提高软件质量的设计 职责驱动设计 (转载)
2012-05-29 15:44
232 查看
随着软件业的不断发展,随着软件需求的不断扩大,软件所管理的范围也在不断拓宽。过去一个软件仅仅管理一台电脑的一个小小的功能,而现在被扩展到了一个企业、一个行业、一个产业链。过去我们开发一套软件,只有少量的二次开发,当它使用到一定时候我们就抛弃掉重新又开发一套。现在,随着用户对软件依赖程度的不断加大,我们很难说抛弃一套软件重新开发了,更多的是在一套软件中持续改进,使这套软件的生命周期持续数年以及数个版本。正是因为软件业面临着如此巨大的压力,我们的代码质量,我们开发的软件拥有的可变更性和持续改进的能力,成为软件制胜的关键因素,令我们不能不反思。
代码质量评价的关键指标:低耦合,高内聚
耦合就是对某元素与其它元素之间的连接、感知和依赖的量度。耦合包括:
1.元素B是元素A的属性,或者元素A引用了元素B的实例(这包括元素A调用的某个方法,其参数中包含元素B)。
2.元素A调用了元素B的方法。
3.元素A直接或间接成为元素B的子类。
4.元素A是接口B的实现。
如果一个元素过于依赖其它元素,一旦它所依赖的元素不存在,或者发生变更,则该元素将不能再正常运行,或者不得不相应地进行变更。因此,耦合将大大影响代码的通用性和可变更性。
内聚,更为专业的说法叫功能内聚,是对软件系统中元素职责相关性和集中度的度量。如果元素具有高度相关的职责,除了这些职责内的任务,没有其它过多的工作,那么该元素就具有高内聚性,反之则为低内聚性。内聚就像一个专横的管理者,它只做自己职责范围内的事,而将其它与它相关的事情,分配给别人去做。
高质量的代码要求我们的代码保持低耦合、高内聚。但是,这个要求是如此的抽象与模糊,如何才能做到这些呢?软件大师们告诉我们了许多方法,其中之一就是Craig Larman的职责驱动设计。
职责驱动设计(Responsibility Drive Design,RDD)是Craig Larman在他的经典著作《UML和模式应用》中提出的。要理解职责驱动设计,我们首先要理解“低表示差异”。
低表示差异
我们开发的应用软件实际上是对现实世界的模拟,因此,软件世界与现实世界存在着必然的联系。当我们在进行需求分析的时候,需求分析员实际上是从客户那里在了解现实世界事物的规则、工作的流程。如果我们在软件分析和设计的过程中,将软件世界与现实世界紧密地联系到一起,我们的软件将更加本色地还原事物最本质的规律。这样的设计,就称之为“低表示差异”。
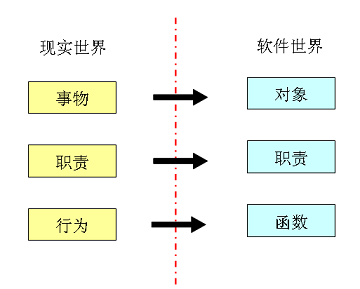
采用“低表示差异”进行软件设计,现实世界有什么事物,就映射为软件世界的各种对象(类);现实世界的事物拥有什么样的职责,在软件世界里的对象就拥有什么样的职责;在现实世界中的事物,因为它的职责而产生的行为,在软件世界中就反映为对象所拥有的函数。
低表示差异,使分析设计者对软件的分析和设计更加简单,思路更加清晰;使代码更加可读,阅读者更加易于理解;更重要的是,当需求发生变更,或者业务产生扩展时,设计者只需要遵循事物本来的面貌去思考和修改软件,使软件更加易于变更和扩展。
角色、职责、协作
理解了“低表示差异”,现在我们来看看我们应当如何运用职责驱动设计进行分析和设计。首先,我们通过与客户的沟通和对业务需求的了解,从中提取出现实世界中的关键事物以及相互之间的关系。这个过程我们通常通过建立领域模型来完成。领域模型建立起来以后,通过诸如Rational Rose这样的设计软件的正向工程,生成了我们在软件系统中最初始的软件类。这些软件类,由于每个都扮演着现实世界中的一个具体的角色,因而赋予了各自的职责。前面我已经提到,如果你的系统采用职责驱动设计的思想进行设计开发,作为一个好的习惯,你应当在每一个软件类的注释首行,清楚地描述该软件类的职责。
