续:有关SQL SERVER分布统计的问题
2012-03-21 13:34
253 查看
查询统计
现在我们来粗略地看下直方图的工作方式,重要的是要了解如何查询表中的统计个数,幸运的是可以使用以下命令来查询:
[/code]
查询结果:

创建统计
在对你的数据库运行上面的查询时看到的统计对象是自动创建的,当然,你也可以通过运行以下命令来手动创建:
[/code]
上面的这条命令将对表t1的i列上创建一个统计对象,同时使用WITH FULLSCAN参数来扫描整个表,而不是采样部分行,主要是为了得到更为精确的统计直方图。
不过,FULL SCAN的开销也是比较大的,但是要比采样扫描更为精确。
采样扫描
默认,SQL SERVER会根据现有的统计对象是否过期来进行创建或更新统计;当检测到与当前数据不匹配时,SQL SERVER会采样表中的数据进行重建统计,默认的采样频率是根据表的大小进行缓慢增加。
当使用采样创建统计时,SQL SERVER会从IAM链中随机选取一些页面,一旦某个页面选定后,页面中的这些数据就作为采样的数据源,这偶尔对导致一些不正确的数据统计,为此,你可能使用FULLSCAN来重建统计。
注意:有关IAM链的信息可以从这个链接http://www.sqlskills.com/blogs/paul/post/Inside-the-Storage-Engine-IAM-pages-IAM-chains-and-allocation-units.aspx获取详细的内容,另外,使用下面的信息来检测标记过期统计的方法,当统计的列发生更新时,SQL SERVER会根据实例中设置的“自动更新统计”来保持数据最新,其工作的方法如下:
当表的行数小于6条,并且该表存储在TEMPDB数据库中,每发生6次修改会触发自动更新
当表的行数大于6条,并且小于等于500,每发生500次修改会触发自动更新
当表的行数大于500条,表中的(500+20%)的数据发生变化会触发自动列新
对于表变量来说,并不会触发自动更新
全扫描
在有些表中,经常看到由于某些列发生变化,与这些列相关的统计也会自动更新,但是若发现创建的统计是基于采样的数据,那你可能需要手动运行
UPDATE STATISTICS WITH FULLSCAN来更新统计,如下命令:
[/code]
说到这里,你可能会问:有必要关注数据库中统计所占用的空间吗?
答案取决于多种因素,通常不用过多关注统计所占用的空间,但是也不总是这样;如果你遇到一个含有非常长的列的表,或许你应该调查一下服务器是否因花费过多的时间和资源来更新这些统计的必要性。
在维护期间重建索引和更新统计,对于一个系统中数据量比较大的表来说,可能删除那些未使用的统计,这样有助于提高重建和统计更新的速度,不过并没有一种方法来检查统计对象是否使用,很难找出哪些统计对象未被使用。
测试
下面来通过一个示例来介绍,脚本创建一个示例表Tab1(26列),然后插入1万行:
[/code]
接着,我们来运行DBCC来执行索引重建,注意该表没有任何统计,你可以通过PROFILER来检查。
[/code]

现在我们假设你在表上为每一列创建一个统计,这意味着重建会触发统计的更新,通常你不必太在意,但是要清楚如何管理就行。
要为每一列创建统计对象,可以使用sp_createstats存储过程。
EXEC sp_createstats;
GO
执行上面的存储过程后,将为表Tab1的26个字段分别创建一个统计,然后再执行重建操作。
DBCC DBREINDEX (Tab1)
GO

从上面的输出可以看出,有大量的更新统计(SELECT StatsMan…)执行。
接下来我们来看一下统计对象占用多少的容量。
统计对象所占用的空间容量实际上很小,不会对系统性能造成影响,如果你持怀疑态度,想调查统计对象实际占用了多少容量,运行以下查询:
[/code]

