(基于Java)编写编译器和解释器-第5章:解析表达式和赋值语句-第一部分(连载)
2012-07-20 20:24
591 查看
在前面的章节中,你已了解在翻译过程中解析器是如何在堆栈上创建和维护符号表的,也知道它执行的某些语义动作如创建和生成表现源程序的中间码(intermediate code)。如第一章所描绘的那样,前端生成的中间码是源程序的一种抽象的、预摘要格式(pre-digested,可以理解为在源程序格式和机器语言格式中间的一个摘要格式,一般为分析树parse tree或抽象语法树syntax tree),方便后端能高效处理。它是前后端之间的一个关键接口,如图1-3和图2-1所示。
==>> 本章中文版源代码下载:svn co http://wci.googlecode.com/svn/branches/ch5/ 源代码使用了UTF-8编码,下载到本地请修改!
前端某些结构(constructs)的解析器:复合语句,赋值语句以及表达式。
解析器生成灵活且语言无关的中间码,用来表示这些结构。
本章仅是个开始。在第6章你将会只用本章学到的中间码和符号来表执行表达式和赋值语句。
本章中接下来将开始使用表现Pascal结构的语法图(syntax diagrams)。如同你在前章学习符号表那样,你将为中间码结构建立概念设计,开发表现接口的Java接口以及编写Java接口实现代码。语法图将引导为生成恰当中间码的解析器的开发过程。最后,一个语法检测实用程序将帮助你验证本章所写代码是否正确。
再次提醒,解析过程也称语法分析,解析器也就是俗称的语法分析器。
语法图
图5-1 展示了Pascaly语句、语句列表(即多个语句在一起)、复合语句以及赋值语句的语法图。因为复合语句本身也是语句,所以复合语句可以嵌套。这章你只需处理复合语句和赋值语句(还有空语句);后续将会涉及到其它Pascal语句。
图5-1:一些Pascal语句的语法图

statment: 一般语句
statement list:连着多条语句的语句列表
compound statement:复合语句
assignment statement:赋值语句
variable:变量
expression:表达式
word:单词或单词token
--------------------------------------
点击图片放大看
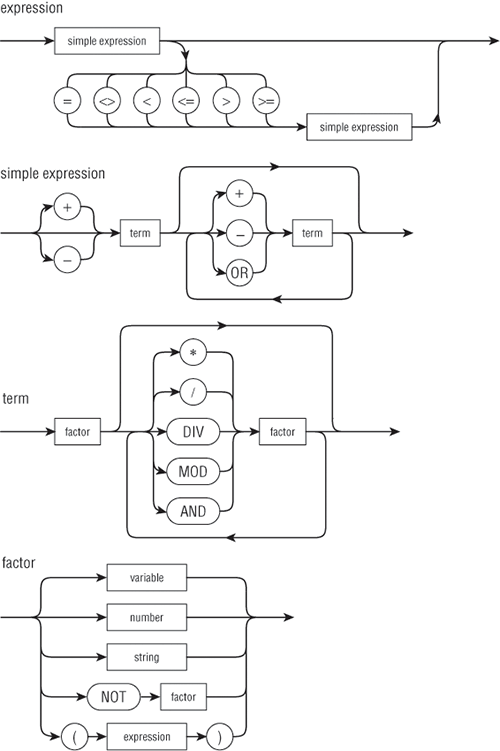
图5-2:Pascal 表达式语法图

图例显示出一个表达式是由单个简单表达式(simple expression)或两个用关系操作符如 = (留意Pascal中使用=表示关系等价比较符,:=表示赋值,而Java是用==和=) 或 <= 隔开的两个简单表达式组成。一个简单表达式由一个或多个被加法运算符(additive operator,加和减都是加法运算符)隔开的term组成。第一个term前面可能有一个加或减号(表示正负)。一个term由一个或多个被操作符隔开的factor组成。factor可以是变量,数字,字符串,NOT紧接另一个factor(表示否定的意思,相当于!boolean_factor)以及被对称括号括住的另一表达式(如(a+b)或((a+b)+(c+d))等)。目前变量只是简单标识符,而一个标识符(identifier)是一个单词(word,参见单词token)。后面将会处理下标和记录域之类的变量(比如数组下标a[0],a[1],还有记录域如a.b,a.b.c等)。
图5-2中的语法图不仅递归的定义了Pascal表达式和它的组成部分(components),它的层次化组成也明确了Pascal的操作符优先级规则。如果你从最上面一个图,由上至下,将每个图中的方框比如简单表达式和term当做对另外一个图的函数过程调用,很明显,低处语法图中的操作符结合更紧密且比高处语法图中的操作符先一步执行。因此,从最底处往上看语法图,Pascal有4级操作优先级:(实际上的Pascal不止这4级,这儿是为写书的简化版本)
如果没有括号(园括号(),改变优先级),高级别的操作符优于低级别的执行,同一级别操作符从左到右执行。因为最底处的语法图factor定义了带括号的表达式,所以带括号表达式总是先执行,从最里面的括号往外执行(这个很好理解,比如有两层括号(a+(b+c)),首先执行最里面的括号表达式b+c,得到结果k,然后是外面括号表达式a+k)。括号里面的表达式优先级按正常的4级执行。
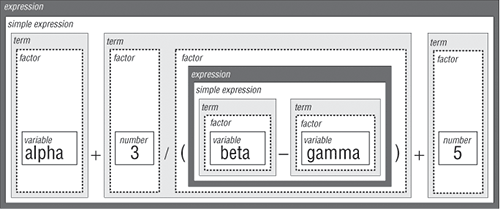
图5-3 展示了怎么遵照表达式语法图,分解算术表达式 alpha + 3 / (beta – gamma) + 5
图5-3: Pascal表达式分解

图5-4 展示了如下的复合语句的分析树:
清单5-2 展示了接口ICodeNode 详细参见本章源代码,这里不再显示。
清单5-3 展示了接口ICodeNodeType,现在它是一个占位类,没有内容,实现为枚举。详细参见本章源代码,这里不再显示。
清单5-4 展示了接口ICodeKey,它也是一个占位类,实现同样为枚举。详细参见本章源代码,这里不再显示。
