(基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第三部分(连载)
2012-07-14 21:24
609 查看
续 第二部分
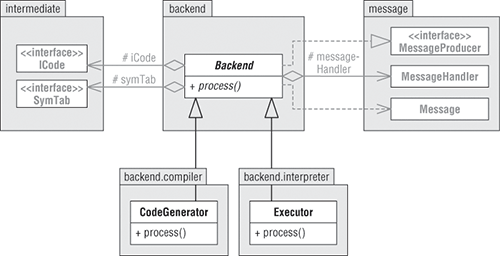
图2-7 子类CodeGenerator和Executor分别是后端的编译器和解析器实现。

编译器约定摘要格式为:
instructionCount:指令生成条数。
elapsedTime:代码生成耗用时间。
所有COMILER_SUMMARY消息必须遵循这种约定。
清单2-20:类CodeGenerator的初级版实现
解释器约定摘要消息格式为:
executionCount:执行语句数
runtimeErrors:运行期错误数
elapsedTime:耗费时间
所有INTERPRETER_SUMMARY消息的监听器必须遵循此种约定。
清单2-21:Executor类process()方法的初级实现
清单2-22 工厂类BackEndFactory
如果classes目录包含相应的class文件且当前目录包含Pascal源文件hello.pas,使用类似如下的命令行去编译文件。
java –classpath classes Pascal compile hello.pas
解释源文件类似如下命令行
java –classpath classes Pascal execute hello.pas
在Eclipse更简单,因为hello.pas在根目录下,直接创建两个如下的Java Application,一个编译,一个解释,非常happy。

构造函数根据源文件路径创建一个Source对象,接着根据命令行参数调用前端和后端工厂创建相应组件。构造函数调用parser的parse()方法解析源文件,得到生成的中间码和符号表并将它们传给后端的process方法。
注意构造函数调用前端工厂为Pascal源语言创建top-down解析器但不依赖具体源语言或使用的解析器类型。源语言和解析器(parser)类型已传给命令行。同样地,Pascal类也不需要知道到底后端工厂创建的是编译器还是解释器(因为是公共的Backend抽象类)。
三个内部类分别是parser,Source和Backend的监听器。类SourceMessageListener,ParserMessageListener和BackendMessageListener分别遵循source,Parser以及Backend的消息格式约定。它们使用格式串SOURCE_LINE_FORMAT,PARSER_SUMMARY_FORMAT,INTERPRETER_SUMMARY_FORMAT以及COMPILER_SUMMARY_FORMAT,正确地输入格式化后的文本给System.out。
假设文件hello.pas包含清单2-24里的Pascal程序。
清单2-24 Pascal程序hello.pas
则初级编译器将输出如清单2-25所示的内容。
初级解释器将生成如清单2-26的输出。
清单2-26: Pascal 解释器输出
初始后端实现
框架后端支持编译器和解释器。现在框架抽象类Backend有两个极简版实现,一个为编译器另一个为解释器。图2-7 展示了它们的UML类图。图2-7 子类CodeGenerator和Executor分别是后端的编译器和解析器实现。
编译器
编译器后端做代码生成。backend.compiler包中的类CodeGenerator实现框架抽象类Backend。现在它被最大简化了。清单2-20 展示了它的父类方法process的实现。方法参数引用自中间码和符号表,它产生一条消息指出生成器生成了多少条机器语言指令(目前0条,因为没有实际生成过程)以及代码生成耗用时间。它调用sendMessage()方法发送编译摘要消息。编译器约定摘要格式为:
instructionCount:指令生成条数。
elapsedTime:代码生成耗用时间。
所有COMILER_SUMMARY消息必须遵循这种约定。
清单2-20:类CodeGenerator的初级版实现
[code]/**
* <p>编译器的后端代码生成器</p>
*/
public class CodeGenerator extends Backend
{public void process(ICode iCode, SymTab symTab)
throws Exception
{long startTime = System.currentTimeMillis();
float elapsedTime = (System.currentTimeMillis() - startTime)/1000f;
int instructionCount = 0;
// 发送编译摘要消息
sendMessage(new Message(COMPILER_SUMMARY,
new Number[]{instructionCount,elapsedTime}));
}
}[/code]
解释器
解释器后端做程序执行。包backend.interpreter中的类Executor实现框架抽象类Backend。现在它也被最大简化了。清单2-21 展示了它的父类方法process的实现。它产生一条解释状态消息表明它执行了多少条语句,运行错误数(目前都是0)以及执行程序所耗费的时间。它调用sendMessage()发送消息。解释器约定摘要消息格式为:
executionCount:执行语句数
runtimeErrors:运行期错误数
elapsedTime:耗费时间
所有INTERPRETER_SUMMARY消息的监听器必须遵循此种约定。
清单2-21:Executor类process()方法的初级实现
[code]/**
* <p>解释器后端执行器</p>
*/
public class Executor extends Backend
{public void process(ICode iCode, SymTab symTab)
throws Exception
{long startTime = System.currentTimeMillis();
float elapsedTime = (System.currentTimeMillis() - startTime)/1000f;
int executionCount = 0;
int runtimeErrors = 0;
// 发送解释摘要消息
sendMessage(new Message(INTERPRETER_SUMMARY,
new Number[]{executionCount,runtimeErrors,
elapsedTime}));
}
}[/code]
后端工厂
如前端一样,后端工厂类创建合适的后端组件。清单2-22 工厂类BackEndFactory
[code]/**
* <p>产生编译器或解释器后端的工厂</p>
*/
public class BackendFactory
{/**
* 视参数产生编译器或解释器后端
* @param operation "compile"或者"execute"
* @return 后端组件
* @throws Exception if an error occurred.
