基本原理就是:他们在哈希表中不是用一个哈希值而是用三个哈希值来校验字符串。
MPQ使用文件名哈希表来跟踪内部的所有文件。但是这个表的格式与正常的哈希表有一些不同。首先,它没有使用哈希作为下标,把实际的文件名存储在表中用于验证,实际上它根本就没有存储文件名。而是使用了3种不同的哈希:一个用于哈希表的下标,两个用于验证。这两个验证哈希替代了实际文件名。
当然了,这样仍然会出现2个不同的文件名哈希到3个同样的哈希。但是这种情况发生的概率平均是:1:18889465931478580854784,这个概率对于任何人来说应该都是足够小的。现在再回到数据结构上,Blizzard使用的哈希表没有使用链表,而采用"顺延"的方式来解决问题,看看这个算法:
lpszString 为要在hash表中查找的字符串;lpTable 为存储字符串hash值的hash表;nTableSize 为hash表的长度:
int GetHashTablePos( char *lpszString, MPQHASHTABLE *lpTable, int nTableSize )
{
const int HASH_OFFSET = 0, HASH_A = 1, HASH_B = 2;
int nHash = HashString( lpszString, HASH_OFFSET );
int nHashA = HashString( lpszString, HASH_A );
int nHashB = HashString( lpszString, HASH_B );
int nHashStart = nHash % nTableSize;
int nHashPos = nHashStart;
while ( lpTable[nHashPos].bExists )
{
/*如果仅仅是判断在该表中时候存在这个字符串,就比较这两个hash值就可以了,不用对
*结构体中的字符串进行比较。这样会加快运行的速度?减少hash表占用的空间?这种
*方法一般应用在什么场合?*/
if ( lpTable[nHashPos].nHashA == nHashA
&& lpTable[nHashPos].nHashB == nHashB )
{
return nHashPos;
}
else
{
nHashPos = (nHashPos + 1) % nTableSize;
}
if (nHashPos == nHashStart)
break;
}
return -1;
}
上述程序解释:
1.计算出字符串的三个哈希值(一个用来确定位置,另外两个用来校验)
2. 察看哈希表中的这个位置
3. 哈希表中这个位置为空吗?如果为空,则肯定该字符串不存在,返回-1。
4. 如果存在,则检查其他两个哈希值是否也匹配,如果匹配,则表示找到了该字符串,返回其Hash值。
5. 移到下一个位置,如果已经移到了表的末尾,则反绕到表的开始位置起继续查询
6. 看看是不是又回到了原来的位置,如果是,则返回没找到
7. 回到3
具体的代码和介绍请参加博文http://blog.csdn.net/v_JULY_v/article/details/6256463
第四部分:从set/map谈到hashtable/hash_map/hash_set
STL容器分两种,
序列式容器(vector/list/deque/stack/queue/heap),
关联式容器。关联式容器又分为set(集合)和map(映射表)两大类,以及这两大类的衍生体multiset(多键集合)和multimap(多键映射表),这些容器均以RB-tree完成。此外,还有第3类关联式容器,如hashtable(散列表),以及以hashtable为底层机制完成的hash_set(散列集合)/hash_map(散列映射表)/hash_multiset(散列多键集合)/hash_multimap(散列多键映射表)。也就是说,set/map/multiset/multimap都内含一个RB-tree,而hash_set/hash_map/hash_multiset/hash_multimap都内含一个hashtable。
所谓关联式容器,类似关联式数据库,每笔数据或每个元素都有一个键值(key)和一个实值(value),即所谓的Key-Value(键-值对)。当元素被插入到关联式容器中时,容器内部结构(RB-tree/hashtable)便依照其键值大小,以某种特定规则将这个元素放置于适当位置。
包括在非关联式数据库中,比如,在MongoDB内,文档(document)是最基本的数据组织形式,每个文档也是以Key-Value(键-值对)的方式组织起来。一个文档可以有多个Key-Value组合,每个Value可以是不同的类型,比如String、Integer、List等等。
{ "name" : "July",
"sex" : "male",
"age" : 23 }
set/map/multiset/multimap
set,同map一样,所有元素都会根据元素的键值自动被排序,因为set/map两者的所有各种操作,都只是转而调用RB-tree的操作行为,不过,值得注意的是,两者都不允许两个元素有相同的键值。
