开源搜索框架Lucene学习之分词器(4)——通过分词器源码学习装饰者模式
2012-01-05 17:14
330 查看
以前也学习过一些设计模式,但由于没有实践,虽然当时学的时候以为自己都理解了,其实都是半知半解。我个人觉得光看哪些书以及别人讲解,还是不够的,一定需要自己实践或者亲自体会到他的好处的时候,你才能有一个较深的理解。在学习分词器的代码的时候,我就发现他使用了装饰者模式,而且用得比较精妙。所以我就结合这个案例,然后看了一下一些书籍对这个模式的介绍,认真的学习了一下这个模式,下面记录我自己的一些心得。
装饰模式(Decorator),动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为灵活。引用自《大话设计模式》
通过这句话,我们可以理解为,装饰者模式其实就是为了装饰某一个对象,给这些对象添加一些其他的属性。每个装饰者在实现的时候,都可以不用关心被装饰者的内部实现。其实我们不使用装饰者模式照样可以实现这些功能,比如在这个类里面或子类里面添加一些新的字段来实现额外的职责,但是这样做了之后,第一会增加这个类的复杂性,第二一般来说这些额外的职责都是某些特殊的情况下才需要增加的,如果我们直接把它写在类里面就不太好。而装饰者模式是把每一个额外的职责通过另外的类来实现,如果哪一个对象需要这个职责,就用实现了这个职责的类去装饰这个对象。这样做的一个好处就是把装饰的功能从这个对象类中移除,这样可以使核心类的内容简单化。而且我们可以通过代码来按照不同的顺序去装饰这个对象。
我们来看一个结构图:
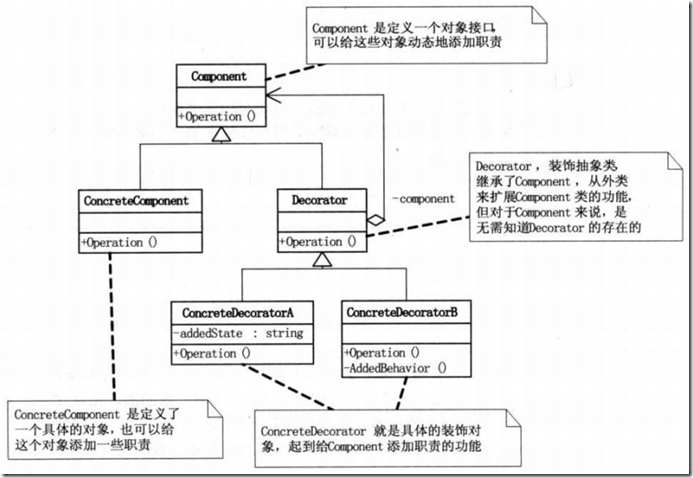
这张图是来自《大话设计模式》,首先有一个Component类,这个类是一个对象接口,可以给这个对象动态的添加职责。ConcreteComponent是定义了一个具体的对象,也可以给这个对象添加一些职责。Decorator类,就是装饰的抽象类,继承了Component,从外类来扩展Component类的功能。ConcreteDecoratorA和ConcreteDecoratorB则是具体的装饰类,负责实现具体的装饰职责的实现。下面来看看分词模块的整个类的结构图:
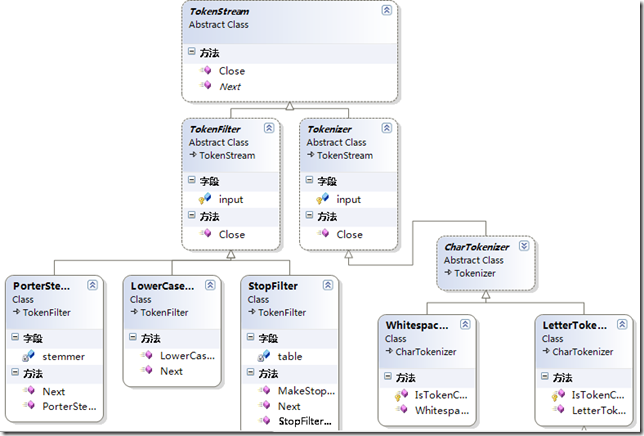
我们可以看到,是不是和上面的装饰者模式的结构图一样。TokenStream是一个抽象类,我们姑且把它理解为上面的对象接口(抽象类与接口的区别网上有很多资料),与Component对应。Tokenizer就是我们的具体对象类,其实这里与上面还是有一点区别的,那就是Tokenizer其实并不是具体的对象类,它也是一个抽象的类,真正具体的对象类是Tokenizer的子类CharTokenizer以及CharTokenizer的子类WhitespaceTokenizer和LetterTokenizer,这三个类实现了TokenStream定义的虚方法,并进行了一些扩充。它们就是具体的对象类。而TokenFilter则是装饰的抽象类,相当于上面的Decorator,它也是继承于TokenStream类。它的三个子类PorterStemFilter,LowerCaseFilter以及StopFilter就是具体的三个装饰者类,这三个类是来修饰Tokenizer的子类的。