*/
public static Backend createBackend(String operation)
throws Exception
{ if (operation.equalsIgnoreCase("compile")){return new CodeGenerator();
}
else if (operation.equalsIgnoreCase("execute")){return new Executor();
}
else{ throw new Exception("后端工厂: 不支持的操作 '" +operation + "'");
}
}
}[/code]
/**
*
* Pascal外壳程序,根据参数选择性的调用编译器或者解释器
*
* <p>Copyright (c) 2009 by Ronald Mak</p>
* <p>For instructional purposes only.No warranties.</p>
*/
public class Pascal
{private Parser parser;// 语言无关的 parser
private Source source;// 语言无关的 scanner
private ICode iCode;// 抽象语法树
private SymTab symTab;// 符号表
private Backend backend;// 后端
/**
* 编译或者解释源程序
* @param operation compile 或者 execute
* @param filePath 源文件路径
* @param flags 命令行参数标记
*/
public Pascal(String operation, String filePath, String flags)
{ try{//显示中间码结构
boolean intermediate = flags.indexOf('i') > -1;//显示符号引用
boolean xref = flags.indexOf('x') > -1;source = new Source(new BufferedReader(new FileReader(filePath)));
source.addMessageListener(new SourceMessageListener());
//top-down是Parser的一种,还有一种本书没有实现的bottom-up。
parser = FrontendFactory.createParser("Pascal", "top-down", source);parser.addMessageListener(new ParserMessageListener());
backend = BackendFactory.createBackend(operation);
backend.addMessageListener(new BackendMessageListener());
parser.parse();
source.close();
//生成中间码和符号表
iCode = parser.getICode();
symTab = parser.getSymTab();
//交由后端处理
backend.process(iCode, symTab);
}
catch (Exception ex){ System.out.println("***** 翻译器出现错误 *****");ex.printStackTrace();
}
}
private static final String FLAGS = "[-ix]";
private static final String USAGE =
"使用方式: Pascal execute|compile " + FLAGS + " <源文件路径>";
/**
* 入口程序,参考Pascal构造函数的参数接受过程。<br>
* 例如:compile -i hello.pas
*/
public static void main(String args[])
{ try{String operation = args[0];
// 翻译操作类型,compile或execute
if (!( operation.equalsIgnoreCase("compile") || operation.equalsIgnoreCase("execute"))){throw new Exception();
}
int i = 0;
String flags = "";
// 参数标识
while ((++i < args.length) && (args[i].charAt(0) == '-')){flags += args[i].substring(1);
}
// 源文件
if (i < args.length){String path = args[i];
new Pascal(operation, path, flags);
}
else{throw new Exception();
}
}
catch (Exception ex){System.out.println(USAGE);
}
}
private static final String SOURCE_LINE_FORMAT = "%03d %s";
/**
* 源(也就是源文件)的监听器,用于监听源文件的读取情况,如果注册了监听器,源每产生一条消息比如<br>
* 读取了一行等,将会调用相应的监听器处理。典型的Observe模式
*/
private class SourceMessageListener implements MessageListener
{public void messageReceived(Message message)
{MessageType type = message.getType();
Object body[] = (Object []) message.getBody();
switch (type){//源读取了一行
case SOURCE_LINE:{int lineNumber = (Integer) body[0];
String lineText = (String) body[1];
System.out.println(String.format(SOURCE_LINE_FORMAT,
lineNumber, lineText));
break;
}
}
}
}
private static final String PARSER_SUMMARY_FORMAT =
"源文件共有\t%d行。" +
"\n有\t%d个语法错误." +
"\n解析共耗费\t%.2f秒.\n";
/**
* Parser的监听器,监听来自Parser解析过程中产生的消息,还是Observe模式
*/
private class ParserMessageListener implements MessageListener
{public void messageReceived(Message message)
{MessageType type = message.getType();
switch (type){ case PARSER_SUMMARY:{Number body[] = (Number[]) message.getBody();
int statementCount = (Integer) body[0];
int syntaxErrors = (Integer) body[1];
float elapsedTime = (Float) body[2];
System.out.println("\n----------代码解析统计信--------------");System.out.printf(PARSER_SUMMARY_FORMAT,
statementCount, syntaxErrors,
elapsedTime);
break;
}
}
}
}
private static final String INTERPRETER_SUMMARY_FORMAT =
"共执行\t%d 条语句。" +
"\n运行中发生了\t%d 个错误。" +
"\n执行共耗费\t%.2f 秒。\n";
private static final String COMPILER_SUMMARY_FORMAT =
"共生成\t\t%d 条指令" +
"\n代码生成共耗费\t%.2f秒\n";
/**
* Listener for back end messages.