从Size KB列可以知道每一个统计对象使用的字节数。
现在我们来粗略地看下直方图的工作方式,重要的是要了解如何查询表中的统计个数,幸运的是可以使用以下命令来查询:
[code]SELECT Schema_name(sys.objects.schema_id) + '.' + Object_Name(sys.stats.object_id) AS Table_Name,
sys.columns.name AS Column_Name,
sys.stats.Name AS Stats_Name
FROM sys.stats
INNER JOIN sys.stats_columns
ON stats.object_id = stats_columns.object_id
AND stats.stats_id = stats_columns.stats_id
INNER JOIN sys.columns
ON stats_columns.object_id = columns.object_id
AND stats_columns.column_id = columns.column_id
INNER JOIN sys.objects
ON stats.object_id = objects.object_id
LEFT OUTER JOIN sys.indexes
ON sys.stats.Name = sys.indexes.Name
WHERE sys.objects.type = 'U'
--AND sys.objects.name = 'Tab1'
ORDER BY Table_Name
GO
[/code]
查询结果:

创建统计
在对你的数据库运行上面的查询时看到的统计对象是自动创建的,当然,你也可以通过运行以下命令来手动创建:
[code] CREATE STATISTICS Stats_MyStatOnCol1 ON t1(i) WITH FULLSCAN
[/code]
上面的这条命令将对表t1的i列上创建一个统计对象,同时使用WITH FULLSCAN参数来扫描整个表,而不是采样部分行,主要是为了得到更为精确的统计直方图。
不过,FULL SCAN的开销也是比较大的,但是要比采样扫描更为精确。
采样扫描
默认,SQL SERVER会根据现有的统计对象是否过期来进行创建或更新统计;当检测到与当前数据不匹配时,SQL SERVER会采样表中的数据进行重建统计,默认的采样频率是根据表的大小进行缓慢增加。
当使用采样创建统计时,SQL SERVER会从IAM链中随机选取一些页面,一旦某个页面选定后,页面中的这些数据就作为采样的数据源,这偶尔对导致一些不正确的数据统计,为此,你可能使用FULLSCAN来重建统计。
注意:有关IAM链的信息可以从这个链接http://www.sqlskills.com/blogs/paul/post/Inside-the-Storage-Engine-IAM-pages-IAM-chains-and-allocation-units.aspx获取详细的内容,另外,使用下面的信息来检测标记过期统计的方法,当统计的列发生更新时,SQL SERVER会根据实例中设置的“自动更新统计”来保持数据最新,其工作的方法如下:
当表的行数小于6条,并且该表存储在TEMPDB数据库中,每发生6次修改会触发自动更新
当表的行数大于6条,并且小于等于500,每发生500次修改会触发自动更新
当表的行数大于500条,表中的(500+20%)的数据发生变化会触发自动列新
对于表变量来说,并不会触发自动更新
全扫描
在有些表中,经常看到由于某些列发生变化,与这些列相关的统计也会自动更新,但是若发现创建的统计是基于采样的数据,那你可能需要手动运行
UPDATE STATISTICS WITH FULLSCAN来更新统计,如下命令:
[code] UPDATE STATISTICS Tab1 Stats_MyStatOnCol1 WITH FULLSCAN
[/code]
说到这里,你可能会问:有必要关注数据库中统计所占用的空间吗?
答案取决于多种因素,通常不用过多关注统计所占用的空间,但是也不总是这样;如果你遇到一个含有非常长的列的表,或许你应该调查一下服务器是否因花费过多的时间和资源来更新这些统计的必要性。
在维护期间重建索引和更新统计,对于一个系统中数据量比较大的表来说,可能删除那些未使用的统计,这样有助于提高重建和统计更新的速度,不过并没有一种方法来检查统计对象是否使用,很难找出哪些统计对象未被使用。
测试
下面来通过一个示例来介绍,脚本创建一个示例表Tab1(26列),然后插入1万行:
[code] CREATE TABLE Tab1 (ID Int IDENTITY(1,1) PRIMARY KEY,
Col1 VarChar(200) DEFAULT NEWID(),
Col2 VarChar(200) DEFAULT NEWID(),
Col3 VarChar(200) DEFAULT NEWID(),
Col4 VarChar(200) DEFAULT NEWID(),
Col5 VarChar(200) DEFAULT NEWID(),
Col6 VarChar(200) DEFAULT NEWID(),
Col7 VarChar(200) DEFAULT NEWID(),
Col8 VarChar(200) DEFAULT NEWID(),
Col9 VarChar(200) DEFAULT NEWID(),
Col10 VarChar(200) DEFAULT NEWID(),
Col11 VarChar(200) DEFAULT NEWID(),
Col12 VarChar(200) DEFAULT NEWID(),
Col13 VarChar(200) DEFAULT NEWID(),
Col14 VarChar(200) DEFAULT NEWID(),
Col15 VarChar(200) DEFAULT NEWID(),
Col16 VarChar(200) DEFAULT NEWID(),
Col17 VarChar(200) DEFAULT NEWID(),
Col18 VarChar(200) DEFAULT NEWID(),
Col19 VarChar(200) DEFAULT NEWID(),
Col20 VarChar(200) DEFAULT NEWID(),
Col21 VarChar(200) DEFAULT NEWID(),
Col22 VarChar(200) DEFAULT NEWID(),
Col23 VarChar(200) DEFAULT NEWID(),
Col24 VarChar(200) DEFAULT NEWID(),
Col25 VarChar(200) DEFAULT NEWID())
GO
INSERT INTO Tab1 DEFAULT VALUES
GO 10000
[/code]
接着,我们来运行DBCC来执行索引重建,注意该表没有任何统计,你可以通过PROFILER来检查。
[code] DBCC DBREINDEX (Tab1)
GO
[/code]
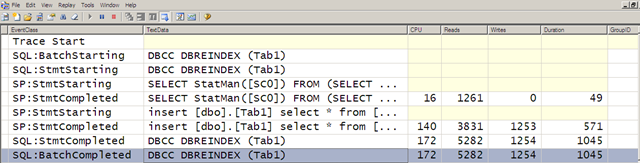
现在我们假设你在表上为每一列创建一个统计,这意味着重建会触发统计的更新,通常你不必太在意,但是要清楚如何管理就行。
要为每一列创建统计对象,可以使用sp_createstats存储过程。
EXEC sp_createstats;
GO
执行上面的存储过程后,将为表Tab1的26个字段分别创建一个统计,然后再执行重建操作。
DBCC DBREINDEX (Tab1)
GO

