字符设备驱动程序 2
2011-08-23 00:17
218 查看
三、字符设备的注册
内核内部使用struct cdev结构来表示字符设备。在内核调用设备的操作之前,必须分配并注册一个或多个struct cdev。代码应包含<linux/cdev.h>,它定义了struct cdev以及与其相关的一些辅助函数。
注册一个独立的cdev设备的基本过程如下:
1、为struct cdev 分配空间(如果已经将struct cdev 嵌入到自己的设备的特定结构体中,并分配了空间,这步略过!)
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops=&my_ops;
2、初始化struct cdev
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
3、初始化cdev.owner
cdev.owner = THIS_MODULE;
4、cdev设置完成,通知内核struct cdev的信息(在执行这步之前必须确定你对struct cdev的以上设置已经完成!)
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
这里, dev 是 cdev 结构, num 是这个设备响应的第一个设备号, count 是应当关联到设备的设备号的数目. 常常 count 是 1, 但是有多个设备号对应于一个特定的设备的情形. 例如, 设想 SCSI 磁带驱动, 它允许用户空间来选择操作模式(例如密度), 通过安排多个次编号给每一个物理设备.
在使用 cdev_add 是有几个重要事情要记住. 第一个是这个调用可能失败. 如果它返回一个负的错误码, 你的设备没有增加到系统中. 它几乎会一直成功, 但是, 并且带起了其他的点: cdev_add 一返回, 你的设备就是"活的"并且内核可以调用它的操作. 除非你的驱动完全准备好处理设备上的操作, 你不应当调用 cdev_add.
5、从系统中移除一个字符设备:void cdev_del(struct cdev *p)
以下是scull中的初始化代码(之前已经为struct scull_dev 分配了空间):
老方法
如果你深入浏览 2.6 内核的大量驱动代码, 你可能注意到有许多字符驱动不使用我们刚刚描述过的 cdev 接口. 你见到的是还没有更新到 2.6 内核接口的老代码. 因为那个代码实际上能用, 这个更新可能很长时间不会发生. 为完整, 我们描述老的字符设备注册接口, 但是新代码不应当使用它; 这个机制在将来内核中可能会消失.
注册一个字符设备的经典方法是使用:
int register_chrdev(unsigned int major, const char *name, struct file_operations *fops);
这里, major 是感兴趣的主编号, name 是驱动的名子(出现在 /proc/devices), fops 是缺省的 file_operations 结构. 一个对 register_chrdev 的调用为给定的主编号注册 0 - 255 的次编号, 并且为每一个建立一个缺省的 cdev 结构. 使用这个接口的驱动必须准备好处理对所有 256 个次编号的 open 调用( 不管它们是否对应真实设备 ), 它们不能使用大于 255 的主或次编号.
如果你使用 register_chrdev, 从系统中去除你的设备的正确的函数是:
int unregister_chrdev(unsigned int major, const char *name);
major 和 name 必须和传递给 register_chrdev 的相同, 否则调用会失败.