*/
private class BackendMessageListener implements MessageListener
{/**
* Called by the back end whenever it produces a message.
* @param message the message.
*/
public void messageReceived(Message message)
{MessageType type = message.getType();
switch (type){ case INTERPRETER_SUMMARY:{Number body[] = (Number[]) message.getBody();
int executionCount = (Integer) body[0];
int runtimeErrors = (Integer) body[1];
float elapsedTime = (Float) body[2];
System.out.println("\n----------解释统计信息------------");System.out.printf(INTERPRETER_SUMMARY_FORMAT,
executionCount, runtimeErrors,
elapsedTime);
break;
}
case COMPILER_SUMMARY:{Number body[] = (Number[]) message.getBody();
int instructionCount = (Integer) body[0];
float elapsedTime = (Float) body[1];
System.out.println("\n----------编译统计信--------------");System.out.printf(COMPILER_SUMMARY_FORMAT,
instructionCount, elapsedTime);
break;
}
}
}
}
}[/code]
如果classes目录包含相应的class文件且当前目录包含Pascal源文件hello.pas,使用类似如下的命令行去编译文件。
java –classpath classes Pascal compile hello.pas
解释源文件类似如下命令行
java –classpath classes Pascal execute hello.pas
在Eclipse更简单,因为hello.pas在根目录下,直接创建两个如下的Java Application,一个编译,一个解释,非常happy。
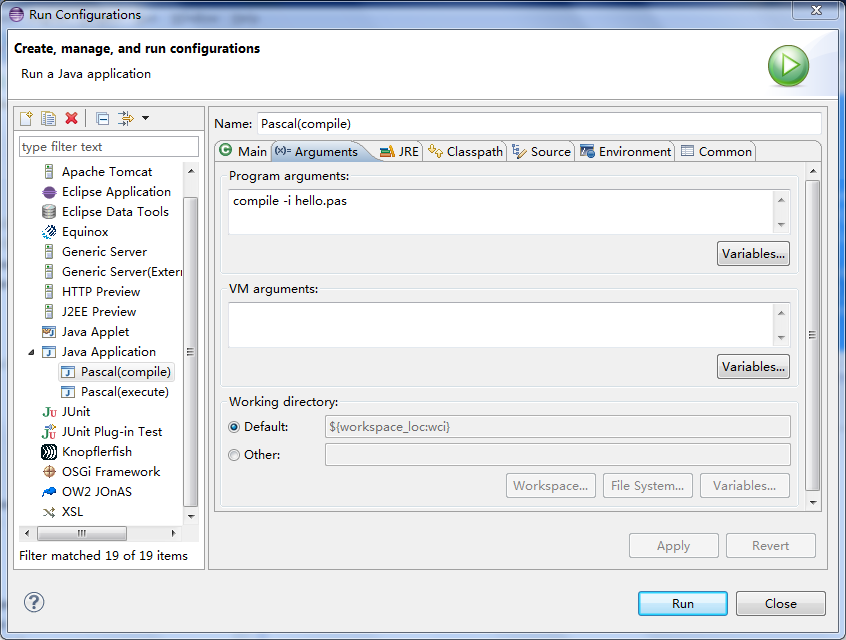
构造函数根据源文件路径创建一个Source对象,接着根据命令行参数调用前端和后端工厂创建相应组件。构造函数调用parser的parse()方法解析源文件,得到生成的中间码和符号表并将它们传给后端的process方法。
注意构造函数调用前端工厂为Pascal源语言创建top-down解析器但不依赖具体源语言或使用的解析器类型。源语言和解析器(parser)类型已传给命令行。同样地,Pascal类也不需要知道到底后端工厂创建的是编译器还是解释器(因为是公共的Backend抽象类)。
三个内部类分别是parser,Source和Backend的监听器。类SourceMessageListener,ParserMessageListener和BackendMessageListener分别遵循source,Parser以及Backend的消息格式约定。它们使用格式串SOURCE_LINE_FORMAT,PARSER_SUMMARY_FORMAT,INTERPRETER_SUMMARY_FORMAT以及COMPILER_SUMMARY_FORMAT,正确地输入格式化后的文本给System.out。
假设文件hello.pas包含清单2-24里的Pascal程序。
清单2-24 Pascal程序hello.pas
PROGRAM hello (output);
{Write 'Hello, world.' ten times.}
VAR
i : integer;
BEGIN{hello}
FOR i := 1 TO 10 DO BEGIN
writeln('Hello, world.');
END;
END{hello}.
