第二章:分析基本查询的图形执行计划
2011-12-12 15:48
316 查看
本章的目的是让您能够解释简单的图形执行计划,换言之,简单的SELECT、UPDATE、INSERT或DELETE查询的执行计划是指那些少数连接或没有高级功能或提示的查询。为此,我们将介绍下列图形计划中的主题:
1.运算符2.连接
3.WHERE从句
4.聚合
5.INSERT、UPDATE、DELETE执行计划
图形执行计划语言
从某种程度上,学习图形执行计划与学习新的语言类似,唯一不同的是:图形执行计划语言是基于图标,每个图标代表着特定的运算符,本章我们就用“图标”和“运算符”术语。上一章中,我们只介绍了两个运算符(SELECT和表扫描),不过,这仅是79个运算符的其中两个,当然,我们也不用记住这79个运算符;多数查询仅使用一小部分的图标,这些也是我们本章打算介绍的。如果您遇到这里未提及的,可以从联机丛书中获取更详细的信息。
下面列出了四种类型不同的运算符:
l 逻辑和物理运算符:也叫迭代器,通常以蓝色图标显示,表示查询执行或DML语句
l 并行物理运算符:也以蓝色图标显示,用于表示并行操作;基本上,它们是逻辑和物理运算符的子集,由于其需要不同程度的执行分析也需要分别考虑。
l 游标运算符:以黄色图标显示,表示T-SQL游标操作
l 语言元素:以绿色图标显示,表示T-SQL语言元素,如Assign、Declare、If、Select(Result)、While等等
本章我们主要介绍逻辑和物理运算符,包括并行物理运算符。联机丛书以字母的顺序的显示,显然不适用于学习,这里我们仅介绍最常用的那些运算符,当然,最常用的这些运算符因DBA的不同而不同,所以下面我就最常用的运算符加以介绍,以从左到右和从上至下的顺序。
| Select (Result) | Sort | Clustered Index Seek | Clustered Index Scan | Non-clustered Index Scan |
| Non-clustered Index Seek | Table Scan | RID Lookup | Key Lookup | Hash Match |
| Nested Loops | Merge Join | Top | Compute Scalar | Constant Scan |
| Filter | Lazy Spool | Spool | Eager Spool | Stream Aggregate |
| Distribute Streams | Repartition Streams | Gather Streams | Bitmap | Split |
运算符的行为是值得理解的,一些运算符如排序Sort、哈希匹配(聚合)hash match(aggregate)和哈希连接hash join需要一定量的内存才可以执行,正因这样,含有上述运算符的查询执行前需要有可用的内存来支持,这可能会造成性能的影响。多数运算符的工作方式表现为两种:non-blocking和blocking。Non-blocking运算符在接收到输入的同时也创建了输出数据,而blocking运算符在创建输出数据之前需要获得所有数据,blocking运算可能导致并发问题出现,影响性能。
单表查询 我们先看一些基于简单表查询的简单计划。
[b]聚集索引扫描(Clustered Index Scan)[/b]

考虑下面的简单查询:
[code] Use AdventureWorks
Go
SELECT *
FROM Person.Contact
GO
[/code]
以下是实际的执行计划:
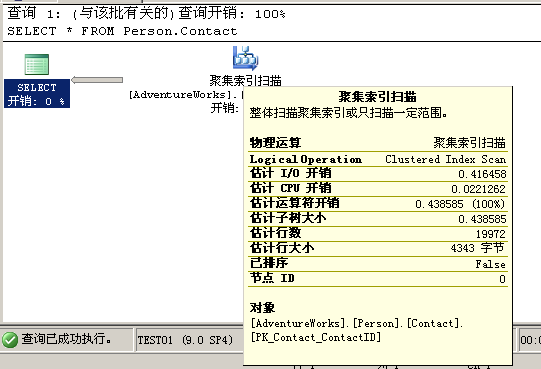
从图中可以知道,使用了“聚集索引扫描”来获取数据,如果将鼠标指针放到“聚集索引扫描”图标,会出现“工具提示”窗口,在窗口中,可以看到使用的聚集索引是PK_Contact_ContactID和估计的行数19972。
在SQL Server中,索引以B树的形式存储,聚集索引不仅存储了键结构也对数据进行排序并进行存储,这也是每个表仅有一个聚集索引的原因所在。
同样,聚集索引扫描的概念等于同表扫描,为找到所需数据,需要以逐行扫描的方式来扫描整个索引树。
索引扫描经常发生,尤其在本例也如此,当存在索引并且优化器判定返回的数据之多,显然扫描索引中的值要快于使用索引中提供的键值。
若您在执行计划中看到“索引扫描”,可能要问的一个问题是:是否有必要返回大量数据?若返回的数据超过预期,那就需要对您的查询中WHERE子句进行优化了,以便只返回需要的数据。返回不必要的数据不仅耗费SQL Server的资源,也对整体性能有所损伤。
[b]聚集索引查找(Clustered Index Seek)[/b]

