[论文笔记] Crowdsourced Databases: Query Processing with People (CIDR, 2011)
2012-03-26 10:52
453 查看
Time: 1.5 hours
Timespan: Mar 24 – Mar 26, 2012
Adam Marcus, Eugene Wu, Samuel Madden, Robert C. Miller: Crowdsourced Databases: Query Processing with People. CIDR 2011: 211-214 (Fifth Biennial Conference on Innovative Data Systems Research)
作者Adam Marcus是MIT CSAIL实验室(Haystack项目就是这个实验室的)的研究生。这篇四页的短文提出了一个概念原型Qurk:具有类似SQL的查询系统,具体任务经分解、包装后发布到MTurk上。文中对Qurk的描述:"a novel query system for managing these workflows, allowing MTurk-style processing of relational databases"。以下是论文内容:
1. 针对这样的一个系统,(S1)提出了一些问题:
(1) relation operations(比如等值连接) 在该系统中对等的操作怎么定义?
(2) 对于一个给定的任务,应该产生多少个HIT为宜?(比如对于一个排序的操作,可以只产生一个HIT,要求在这个HIT中对所有的项进行排序;也可以产生多个HIT,分别排序,但最后需要有merge的机制)
(3) 查询空间太大时,如果进行采样查询?
(4) 如何定价?
2. (S2)中提出了几个"Motivating Examples"
(1) 给定:一组公司名称列表
要求返回:这些公司的CEO和联系方式的列表
(2) 给定:一组灾难中难民的照片,另一组家人提供的照片
要求返回:匹配的照片对
(3) 给定: 一组信息
要求返回:区分这些信息表达的情况(比如”正面”还是”负面”)
(4) 给定:一组产品的列表
要求返回: 根据Amazon上的review,对这些产品进行排名。
3. (S3)中给出了系统设计的概念图
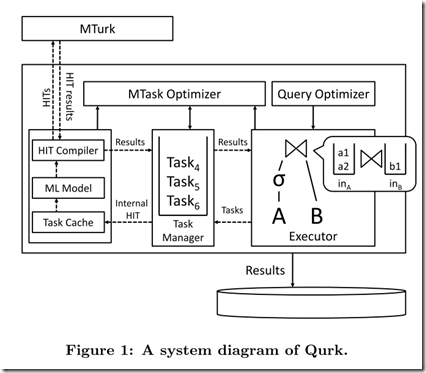
Executor用来产生供人类执行的任务列表。
Task Manager维护了一个任务的Queue,这些任务对应HIT。
Task Cache缓存已执行过的任务。
HIT Compiler用来生成供最终用户查看的HIT的HTML页面;可通过MTurk API与MTurk交互。
4. (S4)中举了一下查询语句的例子,如下:


5. (S6)中提出了一些优化的方向,包括: Runtime Priceing, Input Sampling, Batch Predicates, Operator Implementations, Join Heuristics, Task Result Cache, Model Training。
优化时会有一些导向,如:maxCost, minConfidence, maxLatency等。
6. 本文介绍了Qurk系统的概念,全文都很好懂。相关可关注的内容:
(1) embedding turkers as editors into a word processing system (To appear: Soylent. In UIST, New York, NY, USA,2010.)
(2) Crowdflower: provides an API to make developing HITs and finding cheating turkers easier. http://crowdflower.com/
Timespan: Mar 24 – Mar 26, 2012
Adam Marcus, Eugene Wu, Samuel Madden, Robert C. Miller: Crowdsourced Databases: Query Processing with People. CIDR 2011: 211-214 (Fifth Biennial Conference on Innovative Data Systems Research)
作者Adam Marcus是MIT CSAIL实验室(Haystack项目就是这个实验室的)的研究生。这篇四页的短文提出了一个概念原型Qurk:具有类似SQL的查询系统,具体任务经分解、包装后发布到MTurk上。文中对Qurk的描述:"a novel query system for managing these workflows, allowing MTurk-style processing of relational databases"。以下是论文内容:
1. 针对这样的一个系统,(S1)提出了一些问题:
(1) relation operations(比如等值连接) 在该系统中对等的操作怎么定义?
(2) 对于一个给定的任务,应该产生多少个HIT为宜?(比如对于一个排序的操作,可以只产生一个HIT,要求在这个HIT中对所有的项进行排序;也可以产生多个HIT,分别排序,但最后需要有merge的机制)
(3) 查询空间太大时,如果进行采样查询?
(4) 如何定价?
2. (S2)中提出了几个"Motivating Examples"
(1) 给定:一组公司名称列表
要求返回:这些公司的CEO和联系方式的列表
(2) 给定:一组灾难中难民的照片,另一组家人提供的照片
要求返回:匹配的照片对
(3) 给定: 一组信息
要求返回:区分这些信息表达的情况(比如”正面”还是”负面”)
(4) 给定:一组产品的列表
要求返回: 根据Amazon上的review,对这些产品进行排名。
3. (S3)中给出了系统设计的概念图