则初级编译器将输出如清单2-25所示的内容。
001 PROGRAM hello (output);
002
003{Write 'Hello, world.' ten times.}
004
005 VAR
006 i : integer;
007
008 BEGIN{hello}
009 FOR i := 1 TO 10 DO BEGIN
010 writeln('Hello, world.');
011 END;
012 END{hello}.
----------代码解析统计信--------------
源文件共有12行。
有0个语法错误.
解析共耗费0.03秒.
----------编译统计信--------------
共生成0 条指令
代码生成共耗费0.00秒
| 设计笔记 |
| 本章有很多烦人事是确保框架是源语言无关且能支持任何编译器或解释器。即使Pascal类相当不可知你也将Pascal相关组件加到前端以及编译或解释相关组件加到后端。 软件工程的一个主要挑战是管理变更。你能更改源语言,解析类型,或要一个编译器还是一个解释器。因为框架被设计成可伸缩,它将是可靠的,并不需要什么改动。而你仅需要实现子类时做些改动。 如果说你想要一个bottom-up而不是top-down解析器(parser,也称语法分析器,以后都称为解析器),那么使用同样的前端ParserScanner类,增加一个新的Parser实现如PascalParserBU。或者更改源语言为Java,实现一个Parser子类JavaParserTD,不过这个子类需要一个新的Scanner比如JavaScanner。 因此为管理变更,应用此条软件工程法则,那就是封装多变的代码使其与不变的代码隔离开来。在前端,Parser和Scanner可能有变化,则把它们封装在子类实现中。后端的编译器和解释器同样是子类。变化的子类与不变的框架类隔离开来。 因为我们所有的解析器,其中PascalParserTD是一个例子,它继承自Parser基类,所有解析器组成一个可互换的类族。其它类族有Scanner的子类(比如PascalScanner,Token子类(比如EofToken)以及Backend子类(比如CodeGenerator和Executor)。在每个类族中,你能增加和交换族成员而不需修改框架代码。 策略模式(Strategy Design Pattern)详细说明了此等类族的用法。早点实现这种设计模式去管理变更会让你在接下来章节的进一步开发中获益更多。 |
清单2-26: Pascal 解释器输出
001 PROGRAM hello (output);这些端对端测试运行满足本章的第四和最后一个目标。[/code]
002
003{Write 'Hello, world.' ten times.}
004
005 VAR
006 i : integer;
007
008 BEGIN{hello}
009 FOR i := 1 TO 10 DO BEGIN
010 writeln('Hello, world.');
011 END;
012 END{hello}.
----------代码解析统计信--------------
源文件共有12行。
有0个语法错误.
解析共耗费0.03秒.
----------解释统计信息------------
共执行0 条语句。
运行中发生了0 个错误。
执行共耗费0.00 秒。

相关文章推荐
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第三部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第二部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第二部分(连载)
- (基于Java)编写编译器和解释器-第9章:解析声明-第三部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第一部分(连载)
- (基于Java)编写编译器和解释器-第2章:框架I:编译器和解释器-第一部分(连载)
- (基于Java)编写编译器和解释器-第9章:解析声明-第二部分(连载)
- (基于Java)编写编译器和解释器-第7章:解析(Parsing)控制语句-第二部分(连载)
- (基于Java)编写编译器和解释器-第3章:扫描-第二部分(连载)
- (基于Java)编写编译器和解释器-第5章:解析表达式和赋值语句-第二部分(连载)
- (基于Java)编写编译器和解释器-第10章:类型检查-第二部分
- (基于Java)编写编译器和解释器-第5A章:基于Antlr解析表达式和赋值语句及计算(连载)
- (基于Java)编写编译器和解释器-第3章:扫描-第一部分(连载)
- (基于Java)编写编译器和解释器-第11章:解析程序、过程和函数-第一部分
- (基于Java)编写编译器和解释器-简介(连载)
- (基于Java)编写编译器和解释器-第8章:解释Pascal控制语句(连载)
- (基于Java)编写编译器和解释器-第3A章:基于Antlr构造词法分析器(连载)
- (基于Java)编写编译器和解释器-第9章:解析声明-第一部分(连载)
- (基于Java)编写编译器和解释器-第5章:解析表达式和赋值语句-第一部分(连载)
- (基于Java)编写编译器和解释器-第1章:介绍(连载)