在上面的查询中添加一个WHERE子句:
[code]SELECT *
FROM Person.Contact
WHERE ContactID =1
[/code]
现在再运行查看其执行计划,如下图所示:
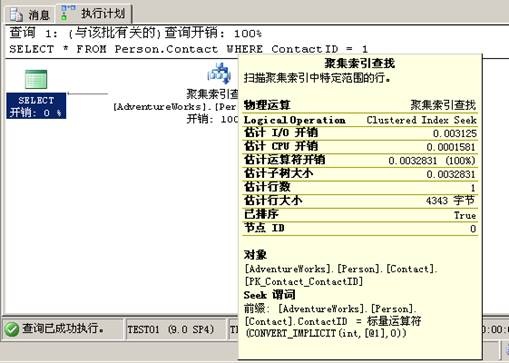
索引查找完全不同于“索引扫描”(引擎逐行查找数据),当优化器能够通过索引来查找相应的记录时就会使用索引查找(不论聚集索引与否),因此,优化器告诉存储引擎通过索引提供的键值来查找记录。
当索引用于查找操作时,其键值用于快速定位需要的数据行或记录,这有点类似于查询书本索引的关键字一样去得到正确的页号。
在上面的例子,针对Person.Contact表使用了“聚集索引查找”运算,注意到PK_Contact_ContactID既是主键又是聚集索引,此外,在聚集索引查找的“工具提示”窗口中“已排序”属性现在为“True”,说明数据是排过序的。
[b]非聚集索引查找(Non-clustered Index Seek)[/b]

再对WHERE条件做一下修改:
[code] SELECT ContactID
FROM Person.Contact
WHERE EmailAddress LIKE 'sab%'
[/code]
再次运行,其执行计划如下:
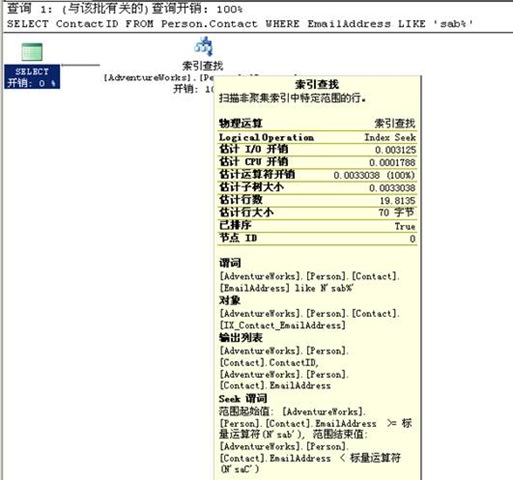
从“工具提示”窗口看出,使用了非聚集索引,IX_Contact_EmailAddress。
注意:聚集索引查找图标被误标记为“索引查找”,明显地,这是一个错误,希望可以得到修复,不论怎样,对于您知道这一点就行。
与“聚集索引查找”一样,非聚集索引查找使用索引来查询记录,不同的是:非聚集查找需要使用“非聚集索引”来执行该操作,取决于查询和索引,查询优化器可能要找出非聚集索引中的所有数据或者需要查询聚集索引中的数据,由于需要额外的I/O操作来执行额外的查询,因此对性能有所影响。
键查询(KEY LOOKUP)

我们再对先前的查询稍做修改,如下所示:
[code] SELECT ContactID,
LastName,
Phone
FROM Person.Contact
WHERE EmailAddress LIKE 'sab%'
[/code]
执行计划如下:

从上图的执行计划可以看出,与先前的操作相比,多了一个操作(键查找),按照“从右至左,从上至下”的顺序分析执行计划,第一个操作是使用了IX_Contact_EmailAddress索引的索引查找,此索引是非唯一且非聚集索引,显然它是未覆盖的,“未覆盖non-convering”索引是一种并不包含在查询中返回所需列的索引,它使查询优化器不仅需要读取索引页,也需要通过“聚集索引”来获取可能需要返回的数据信息。
参考“索引查找”的“工具提示”窗口的输出列也可以看到,只显示了“EmailAddress”和“ContactID”列,如下所示:

然后,这些键值将用于在“PK_Contact_ContactID”聚集索引中所使用的“键查询(Key Lookup)”来查找对应的记录,从而找到“LastName”和“Phone”列,如下所示:
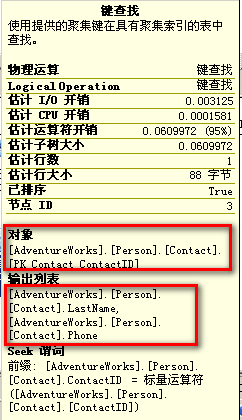
“键查询(Key lookup)”也称为“书签查询”,基本上,优化器不能一次获取记录数据,需要使用“聚集键”或“行ID”来顺着“聚集索引”或表来查询对应的数据。
“键查询”也暗指可以借助于“覆盖索引”或“Included”索引技术来提升性能,这两种技术都包含查询引用的字段信息,因此每行的字段信息都可以通过该索引找到,就不需要额外的“键查询”操作,从而得到所有需要的数据信息;另外,“键查询”通常与“嵌套循环连接(Nested Loop Join)”操作配合完成。
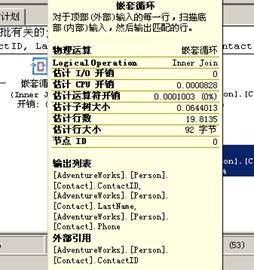
通常,“嵌套循环连接”是一种没有性能影响的标准连接,在这种情况下,需要使用“键查询”操作,“嵌套循环连接”需要合并“索引查找”和“键查询”的记录行信息;若不采用“键查询”(存在覆盖索引),则也无需“嵌套循环”运算。
[b]表扫描[/b]

