随机取数据算法性能比较
2011-11-21 11:23
267 查看
您有在工作中有类似这样的需求吗:从10万条不重复的数据中随机取出1千条不重复的数据?这里我们通过几种方法来实现此需求,并对每种方法进行性能比较,然后得出较优的方案,如果您有更优的方案,欢迎分享。
初始化数据:
第一种方案:使用LINQ获取随机数用Guid排序
第二种方案:Linq获取随机数,使用int作为排序字段
第三种方案: 模拟LINQ获取随机数,使用int作为排序字段
第四种方案:通过移动数组下标,获取前getCount数量的随机数
F5运行,输出如下:

Ctrl+F5运行,输出如下:

当我们修改循环次数为10次和输入数量变为10000时,看一下效果:
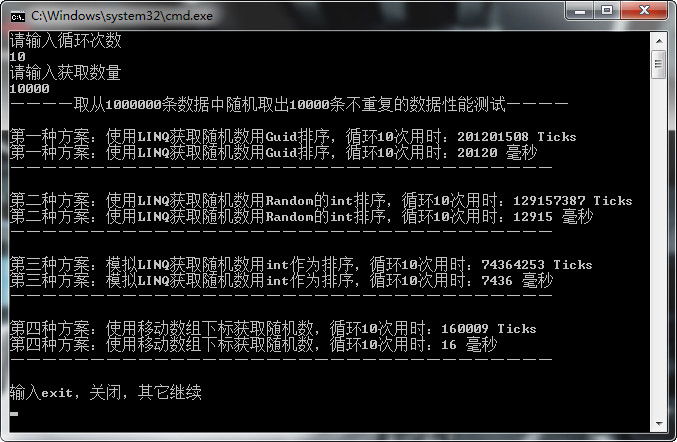
综述:从以上可以看出,Ctrl+F5会比F5下性能高,第一种方案:使用LINQ获取随机数用Guid排序性能 < 第二种方案:使用LINQ获取随机数用Random的int排序性能 < 第三种方案:模拟LINQ获取随机数用int作为排序性能 < 第四种方案:使用移动数组下标获取随机数。而且【第四种方案:使用移动数组下标获取随机数】性能会远远优于其它三种方案。如果您有更优的方案,欢迎分享,谢谢!~
感谢:LQ和LKX两位同事在此问题上进行的讨论与贡献!~
点击下载DEMO。
初始化数据:
//最大值
const int maxValue = 1000000;
//循环次数
int cycleCount = 1;
//获取数量
int getCount = 1000;
int[] iAry = new int[maxValue];
for (int i = 0; i < maxValue; ++i)
{
iAry[i] = i;
}
Random random = new Random();第一种方案:使用LINQ获取随机数用Guid排序
/// <summary>
/// Linq获取随机数,使用Guid作为排序字段
/// </summary>
/// <param name="iAry">已初始化好的数据</param>
/// <param name="getCount">需要获取的数量</param>
private static int[] LinqGetRandomUseGuidSort(int[] iAry, int getCount)
{
var iResult = (from p in iAry select p).OrderBy(e => Guid.NewGuid()).Take(getCount);
//LINQ的延迟执行,所以到必须到这步才能出真正的执行时间
var list = iResult.ToArray<int>();
return list;
}第二种方案:Linq获取随机数,使用int作为排序字段
/// <summary>
/// Linq获取随机数,使用int作为排序字段
/// </summary>
/// <param name="iAry">已初始化好的数据</param>
/// <param name="random">随机对象</param>
/// <param name="maxValue">最大数量</param>
/// <param name="getCount">需要获取的数量</param>
private static int[] LinqGetRandomUseRandomSort(int[] iAry, Random random, int maxValue, int getCount)
{
var iResult = (from p in iAry select p).OrderBy(e => random.Next(0, maxValue)).Take(getCount);
//LINQ的延迟执行,所以到必须到这步才能出真正的执行时间
var list = iResult.ToArray<int>();
return list;
}第三种方案: 模拟LINQ获取随机数,使用int作为排序字段
public struct Item
{
public int Key;
public int Value;
}
public class ItemComparer : IComparer<Item>
{
public int Compare(Item x, Item y)
{
return x.Key - y.Key;
}
}
/// <summary>
/// 模拟LINQ获取随机数,使用int作为排序字段
/// </summary>
/// <param name="iAry">已初始化好的数据</param>
/// <param name="random">随机对象</param>
/// <param name="maxValue">最大数量</param>
/// <param name="getCount">需要获取的数量</param>
/// <returns></returns>
private static int[] ArrayGetRandomUseRandomSort(int[] iAry, Random random, int maxValue, int getCount)
{
Item[] ary = new Item[maxValue];
for (int i = 0; i < maxValue; ++i)
{
ary[i] = new Item { Key = random.Next(0, maxValue), Value = i };
}
//LINQ内部是用的快速排序
Array.Sort(ary, new ItemComparer());
int[] tempAry = new int[getCount];
for (int j = 0; j < getCount; ++j)
{
tempAry[j] = ary[j].Value;
}
return tempAry;
}第四种方案:通过移动数组下标,获取前getCount数量的随机数
/// <summary>
/// 通过移动数据下标,获取前getCount数量的随机数
/// </summary>
/// <param name="iAry">已初始化好的数据</param>
/// <param name="random">随机对象</param>
/// <param name="maxValue">最大数量</param>
/// <param name="getCount">需要获取的数量</param>
private static int[] MoveArraySubscriptGetRandom(int[] iAry, Random random, int maxValue, int getCount)
{
//数组随机下标
int tempIndex = 0;
//当前得到的数量
int tempCount = 0;
//数组随机下标指向的数值
int tempValue = 0;
//当得到数量为getCount时跳出循环,那么数组的前getCount条数据就是要获取的随机值
while (tempCount < getCount)
{
//从当前得到的数量+1开始获取下标
tempIndex = random.Next(tempCount + 1, maxValue);
//把取到的值存入数组的前面位置
tempValue = iAry[tempIndex];
iAry[tempIndex] = iAry[tempCount];
iAry[tempCount] = tempValue;
tempCount += 1;
}
//返回数量为iAry的总数量,使用时只需使用前getCount条即可
return iAry;
}F5运行,输出如下:
Ctrl+F5运行,输出如下:
当我们修改循环次数为10次和输入数量变为10000时,看一下效果:
综述:从以上可以看出,Ctrl+F5会比F5下性能高,第一种方案:使用LINQ获取随机数用Guid排序性能 < 第二种方案:使用LINQ获取随机数用Random的int排序性能 < 第三种方案:模拟LINQ获取随机数用int作为排序性能 < 第四种方案:使用移动数组下标获取随机数。而且【第四种方案:使用移动数组下标获取随机数】性能会远远优于其它三种方案。如果您有更优的方案,欢迎分享,谢谢!~
感谢:LQ和LKX两位同事在此问题上进行的讨论与贡献!~
点击下载DEMO。
作者:心海巨澜 出处:http://xinhaijulan.cnblogs.com
版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