从上面的输出可以看出,有大量的更新统计(SELECT StatsMan…)执行。
接下来我们来看一下统计对象占用多少的容量。
统计对象所占用的空间容量实际上很小,不会对系统性能造成影响,如果你持怀疑态度,想调查统计对象实际占用了多少容量,运行以下查询:
[code] IF OBJECT_ID('tempdb.dbo.#TMP') IS NOT NULLDROP TABLE #TMP
GO
CREATE TABLE #TMP (ID Int Identity(1,1) PRIMARY KEY,
Table_Name VarChar(200),
Column_Name VarChar(200),
Stats_Name VarChar(200),
ColStats_Stream VarBinary(MAX),
ColRows BigInt,
ColData_Pages BigInt)
GO
DECLARE @Tab TABLE (ROWID Int IDENTITY(1,1) PRIMARY KEY,
Table_Name VarChar(200),
Column_Name VarChar(200),
Stats_Name VarChar(200))
DECLARE @i Int = 0,
@Table_Name VarChar(200) = '',
@Column_Name VarChar(200) = '',
@Stats_Name VarChar(200) = ''
INSERT INTO @Tab (Table_Name, Column_Name, Stats_Name)
SELECT Schema_name(sys.objects.schema_id) + '.' + Object_Name(sys.stats.object_id) AS Table_Name,
sys.columns.name AS Column_Name,
sys.stats.Name AS Stats_Name
FROM sys.stats
INNER JOIN sys.stats_columns
ON stats.object_id = stats_columns.object_id
AND stats.stats_id = stats_columns.stats_id
INNER JOIN sys.columns
ON stats_columns.object_id = columns.object_id
AND stats_columns.column_id = columns.column_id
INNER JOIN sys.objects
ON stats.object_id = objects.object_id
LEFT OUTER JOIN sys.indexes
ON sys.stats.Name = sys.indexes.Name
WHERE sys.objects.type = 'U'
ORDER BY Table_Name
SELECT TOP 1 @i = ROWID,
@Table_Name = Table_Name,
@Column_Name = Column_Name,
@Stats_Name = Stats_Name
FROM @Tab
WHERE ROWID > @I
WHILE @@RowCount > 0
BEGIN
--PRINT 'UPDATE STATISTICS "' + @Table_Name + '" "'+@Stats_Name+'" WITH FULLSCAN'
--EXEC ('UPDATE STATISTICS "' + @Table_Name + '" "'+@Stats_Name+'" WITH FULLSCAN')INSERT INTO #TMP(ColStats_Stream, ColRows, ColData_Pages)
EXEC ('DBCC SHOW_STATISTICS ("' + @Table_Name + '", "'+@Stats_Name+'") WITH STATS_STREAM');WITH CTE_Temp AS (SELECT TOP (@@RowCount) * FROM #TMP ORDER BY ID DESC)
UPDATE CTE_Temp
SET Table_Name = @Table_Name,
Column_Name = @Column_Name,
Stats_Name = @Stats_Name
SELECT TOP 1 @i = ROWID,
@Table_Name = Table_Name,
@Column_Name = Column_Name,
@Stats_Name = Stats_Name
FROM @Tab
WHERE ROWID > @I
END
GO
SELECT SUM(DATALENGTH(ColStats_Stream) / 1024.) AS [Size KB]
FROM #TMP
GO
SELECT Table_Name,
Column_Name,
Stats_Name,
ColStats_Stream,
DATALENGTH(ColStats_Stream) / 1024. AS [Size KB]
FROM #TMP
ORDER BY [Size KB] DESC
[/code]
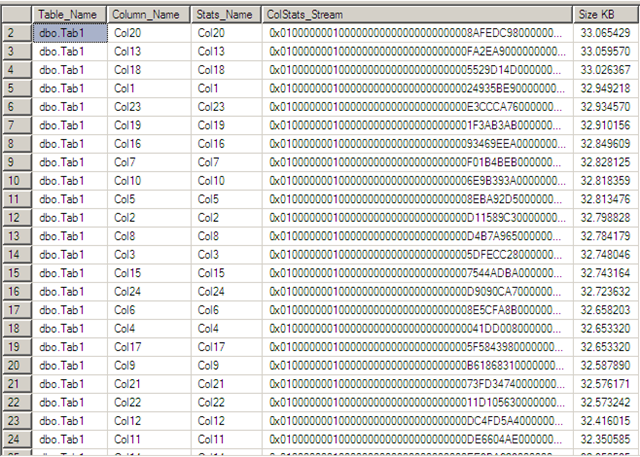
从Size KB列可以知道每一个统计对象使用的字节数。

相关文章推荐
- 有关SQL Server分布统计的问题
- 有关SQL Server分布统计的问题
- SQL Server统计信息:问题和解决方案
- 有关Gridview中统计数据的问题
- storm对网站有关数据的统计以及多线程问题探讨
- SQL Server处理空值时有关的三问题
- MYSQL中有关SUM字段按条件统计使用IF函数(case)问题
- 有关C语言的数据统计和编程问题 高手请进
- 概率统计里分布函数中的右连续问题
- 有关eclipse连接SQL Server 2008的问题
- Local Response Normalization作用——感觉LRN也是解决的梯度消失和爆炸问题,统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的
- MYSQL中有关SUM字段按条件统计使用IF函数(case)问题
- 一个有关访问量统计的数据库设计以及isqlplus的一个设置问题
- MYSQL中有关SUM字段按条件统计使用IF函数(case)问题
- 有关SQLServer内存问题(收藏)-数据库专栏,SQL Server
- SQL Server统计信息:问题和解决方案
- 有关sql server用int型主键的一些问题
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
- Sql Server关于按周统计的问题 [转]
- 有关C语言程序内存问题的5条规则