我们来看CharTokenizer这个子类,它的作用是把语汇单元流以非英文字符来划分成一个个的Token。它并没有对Token进行一些处理,比如我们现在要把这些Token里面的字母都变成小写,提取它们的词干,然后再去掉停词,怎么办呢,按照我们前面的理解,这些就是想为对象增加一些额外的职责,那么我们可以用装饰者模式来实现,刚才说的三个功能,我们不用在CharTokenizer这个类里面实现它们。我们分别用三个装饰者类来实现这三个功能,也就是PorterStemFilter,LowerCaseFilter以及StopFilter这三个类,上图可能看不出来,实际上这三个类的构造函数都会接收一个TokenStream类型的参数,而CharTokenizer类也是从TokenStream类继承而来的,所以我们就明白,当我们创建了一个CharTokenizer类的对象后,我们可以把这个对象传递给前面所说的三个装饰者类,然后在三个不同的装饰者类里面去实现不同的额外的职责。前面我们说过,其实这些额外的职责也可以在具体对象类的子类里面实现,只不过这样不太灵活,或者说增加了复杂性,在这里我们可以看到,分词器模块里面兼顾了这两种实现方式,比如把Token变为小写这个功能,它用了一个装饰者类LowerCaseFilter类来实现,但同时它也用了一个子类来实现,也就是LowerCaseTokenizer(在上图没有显示,它是LetterTokenizer的一个子类),所以CharTokenizer类与LowerCaseFilter类共同作用的效果与LowerCaseTokenizer类的作用是一样的,只不过一个是通过装饰者模式实现的,另外一个是通过在子类里面实现的。
在分词模块里面,总共有四个分词器,分别是SimplyAnalyzer,WhiteSpaceAnalyzer,StopAnalyzer以及StandardAnalyzer分词器。其实这四个分词器就是把不同的对象与不同的装饰者类组合而成的,我们可以看代码。
SimplyAnalyzer里的代码:
[/code]
我们可以看到SimplyAnalyzer分词器里面只是构建了一个LowerCaseTokenizer类,也就是SimplyAnalyzer器是按非英文字母字符划分Token,并把每一个Token变成小写的。再来看WhitespaceAnalyzer的代码:
[/code]
我们可以看到WhitespaceAnalyzer分词器里面只是构建了一个WhitespaceTokenizer类。我们再看StopAnalyzer类,我们只看里面的一个方法:
[/code]
这里我们可以看到,首先创建了一个LowerCaseTokenizer,然后把这个类传递给了StopFilter这个装饰者类,它首先是按非英文字母来划分Token,然后转化成小写。但是它还需要完成一个额外的功能,那就是去掉停词。而StopFilter这个装饰者类的作用就是去掉停词,我们知道所有的装饰者类的构造函数中都接收一个TokenSteam类的对象,而LowerCaseTokenizer是继承自TokenStream,所以我们可以直接把LowerCaseTokenizer类的对象传递给StopFilter这个装饰者类,让这个装饰者类去实现去掉停词的功能。
如果上面的还不够明显,我们接下来来看StandardAnalyzer类的代码:
[/code]
