宽字符wchar_t和窄字符char区别和相互转换
2012-03-31 18:28
369 查看
1. 首先,说下窄字符char了,大家都很清楚,就是8bit表示的byte,长度固定。char字符只能表示ASII码表中的256个字符,包括前128个可见字符和后面的128个不可见字符。
而wchar_t则是因为char所能表示的字符数太少(256个)而应运而生的,它的长度可以8bit,16bit,32bit,长度是与不同平台上的c库相关的。其实这个长度是根据指定平台上想要用的encoding编码方式来设定的。
在win32 MSVC环境下,c库中wchar_t的长度是2个byte,定义如下:
typedef unsigned short wchar_t; /* 16 bits */
它是按照utf-16编码,但是因为wchar_t定义的长度只有2个字节,所以它不能表示utf-16编码长度为4个字节的字符。即wchar_t只表示了utf-16的一个子集。换句话话说,就是MSVC下,wchar_t是utf-16编码的,但是只能表示utf-16的一个子集。按utf-16编码时,大部分字符都以固定长度的字节 (2字节) 储存.
在Linux-x86的GCC环境下,c库中wchar_t的长度为四个字节,用UCS-4(即utf-32编码方式)。
wchar_t就是存储的字符的unicode码值的编码值,如windows下就是unicode码值的utf-16编码值:
TCHAR wide[] = L"态";
在vs中watch为: [0] 24577 L'态' wchar_t,即对应的十进制为24577,而"态"unicode表中查到的码值为十六进制的6001,而0x6001对应的十进制值就是24577.
TCHAR wide[] = L"a"; 因为a的unicode值与ASCII值一样,为97. 如果unicode码值U小于0x10000,则U的UTF-16编码就是U对应的16位无符号整数。
所以可知,0x6001的utf-16编码值就是0x6001。
wchar_t w1= L'中'; //Unicode 编码
wchar_t w2= '中'; //Ansi编码
printf( "%0x %0x ",w1,w2);
结果:
4e2d d6d0
虽然同样是赋值给wchar_t,但是不同的编码则值是不同的。同时也说明了wchar_t不光是可以存储Unicode宽字符,也可以存储其它的编码。但是如果是存储的Ansi编码,则按照宽字符的格式输出的是什么呢?
wchar_t c= L'中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述代码能正常输出'中'字
wchar_t c= '中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述代码不能正常输出'中'字,结果是什么也没输出。
所以如果是需要宽字符参数的API里传入值为Ansi编码值的wchar_t可能会得到不可预测的结果。
c/c++标准只是声明wchar_t是一个可以表示字符集中的任意一个字符的足够宽的变量类型。wchar_t可以用任何encoding编码方式来存储这个字符,如ANSI, or UCS-2, or UCS- 4, 甚至是SCU-128,只不过我们通常是用unicode编码方式。wchar_t是与实现相关的。
所以为了可移植性,我们不能假定wchar_t的编码方式,然后根据编码方式做一些相关性操作,我们只能理解它为一个足够宽的字符类型。
参考:http://prog.eskosoft.com/2007/01/13/19
2. ANSI码
ANSI码(American National Standards Institute),中文:美国国家标准学会的标准码。
我们说的ansi码,指windows平台的一种ascii扩展码,他将ascii码扩展到8bits,增加了0x80-0xff共128个字符。
对于ANSI码表而言,它兼容ASCII码表,0x00~0x7F之间的字符,依旧是1个字节代表1个字符。为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个非英语字符。
像GB2312, BIG5, JIS 等使用ANSI码表的0x80~0xFF范围的 2 个字节来代表一个字符的各种汉字延伸编码方式,统称为ANSI 编码。比如:汉字 '中' 在GB2312码表中,使用 [0xD6,0xD0] 这两个字节存储。ANSI 编码与UTF-8一样,也是一种编码方式。
ANSI用一个字节来表示英语字符,用两个字节来表示一个非英语字符----这个字符位于某个字符集中的value。而字符集则可以是象GB2312,BIG5等在ASCII码表基础上扩展的字符集。这些字符集中兼容ASCII码表,并且加入了汉字(或繁体等)的字符集。
在vs 的c++环境下,可以通过如下方式查看汉字的ANSI编码值。char类型取值范围为-128~127。-42对应的char类型数据的原码为“10101010”,反码为"11010101",补码为"11010110",即十六进制为0xD6。同理-48则为0xD0.由此我们可知,ANSI,是通过两个窄字符char来表示一个汉字的。