四、scull模型的内存使用
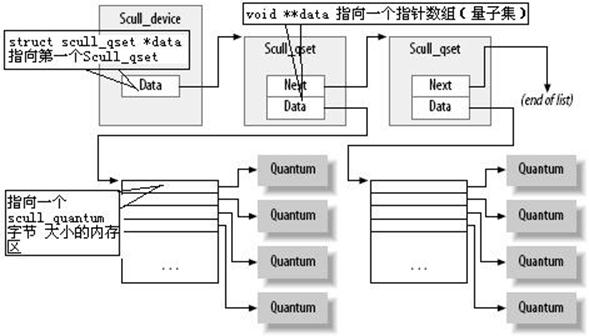
以下是scull模型的结构体:
scull驱动程序引入了两个Linux内核中用于内存管理的核心函数,它们的定义都在<linux/slab.h>:
以下是scull模块中的一个释放整个数据区的函数(类似清零),将在scull以写方式打开和scull_cleanup_module中被调用:
以下是scull模块中的一个沿链表前行得到正确scull_set指针的函数,将在read和write方法中被调用:
其实这个函数的实质是:如果已经存在这个scull_set,就返回这个scull_set的指针。如果不存在这个scull_set,一边沿链表为scull_set分配空间一边沿链表前行,直到所需要的scull_set被分配到空间并初始化为止,就返回这个scull_set的指针。


五、open和release
open方法提供给驱动程序以初始化的能力,为以后的操作作准备。应完成的工作如下:
(1)检查设备特定的错误(如设备未就绪或硬件问题);
(2)如果设备是首次打开,则对其进行初始化;
(3)如有必要,更新f_op指针;
(4)分配并填写置于filp->private_data里的数据结构。
int (*open)(struct inode *inode, struct file *filp);
inode 参数有我们需要的信息,以它的 i_cdev 成员的形式, 里面包含我们之前建立的 cdev 结构. 唯一的问题是通常我们不想要 cdev 结构本身, 我们需要的是包含 cdev 结构的 scull_dev 结构. C 语言使程序员玩弄各种技巧来做这种转换; 但是, 这种技巧编程是易出错的, 并且导致别人难于阅读和理解代码. 幸运的是, 在这种情况下, 内核 hacker 已经为我们实现了这个技巧, 以 container_of 宏的形式, 在 <linux/kernel.h> 中定义。
而根据scull的实际情况,他的open函数只要完成第四步(将初始化过的struct scull_dev dev的指针传递到filp->private_data里,以备后用)就好了,所以open函数很简单。但是其中用到了定义在<linux/kernel.h>中的container_of宏,源码如下:
其实从源码可以看出,其作用就是:通过指针ptr,获得包含ptr所指向数据(是member结构体)的type结构体的指针。即是用指针得到另外一个指针。
这个宏使用一个指向 container_field 类型的成员的指针, 它在一个 container_type 类型的结构中, 并且返回一个指针指向包含结构. 在 scull_open, 这个宏用来找到适当的设备结构:
struct scull_dev *dev; /* device information */ dev = container_of(inode->i_cdev, struct scull_dev, cdev); filp->private_data = dev; /* for other methods */
一旦它找到 scull_dev 结构, scull 在文件结构的 private_data 成员中存储一个它的指针, 为以后更易存取.
识别打开的设备的另外的方法是查看存储在 inode 结构的次编号. 如果你使用 register_chrdev 注册你的设备, 你必须使用这个技术. 确认使用 iminor 从 inode 结构中获取次编号, 并且确定它对应一个你的驱动真正准备好处理的设备.
scull_open 的代码(稍微简化过)是:
int scull_open(struct inode *inode, struct file *filp) {
struct scull_dev *dev; /* device information */
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev;/* for other methods */
/* now trim to 0 the length of the device if open was write-only */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) { scull_trim(dev); /* ignore errors */ } return 0; /* success */ }
release方法提供释放内存,关闭设备的功能。应完成的工作如下:
(1)释放由open分配的、保存在file->private_data中的所有内容;
(2)在最后一次关闭操作时关闭设备。
由于前面定义了scull是一个全局且持久的内存区,所以他的release什么都不做。
int scull_release(struct inode *inode, struct file *filp) { return 0; }


六、read和write
read和write方法的主要作用就是实现内核与用户空间之间的数据拷贝。
ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);
对于 2 个方法, filp 是文件指针, count 是请求的传输数据大小. buff 参数指向持有被写入数据的缓存, 或者放入新数据的空缓存. 最后, offp 是一个指针指向一个"long offset type"对象, 它指出用户正在存取的文件位置. 返回值是一个"signed size type"; 它的使用在后面讨论.
让我们重复一下, read 和 write 方法的 buff 参数是用户空间指针. 因此, 它不能被内核代码直接解引用.这个限制有几个理由:
依赖于你的驱动运行的体系, 以及内核被如何配置的, 用户空间指针当运行于内核模式可能根本是无效的. 可能没有那个地址的映射, 或者它可能指向一些其他的随机数据.
