CUDA学习笔记
2012-04-26 07:46
344 查看
1. About page-locked host memory / pinned memory:
(1) Restrict their use to memory that will be used as a source/destination in calls to cudaMemcpy() and freeing
them when they are no longer needed.
(2) When we use cudaMemcpyAsync(), we need to use page locked host memory.
2. About streams:
(1) Nvidia's GPU has two separate engines handling memory copies and kernel executions:Copy Engine & Kernel
Engine
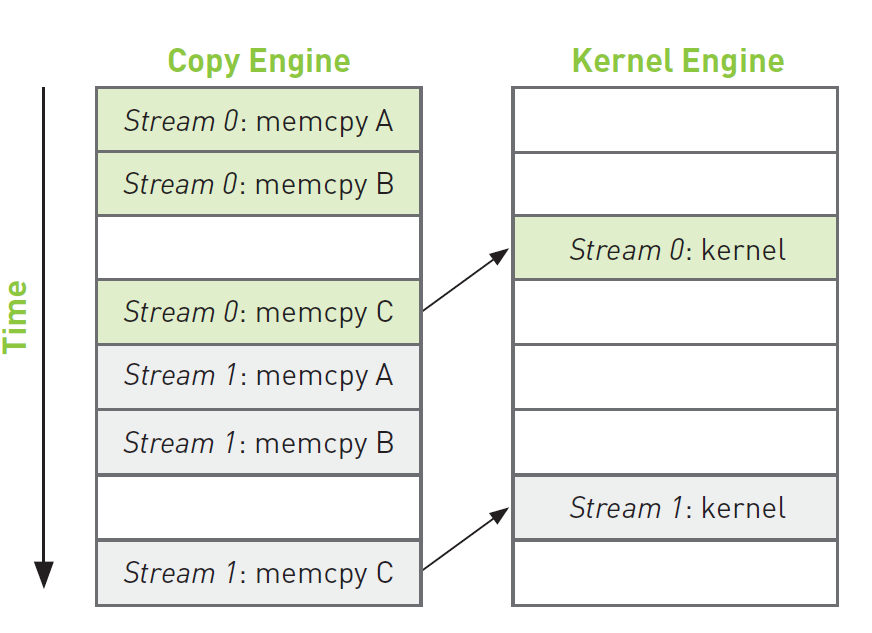
Figure 1 : not efficient
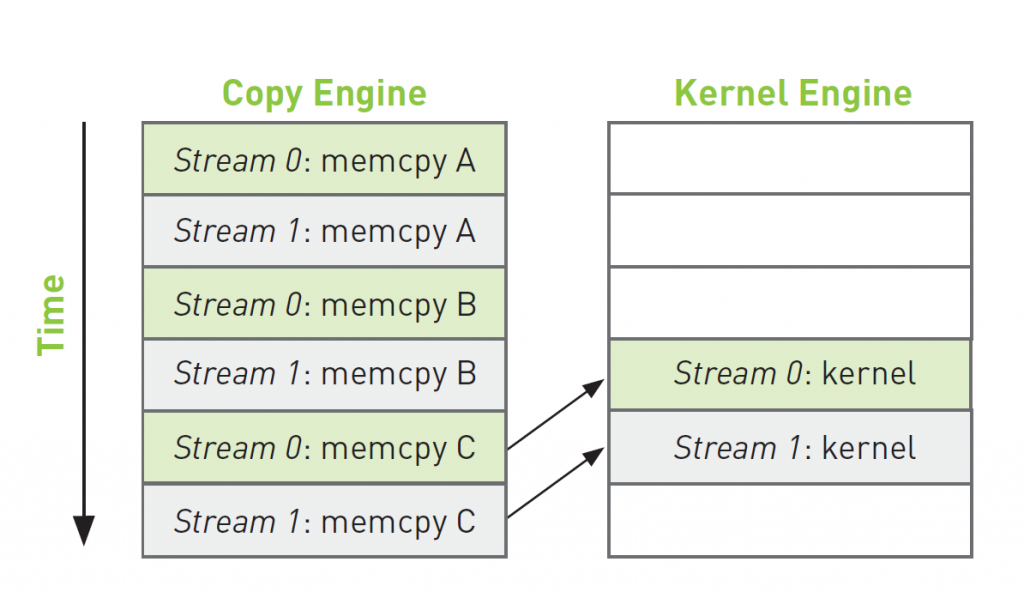
Figure2 : efficient
Trick: queue operations in all streams in a breadth-first order instead of depth-first order
To be continued...
(1) Restrict their use to memory that will be used as a source/destination in calls to cudaMemcpy() and freeing
them when they are no longer needed.
(2) When we use cudaMemcpyAsync(), we need to use page locked host memory.
2. About streams:
(1) Nvidia's GPU has two separate engines handling memory copies and kernel executions:Copy Engine & Kernel
Engine
Figure 1 : not efficient
Figure2 : efficient
Trick: queue operations in all streams in a breadth-first order instead of depth-first order
To be continued...

相关文章推荐
- CUDA学习笔记之程序优化
- CUDA学习笔记
- CUDA学习笔记之GPU和CPU的区别
- CUDA学习笔记——一些基本概念
- CUDA学习笔记之Tesla图形与计算架构和通用计算模型
- 【caffe 学习笔记之1】 WIN10+VS2013+CUDA7.5下CPU/GPU caffe配置
- NVIDIA DIGITS 学习笔记(NVIDIA DIGITS-2.0 + Ubuntu 14.04 + CUDA 7.0 + cuDNN 7.0 + Caffe 0.13.0)
- 【CUDA学习笔记】1.纹理内存
- (二)cuda学习笔记之 cuda基本概念
- CUDA学习笔记之随机数
- cuda学习笔记之异步并行执行
- 【CUDA学习笔记】3.纹理引用API
- deep CNN, Theano和CUDA学习笔记
- OpenCV学习笔记(六)OpenCV3.3+VS2013 配置CUDA加速
- CUDA学习笔记之程序优化
- CUDA学习笔记之 CUDA存储器模型
- DL学习笔记【4】caffe+win10+VS2013+cuda6.5+python安装过程
- 炼数成金CUDA视频教程——第三课2——学习笔记
- 深度学习笔记:windows10+visual studio 2013+cuda7.5+theano+lasagne环境配置