相关文章推荐
- 随机取数据算法性能比较
- 随机取数据算法性能比较
- 随机打乱一组数据(算法)
- 算法上级报告(渗透问题(Percolation),几种排序算法的实验性能比较,地图路由(Map Routing))
- 基本算法复习之排序:性能比较、代码分析
- 常用推荐算法性能比较
- ArcEngine数据删除几种方法和性能比较【转载】
- A*,Dijkstra,BFS算法性能比较及A*算法的应用
- Hadoop链式MapReduce、多维排序、倒排索引、自连接算法、二次排序、Join性能优化、处理员工信息Join实战、URL流量分析、TopN及其排序、求平均值和最大最小值、数据清洗ETL、分析气
- 针对特征词选择法的验证实验“各种特征词选择算法对文本分类性能的影响”:纸上得来终觉浅,觉知此事要躬行 (实验数据下载)
- 一之续、A*,Dijkstra,BFS算法性能比较及A*算法的应用
- 设定二维整数数组B[0..m-1,0..n-1]的数据在行,列方向上都按从小到大的顺序排序,且整形变量x中的数据在B中存在。设计一个算法,找出一对满足B[i][j]=x的I,j值,要求比较次数不超过m
- 关于要随机使用某些数据,有要均匀使用的算法
- 前台传来的新数据与数据库中的旧数据比较更新算法
- GDI+、FFMPEG图像放大算法性能比较
- 不同版本的SQL Server之间数据导出导入的方法及性能比较
- ArcEngine数据删除几种方法和性能比较
- HBase 高性能获取数据(多线程批量式解决办法) + MySQL和HBase性能测试比较
- Java不同压缩算法的性能比较
- oracle技术之oracle数据泵不同工作方式性能比较(五)