就算这个指针在内核空间是同样的东西, 用户空间内存是分页的, 在做系统调用时这个内存可能没有在 RAM 中. 试图直接引用用户空间内存可能产生一个页面错, 这是内核代码不允许做的事情. 结果可能是一个"oops", 导致进行系统调用的进程死亡.
置疑中的指针由一个用户程序提供, 它可能是错误的或者恶意的. 如果你的驱动盲目地解引用一个用户提供的指针, 它提供了一个打开的门路使用户空间程序存取或覆盖系统任何地方的内存. 如果你不想负责你的用户的系统的安全危险, 你就不能直接解引用用户空间指针.
因为Linux的内核空间和用户空间隔离的,所以要实现数据拷贝就必须使用在<asm/uaccess.h>中定义的:
而值得一提的是以上两个函数和
之间的关系:通过源码可知,前者调用后者,但前者在调用前对用户空间指针进行了检查。
这 2 个函数的角色不限于拷贝数据到和从用户空间: 它们还检查用户空间指针是否有效. 如果指针无效, 不进行拷贝; 如果在拷贝中遇到一个无效地址, 另一方面, 只拷贝部分数据. 在 2 种情况下, 返回值是还要拷贝的数据量. scull 代码查看这个错误返回, 并且如果它不是 0 就返回 -EFAULT 给用户.
至于实际的设备方法, read 方法的任务是从设备拷贝数据到用户空间(使用 copy_to_user), 而 write 方法必须从用户空间拷贝数据到设备(使用 copy_from_user). 每个 read 或 write 系统调用请求一个特定数目字节的传送, 但是驱动可自由传送较少数据 -- 对读和写这确切的规则稍微不同, 在本章后面描述.
不管这些方法传送多少数据, 它们通常应当更新 *offp 中的文件位置来表示在系统调用成功完成后当前的文件位置. 内核接着在适当时候传播文件位置的改变到文件结构. pread 和 pwrite 系统调用有不同的语义; 它们从一个给定的文件偏移操作, 并且不改变其他的系统调用看到的文件位置. 这些调用传递一个指向用户提供的位置的指针, 并且放弃你的驱动所做的改变.
read方法
read 的返回值由调用的应用程序解释:
如果这个值等于传递给 read 系统调用的 count 参数, 请求的字节数已经被传送. 这是最好的情况.
如果是正数, 但是小于 count, 只有部分数据被传送. 这可能由于几个原因, 依赖于设备. 常常, 应用程序重新试着读取. 例如, 如果你使用 fread 函数来读取, 库函数重新发出系统调用直到请求的数据传送完成.
如果值为 0, 到达了文件末尾(没有读取数据).
一个负值表示有一个错误. 这个值指出了什么错误, 根据 <linux/errno.h>. 出错的典型返回值包括 -EINTR( 被打断的系统调用) 或者 -EFAULT( 坏地址 ).
前面列表中漏掉的是这种情况"没有数据, 但是可能后来到达". 在这种情况下, read 系统调用应当阻塞.
ssize_t scull_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr; /* the first listitem */
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset; /* how many bytes in the listitem */
int item, s_pos, q_pos, rest;
ssize_t retval = 0;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
if (*f_pos >= dev->size)
goto out;
if (*f_pos + count > dev->size)
count = dev->size - *f_pos;
/* find listitem, qset index, and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position (defined elsewhere) */
dptr = scull_follow(dev, item);
if (dptr == NULL || !dptr->data || ! dptr->data[s_pos])
goto out; /* don't fill holes */
/* read only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_to_user(buf, dptr->data[s_pos] + q_pos, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
out:
up(&dev->sem);
return retval;
}
write, 象 read, 可以传送少于要求的数据, 根据返回值的下列规则:
如果值等于 count, 要求的字节数已被传送.