当我们完成了系统中软件类的制订,分配好了各自的职责,我们就应该开始根据软件需求,编写各个软件类的功能。在前面我给大家提出了一个建议,就是不要在一个函数中编写大段的代码。编写大段的代码,通常会降低代码的内聚度,因为这些代码中将包含不是该软件类应当完成的工作。作为一个有经验的开发人员,在编写一个功能时,首先应当对功能进行分解。一段稍微复杂的功能,通常都可以被分解成一个个相对独立的步骤。步骤与步骤之间存在着交互,那就是数据的输入输出。通过以上的分解,每一个步骤将形成一个独立的函数,并且使用一个可以表明这个步骤意图的释义函数名。接下来,我们应当考虑的,就是应当将这些函数交给谁。它们有可能交给原软件类,也有可能交给其它软件类,其分配的原则是什么呢?答案是否清楚,那就是职责。每个软件类代表现实世界的一个事物,或者说一个角色。在现实世界中这个任务应当由谁来完成,那么在软件世界中,这个函数就应当分配给相应的那个软件类。
通过以上步骤的分解,一个功能就分配给了多个软件类,相互协作地完成这个功能。这样的分析和设计,其代码一定是高内聚的和高可读性的。同时,当需求发生变更的时候,设计者通过对现实世界的理解,可以非常轻松地找到那个需要修改的软件类,而不会影响其它类,因而也就变得易维护、易变更和低耦合了。
说了这么多,举一个实例也许更能帮助理解。拿一个员工工资系统来说吧。当人力资源在发放一个月工资的时候,以及离职的员工肯定不能再发放工资了。在系统设计的期初,开发人员商量好,在员工信息中设定一个“离职标志”字段。编写工资发放的开发人员通过查询,将“离职标志”为false的员工查询出来,并为他们计算和发放工资。但是,随着这个系统的不断使用,编写员工管理的开发人员发现,“离职标志”字段已经不能满足客户的需求,因而将“离职标志”字段废弃,并增加了一个“离职时间”字段来管理离职的员工。然而,编写工资发放的开发人员并不知道这样的变更,依然使用着“离职标志”字段。显然,这样的结果就是,软件系统开始对离职员工发放工资了。仔细分析这个问题的原因,我们不难发现,确认员工是否离职,并不是“发放工资”软件类应当完成的工作,而应当是“员工管理”软件类应当完成的。如果将“获取非离职员工”的任务交给“员工管理”软件类,而“发放工资”软件类仅仅只是去调用,那么离职功能由“离职标志”字段改为了“离职时间”字段,其实就与“发放工资”软件类毫无关系。而作为“员工管理”的开发人员,一旦发生这样的变更,他当然知道去修改自己相应的“获取非离职员工”函数,这样就不会发生以上问题。通过这样一个实例,也许你能够理解“职责驱动设计”的精要与作用了吧。
职责分配与信息专家
通过以上对职责驱动设计的讲述,我们不难发现,职责驱动设计的精要就是职责分配。但是,在纷繁复杂的软件设计中,如何进行职责分配常常令我们迷惑。幸运的是,Larman大师清楚地认识到了这一点。在他的著作中,信息专家模式为我们提供了帮助。
信息专家模式(又称为专家模式)告诉我们,在分析设计中,应当将职责分配给软件系统中的这样一个软件类,它拥有实现这个职责所必须的信息。我们称这个软件类,叫“信息专家”。用更加简短的话说,就是将职责分配给信息专家。
为什么我们要将职责分配给信息专家呢?我们用上面的例子来说明吧。当“发放工资”软件类需要获取非离职员工时,“员工管理”软件类就是“获取非离职员工”任务的信息专家,因为它掌握着所有员工的信息。假设我们不将“获取非离职员工”的任务交给“员工管理”软件类,而是另一个软件类X,那么,为了获取员工信息,软件类X不得不访问“员工管理”软件类,从而使“发放工资”与X耦合,X又与“员工管理”耦合。这样的设计,不如直接将“获取非离职员工”的任务交给“员工管理”软件类,使得“发放工资”仅仅与“员工管理”耦合,从而有效地降低了系统的整体耦合度。
总之,采用“职责驱动设计”的思路,为我们提高软件开发质量、可读性、可维护性,以及保持软件的持续发展,提供了一个广阔的空间。
代码质量评价的关键指标:低耦合,高内聚
耦合就是对某元素与其它元素之间的连接、感知和依赖的量度。耦合包括:
1.元素B是元素A的属性,或者元素A引用了元素B的实例(这包括元素A调用的某个方法,其参数中包含元素B)。