如符号表工厂一样,这儿对中间码也需要一个工厂类产生它的组件。清单5-5 展示了类ICodeFactory:

清单 5-7 展示了类ICodeImpl。详细参见本章源代码,这里不再显示。这是一个分析树节点非常简单明了的实现。构造函数用给定的节点类型创建一个节点。copy方法创建一个与当前节点同类型的新节点,并将所有属性拷贝到新节点。
清单5-8 展示了枚举类型ICodeNodeTypeImpl。详细参见本章源代码,这里不再显示。它枚举了所有分析树节点类型的值。
清单5-9 展示了枚举类型ICodeKeyImpl。详细参见本章源代码,这里不再显示。
不要在分析树节点上存太多属性(要使用硬编码,方便查看程序结构和逻辑)。大部分信息被分布在节点类型本身和分析树结构上(比如结构上的域等)。
工业标准XML能以文本格式表现树结构。例如,清单5-10 展示了图5-4中的分析树呈现,这里假定对应的源代码在第18行到22行。
==>> 本章中文版源代码下载:svn co http://wci.googlecode.com/svn/branches/ch5/ 源代码使用了UTF-8编码,下载到本地请修改!
目标和方法
这章你将重点关注表达式解析,但也包括包含表达式的赋值语句,还有包含赋值语句的复合(compound)语句。我们的目标是:前端某些结构(constructs)的解析器:复合语句,赋值语句以及表达式。
解析器生成灵活且语言无关的中间码,用来表示这些结构。
本章仅是个开始。在第6章你将会只用本章学到的中间码和符号来表执行表达式和赋值语句。
本章中接下来将开始使用表现Pascal结构的语法图(syntax diagrams)。如同你在前章学习符号表那样,你将为中间码结构建立概念设计,开发表现接口的Java接口以及编写Java接口实现代码。语法图将引导为生成恰当中间码的解析器的开发过程。最后,一个语法检测实用程序将帮助你验证本章所写代码是否正确。
再次提醒,解析过程也称语法分析,解析器也就是俗称的语法分析器。
语法图
图5-1 展示了Pascaly语句、语句列表(即多个语句在一起)、复合语句以及赋值语句的语法图。因为复合语句本身也是语句,所以复合语句可以嵌套。这章你只需处理复合语句和赋值语句(还有空语句);后续将会涉及到其它Pascal语句。
图5-1:一些Pascal语句的语法图

statment: 一般语句
statement list:连着多条语句的语句列表
compound statement:复合语句
assignment statement:赋值语句
variable:变量
expression:表达式
word:单词或单词token
--------------------------------------
点击图片放大看
图5-2:Pascal 表达式语法图
图例显示出一个表达式是由单个简单表达式(simple expression)或两个用关系操作符如 = (留意Pascal中使用=表示关系等价比较符,:=表示赋值,而Java是用==和=) 或 <= 隔开的两个简单表达式组成。一个简单表达式由一个或多个被加法运算符(additive operator,加和减都是加法运算符)隔开的term组成。第一个term前面可能有一个加或减号(表示正负)。一个term由一个或多个被操作符隔开的factor组成。factor可以是变量,数字,字符串,NOT紧接另一个factor(表示否定的意思,相当于!boolean_factor)以及被对称括号括住的另一表达式(如(a+b)或((a+b)+(c+d))等)。目前变量只是简单标识符,而一个标识符(identifier)是一个单词(word,参见单词token)。后面将会处理下标和记录域之类的变量(比如数组下标a[0],a[1],还有记录域如a.b,a.b.c等)。
| 设计笔记 |
| 再说一次,语法图的圆框表示终端符号,因此每个都嵌有字面文本。Pascal有1字符或2字符长的特殊符号比如 = 和 := (这提示我们在词法解析的时候,只需要前探两次即可,在antlr中,LLK中的 k=2),关键字不区分大小写。 |
| 层级 | 操作符 |
| 1(最高) | NOT |
| 2 | 乘法类运算符 * / DIV MOD AND |
| 3 | 加法类运算符 + - |
| 4 | 关系比较符:= <> < <= > >= |
图5-3 展示了怎么遵照表达式语法图,分解算术表达式 alpha + 3 / (beta – gamma) + 5
图5-3: Pascal表达式分解
中间码概念设计
有很多种方式表示中间码。你将会用树形数据结构,因而中间码的形式成了分析树(parse tree)。(更准确的说法是抽象语法树或AST,因为有些源程序Token比如括号被“抽象”没了。但本书仍旧使用通用术语分析树)图5-4 展示了如下的复合语句的分析树:
public interface ICode
{/**
* 使某一节点成为分析树的根节点
* @param node 树节点
* @return 根节点
*/
public ICodeNode setRoot(ICodeNode node);
/**
* @return 分析树跟节点
*/