如果正值, 但是小于 count, 只有部分数据被传送. 程序最可能重试写入剩下的数据.
如果值为 0, 什么没有写. 这个结果不是一个错误, 没有理由返回一个错误码. 再一次, 标准库重试写调用. 我们将在第 6 章查看这种情况的确切含义, 那里介绍了阻塞.
一个负值表示发生一个错误; 如同对于读, 有效的错误值是定义于 <linux/errno.h>中.
不幸的是, 仍然可能有发出错误消息的不当行为程序, 它在进行了部分传送时终止. 这是因为一些程序员习惯看写调用要么完全失败要么完全成功, 这实际上是大部分时间的情况, 应当也被设备支持. scull 实现的这个限制可以修改, 但是我们不想使代码不必要地复杂.
write 的 scull 代码一次处理单个量子, 如 read 方法做的:
ssize_t scull_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr;
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset;
int item, s_pos, q_pos, rest;
ssize_t retval = -ENOMEM; /* value used in "goto out" statements */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* find listitem, qset index and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position */
dptr = scull_follow(dev, item);
if (dptr == NULL)
goto out;
if (!dptr->data)
{
dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL);
if (!dptr->data)
goto out;
memset(dptr->data, 0, qset * sizeof(char *));
}
if (!dptr->data[s_pos])
{
dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL);
if (!dptr->data[s_pos])
goto out;
}
/* write only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_from_user(dptr->data[s_pos]+q_pos, buf, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
/* update the size */
if (dev->size < *f_pos)
dev->size = *f_pos;
out:
up(&dev->sem);
return retval;
}
readv 和 writev
Unix 系统已经长时间支持名为 readv 和 writev 的 2 个系统调用. 这些 read 和 write 的"矢量"版本使用一个结构数组, 每个包含一个缓存的指针和一个长度值. 一个 readv 调用被期望来轮流读取指示的数量到每个缓存. 相反, writev 要收集每个缓存的内容到一起并且作为单个写操作送出它们.
如果你的驱动不提供方法来处理矢量操作, readv 和 writev 由多次调用你的 read 和 write 方法来实现. 在许多情况, 但是, 直接实现 readv 和 writev 能获得更大的效率.
矢量操作的原型是:
ssize_t (*readv) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
ssize_t (*writev) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
这里, filp 和 ppos 参数与 read 和 write 的相同. iovec 结构, 定义于 <linux/uio.h>, 如同:
struct iovec
{
void __user *iov_base; __kernel_size_t iov_len;
};
每个 iovec 描述了一块要传送的数据; 它开始于 iov_base (在用户空间)并且有 iov_len 字节长. count 参数告诉有多少 iovec 结构. 这些结构由应用程序创建, 但是内核在调用驱动之前拷贝它们到内核空间.
矢量操作的最简单实现是一个直接的循环, 只是传递出去每个 iovec 的地址和长度给驱动的 read 和 write 函数. 然而, 有效的和正确的行为常常需要驱动更聪明. 例如, 一个磁带驱动上的 writev 应当将全部 iovec 结构中的内容作为磁带上的单个记录.
很多驱动, 但是, 没有从自己实现这些方法中获益. 因此, scull 省略它们. 内核使用 read 和 write 来模拟它们, 最终结果是相同的.


七、模块实验
这次模块实验的使用是友善之臂SBC2440V4,使用Linux2.6.22.2内核。
模块程序链接:
scull模块源程序
模块测试程序链接:模块测试程序
测试结果:
实验不仅测试了模块的读写能力,还测试了量子读写是否有效。
内核内部使用struct cdev结构来表示字符设备。在内核调用设备的操作之前,必须分配并注册一个或多个struct cdev。代码应包含<linux/cdev.h>,它定义了struct cdev以及与其相关的一些辅助函数。
注册一个独立的cdev设备的基本过程如下:
1、为struct cdev 分配空间(如果已经将struct cdev 嵌入到自己的设备的特定结构体中,并分配了空间,这步略过!)