2.元素A调用了元素B的方法。
3.元素A直接或间接成为元素B的子类。
4.元素A是接口B的实现。
如果一个元素过于依赖其它元素,一旦它所依赖的元素不存在,或者发生变更,则该元素将不能再正常运行,或者不得不相应地进行变更。因此,耦合将大大影响代码的通用性和可变更性。
内聚,更为专业的说法叫功能内聚,是对软件系统中元素职责相关性和集中度的度量。如果元素具有高度相关的职责,除了这些职责内的任务,没有其它过多的工作,那么该元素就具有高内聚性,反之则为低内聚性。内聚就像一个专横的管理者,它只做自己职责范围内的事,而将其它与它相关的事情,分配给别人去做。
高质量的代码要求我们的代码保持低耦合、高内聚。但是,这个要求是如此的抽象与模糊,如何才能做到这些呢?软件大师们告诉我们了许多方法,其中之一就是Craig Larman的职责驱动设计。
职责驱动设计(Responsibility Drive Design,RDD)是Craig Larman在他的经典著作《UML和模式应用》中提出的。要理解职责驱动设计,我们首先要理解“低表示差异”。
低表示差异
我们开发的应用软件实际上是对现实世界的模拟,因此,软件世界与现实世界存在着必然的联系。当我们在进行需求分析的时候,需求分析员实际上是从客户那里在了解现实世界事物的规则、工作的流程。如果我们在软件分析和设计的过程中,将软件世界与现实世界紧密地联系到一起,我们的软件将更加本色地还原事物最本质的规律。这样的设计,就称之为“低表示差异”。
采用“低表示差异”进行软件设计,现实世界有什么事物,就映射为软件世界的各种对象(类);现实世界的事物拥有什么样的职责,在软件世界里的对象就拥有什么样的职责;在现实世界中的事物,因为它的职责而产生的行为,在软件世界中就反映为对象所拥有的函数。
低表示差异,使分析设计者对软件的分析和设计更加简单,思路更加清晰;使代码更加可读,阅读者更加易于理解;更重要的是,当需求发生变更,或者业务产生扩展时,设计者只需要遵循事物本来的面貌去思考和修改软件,使软件更加易于变更和扩展。
角色、职责、协作
理解了“低表示差异”,现在我们来看看我们应当如何运用职责驱动设计进行分析和设计。首先,我们通过与客户的沟通和对业务需求的了解,从中提取出现实世界中的关键事物以及相互之间的关系。这个过程我们通常通过建立领域模型来完成。领域模型建立起来以后,通过诸如Rational Rose这样的设计软件的正向工程,生成了我们在软件系统中最初始的软件类。这些软件类,由于每个都扮演着现实世界中的一个具体的角色,因而赋予了各自的职责。前面我已经提到,如果你的系统采用职责驱动设计的思想进行设计开发,作为一个好的习惯,你应当在每一个软件类的注释首行,清楚地描述该软件类的职责。
当我们完成了系统中软件类的制订,分配好了各自的职责,我们就应该开始根据软件需求,编写各个软件类的功能。在前面我给大家提出了一个建议,就是不要在一个函数中编写大段的代码。编写大段的代码,通常会降低代码的内聚度,因为这些代码中将包含不是该软件类应当完成的工作。作为一个有经验的开发人员,在编写一个功能时,首先应当对功能进行分解。一段稍微复杂的功能,通常都可以被分解成一个个相对独立的步骤。步骤与步骤之间存在着交互,那就是数据的输入输出。通过以上的分解,每一个步骤将形成一个独立的函数,并且使用一个可以表明这个步骤意图的释义函数名。接下来,我们应当考虑的,就是应当将这些函数交给谁。它们有可能交给原软件类,也有可能交给其它软件类,其分配的原则是什么呢?答案是否清楚,那就是职责。每个软件类代表现实世界的一个事物,或者说一个角色。在现实世界中这个任务应当由谁来完成,那么在软件世界中,这个函数就应当分配给相应的那个软件类。
通过以上步骤的分解,一个功能就分配给了多个软件类,相互协作地完成这个功能。这样的分析和设计,其代码一定是高内聚的和高可读性的。同时,当需求发生变更的时候,设计者通过对现实世界的理解,可以非常轻松地找到那个需要修改的软件类,而不会影响其它类,因而也就变得易维护、易变更和低耦合了。