不同的是:set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值,而map的所有元素都是pair,同时拥有实值(value)和键值(key),pair的第一个元素被视为键值,第二个元素被视为实值。
至于multiset/multimap,他们的特性及用法和set/map完全相同,唯一的差别就在于它们允许键值重复,即所有的插入操作基于RB-tree的insert_equal()而非insert_unique()。
hash_table:

hash_set/hash_map/hash_multiset/hash_multimap
hash_set/hash_map,两者的一切操作都是基于hashtable之上。不同的是,hash_set同set一样,同时拥有实值和键值,且实质就是键值,键值就是实值,而hash_map同map一样,每一个元素同时拥有一个实值(value)和一个键值(key),所以其使用方式,和上面的map基本相同。但由于hash_set/hash_map都是基于hashtable之上,所以不具备自动排序功能。为什么?因为hashtable没有自动排序功能。
至于hash_multiset/hash_multimap的特性与上面的multiset/multimap完全相同,唯一的差别就是它们hash_multiset/hash_multimap的底层实现机制是hashtable(而multiset/multimap,上面说了,底层实现机制是RB-tree),所以它们的元素都不会被自动排序,不过也都允许键值重复。
所以,综上,说白了,什么样的结构决定其什么样的性质,因为set/map/multiset/multimap都是基于RB-tree之上,所以有自动排序功能,而hash_set/hash_map/hash_multiset/hash_multimap都是基于hashtable之上,所以不含有自动排序功能,至于加个前缀multi_无非就是允许键值重复而已,对比RB-tree和hash-table,前者有自动排序的优点,而后者在查找方面有O(1)的优势
hash_map的应用:/article/1746039.html
set/map,与hash_set/hash_map的性能比较?共计3个问题,如下:
1、hash_set在千万级数据下,insert操作优于set? 这位blog:http://t.cn/zOibP7t给的实践数据可靠不?
2、那map和hash_map的性能比较呢? 谁做过相关实验?
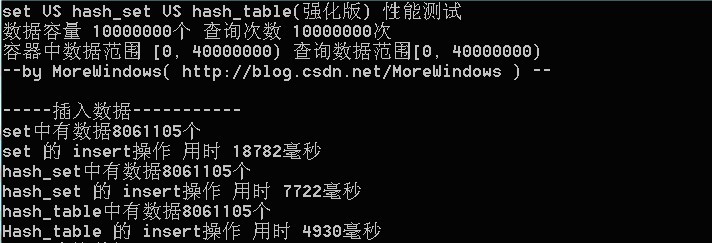
3、那查询操作呢,如下段文字所述?

今天又看了July的博文教你如何迅速秒杀掉:99%的海量数据处理面试题,其中有介绍到set/map与hashtable/hash_map/hash_set,本文就是对其做的一些总结。
第一部分:什么是HASH
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素
散列表:
一个具有关键字k的元素被被散列到h(k)上,h(k)是关键字k的散列值。采用散列函数的目的就在于缩小需要处理的下标范围,即我们要处理的值就从U降到m了
碰撞:
通过链接法解决碰撞:
链接法的最坏情况下的查找时间为O(n),
假定可以再O(1)时间内计算出散列值h(k),从而查找具有关键字为k的元素的时间线性的依赖于表T[h(k)]的长度n
全部字典操作在平均情况下都可以再O(1)时间内完成。
散列函数:
除法散列法:
h(k)=
k mod m;
乘法散列法:
h(k) = 下底(m(kAmod1))
用关键字k成乘上常数k,并抽取kA的小数部分。然后,用m乘以这个值,再取结果的底。
第二部分:HASH表的查找
我们由一个简单的问题逐步入手:有一个庞大的字符串数组,然后给你一个单独的字符串,让你从这个数组中查找是否有这个字符串并找到它,你会怎么做?有一个方法最简单,老老实实从头查到尾,一个一个比较,直到找到为止,我想只要学过程序设计的人都能把这样一个程序作出来,但要是有程序员把这样的程序交给用户,我只能用无语来评价,或许它真的能工作,但...也只能如此了。
是不是把第一个算法改进一下,改成逐个比较字符串的Hash值就可以了呢,答案是,远远不够,要想得到最快的算法,就不能进行逐个的比较,通常是构造一个哈希表(Hash Table)来解决问题,哈希表是一个大数组,这个数组的容量根据程序的要求来定义,例如1024,每一个Hash值通过取模运算 (mod) 对应到数组中的一个位置,这样,只要比较这个字符串的哈希值对应的位置有没有被占用,就可以得到最后的结果了,想想这是什么速度?是的,是最快的O(1)。
hash表的一个简单的实现,具体函数参见/article/8713418.html
struct HashNode
{
char* sKey; //键
int nValue; //值
HashNode* pNext; //当Hash值冲突时,指向HASH值相同的下一个节点。
}
HashNode* hashTable[HASH_TABLE_MAX_SIZE]; //哈希表的数组