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops=&my_ops;
2、初始化struct cdev
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
3、初始化cdev.owner
cdev.owner = THIS_MODULE;
4、cdev设置完成,通知内核struct cdev的信息(在执行这步之前必须确定你对struct cdev的以上设置已经完成!)
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
这里, dev 是 cdev 结构, num 是这个设备响应的第一个设备号, count 是应当关联到设备的设备号的数目. 常常 count 是 1, 但是有多个设备号对应于一个特定的设备的情形. 例如, 设想 SCSI 磁带驱动, 它允许用户空间来选择操作模式(例如密度), 通过安排多个次编号给每一个物理设备.
在使用 cdev_add 是有几个重要事情要记住. 第一个是这个调用可能失败. 如果它返回一个负的错误码, 你的设备没有增加到系统中. 它几乎会一直成功, 但是, 并且带起了其他的点: cdev_add 一返回, 你的设备就是"活的"并且内核可以调用它的操作. 除非你的驱动完全准备好处理设备上的操作, 你不应当调用 cdev_add.
5、从系统中移除一个字符设备:void cdev_del(struct cdev *p)
以下是scull中的初始化代码(之前已经为struct scull_dev 分配了空间):
| /* * Set up the char_dev structure for this device. */ static void scull_setup_cdev(struct scull_dev *dev, int index) { int err, devno = MKDEV(scull_major, scull_minor + index); cdev_init(&dev->cdev, &scull_fops); dev->cdev.owner = THIS_MODULE; dev->cdev.ops = &scull_fops; //这句可以省略,在cdev_init中已经做过 err = cdev_add (&dev->cdev, devno, 1); /* Fail gracefully if need be 这步值得注意*/ if (err) printk(KERN_NOTICE "Error %d adding scull%d", err, index); } |
如果你深入浏览 2.6 内核的大量驱动代码, 你可能注意到有许多字符驱动不使用我们刚刚描述过的 cdev 接口. 你见到的是还没有更新到 2.6 内核接口的老代码. 因为那个代码实际上能用, 这个更新可能很长时间不会发生. 为完整, 我们描述老的字符设备注册接口, 但是新代码不应当使用它; 这个机制在将来内核中可能会消失.
注册一个字符设备的经典方法是使用:
int register_chrdev(unsigned int major, const char *name, struct file_operations *fops);
这里, major 是感兴趣的主编号, name 是驱动的名子(出现在 /proc/devices), fops 是缺省的 file_operations 结构. 一个对 register_chrdev 的调用为给定的主编号注册 0 - 255 的次编号, 并且为每一个建立一个缺省的 cdev 结构. 使用这个接口的驱动必须准备好处理对所有 256 个次编号的 open 调用( 不管它们是否对应真实设备 ), 它们不能使用大于 255 的主或次编号.
如果你使用 register_chrdev, 从系统中去除你的设备的正确的函数是:
int unregister_chrdev(unsigned int major, const char *name);
major 和 name 必须和传递给 register_chrdev 的相同, 否则调用会失败.
