《大话数据结构》--学习笔记8 ***重点***
2012-05-14 21:34
656 查看
3.6.4 线性表链式存储结构代码描述
单链表中,我们在C语言中可用结构指针来描述/*线性表的单链表存储结构*/
typedef struct Node
{
ElemType data;
struct Node *next;
}Node;
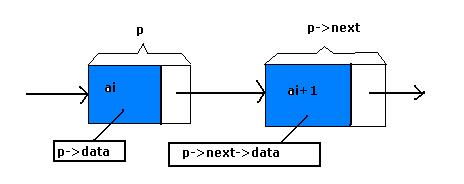
typedef struct Node * LinkList; /*定义LinkList*/从这个结构中我们也就直道,结点由存放数据元素的数据域存放后续结点地址的指针域组成。假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data 来表示,p->data的值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next表示一个指针。p->next指向谁呢?指向下一个i+1个元素,即指向ai+1的指针。也就是说,如果p->data=ai,那么p->next->data=ai+1,如图:
3.7 单链表的读取
在单链表中,由于第i个元素到底在哪?没办法一开始就知道,必须得从头开始找。因此,对于单链表实现获取第i个元素的数据的操作GetElem,在算法上,相对要麻烦些.获取第i个元素的数据的操作GetElem 函数的实现代码如下:
/*初始条件:顺序线性表L已存在,1<=i<=ListLength(L)*/
/*操作结果:用e返回L中第i个数据元素的值*/
Status GetElem(SqList L,int i, ElemType *e)
{
int j;
LinkList p; /*声明一结点p*/
p=L->next; /*让p指向链表L的第一个结点*/
j=1; //j为计数器
while (p&&j<i) /*p不为空或者计数器j还没等于i时,循环继续*/
{
p=p->next;
++j;
}
if ( !p || j>i ) /*p为空 或 j>i的出错情况*/
return ERROR;
*e = p->data; //第i个结点时,第i个数据元素值返回给e
return OK;
}在线性表的顺序存储结构中,我们要计算任意一个元素的存储位置是很容易的。说白了,就是从头开始找,直到第i个元素为止。由于这个算法的时间复杂度取决于i的位置,当i=1时,则不需要遍历,第一个就取出数据了。而当i=n时,遍历n-1次才可以,因此最坏的情况的时间复杂度是O(n)
由于单链表的结构中没有定义表长,所以不能事先知道要循环多少次,因此也就不方便使用for来控制循环。其主要核心思想就是“工作指针后移”。
这其实也是很多算法的常用技术。
此时,有人说,这么麻烦,这数据结构有什么意思?还不如顺序结构呢?
哈,世间万物总是两面的,有好自然有不足,有差自然有优。下面我们来看一下在链表中如何实现“插入”和“删除”。
3.8 单链表的插入与删除
3.8.1 单链表的插入
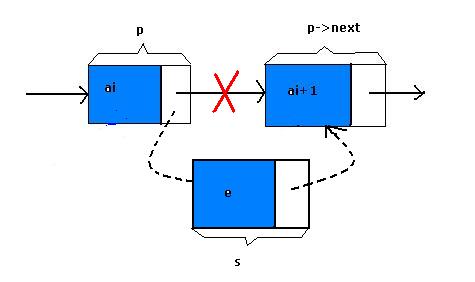
先来看单链表的插入。假设存储元素e的结点为s,要实现结点p、p->next、s之间的逻辑关系变化,只需将结点s插入到结点p和p->next 之间即可。可如何插入呢?根本不用惊动其他结点,只要让s->next 和p->next的指针做一点改变即可。s->next=p->next; p->next=s;
解读这两句代码,即让p的后续结点改成s的后续结点,再把结点s变成p的后续结点如图:
思考一下,这两句的顺序可以交换吗?
如果先p->next=s;再s->next=p->next;会怎么样?我们来看一下照这两句这样的顺的话,如图:
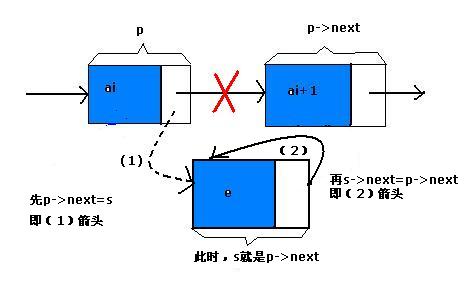
看明白了吗?如果先p->next=s;再s->next=p->next;因为第一句使得p->next覆盖成了s的地址,那么s->next=p->next 其实就是s->next=s啦!这样真正插入的s没有了下一级,这样的插入操作就失败了。掉链子了...
所以这两句话,无论如何是不能反的!