int hash_table_size; //哈希表中元素的个数
第三部分:强大的MPQ
这里先介绍一下MPQ,MPQ,也称MoPaQ,是Mike O'Brien发明的一种压缩文件格式。在1996作为,MPQ应用在Diablo(暗黑破坏神)游戏中。
回到刚才的查找,我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”,感谢大学里学的数据结构教会了这个百试百灵的法宝,我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。事情到此似乎有了完美的结局, 然而Blizzard的程序员使用的方法则是更精妙的方法。基本原理就是:他们在哈希表中不是用一个哈希值而是用三个哈希值来校验字符串。
MPQ使用文件名哈希表来跟踪内部的所有文件。但是这个表的格式与正常的哈希表有一些不同。首先,它没有使用哈希作为下标,把实际的文件名存储在表中用于验证,实际上它根本就没有存储文件名。而是使用了3种不同的哈希:一个用于哈希表的下标,两个用于验证。这两个验证哈希替代了实际文件名。
当然了,这样仍然会出现2个不同的文件名哈希到3个同样的哈希。但是这种情况发生的概率平均是:1:18889465931478580854784,这个概率对于任何人来说应该都是足够小的。现在再回到数据结构上,Blizzard使用的哈希表没有使用链表,而采用"顺延"的方式来解决问题,看看这个算法:
lpszString 为要在hash表中查找的字符串;lpTable 为存储字符串hash值的hash表;nTableSize 为hash表的长度:
int GetHashTablePos( char *lpszString, MPQHASHTABLE *lpTable, int nTableSize )
{
const int HASH_OFFSET = 0, HASH_A = 1, HASH_B = 2;
int nHash = HashString( lpszString, HASH_OFFSET );
int nHashA = HashString( lpszString, HASH_A );
int nHashB = HashString( lpszString, HASH_B );
int nHashStart = nHash % nTableSize;
int nHashPos = nHashStart;
while ( lpTable[nHashPos].bExists )
{
/*如果仅仅是判断在该表中时候存在这个字符串,就比较这两个hash值就可以了,不用对
*结构体中的字符串进行比较。这样会加快运行的速度?减少hash表占用的空间?这种
*方法一般应用在什么场合?*/
if ( lpTable[nHashPos].nHashA == nHashA
&& lpTable[nHashPos].nHashB == nHashB )
{
return nHashPos;
}
else
{
nHashPos = (nHashPos + 1) % nTableSize;
}
if (nHashPos == nHashStart)
break;
}
return -1;
}
上述程序解释:
1.计算出字符串的三个哈希值(一个用来确定位置,另外两个用来校验)
2. 察看哈希表中的这个位置
3. 哈希表中这个位置为空吗?如果为空,则肯定该字符串不存在,返回-1。
4. 如果存在,则检查其他两个哈希值是否也匹配,如果匹配,则表示找到了该字符串,返回其Hash值。
5. 移到下一个位置,如果已经移到了表的末尾,则反绕到表的开始位置起继续查询
6. 看看是不是又回到了原来的位置,如果是,则返回没找到
7. 回到3
具体的代码和介绍请参加博文http://blog.csdn.net/v_JULY_v/article/details/6256463
第四部分:从set/map谈到hashtable/hash_map/hash_set
STL容器分两种,
序列式容器(vector/list/deque/stack/queue/heap),
关联式容器。关联式容器又分为set(集合)和map(映射表)两大类,以及这两大类的衍生体multiset(多键集合)和multimap(多键映射表),这些容器均以RB-tree完成。此外,还有第3类关联式容器,如hashtable(散列表),以及以hashtable为底层机制完成的hash_set(散列集合)/hash_map(散列映射表)/hash_multiset(散列多键集合)/hash_multimap(散列多键映射表)。也就是说,set/map/multiset/multimap都内含一个RB-tree,而hash_set/hash_map/hash_multiset/hash_multimap都内含一个hashtable。
所谓关联式容器,类似关联式数据库,每笔数据或每个元素都有一个键值(key)和一个实值(value),即所谓的Key-Value(键-值对)。当元素被插入到关联式容器中时,容器内部结构(RB-tree/hashtable)便依照其键值大小,以某种特定规则将这个元素放置于适当位置。
