(基于Java)编写编译器和解释器-第4章:符号表(连载)
2012-07-19 13:58
706 查看
作为语义分析的一部分,解释器/编译器的解析器在整个翻译过程中创建和维护符号表。符号表用来存储源文件中的token数据信息,基本上跟标识符有关。如你在图1-3和2-1中所看到的,符号表是横在前端和后端之间即中间层的一个核心组件。
==>> 本章中文版源代码下载:svn co http://wci.googlecode.com/svn/branches/ch4/ 源代码使用了UTF-8编码,下载到局部请修改!
本章目标是:
一个灵活的,语言无关的符号表。
一个简单的实用程序用来解析Pascal 源程序,并生成一个标识符(ID)交叉引用(cross-reference)列表。
方法先建立符号表的概念设计,接着开发表现此设计的Java接口,最后编写Java类实现接口。交叉引用的实用程序将帮助验证你代码的正确性,它将通过建立(entering),查找(finding),和更新(updating)数据等操作来使用符号表。
符号表概念设计
在翻译过程中,编译器/解释器创建和更新符号表的表项(entry),表项用来存储源程序中某些token的信息。每个表项有个名字即token的文本串。例如,存储标识符 token的表项用了标识符的名字,它还包括标识符的其它信息。在源程序翻译过程中,编译器/解释器查找和更新这些信息。
符号表要放什么样的数据? 有用的数据!有关标识符的符号表项一般会包括它的类型,结构,以及是怎么定义的。(符号表概念设计)目标之一保持符号表的灵活性,使其不仅限于Pascal。不管符号表存储什么样的信息,它必须要支持的基本操作有:
建立新数据(enter new information)
查找现存数据(look up existing information)
更新现存数据(update existing information)
图4-1 展示了符号表栈、符号表、符号表项的概念设计。在概念设计中,符号表栈包含一个或多个符号表,而每个表中又包含多个表项。每个符号表项包含一个一般为标识符 token的信息,还包含表项名称和属性形式的token信息。符号表以表项名为搜索关键字搜索相关表项。

此时你不需知道也不需关心该用何种数据结构构建符号表或该如何存储表项。根据概念设计,你仅需要明白符号表有哪些重要组件,它们各扮演什么角色,以及相互之间的关系。
(图中的Symbol table为符号表,Entry为符号表中的一项。符号表项有名称name和各式其它属性attributes)。
点击图片放大看
图4-2:符号表接口

尽管目前栈中只有一个(符号)表,你也能引入符号表的一些关键操作:
* 在局部符号表中建立一个新的表项,当前的表在栈顶。
* 通过搜索局部符号表查找某个表项。
* 在栈中的所有表中查找某个表项。
一旦某个符号表项被找到,你就能更新它的内容。注意你只能在局部表中建立新表项。然后你能在局部表或栈中的所有表中查找某表项。
接口SymTabStack支持上面的这些操作。方法enterLocal在局部表中建立一个新项。方法lookupLocal搜索局部表,还有方法lookup搜索栈中所有表。接口SymTabStack定义了另两个方法:getCurrentNestingLevel()返回当前的嵌套层级及getLocalSymTab()返回栈顶的局部符号表。直到第9章才涉及到嵌套(多个符号表,目前只有一个)。
接口SymTabEntry 表示一个符号表项。方法getName()获取项的名称,方法setAttributes和getAttributes分别设置和返回表项的属性信息。为支持交叉引用,方法appendLineNumber() 在每次表项名称出现时,存储对应的源代码行位置。方法getLineNumbers()返回表项所有的行位置信息。每个表项保留一个指向包含它的符号表的引用,方法getSymTab返回这个引用。
根据图4-2中的UML类图很自然的创建这些Java接口(为毛不用代码生成,还要手写??)。清单4-1 展示了SymTabStack接口。
点击图片放大看
清单4-1:SymTabStack接口 详细参见本章源代码,这里不再显示。
第二章有SymTab接口的早期版本。清单4-2 展示了一个内容更丰富的版本。详细参见本章源代码,这里不再显示。