说了这么多,举一个实例也许更能帮助理解。拿一个员工工资系统来说吧。当人力资源在发放一个月工资的时候,以及离职的员工肯定不能再发放工资了。在系统设计的期初,开发人员商量好,在员工信息中设定一个“离职标志”字段。编写工资发放的开发人员通过查询,将“离职标志”为false的员工查询出来,并为他们计算和发放工资。但是,随着这个系统的不断使用,编写员工管理的开发人员发现,“离职标志”字段已经不能满足客户的需求,因而将“离职标志”字段废弃,并增加了一个“离职时间”字段来管理离职的员工。然而,编写工资发放的开发人员并不知道这样的变更,依然使用着“离职标志”字段。显然,这样的结果就是,软件系统开始对离职员工发放工资了。仔细分析这个问题的原因,我们不难发现,确认员工是否离职,并不是“发放工资”软件类应当完成的工作,而应当是“员工管理”软件类应当完成的。如果将“获取非离职员工”的任务交给“员工管理”软件类,而“发放工资”软件类仅仅只是去调用,那么离职功能由“离职标志”字段改为了“离职时间”字段,其实就与“发放工资”软件类毫无关系。而作为“员工管理”的开发人员,一旦发生这样的变更,他当然知道去修改自己相应的“获取非离职员工”函数,这样就不会发生以上问题。通过这样一个实例,也许你能够理解“职责驱动设计”的精要与作用了吧。
职责分配与信息专家
通过以上对职责驱动设计的讲述,我们不难发现,职责驱动设计的精要就是职责分配。但是,在纷繁复杂的软件设计中,如何进行职责分配常常令我们迷惑。幸运的是,Larman大师清楚地认识到了这一点。在他的著作中,信息专家模式为我们提供了帮助。
信息专家模式(又称为专家模式)告诉我们,在分析设计中,应当将职责分配给软件系统中的这样一个软件类,它拥有实现这个职责所必须的信息。我们称这个软件类,叫“信息专家”。用更加简短的话说,就是将职责分配给信息专家。
为什么我们要将职责分配给信息专家呢?我们用上面的例子来说明吧。当“发放工资”软件类需要获取非离职员工时,“员工管理”软件类就是“获取非离职员工”任务的信息专家,因为它掌握着所有员工的信息。假设我们不将“获取非离职员工”的任务交给“员工管理”软件类,而是另一个软件类X,那么,为了获取员工信息,软件类X不得不访问“员工管理”软件类,从而使“发放工资”与X耦合,X又与“员工管理”耦合。这样的设计,不如直接将“获取非离职员工”的任务交给“员工管理”软件类,使得“发放工资”仅仅与“员工管理”耦合,从而有效地降低了系统的整体耦合度。
总之,采用“职责驱动设计”的思路,为我们提高软件开发质量、可读性、可维护性,以及保持软件的持续发展,提供了一个广阔的空间。

相关文章推荐
- 浅谈如何提高软件项目产品的质量(转载)
- 主题:一堂如何提高代码质量的培训课 之 领域驱动设计
- 转载: 提高软件质量实践――google 篇
- 软件架构设计--质量驱动
- 转载:提高PHP代码质量36计
- 如何利用缺陷的管理提高软件开发质量五——缺陷预测
- 【草根总结】软件质量可以得到明显提高的10个环节
- 领域驱动设计和开发实战(转载)
- 如何做好软件系统设计阶段质量保障
- [转载]如果你是12306网站架构师,你会如何设计网站的软件架构和硬件系统架构?
- 问题驱动的软件测试设计:架构与过程
- 提高代码质量:如何编写函数 --转载
- 结合领域驱动设计的SOA分布式软件架构
- 如何开发高质量的软件 - 通过测试集中型的软件开发方法来提高软件质量
- 怎样设计好自己的加密软件(转载)
- [转载]FindBugs,第 1 部分: 提高代码质量
- 结合领域驱动设计的SOA分布式软件架构
- 如何利用缺陷的管理提高软件开发质量三 -如何利用时间点发现缺陷数
- “轻”方法与满意质量——市场驱动的软件工程实践
- 软件开发周期----如何提高软件开发质量----论团队管理的非技术性因素(part 2)