四、scull模型的内存使用
以下是scull模型的结构体:
| /* * Representation of scull quantum sets. */ struct scull_qset { void **data; struct scull_qset *next; }; struct scull_dev { struct scull_qset *data; /* Pointer to first quantum set */ int quantum; /* the current quantum size */ int qset; /* the current array size */ unsigned long size; /* amount of data stored here */ unsigned int access_key; /* used by sculluid and scullpriv */ struct semaphore sem; /* mutual exclusion semaphore */ struct cdev cdev; /* Char device structure */ }; |
| void *kmalloc(size_t size, int flags); void kfree(void *ptr); |
| int scull_trim(struct scull_dev *dev) { struct scull_qset *next, *dptr; int qset = dev->qset; /* 量子集中量子的个数*/ int i; for (dptr = dev->data; dptr; dptr = next) { /* 循环scull_set个数次,直到dptr为NULL为止。*/ if (dptr->data) { for (i = 0; i < qset; i++)/* 循环一个量子集中量子的个数次*/ kfree(dptr->data[i]);/* 释放其中一个量子的空间*/ kfree(dptr->data);/* 释放当前的scull_set的量子集的空间*/ dptr->data = NULL;/* 释放一个scull_set中的void **data指针*/ } next = dptr->next; /* 准备下个scull_set的指针*/ kfree(dptr);/* 释放当前的scull_set*/ } dev->size = 0; /* 当前的scull_device所存的数据为0字节*/ dev->quantum = scull_quantum;/* 初始化一个量子的大小*/ dev->qset = scull_qset;/* 初始化一个量子集中量子的个数*/ dev->data = NULL;/* 释放当前的scull_device的struct scull_qset *data指针*/ return 0; } |
| /*Follow the list*/ struct scull_qset *scull_follow(struct scull_dev *dev, int n) { struct scull_qset *qs = dev->data; /* Allocate first qset explicitly if need be */ if (! qs) { qs = dev->data = kmalloc(sizeof(struct scull_qset), GFP_KERNEL); if (qs == NULL) return NULL; /* Never mind */ memset(qs, 0, sizeof(struct scull_qset)); } /* Then follow the list */ while (n--) { if (!qs->next) { qs->next = kmalloc(sizeof(struct scull_qset), GFP_KERNEL); if (qs->next == NULL) return NULL; /* Never mind */ memset(qs->next, 0, sizeof(struct scull_qset)); } qs = qs->next; continue; } return qs; } |
五、open和release
open方法提供给驱动程序以初始化的能力,为以后的操作作准备。应完成的工作如下:
(1)检查设备特定的错误(如设备未就绪或硬件问题);
(2)如果设备是首次打开,则对其进行初始化;
(3)如有必要,更新f_op指针;
(4)分配并填写置于filp->private_data里的数据结构。
int (*open)(struct inode *inode, struct file *filp);
inode 参数有我们需要的信息,以它的 i_cdev 成员的形式, 里面包含我们之前建立的 cdev 结构. 唯一的问题是通常我们不想要 cdev 结构本身, 我们需要的是包含 cdev 结构的 scull_dev 结构. C 语言使程序员玩弄各种技巧来做这种转换; 但是, 这种技巧编程是易出错的, 并且导致别人难于阅读和理解代码. 幸运的是, 在这种情况下, 内核 hacker 已经为我们实现了这个技巧, 以 container_of 宏的形式, 在 <linux/kernel.h> 中定义。
而根据scull的实际情况,他的open函数只要完成第四步(将初始化过的struct scull_dev dev的指针传递到filp->private_data里,以备后用)就好了,所以open函数很简单。但是其中用到了定义在<linux/kernel.h>中的container_of宏,源码如下:
| #define container_of(ptr, type, member) ({ \ const typeof( ((type *)0)->member ) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type,member) );}) |
这个宏使用一个指向 container_field 类型的成员的指针, 它在一个 container_type 类型的结构中, 并且返回一个指针指向包含结构. 在 scull_open, 这个宏用来找到适当的设备结构:
struct scull_dev *dev; /* device information */ dev = container_of(inode->i_cdev, struct scull_dev, cdev); filp->private_data = dev; /* for other methods */
一旦它找到 scull_dev 结构, scull 在文件结构的 private_data 成员中存储一个它的指针, 为以后更易存取.