清单4-3 展示了SymTabEntry接口。详细参见本章源代码,这里不再显示。
最后,清单4-4 展示SymTabKey的占位接口,它用来表示表项的属性键。 详细参见本章源代码,这里不再显示。

因为你希望符号表的调用代码仅关注它的接口,你得搞个符号表工厂将调用者与实现细节隔离开来。清单 4-5 展示了类SymTabFactory。每个方法可构造某个此实现类的实例,返回实现的接口。详细参见本章源代码,这里不再显示。
因为一个编译器/解释器仅有单个符号表栈,你能通过一个静态域指向它。清单展示了框架类Parser中的静态域symTabStack。
清单4-6 Parser类的静态域(符号表栈)
方法setAttribute()和getAttribute分别调用了父哈希表的put()和get()方法。
清单4-10 展示了枚举类型SymTabKeyImpl,它实现了接口SymTabKey。后续章节将会用到这些键。详细参见本章源代码,这里不再显示。
到此完成了本章的第一个目标,即建立一个灵活的,语言无关的符号表。符号表的灵活性体现在调用者只需关注它的接口,因而容许后续实现的改进。符号表项能存储任意信息,并没有Pascal特定限制。
java -classpath classes Pascal compile -x newton.pas
-x选项用来生成交叉引用列表。
清单4-11:一个生成的交叉引用清单。
String name = token.getText().toLowerCase();
清单4-13 展示了util包中的新辅助类CrossReferencer。详细参见本章源代码,这里不再显示。
方法printSymTab()遍历符号表的有序表项。对每个项,它先打印出标识符的名字,接着是所有行位置的明细。
在第9章,在学过怎么解析Pascal声明(declarations)后,你将会写一个更NB的CrosssReferencer版本。
为支持打印交叉引用表,须在Pascal主程序的构造函数中做些小改动。
首先将源程序的行输出注释掉,因为没啥意义。详见源程序中的第49行。
然后添加一个域stack指向程序运行过程中的符号表堆栈:
接着在Pascal构造函数中的62行处,增加打印交叉引用语句,详见下面的粗体部分。
注意这儿有个较大的变化就是前面章节中的symTab域将会被stack取代(作者刚开始为简单没有引入符号表堆栈,只有个符号表占位,现在加进了,所有有好几api要改)。构造函数现在从parser中取符号表栈,而不是符号表。你需要修改Backend抽象类的process方法,将第二个参数的类型由SymTab改成SymTabStack。因为抽象process是个抽象函数,你还必须改它的两个继承类的实现:compiler和executor。
如果 "-x"命令行参数存在,则构造函数创建一个新的CrossReferencer对象,然后调用它的print方法生成一个交叉引用列表。
==>> 本章中文版源代码下载:svn co http://wci.googlecode.com/svn/branches/ch4/ 源代码使用了UTF-8编码,下载到局部请修改!
目标与方法
对于编译器开发者来说,维护一个组织良好的符号表(Symbol Table)是一个重要技能。当编译器/解释器翻译源程序时,它必须能够快速有效地建立新数据,访问和更新现存数据。否则翻译过程会变慢或变糟,生成不正确的结果。本章目标是:
一个灵活的,语言无关的符号表。
一个简单的实用程序用来解析Pascal 源程序,并生成一个标识符(ID)交叉引用(cross-reference)列表。
方法先建立符号表的概念设计,接着开发表现此设计的Java接口,最后编写Java类实现接口。交叉引用的实用程序将帮助验证你代码的正确性,它将通过建立(entering),查找(finding),和更新(updating)数据等操作来使用符号表。
符号表概念设计
在翻译过程中,编译器/解释器创建和更新符号表的表项(entry),表项用来存储源程序中某些token的信息。每个表项有个名字即token的文本串。例如,存储标识符 token的表项用了标识符的名字,它还包括标识符的其它信息。在源程序翻译过程中,编译器/解释器查找和更新这些信息。符号表要放什么样的数据? 有用的数据!有关标识符的符号表项一般会包括它的类型,结构,以及是怎么定义的。(符号表概念设计)目标之一保持符号表的灵活性,使其不仅限于Pascal。不管符号表存储什么样的信息,它必须要支持的基本操作有:
建立新数据(enter new information)
查找现存数据(look up existing information)
更新现存数据(update existing information)
符号表栈
为解析块状结构化的语言比如Pascal,你实际上需要多个符号表(当然类型只有一个,这儿是说多个实例)-- 全局符号表一个,每个主程序一个,每个过程(procedure)和函数(function)一个,每个记录(Record)类型一个。因为Pascal函数和记录可以嵌套(routine,procedure和function都是routine),符号表必须在一个栈上维护。栈顶的符号表维护当前解析器正处理的程序、函数、结构、记录的相关信息。当解析器按照某种方式解析一个Pascal程序时,碰到进入和离开嵌套函数和记录类型定义的情况,分别压入符号表(入栈)和弹出符号表(出栈)。栈顶的符号表就是俗称的局部表(local table)。(如果全局表是栈中唯一元素,那么它也是局部表)图4-1 展示了符号表栈、符号表、符号表项的概念设计。在概念设计中,符号表栈包含一个或多个符号表,而每个表中又包含多个表项。每个符号表项包含一个一般为标识符 token的信息,还包含表项名称和属性形式的token信息。符号表以表项名为搜索关键字搜索相关表项。
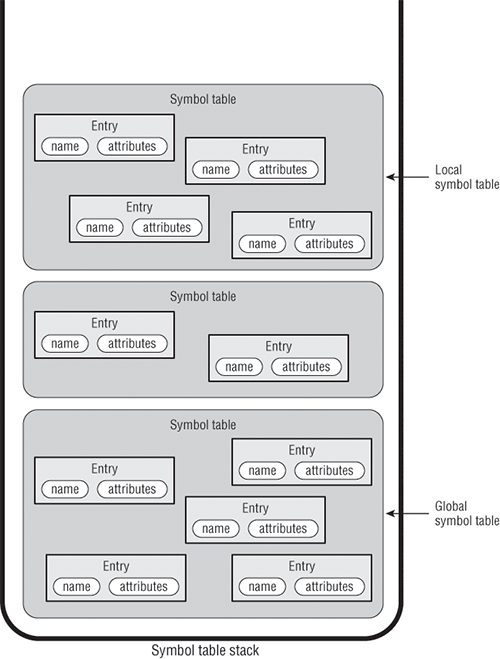
此时你不需知道也不需关心该用何种数据结构构建符号表或该如何存储表项。根据概念设计,你仅需要明白符号表有哪些重要组件,它们各扮演什么角色,以及相互之间的关系。
| 设计笔记 |
| 理想情况下,编译器/解释器的其它组件不必知道太多符号表概念层面以外的东西(比如实现),这维护了主要组件之间的松耦合关系。 直到第9章,你仅会在栈中看到一个符号表。现在定义符号表将会使得后续涉及到多个符号表的翻译过程更轻松。 |
点击图片放大看
符号表接口
根据图4-1所示的符号表组件,你可得到一个接口的UML设计图,这些接口放在包intermediate中。图4-2:符号表接口
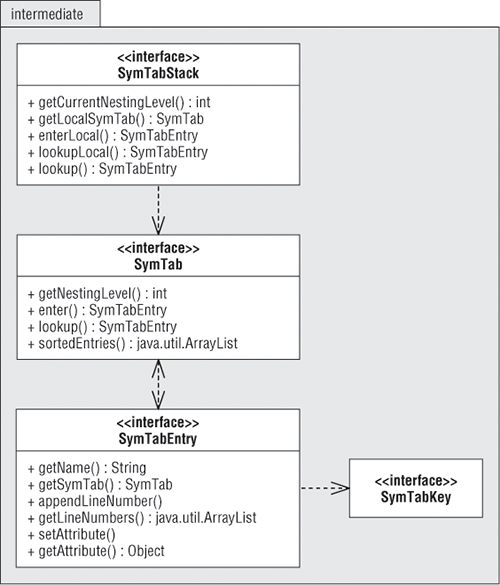
尽管目前栈中只有一个(符号)表,你也能引入符号表的一些关键操作:
* 在局部符号表中建立一个新的表项,当前的表在栈顶。
* 通过搜索局部符号表查找某个表项。
* 在栈中的所有表中查找某个表项。
一旦某个符号表项被找到,你就能更新它的内容。注意你只能在局部表中建立新表项。然后你能在局部表或栈中的所有表中查找某表项。
接口SymTabStack支持上面的这些操作。方法enterLocal在局部表中建立一个新项。方法lookupLocal搜索局部表,还有方法lookup搜索栈中所有表。接口SymTabStack定义了另两个方法:getCurrentNestingLevel()返回当前的嵌套层级及getLocalSymTab()返回栈顶的局部符号表。直到第9章才涉及到嵌套(多个符号表,目前只有一个)。
接口SymTabEntry 表示一个符号表项。方法getName()获取项的名称,方法setAttributes和getAttributes分别设置和返回表项的属性信息。为支持交叉引用,方法appendLineNumber() 在每次表项名称出现时,存储对应的源代码行位置。方法getLineNumbers()返回表项所有的行位置信息。每个表项保留一个指向包含它的符号表的引用,方法getSymTab返回这个引用。
根据图4-2中的UML类图很自然的创建这些Java接口(为毛不用代码生成,还要手写??)。清单4-1 展示了SymTabStack接口。
点击图片放大看
清单4-1:SymTabStack接口 详细参见本章源代码,这里不再显示。
第二章有SymTab接口的早期版本。清单4-2 展示了一个内容更丰富的版本。详细参见本章源代码,这里不再显示。
清单4-3 展示了SymTabEntry接口。详细参见本章源代码,这里不再显示。
最后,清单4-4 展示SymTabKey的占位接口,它用来表示表项的属性键。 详细参见本章源代码,这里不再显示。
符号表工厂