从字面上讲,表扫描易懂,在第一章我们就有介绍,它表示需要逐行扫描整张表来返回所需要的数据。通过下面简单的查询来理解“表扫描”运算:
[code]SELECT *
FROM dbo.DatabaseLog
[/code]
查询执行计划如下:
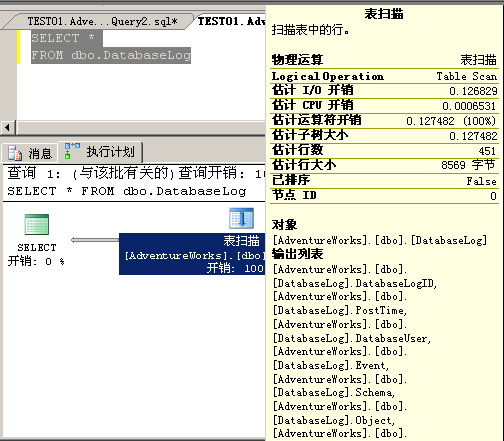
发生“表扫描”有多种原因,不过,通常是由于表中没有可用的索引,查询优化器需要遍历每一行来查找要返回的数据行;另外一种情况是当返回表中所有数据行时(以本例而言)。当返回表的所有行信息,不论存在索引与否,扫描每一行要比查询索引行快得多(仅适用于表中的数据很少的情况)。
假如表中的记录行相当少,表扫描显然不是问题,换言之,要是表很大,需要返回很多数据,那你就需要重写查询来返回较少的行或者使用索引来提升性能。
RID查询

如果在先前的DatabaseLog查询中进行对主键进行条件过滤,我们将会看到使用“索引查找”和“RID查询”
[code]SELECT *
FROM dbo.DatabaseLog
WHERE DatabaseLogID = 1
[/code]

在本例,查询优化器首先在主键上执行一个“索引查找”操作,而这个索引符合WHERE子句标准,索引并不包括所有必需的列,我们如何知道的?
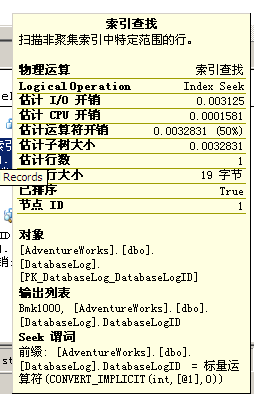
从上图可以看出,在输出列表中有一个叫做“Bmk1000”,该列告诉我们这样一点,实际上“索引查找”是包含“书签查询”的计划的一部分,接着,查询优化器需要执行RID查询(书签查询发生在heap表,即表中不存在聚集索引)使用“行标识符”来查找数据行。按句话说,由于表没有聚集索引,需要使用指向heap的行标识符,这显然增加了额外的磁盘I/O操作。

从上图可以发现,“Bmk1000”再次使用,这次是以“Seek 谓词”的形式出现,意在说明书签查询用于查询计划的一部分,在本例,由于查找的只有一行,从性能的角度看并不存在性能问题,但是若返回许多数据行,则需要认真对待,并分析一下如何降低磁盘I/O的操作来提升性能,或者通过重写查询、添加聚集索引、覆盖索引或Included索引技术来提升性能。

相关文章推荐
- 第二章:分析基本查询的图形执行计划
- 第二章:分析基本查询的图形执行计划
- 续第二章:分析基本查询的图形执行计划--表连接
- 续第二章:分析基本查询的图形执行计划--表连接
- SQL执行计划解析(2)- 基本查询的图形执行计划(上)
- 第三章:分析基本查询的文本和XML执行计划
- 第三章:分析基本查询的文本和XML执行计划
- SQL执行计划解析(2)- 基本查询的图形执行计划(中)
- 执行计划--常用的查询分析
- 如何使用SQLPLUS分析SQL语句(查询执行计划跟踪)
- Hive----查询执行计划(explain)和分析表数据(ANALYZE)
- 如何使用SQLPLUS分析SQL语句(查询执行计划跟踪)
- 左驱动非分区表数据量变化影响分区查询执行计划变形分析!
- 通过Explain查询和分析SQL的执行计划
- 优化 SQL Server 查询性能----分析执行计划,索引与索引视图,如何识别要优化的查询
- 高性能可扩展mysql(执行计划,索引分析优化改写,删除重复数据,区间统计,满查询日志)
- 如何使用SQLPLUS分析SQL语句(查询执行计划跟踪)
- 优化 SQL Server 查询性能----分析执行计划,索引与索引视图,如何识别要优化的查询
- oracle数据库执行计划统计分析,优化表数据字典,提高sql查询效率
- SQLServer查询执行计划分析 - 案例