识别打开的设备的另外的方法是查看存储在 inode 结构的次编号. 如果你使用 register_chrdev 注册你的设备, 你必须使用这个技术. 确认使用 iminor 从 inode 结构中获取次编号, 并且确定它对应一个你的驱动真正准备好处理的设备.
scull_open 的代码(稍微简化过)是:
int scull_open(struct inode *inode, struct file *filp) {
struct scull_dev *dev; /* device information */
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev;/* for other methods */
/* now trim to 0 the length of the device if open was write-only */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) { scull_trim(dev); /* ignore errors */ } return 0; /* success */ }
release方法提供释放内存,关闭设备的功能。应完成的工作如下:
(1)释放由open分配的、保存在file->private_data中的所有内容;
(2)在最后一次关闭操作时关闭设备。
由于前面定义了scull是一个全局且持久的内存区,所以他的release什么都不做。
int scull_release(struct inode *inode, struct file *filp) { return 0; }
六、read和write
read和write方法的主要作用就是实现内核与用户空间之间的数据拷贝。
ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);
对于 2 个方法, filp 是文件指针, count 是请求的传输数据大小. buff 参数指向持有被写入数据的缓存, 或者放入新数据的空缓存. 最后, offp 是一个指针指向一个"long offset type"对象, 它指出用户正在存取的文件位置. 返回值是一个"signed size type"; 它的使用在后面讨论.
让我们重复一下, read 和 write 方法的 buff 参数是用户空间指针. 因此, 它不能被内核代码直接解引用.这个限制有几个理由:
依赖于你的驱动运行的体系, 以及内核被如何配置的, 用户空间指针当运行于内核模式可能根本是无效的. 可能没有那个地址的映射, 或者它可能指向一些其他的随机数据.
就算这个指针在内核空间是同样的东西, 用户空间内存是分页的, 在做系统调用时这个内存可能没有在 RAM 中. 试图直接引用用户空间内存可能产生一个页面错, 这是内核代码不允许做的事情. 结果可能是一个"oops", 导致进行系统调用的进程死亡.
置疑中的指针由一个用户程序提供, 它可能是错误的或者恶意的. 如果你的驱动盲目地解引用一个用户提供的指针, 它提供了一个打开的门路使用户空间程序存取或覆盖系统任何地方的内存. 如果你不想负责你的用户的系统的安全危险, 你就不能直接解引用用户空间指针.
因为Linux的内核空间和用户空间隔离的,所以要实现数据拷贝就必须使用在<asm/uaccess.h>中定义的:
| unsigned long copy_to_user(void __user *to, const void *from, unsigned long count); unsigned long copy_from_user(void *to, const void __user *from, unsigned long count); |
| #define __copy_from_user(to,from,n) (memcpy(to, (void __force *)from, n), 0) #define __copy_to_user(to,from,n) (memcpy((void __force *)to, from, n), 0) |
这 2 个函数的角色不限于拷贝数据到和从用户空间: 它们还检查用户空间指针是否有效. 如果指针无效, 不进行拷贝; 如果在拷贝中遇到一个无效地址, 另一方面, 只拷贝部分数据. 在 2 种情况下, 返回值是还要拷贝的数据量. scull 代码查看这个错误返回, 并且如果它不是 0 就返回 -EFAULT 给用户.
至于实际的设备方法, read 方法的任务是从设备拷贝数据到用户空间(使用 copy_to_user), 而 write 方法必须从用户空间拷贝数据到设备(使用 copy_from_user). 每个 read 或 write 系统调用请求一个特定数目字节的传送, 但是驱动可自由传送较少数据 -- 对读和写这确切的规则稍微不同, 在本章后面描述.
不管这些方法传送多少数据, 它们通常应当更新 *offp 中的文件位置来表示在系统调用成功完成后当前的文件位置. 内核接着在适当时候传播文件位置的改变到文件结构. pread 和 pwrite 系统调用有不同的语义; 它们从一个给定的文件偏移操作, 并且不改变其他的系统调用看到的文件位置. 这些调用传递一个指向用户提供的位置的指针, 并且放弃你的驱动所做的改变.
read方法
read 的返回值由调用的应用程序解释:
如果这个值等于传递给 read 系统调用的 count 参数, 请求的字节数已经被传送. 这是最好的情况.