图4-3 展示了符号表实现类的UML类图,这些类都在包intermediate.symtabimpl中。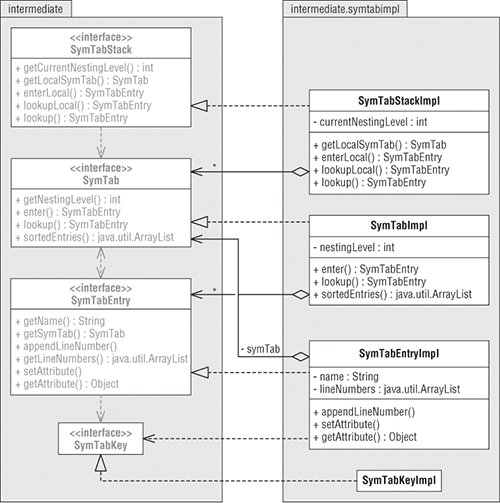
| 设计笔记 |
| 拥有权(ownership)箭号(arrow)的箭头端的星号'*'表示重数(multiplicity,多个的意思)。左边的图展示了一个SymtabStackImpl对象可拥有0或多个SymTab对象,一个SymTab对象能拥有0或多个SymTabEntry对象。 |
| 设计笔记 |
| 使用接口定义全部符号表组件使得其它组件(语法分析器等)在代码调用符号表的时候只需要关注接口,而不需要知道任何符号表的具体实现。这样的松耦合为最大程度上支持了灵活性。你可将符号表实现成你任意喜欢的那种,不管实现怎么改,只要接口不变,其它组件的调用也就不需要改。换句话说,所有调用者仅需要明白概念级别上的符号表即可。(而不需要关心实现上的符号表) |
因为一个编译器/解释器仅有单个符号表栈,你能通过一个静态域指向它。清单展示了框架类Parser中的静态域symTabStack。
清单4-6 Parser类的静态域(符号表栈)
public class SymTabEntryImpl
extends HashMap<SymTabKey, Object>
implements SymTabEntry
{private String name; // 名称
private SymTab symTab; // 所在表
private ArrayList<Integer> lineNumbers;// 所有出现的行位置
public SymTabEntryImpl(String name, SymTab symTab)
{this.name = name;
this.symTab = symTab;
this.lineNumbers = new ArrayList<Integer>();
}
public void appendLineNumber(int lineNumber)
{lineNumbers.add(lineNumber);
}
public void setAttribute(SymTabKey key, Object value)
{put(key, value);
}
public Object getAttribute(SymTabKey key)
{return get(key);
}
}[/code]
方法setAttribute()和getAttribute分别调用了父哈希表的put()和get()方法。
| 设计笔记 |
| 就每项你能存储什么这点来说,使用hashmap实现符号表项的设计提供了最大的灵活性。 |
到此完成了本章的第一个目标,即建立一个灵活的,语言无关的符号表。符号表的灵活性体现在调用者只需关注它的接口,因而容许后续实现的改进。符号表项能存储任意信息,并没有Pascal特定限制。
程序4:Pascal交叉引用 I
你即将验证新创建的符号表。你可通过生成Pascal源程序中的标识符(ID)交叉引用列表来完成这个目标(即本章的第二个目标)。清单4-11 展示了用类似下面的命令行产生的输出样例。java -classpath classes Pascal compile -x newton.pas
-x选项用来生成交叉引用列表。
清单4-11:一个生成的交叉引用清单。
public void parse() throws Exception{Token token;
long startTime = System.currentTimeMillis();
try{ while (!((token = nextToken()) instanceof EofToken)){TokenType tokenType = token.getType();
if (tokenType == PascalTokenType.IDENTIFIER){String entry_name = token.getText().toLowerCase();
//是否出现过
SymTabEntry entry_existed = symTabStack.lookup(entry_name);
if (null == entry_existed){//第一次出现?