包括在非关联式数据库中,比如,在MongoDB内,文档(document)是最基本的数据组织形式,每个文档也是以Key-Value(键-值对)的方式组织起来。一个文档可以有多个Key-Value组合,每个Value可以是不同的类型,比如String、Integer、List等等。
{ "name" : "July",
"sex" : "male",
"age" : 23 }
set/map/multiset/multimap
set,同map一样,所有元素都会根据元素的键值自动被排序,因为set/map两者的所有各种操作,都只是转而调用RB-tree的操作行为,不过,值得注意的是,两者都不允许两个元素有相同的键值。
不同的是:set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值,而map的所有元素都是pair,同时拥有实值(value)和键值(key),pair的第一个元素被视为键值,第二个元素被视为实值。
至于multiset/multimap,他们的特性及用法和set/map完全相同,唯一的差别就在于它们允许键值重复,即所有的插入操作基于RB-tree的insert_equal()而非insert_unique()。
hash_table:
hash_set/hash_map/hash_multiset/hash_multimap
hash_set/hash_map,两者的一切操作都是基于hashtable之上。不同的是,hash_set同set一样,同时拥有实值和键值,且实质就是键值,键值就是实值,而hash_map同map一样,每一个元素同时拥有一个实值(value)和一个键值(key),所以其使用方式,和上面的map基本相同。但由于hash_set/hash_map都是基于hashtable之上,所以不具备自动排序功能。为什么?因为hashtable没有自动排序功能。
至于hash_multiset/hash_multimap的特性与上面的multiset/multimap完全相同,唯一的差别就是它们hash_multiset/hash_multimap的底层实现机制是hashtable(而multiset/multimap,上面说了,底层实现机制是RB-tree),所以它们的元素都不会被自动排序,不过也都允许键值重复。
所以,综上,说白了,什么样的结构决定其什么样的性质,因为set/map/multiset/multimap都是基于RB-tree之上,所以有自动排序功能,而hash_set/hash_map/hash_multiset/hash_multimap都是基于hashtable之上,所以不含有自动排序功能,至于加个前缀multi_无非就是允许键值重复而已,对比RB-tree和hash-table,前者有自动排序的优点,而后者在查找方面有O(1)的优势
hash_map的应用:/article/1746039.html
set/map,与hash_set/hash_map的性能比较?共计3个问题,如下:
1、hash_set在千万级数据下,insert操作优于set? 这位blog:http://t.cn/zOibP7t给的实践数据可靠不?
2、那map和hash_map的性能比较呢? 谁做过相关实验?
3、那查询操作呢,如下段文字所述?

相关文章推荐
- 从set/map谈到hashtable/hash_map/hash_set
- 第一部分、从 set/map 谈到 hashtable/hash_map/hash_set
- STL学习——STL中的关联式容器总结(RB-tree、set、map、hashtable、hash_set、hash_map)
- 从set/map谈到hashtable/hash_map/hash_set
- 【第10章 关联容器】hashtable, hash_map, hash_set, hash_multiset, hash_multimap基于hashtable
- Java【集合系列】-14- Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- 5.Java集合总结系列:常见集合类的使用(List/Set/Map)
- Java系列-Set、List、Map的遍历总结
- Java 集合系列之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- Redis基本数据结构总结之SET、ZSET和HASH
- ECMAScript 6 学习系列课程 (ES6 Set和Map数据结构)
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
- java集合: List、Set、Map总结 + HashMap/Hashtable 差别
- Redis基本数据结构总结之SET、ZSET和HASH
- 再思考Java里的数据结构容器——hash容器:hashset hashmap hashtable
- 数据结构-08-集合(Set)-哈希表(Hash)-图(Map)