通过上面的代码,我们可以清楚的看到,StandardAnalyzer类首先是创建一个StandardTokenizer对象,然后用了三个装饰者类去装饰这个对象,为这个对象添加了三个额外的功能。在这里,我们就可以非常明显的看到装饰者模式的好处。它可以有效的把类的核心职责与装饰功能分开,这样不但减少了类的复杂性,也使得每个类的职责单一,同时也比较灵活,我们如果需要不同的功能,我们就可以去实现不同的装饰者类,然后用这些装饰者类去装饰这个对象,还有一个好处就是,我可以任意调整装饰的顺序。
上面的仅仅是NLucene的代码,其实在Lucene后来的.net版本Lucene.net里面,还增加了许多分词的类,实现了一些更复杂的分词方法,同时也加入了一些简单的中文分词类,它们全部是在装饰者模式的基础上进行扩充的,不管多复杂的分词器,它都是由一些基础的对象类和一些装饰类组合而成的。通过装饰者模式,我们可以任意的扩充装饰者类,从而可以定制自己的分词器,非常的灵活,这也是装饰者模式的优点。
装饰模式(Decorator),动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为灵活。引用自《大话设计模式》
通过这句话,我们可以理解为,装饰者模式其实就是为了装饰某一个对象,给这些对象添加一些其他的属性。每个装饰者在实现的时候,都可以不用关心被装饰者的内部实现。其实我们不使用装饰者模式照样可以实现这些功能,比如在这个类里面或子类里面添加一些新的字段来实现额外的职责,但是这样做了之后,第一会增加这个类的复杂性,第二一般来说这些额外的职责都是某些特殊的情况下才需要增加的,如果我们直接把它写在类里面就不太好。而装饰者模式是把每一个额外的职责通过另外的类来实现,如果哪一个对象需要这个职责,就用实现了这个职责的类去装饰这个对象。这样做的一个好处就是把装饰的功能从这个对象类中移除,这样可以使核心类的内容简单化。而且我们可以通过代码来按照不同的顺序去装饰这个对象。
我们来看一个结构图:
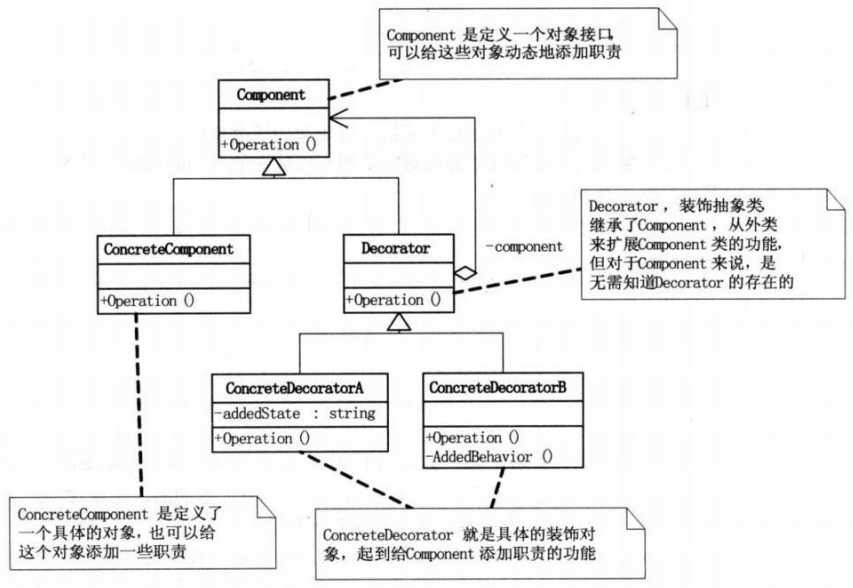
这张图是来自《大话设计模式》,首先有一个Component类,这个类是一个对象接口,可以给这个对象动态的添加职责。ConcreteComponent是定义了一个具体的对象,也可以给这个对象添加一些职责。Decorator类,就是装饰的抽象类,继承了Component,从外类来扩展Component类的功能。ConcreteDecoratorA和ConcreteDecoratorB则是具体的装饰类,负责实现具体的装饰职责的实现。下面来看看分词模块的整个类的结构图:
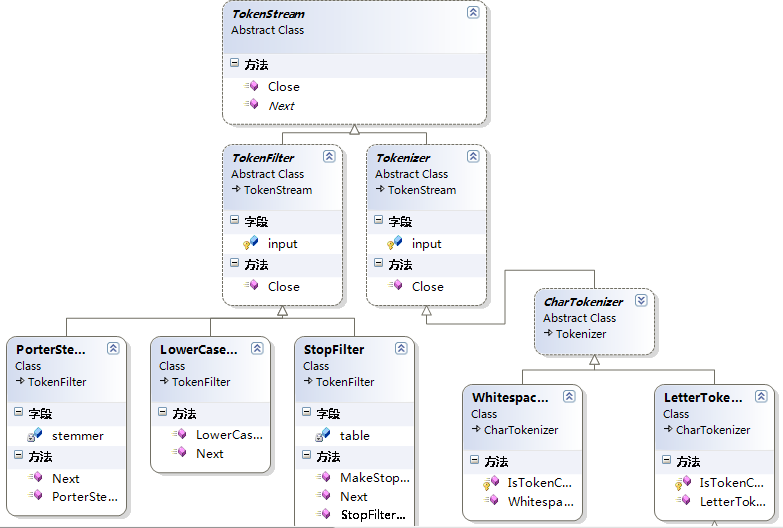
我们可以看到,是不是和上面的装饰者模式的结构图一样。TokenStream是一个抽象类,我们姑且把它理解为上面的对象接口(抽象类与接口的区别网上有很多资料),与Component对应。Tokenizer就是我们的具体对象类,其实这里与上面还是有一点区别的,那就是Tokenizer其实并不是具体的对象类,它也是一个抽象的类,真正具体的对象类是Tokenizer的子类CharTokenizer以及CharTokenizer的子类WhitespaceTokenizer和LetterTokenizer,这三个类实现了TokenStream定义的虚方法,并进行了一些扩充。它们就是具体的对象类。而TokenFilter则是装饰的抽象类,相当于上面的Decorator,它也是继承于TokenStream类。它的三个子类PorterStemFilter,LowerCaseFilter以及StopFilter就是具体的三个装饰者类,这三个类是来修饰Tokenizer的子类的。