public ICodeNode getRoot();
}[/code]
清单5-2 展示了接口ICodeNode 详细参见本章源代码,这里不再显示。
清单5-3 展示了接口ICodeNodeType,现在它是一个占位类,没有内容,实现为枚举。详细参见本章源代码,这里不再显示。
清单5-4 展示了接口ICodeKey,它也是一个占位类,实现同样为枚举。详细参见本章源代码,这里不再显示。
中间码工厂
到现在为止,概念设计和接口并不依赖中间码的具体实现。所有调用中间码的类只需要对中间码接口编程,为使接口与实现松耦合。(如果不记得,复习上一章的重要设计理念:松耦合和面向接口编程,也可以维基百科)如符号表工厂一样,这儿对中间码也需要一个工厂类产生它的组件。清单5-5 展示了类ICodeFactory:
[code] public class ICodeFactory
{/**
* @return 以接口形式返回的中间码实现
*/
public static ICode createICode()
{return new ICodeImpl();
}
/**
* @param type 分析树节点类型
* @return 分析树节点
*/
public static ICodeNode createICodeNode(ICodeNodeType type)
{return new ICodeNodeImpl(type);
}
}[/code]
中间码实现
图5-6展示了intermediate.icodeimpl包中的UML类图,这些类实现了中间码接口。类ICodeImpl实现了接口ICode,类ICodeNodeImpl实现了接口ICodeNode。同样类ICodeNodeTypeImpl实现了类ICodeNodeType且类ICodeKeyImpl实现了类ICodeKey。
清单 5-7 展示了类ICodeImpl。详细参见本章源代码,这里不再显示。这是一个分析树节点非常简单明了的实现。构造函数用给定的节点类型创建一个节点。copy方法创建一个与当前节点同类型的新节点,并将所有属性拷贝到新节点。
| 设计笔记 |
| 类ICodeNodeImpl扩展自java.util.HashMap。如同你实现符号表项那样,将分析树节点实现成哈希表,为在每个节点能存储什么属性问题上,提供了最大的灵活性。 |
| 设计笔记 |
| 通过定义一个单数的枚举值集合,而不是使用枚举类型PascalTokenType现有的值,使得中间码能保持语言无关。 |
不要在分析树节点上存太多属性(要使用硬编码,方便查看程序结构和逻辑)。大部分信息被分布在节点类型本身和分析树结构上(比如结构上的域等)。
打印分析树
"-i"命令行参数被用来请求打印中间码,调试很有用。因为中间码是一个分析树,你打印树结构需要一个漂亮格式。工业标准XML能以文本格式表现树结构。例如,清单5-10 展示了图5-4中的分析树呈现,这里假定对应的源代码在第18行到22行。
<COMPOUND line="18"> <ASSIGN line="19"> <VARIABLE id="alpha" level="0" /> <NEGATE> <INTEGER_CONSTANT value="88" /> </NEGATE> </ASSIGN> <ASSIGN line="20"> <VARIABLE id="beta" level="0" /> <INTEGER_CONSTANT value="99" /> </ASSIGN> <ASSIGN line="21"> <VARIABLE id="result" level="0" /> <ADD> <ADD> <VARIABLE id="alpha" level="0" /> <FLOAT_DIVIDE> <INTEGER_CONSTANT value="3" /> <SUBTRACT> <VARIABLE id="beta" level="0" /> <VARIABLE id="gamma" level="0" /> </SUBTRACT> </FLOAT_DIVIDE> </ADD> <INTEGER_CONSTANT value="5" /> </ADD> </ASSIGN> </COMPOUND>
| 设计笔记 |
| 扩展标记语言(XML)是一个用来表现结构化数据的工业标准,在互联网(Internet)上渐渐流行,通常用来跨网络传输数据,尤其是Web Services。有很多领域应用相关的XML格式(比如工作流BPEL,TCP协议包等)和数不清的API,工具和实用程序用来生成和处理XML。 一个XML文档由元素(element)组成。一个元素通过标记(tag)呈现,比如<address>。一个元素可包含文本或子元素等内容。如果它包含内容,元素通过开放标记(opening tag)和结束标记(closing tag)嵌入内容。例如: <address> <street>123 Main Street</street> <city>San Jose</city> <state>CA</state> </address>与开放标记匹配的结束标记名字一样,但多了一个反斜杠 "/",比如</address>。