当我们 在VS里输入一个“中”字时,其实它在GB2312里对应的两个字符值为0xD6和0xD0,那么VS里其实记录的就是[0xD6,0xD0]这个编码值。当我们电脑控制面板里设置的system locale为中文的时候,[0xD6,0xD0]在VS里就是呈现出“中”字;但是如果system locale设置为韩文时,[0xD6,0xD0]在VS里就是呈现出的就是它所表示的韩文字。即同一个ANSI编码值,对于不同的system locale值(不同的字符集),显示出来的字符是不一样的。
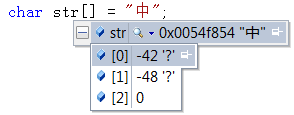
在VS工程属性里无论你选择Multi-Byte Character Set 或 Unicode Character Set字符集,char str[] = "中";这个表达式里,"中"都是ANSI编码,编码值都是[0xD6,0xD0]。即默认情况下,如果不加_T或L,默认情况下所有的字符都是ANSI编码。
3. 相互转换:
转换的时候是与encoding相关的,转换完后显示是和本地的language相关的。
windows:
MultiByteToWideChar和WideCharToMultiByte, MultiByteToWideChar可将utf-8编码的多字节或是ANSI编码的多字节(即两个字节)等转换为Unicode的宽字符wchar_t。例如,两个byte的窄字符表示的ANSI汉字转换为Unicode的宽字符wchar_t。WideCharToMultiByte可以将wchar_t转换utf-8或ANSI 等编码的多字节。
linux:mbstowcs和wcstombs
MultiByteToWideChar根据接口中指定的encoding方式将source多字符转换为对应的unicode值的宽字符;WideCharToMultiByte则刚好相反,是根据指定的encoding编码方式将unicode字符转换为指定的编码方式的多字符。
char str[] = "中";
int len=MultiByteToWideChar(CP_ACP,0,str, -1, NULL,0);
wchar_t *w_string = new wchar_t[len];
memset(w_string,0,sizeof(wchar_t)*len);
MultiByteToWideChar(CP_ACP, 0, str,-1,w_string, len);
运行结果:
则len的长度为2,得到两个宽字符。*w_string则是'中'的宽字符值,*(w_string+1)则为结束符'\0'对应的宽字符值0.
详细的转换过程,下面的link中有详细描述:
http://www.ccw.com.cn/college/soft/b2c/os/htm2011/20111128_954237.shtml
另外附上一个非常不错的文章链接:
http://club.topsage.com/thread-2227977-1-1.html
而wchar_t则是因为char所能表示的字符数太少(256个)而应运而生的,它的长度可以8bit,16bit,32bit,长度是与不同平台上的c库相关的。其实这个长度是根据指定平台上想要用的encoding编码方式来设定的。
在win32 MSVC环境下,c库中wchar_t的长度是2个byte,定义如下:
typedef unsigned short wchar_t; /* 16 bits */
它是按照utf-16编码,但是因为wchar_t定义的长度只有2个字节,所以它不能表示utf-16编码长度为4个字节的字符。即wchar_t只表示了utf-16的一个子集。换句话话说,就是MSVC下,wchar_t是utf-16编码的,但是只能表示utf-16的一个子集。按utf-16编码时,大部分字符都以固定长度的字节 (2字节) 储存.
在Linux-x86的GCC环境下,c库中wchar_t的长度为四个字节,用UCS-4(即utf-32编码方式)。
wchar_t就是存储的字符的unicode码值的编码值,如windows下就是unicode码值的utf-16编码值:
TCHAR wide[] = L"态";
在vs中watch为: [0] 24577 L'态' wchar_t,即对应的十进制为24577,而"态"unicode表中查到的码值为十六进制的6001,而0x6001对应的十进制值就是24577.
TCHAR wide[] = L"a"; 因为a的unicode值与ASCII值一样,为97. 如果unicode码值U小于0x10000,则U的UTF-16编码就是U对应的16位无符号整数。
所以可知,0x6001的utf-16编码值就是0x6001。
wchar_t w1= L'中'; //Unicode 编码
wchar_t w2= '中'; //Ansi编码
printf( "%0x %0x ",w1,w2);
结果:
4e2d d6d0
虽然同样是赋值给wchar_t,但是不同的编码则值是不同的。同时也说明了wchar_t不光是可以存储Unicode宽字符,也可以存储其它的编码。但是如果是存储的Ansi编码,则按照宽字符的格式输出的是什么呢?