对于单链表的表头和表尾的特殊情况,操作是相同的。
单链表第i个数据插入结点的算法思路:
1.声明一结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,在系统中生成一个空结点s;
5.将数据元素e赋值给s->data;
6.单链表的插入标准语句s->next=p->next; p->next=s;
7.返回成功;
实现单链表插入代码算法如下:
Status ListInsert ( LinkList *L,int i, ElemType e)
{
int j;
LinkList p , s; /*声明一结点p,s*/
p=*L ; /*让p指向链表L的第一个结点*/
j=1; //j为计数器
while (p&&j<i) /*p不为空或者计数器j还没等于i时,循环继续*/
{
p=p->next;
++j;
}
if ( !p || j>i ) /*p为空 或 j>i的出错情况*/
return ERROR; //即第i个元素不存在
s = (LinkList) malloc(sizeof(Node)); /*生成新节点(C标准函数)*/
s->data =e;
s->next = p->next; //将p的后续结点赋给s的后续
p->next = s; //将s赋值给p的后续
return OK;
}这里,我们用到了C语言的malloc标准函数,它的作用就是生成一个新的结点,其类型与Node是一样的,其实就是内存中找一个小块空地,准备用来存放e数据的s结点。
3.8.2单链表的删除
现在我们来看单链表的删除。设存储元素ai的结点为q,要实现将结点q删除单链表的操作,其实就是将它的前续结点的指针绕过,指向它的后续结点。 如图: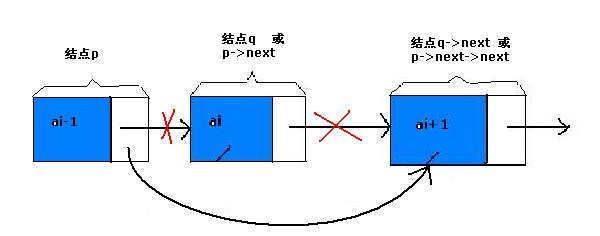
我们实际要做的就一步:p->next=p->next->next; 【q用来取代p->next】
代码即:q=p->next ; p->next=q->next;
单链表第i个数据删除结点的算法:
1.声明一结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,将欲删除的结点p->next 赋值给q;
5.单链表的删除标准语句p->next=q->next;
6.将q结点中的数据赋值给e,作为返回;
7.释放q结点;
8.返回成功。
实现单链表删除的代码算法如下:
Status ListDelete ( LinkList *L,int i, ElemType *e)
{
int j;
LinkList p , q; /*声明一结点p,s*/
p=*L ; /*让p指向链表L的第一个结点*/
j=1; //j为计数器
while (p->next&&j<i) /*p不为空或者计数器j还没等于i时,循环继续*/
{
p=p->next;
++j;
}
if ( !p->next || j>i ) /*p为空 或 j>i的出错情况*/
return ERROR; //即第i个元素不存在
q = p->next ; //将s赋值给p的后续
p->next=q->next; //将q的后续赋值给p的后续
*e =q->next;
free(q); //让系统回收此节点,释放内存
return OK;
}总之,对于插入或删除数据越频繁的操作,单链表的效率优势越明显。
分析一下刚才我们讲的单链表的插入和删除算法,我们发现,它们其实都是由两部分组成:第一部分就是遍历查找第i个元素;第二部分就是插入和删除元素;
从整个算法来说,我们很容易推导出:它们的时间复杂度都是O(n).如果在我们不知道第i个元素的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。但如果我们希望从第i个位置,插入10个元素,对于顺序存储结构意味着,每一次插入都需要移动n-i个元素,每次都是O(n).而单链表,我么只需要在第一次时,找到第i个位置的指针,此时为O(n),接下来只是简单的题通过赋值移动指针而已,时间复杂度都是O(1).显然,对于插入或删除数据越频繁的操作,单链表的优势越明显。

相关文章推荐
- 《大话数据结构》--学习笔记11 ***重点***
- 《大话数据结构》--学习笔记10 ***重点***
- 《大话数据结构》--学习笔记12 ***重点***
- 《大话数据结构》--学习笔记9 ***重点***
- PHP:面向对象学习笔记,重点模拟Mixin(掺入)
- jQuery学习笔记--JqGrid相关操作 方法列表 备忘 重点讲解(超重要)
- 网络营销(学习王宜的“赢在网络营销”)重点笔记01
- svg学习重点笔记
- 学习笔记【机器学习重点与实战】——1 线性回归
- C语言学习笔记(二)——流程控制【重点】
- Android(java)学习笔记194:ListView编写步骤(重点)
- 【鸟哥的linux私房菜-学习笔记】vim重点回顾
- jQuery学习笔记--JqGrid相关操作 方法列表 备忘 重点讲解(超重要)
- jQuery学习笔记--JqGrid相关操作 方法列表 备忘 重点讲解(超重要)
- 数据结构学习笔记10--栈和队列中的一些重点易错知识点
- MySQL学习笔记第二课 重点 修改表
- Java重点知识巩固学习笔记
- python学习笔记18-重点和忘记知识点总结
- Java_JVM学习笔记(深入理解Java虚拟机)___重点
- Swift学习笔记(四)——重点回顾及方法