一个元素如果没有内容可以写成 BEGIN BEGIN{Temperature conversions.}five:= -1 + 2 - 3 + 4 + 3; ratio := five/9.0; fahrenheit := 72; centigrade := (fahrenheit - 32)*ratio; centigrade := 25; fahrenheit := centigrade/ratio + 32; centigrade := 25; fahrenheit := 32 + centigrade/ratio END; {Runtime division by zero error.}dze := fahrenheit/(ratio - ratio); BEGIN{Calculate a square root using Newton's method.}number := 2; root := number; root := (number/root + root)/2; END; ch:= 'x'; str := 'hello, world' END. 要完成解析,首先要修改front.pascal包中类PascalParserTD,使其可称为语句解析器的父类并能够解析Pascal复合语句(留意增加了新的构造函数,传入父解析类)。清单5-13 展示了新构造函数和新版本的parse()方法。 清单5-17 :PascalParserTD改进版,用于处理语句块。 /*新增链条解析(Parser Chain) */ public PascalParserTD(PascalParserTD parent){super(parent.getScanner()); } /** * Pascal的解析过程,产生Pascal相关的iCode和symbol table */ public void parse() throws Exception{long startTime = System.currentTimeMillis(); iCode = ICodeFactory.createICode(); try{Token token = nextToken(); ICodeNode root_node = null; if (token.getType() == PascalTokenType.BEGIN){//前探到一个最外部的复合语句 StatementParser default_parser = new StatementParser(this); //解析begin XXXXX end. 中的内容XXXXX,并吞噬掉end root_node = default_parser.parse(token); token = currentToken(); //指向end. 中的. }else{//每个Pascal程序必须以begin开头,end. 结束 errorHandler.flag(token, PascalErrorCode.UNEXPECTED_TOKEN, this); } if (root_node != null){iCode.setRoot(root_node); } //最后的.存在么? if (token.getType() != PascalTokenType.DOT){errorHandler.flag(token, PascalErrorCode.MISSING_PERIOD, this); } token = currentToken(); //没意义,不过我还是放在这,尊重作者。 // 发送编译摘要信息 float elapsedTime = (System.currentTimeMillis() - startTime) / 1000f; sendMessage(new Message(PARSER_SUMMARY, new Number[]{token.getLineNumber(), getErrorCount(), elapsedTime})); } catch (IOException e){errorHandler.abortTranslation(PascalErrorCode.IO_ERROR, this); } } Pascal解析器子类对象不管何时要创建子解析器对象,它都会调用新构造函数,使得每个子对象都能动态继承父对象的组件(这里主要是Scanner)。如清单5-13新构造器用法所示,一个子解析器对象继承父对象的扫描器(scanner)。提醒一下,前端工厂类FrontendFactory调用的还是原来的构造器(即传入Scanner的那个)。 方法parse()检查当前的token是否是BEGIN,如果是,它调用statementParser.parse()解析一个复合语句直到包含与BEGIN匹配的END为止(详细参见代码),并返回生成的子解析树的根节点。这完成后,当前的token将会是最后的那个点"."(也就是PERIOD TOKEN)。 后续章节你将继续修改类PascalParserTD(还有很多东西没有包含进来,比如过程,函数,记录Record等等)。 >> 继续第5章 相关文章推荐
|