我们来看CharTokenizer这个子类,它的作用是把语汇单元流以非英文字符来划分成一个个的Token。它并没有对Token进行一些处理,比如我们现在要把这些Token里面的字母都变成小写,提取它们的词干,然后再去掉停词,怎么办呢,按照我们前面的理解,这些就是想为对象增加一些额外的职责,那么我们可以用装饰者模式来实现,刚才说的三个功能,我们不用在CharTokenizer这个类里面实现它们。我们分别用三个装饰者类来实现这三个功能,也就是PorterStemFilter,LowerCaseFilter以及StopFilter这三个类,上图可能看不出来,实际上这三个类的构造函数都会接收一个TokenStream类型的参数,而CharTokenizer类也是从TokenStream类继承而来的,所以我们就明白,当我们创建了一个CharTokenizer类的对象后,我们可以把这个对象传递给前面所说的三个装饰者类,然后在三个不同的装饰者类里面去实现不同的额外的职责。前面我们说过,其实这些额外的职责也可以在具体对象类的子类里面实现,只不过这样不太灵活,或者说增加了复杂性,在这里我们可以看到,分词器模块里面兼顾了这两种实现方式,比如把Token变为小写这个功能,它用了一个装饰者类LowerCaseFilter类来实现,但同时它也用了一个子类来实现,也就是LowerCaseTokenizer(在上图没有显示,它是LetterTokenizer的一个子类),所以CharTokenizer类与LowerCaseFilter类共同作用的效果与LowerCaseTokenizer类的作用是一样的,只不过一个是通过装饰者模式实现的,另外一个是通过在子类里面实现的。
在分词模块里面,总共有四个分词器,分别是SimplyAnalyzer,WhiteSpaceAnalyzer,StopAnalyzer以及StandardAnalyzer分词器。其实这四个分词器就是把不同的对象与不同的装饰者类组合而成的,我们可以看代码。
SimplyAnalyzer里的代码:
[code]public class SimpleAnalyzer : Analyzer
{/// <summary>
/// Creates a TokenStream which tokenizes all the text in the provided Reader.
/// </summary>
public override TokenStream TokenStream(String fieldName, TextReader reader)
{return new LowerCaseTokenizer(reader);
}
}
[/code]
我们可以看到SimplyAnalyzer分词器里面只是构建了一个LowerCaseTokenizer类,也就是SimplyAnalyzer器是按非英文字母字符划分Token,并把每一个Token变成小写的。再来看WhitespaceAnalyzer的代码:
[code]public class WhitespaceAnalyzer : Analyzer
{/// <summary>
/// Creates a TokenStream which tokenizes all the text in the provided TextReader.