Executor用来产生供人类执行的任务列表。
Task Manager维护了一个任务的Queue,这些任务对应HIT。
Task Cache缓存已执行过的任务。
HIT Compiler用来生成供最终用户查看的HIT的HTML页面;可通过MTurk API与MTurk交互。
4. (S4)中举了一下查询语句的例子,如下:


5. (S6)中提出了一些优化的方向,包括: Runtime Priceing, Input Sampling, Batch Predicates, Operator Implementations, Join Heuristics, Task Result Cache, Model Training。
优化时会有一些导向,如:maxCost, minConfidence, maxLatency等。
6. 本文介绍了Qurk系统的概念,全文都很好懂。相关可关注的内容:
(1) embedding turkers as editors into a word processing system (To appear: Soylent. In UIST, New York, NY, USA,2010.)
(2) Crowdflower: provides an API to make developing HITs and finding cheating turkers easier. http://crowdflower.com/

相关文章推荐
- [论文笔记] Anatomy of a crowdsourcing platform - Using the example of microworkers.com (IMIS, 2011)
- [论文笔记] Budget-optimal crowdsourcing using low-rank matrix approximations (Allerton, 2011)
- 斯坦福NLP笔记73 —— Query Processing with the Inverted I 3ff0
- [论文笔记] MobileWorks: A Mobile Crowdsourcing Platform for Workers at the Bottom of the Pyramid (Human Computation, 2011)
- [论文笔记] Live Migration of Multiple Virtual Machines with Resource Reservation in Cloud Computing Environments (CLOUD, 2011)
- [论文笔记] Crowdsourcing Translation: Professional Quality from Non-Professionals (ACL, 2011)
- [论文笔记] Task Matching in Crowdsourcing (iThings & CPSCom, 2011)
- [论文笔记] MoneyBee: Towards enabling a ubiquitous, efficient, and easy-to-use mobile crowdsourcing service … (Bell Labs Technical Journal, 2011)
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
- 论文笔记 OHEM: Training Region-based Object Detectors with Online Hard Example Mining
- 论文笔记(3)-Extracting and Composing Robust Features with Denoising Autoencoders
- 论文笔记:Training Region-based Object Detectors with Online Hard Example Mining
- 论文笔记——CVPR 2017 Annotating Object Instances with a Polygon-RNN
- part-aligned系列论文:1711.Beyond Part Models- Person Retrieval with Refined Part Pooling 论文阅读笔记
- [论文笔记] Human computation tasks with global constraints (CHI, 2012)
- 【论文学习笔记】Face Recognition with Learning-based Descriptor
- 论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
- 论文阅读笔记《leaning spatiotemporal features with 3D convolutional network》
- 论文笔记-深度估计(5)Unsupervised Monocular Depth Estimation with Left-Right Consistency
- 【论文笔记】Image Classification with Deep Convolutional Neural Network