entry_existed = symTabStack.enterLocal(entry_name);
}
entry_existed.appendLineNumber(token.getLineNumber());
}else if (tokenType==PascalTokenType.ERROR){// 留意当token有问题是,它的值表示其错误编码
errorHandler.flag(token,
(PascalErrorCode) token.getValue(), this);
}else{//其它暂且忽略
}
}
// 发送编译摘要信息
float elapsedTime = (System.currentTimeMillis() - startTime) / 1000f;
sendMessage(new Message(PARSER_SUMMARY, new Number[]{token.getLineNumber(), getErrorCount(), elapsedTime}));
} catch (IOException e){errorHandler.abortTranslation(PascalErrorCode.IO_ERROR, this);
}
}[/code]上面代码中的第8到23行为修改的部分。parse()方法遍历源程序中所有token,如果token的类型为IDENTIFIER,它尝试在局部(local)符号表中查找这个标识符,假如没找到,此方法在局部表中为此标识符建一个新的项。接着方法调用entry_existed.appendLineNumber()添加当前token所在行位置。记住因为Pascal不分大小写,须调用String的方法toLowerCase()将标识符的名字变成小写存入。
String name = token.getText().toLowerCase();
清单4-13 展示了util包中的新辅助类CrossReferencer。详细参见本章源代码,这里不再显示。
方法printSymTab()遍历符号表的有序表项。对每个项,它先打印出标识符的名字,接着是所有行位置的明细。
在第9章,在学过怎么解析Pascal声明(declarations)后,你将会写一个更NB的CrosssReferencer版本。
为支持打印交叉引用表,须在Pascal主程序的构造函数中做些小改动。
首先将源程序的行输出注释掉,因为没啥意义。详见源程序中的第49行。
//source.addMessageListener(new SourceMessageListener());
然后添加一个域stack指向程序运行过程中的符号表堆栈:
private SymTabStack stack;
接着在Pascal构造函数中的62行处,增加打印交叉引用语句,详见下面的粗体部分。
[code]// 生成中间码和符号表
iCode = parser.getICode();
//symTab = parser.getSymTab();
stack = parser.getSymTabStack();
if(xref){
CrossReferencer cr = new CrossReferencer();
cr.print(stack);
}
// 交由后端处理
backend.process(iCode, stack);
注意这儿有个较大的变化就是前面章节中的symTab域将会被stack取代(作者刚开始为简单没有引入符号表堆栈,只有个符号表占位,现在加进了,所有有好几api要改)。构造函数现在从parser中取符号表栈,而不是符号表。你需要修改Backend抽象类的process方法,将第二个参数的类型由SymTab改成SymTabStack。因为抽象process是个抽象函数,你还必须改它的两个继承类的实现:compiler和executor。
如果 "-x"命令行参数存在,则构造函数创建一个新的CrossReferencer对象,然后调用它的print方法生成一个交叉引用列表。

相关文章推荐
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第一部分(连载)
- (基于Java)编写编译器和解释器-第6章:解释执行表达式和赋值语句(连载)
- (基于Java)编写编译器和解释器-第5章:解析表达式和赋值语句-第二部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第二部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第三部分(连载)
- (基于Java)编写编译器和解释器-第8A章:基于Antlr解析&解释执行Pascal控制语句(连载)
- (基于Java)编写编译器和解释器-第1章:介绍(连载)
- (基于Java)编写编译器和解释器-第9章:解析声明-第二部分(连载)
- (基于Java)编写编译器和解释器-第3章:扫描-第一部分(连载)
- (基于Java)编写编译器和解释器-第3章:扫描-第二部分(连载)
- (基于Java)编写编译器和解释器-第5A章:基于Antlr解析表达式和赋值语句及计算(连载)
- (基于Java)编写编译器和解释器-第7章:解析(Parsing)控制语句-第一部分(连载)
- (基于Java)编写编译器和解释器-第7章:解析(Parsing)控制语句-第二部分(连载)
- (基于Java)编写编译器和解释器-第5章:解析表达式和赋值语句-第一部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第二部分(连载)
- (基于Java)编写编译器和解释器-第8章:解释Pascal控制语句(连载)
- (基于Java)编写编译器和解释器-第9章:解析声明-第一部分(连载)
- (基于Java)编写编译器和解释器-第9章:解析声明-第三部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第一部分(连载)
- (基于Java)编写编译器和解释器-第3A章:基于Antlr构造词法分析器(连载)