/// </summary>
public override TokenStream TokenStream(String fieldName, TextReader reader)
{return new WhitespaceTokenizer(reader);
}
}
[/code]
我们可以看到WhitespaceAnalyzer分词器里面只是构建了一个WhitespaceTokenizer类。我们再看StopAnalyzer类,我们只看里面的一个方法:
[code]public override TokenStream TokenStream(string fieldName, TextReader reader)
{return new StopFilter(new LowerCaseTokenizer(reader), stopTable);
}
[/code]
这里我们可以看到,首先创建了一个LowerCaseTokenizer,然后把这个类传递给了StopFilter这个装饰者类,它首先是按非英文字母来划分Token,然后转化成小写。但是它还需要完成一个额外的功能,那就是去掉停词。而StopFilter这个装饰者类的作用就是去掉停词,我们知道所有的装饰者类的构造函数中都接收一个TokenSteam类的对象,而LowerCaseTokenizer是继承自TokenStream,所以我们可以直接把LowerCaseTokenizer类的对象传递给StopFilter这个装饰者类,让这个装饰者类去实现去掉停词的功能。
如果上面的还不够明显,我们接下来来看StandardAnalyzer类的代码:
[code]public override TokenStream TokenStream(String fieldName, TextReader reader)
{TokenStream result = new StandardTokenizer(reader);
result = new StandardFilter(result);
result = new LowerCaseFilter(result);
result = new StopFilter(result, stopTable);
return result;
}
[/code]
通过上面的代码,我们可以清楚的看到,StandardAnalyzer类首先是创建一个StandardTokenizer对象,然后用了三个装饰者类去装饰这个对象,为这个对象添加了三个额外的功能。在这里,我们就可以非常明显的看到装饰者模式的好处。它可以有效的把类的核心职责与装饰功能分开,这样不但减少了类的复杂性,也使得每个类的职责单一,同时也比较灵活,我们如果需要不同的功能,我们就可以去实现不同的装饰者类,然后用这些装饰者类去装饰这个对象,还有一个好处就是,我可以任意调整装饰的顺序。
上面的仅仅是NLucene的代码,其实在Lucene后来的.net版本Lucene.net里面,还增加了许多分词的类,实现了一些更复杂的分词方法,同时也加入了一些简单的中文分词类,它们全部是在装饰者模式的基础上进行扩充的,不管多复杂的分词器,它都是由一些基础的对象类和一些装饰类组合而成的。通过装饰者模式,我们可以任意的扩充装饰者类,从而可以定制自己的分词器,非常的灵活,这也是装饰者模式的优点。

相关文章推荐
- 开源搜索框架Lucene学习之分词器(3)——通过分词器源码学习抽象方法与虚方法的区别
- 开源搜索框架Lucene学习之分词器(2)——TokenFilter类及其子类
- lua开源测试框架busted源码学习(三)--中介者模式mediator.lua
- 开源搜索框架Lucene学习系列
- 装饰者模式的学习(c#) EF SaveChanges() 报错(转载) C# 四舍五入 保留两位小数(转载) DataGridView样式生成器使用说明 MSSQL如何将查询结果拼接成字符串 快递查询 C# 通过smtp直接发送邮件 C# 带参访问接口,WebClient方式 C# 发送手机短信 文件 日志 写入 与读取
- [search engine] 开源搜索框架 Lucene.net
- 13、学习Lucene3.5索引之通过TokenStream显示分词
- 开源源码搜索+读书学习
- lua开源测试框架busted源码学习(二)--代码框架分析和用例执行流程
- 通过学习spring优秀框架来学习设计模式---单例、工厂
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
- 几个c源码学习开源框架
- DDPush开源推送框架源码分析之Client到DDPush(UDP模式)
- lua开源测试框架busted源码学习(-)----outputHandlers模块
- 开源中国源码学习数据篇(一)之android-async-http框架和AsyncTask
- 如何跟踪学习开源框架的源码
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
- android开源框架学习---EventBus---源码分析
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
- 如何去阅读并学习一些优秀的开源框架的源码?