wchar_t c= L'中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述代码能正常输出'中'字
wchar_t c= '中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述代码不能正常输出'中'字,结果是什么也没输出。
所以如果是需要宽字符参数的API里传入值为Ansi编码值的wchar_t可能会得到不可预测的结果。
c/c++标准只是声明wchar_t是一个可以表示字符集中的任意一个字符的足够宽的变量类型。wchar_t可以用任何encoding编码方式来存储这个字符,如ANSI, or UCS-2, or UCS- 4, 甚至是SCU-128,只不过我们通常是用unicode编码方式。wchar_t是与实现相关的。
所以为了可移植性,我们不能假定wchar_t的编码方式,然后根据编码方式做一些相关性操作,我们只能理解它为一个足够宽的字符类型。
参考:http://prog.eskosoft.com/2007/01/13/19
2. ANSI码
ANSI码(American National Standards Institute),中文:美国国家标准学会的标准码。
我们说的ansi码,指windows平台的一种ascii扩展码,他将ascii码扩展到8bits,增加了0x80-0xff共128个字符。
对于ANSI码表而言,它兼容ASCII码表,0x00~0x7F之间的字符,依旧是1个字节代表1个字符。为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个非英语字符。
像GB2312, BIG5, JIS 等使用ANSI码表的0x80~0xFF范围的 2 个字节来代表一个字符的各种汉字延伸编码方式,统称为ANSI 编码。比如:汉字 '中' 在GB2312码表中,使用 [0xD6,0xD0] 这两个字节存储。ANSI 编码与UTF-8一样,也是一种编码方式。
ANSI用一个字节来表示英语字符,用两个字节来表示一个非英语字符----这个字符位于某个字符集中的value。而字符集则可以是象GB2312,BIG5等在ASCII码表基础上扩展的字符集。这些字符集中兼容ASCII码表,并且加入了汉字(或繁体等)的字符集。
在vs 的c++环境下,可以通过如下方式查看汉字的ANSI编码值。char类型取值范围为-128~127。-42对应的char类型数据的原码为“10101010”,反码为"11010101",补码为"11010110",即十六进制为0xD6。同理-48则为0xD0.由此我们可知,ANSI,是通过两个窄字符char来表示一个汉字的。
当我们 在VS里输入一个“中”字时,其实它在GB2312里对应的两个字符值为0xD6和0xD0,那么VS里其实记录的就是[0xD6,0xD0]这个编码值。当我们电脑控制面板里设置的system locale为中文的时候,[0xD6,0xD0]在VS里就是呈现出“中”字;但是如果system locale设置为韩文时,[0xD6,0xD0]在VS里就是呈现出的就是它所表示的韩文字。即同一个ANSI编码值,对于不同的system locale值(不同的字符集),显示出来的字符是不一样的。
在VS工程属性里无论你选择Multi-Byte Character Set 或 Unicode Character Set字符集,char str[] = "中";这个表达式里,"中"都是ANSI编码,编码值都是[0xD6,0xD0]。即默认情况下,如果不加_T或L,默认情况下所有的字符都是ANSI编码。
3. 相互转换:
转换的时候是与encoding相关的,转换完后显示是和本地的language相关的。
windows:
MultiByteToWideChar和WideCharToMultiByte, MultiByteToWideChar可将utf-8编码的多字节或是ANSI编码的多字节(即两个字节)等转换为Unicode的宽字符wchar_t。例如,两个byte的窄字符表示的ANSI汉字转换为Unicode的宽字符wchar_t。WideCharToMultiByte可以将wchar_t转换utf-8或ANSI 等编码的多字节。
linux:mbstowcs和wcstombs
MultiByteToWideChar根据接口中指定的encoding方式将source多字符转换为对应的unicode值的宽字符;WideCharToMultiByte则刚好相反,是根据指定的encoding编码方式将unicode字符转换为指定的编码方式的多字符。
char str[] = "中";
int len=MultiByteToWideChar(CP_ACP,0,str, -1, NULL,0);
wchar_t *w_string = new wchar_t[len];
memset(w_string,0,sizeof(wchar_t)*len);
MultiByteToWideChar(CP_ACP, 0, str,-1,w_string, len);
运行结果:
则len的长度为2,得到两个宽字符。*w_string则是'中'的宽字符值,*(w_string+1)则为结束符'\0'对应的宽字符值0.
详细的转换过程,下面的link中有详细描述:
http://www.ccw.com.cn/college/soft/b2c/os/htm2011/20111128_954237.shtml
另外附上一个非常不错的文章链接:
http://club.topsage.com/thread-2227977-1-1.html

相关文章推荐
- 宽字符wchar_t和窄字符char区别和相互转换
- 宽字符wchar_t和窄字符char区别和相互转换
- char字符与wchar_t字符的相互转换,以及wchar_t字符串的常用用法
- [转]字节码问题--wchar和char的区别以及wchar和char之间的相互转换字符编码转换等方法及函数介绍
- UNICODE下宽字符的CString转换为const char *和char到WCHAR的相互转换
- 字节码问题--wchar和char的区别以及wchar和char之间的相互转换字符编码转换等方法及函数介绍
- UNICODE下宽字符的CString转换为const char *和char到WCHAR的相互转换
- [转载]字节码问题--wchar和char的区别以及wchar和char之间的相互转换字符编码转换等方法及函数介绍
- 字节码问题--wchar和char的区别以及wchar和char之间的相互转换字符编码转换等方法及函数介绍
- c++ 字符类型总结区别wchar_t,char,WCHAR
- C++ 宽字符(wchar_t)与窄字符(char)的转换
- CString、wchar和char类型的相互转换(转载)
- oracle to_char()to_date()函数 mysql日期和字符相互转换方法
- 【Sql】mysql类似to_char()to_date()函数mysql日期和字符相互转换方法date_f
- c++宽字符与多字节之间转换char—wchar,wchar-char
- char* char[]及string的区别及相互转换
- c++中char*\wchar_t*\string\wstring之间的相互转换
- c++ 字符类型总结区别wchar_t,char,WCHAR
- C++中char*\wchar_t*\string\wstring之间的相互转换:
- C++/MFC-CHAR和WCHAR类型的相互转换