如果是正数, 但是小于 count, 只有部分数据被传送. 这可能由于几个原因, 依赖于设备. 常常, 应用程序重新试着读取. 例如, 如果你使用 fread 函数来读取, 库函数重新发出系统调用直到请求的数据传送完成.
如果值为 0, 到达了文件末尾(没有读取数据).
一个负值表示有一个错误. 这个值指出了什么错误, 根据 <linux/errno.h>. 出错的典型返回值包括 -EINTR( 被打断的系统调用) 或者 -EFAULT( 坏地址 ).
前面列表中漏掉的是这种情况"没有数据, 但是可能后来到达". 在这种情况下, read 系统调用应当阻塞.
ssize_t scull_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr; /* the first listitem */
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset; /* how many bytes in the listitem */
int item, s_pos, q_pos, rest;
ssize_t retval = 0;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
if (*f_pos >= dev->size)
goto out;
if (*f_pos + count > dev->size)
count = dev->size - *f_pos;
/* find listitem, qset index, and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position (defined elsewhere) */
dptr = scull_follow(dev, item);
if (dptr == NULL || !dptr->data || ! dptr->data[s_pos])
goto out; /* don't fill holes */
/* read only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_to_user(buf, dptr->data[s_pos] + q_pos, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
out:
up(&dev->sem);
return retval;
}
write, 象 read, 可以传送少于要求的数据, 根据返回值的下列规则:
如果值等于 count, 要求的字节数已被传送.
如果正值, 但是小于 count, 只有部分数据被传送. 程序最可能重试写入剩下的数据.
如果值为 0, 什么没有写. 这个结果不是一个错误, 没有理由返回一个错误码. 再一次, 标准库重试写调用. 我们将在第 6 章查看这种情况的确切含义, 那里介绍了阻塞.
一个负值表示发生一个错误; 如同对于读, 有效的错误值是定义于 <linux/errno.h>中.
不幸的是, 仍然可能有发出错误消息的不当行为程序, 它在进行了部分传送时终止. 这是因为一些程序员习惯看写调用要么完全失败要么完全成功, 这实际上是大部分时间的情况, 应当也被设备支持. scull 实现的这个限制可以修改, 但是我们不想使代码不必要地复杂.
write 的 scull 代码一次处理单个量子, 如 read 方法做的:
ssize_t scull_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr;
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset;
int item, s_pos, q_pos, rest;
ssize_t retval = -ENOMEM; /* value used in "goto out" statements */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* find listitem, qset index and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position */
dptr = scull_follow(dev, item);
if (dptr == NULL)
goto out;
if (!dptr->data)
{
dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL);
if (!dptr->data)
goto out;
memset(dptr->data, 0, qset * sizeof(char *));
}
if (!dptr->data[s_pos])
{
dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL);
if (!dptr->data[s_pos])
goto out;
}
/* write only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_from_user(dptr->data[s_pos]+q_pos, buf, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
/* update the size */
if (dev->size < *f_pos)
dev->size = *f_pos;
out:
up(&dev->sem);
return retval;
}
readv 和 writev
Unix 系统已经长时间支持名为 readv 和 writev 的 2 个系统调用. 这些 read 和 write 的"矢量"版本使用一个结构数组, 每个包含一个缓存的指针和一个长度值. 一个 readv 调用被期望来轮流读取指示的数量到每个缓存. 相反, writev 要收集每个缓存的内容到一起并且作为单个写操作送出它们.
如果你的驱动不提供方法来处理矢量操作, readv 和 writev 由多次调用你的 read 和 write 方法来实现. 在许多情况, 但是, 直接实现 readv 和 writev 能获得更大的效率.
矢量操作的原型是:
ssize_t (*readv) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
ssize_t (*writev) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
这里, filp 和 ppos 参数与 read 和 write 的相同. iovec 结构, 定义于 <linux/uio.h>, 如同:
struct iovec
{
void __user *iov_base; __kernel_size_t iov_len;
};
每个 iovec 描述了一块要传送的数据; 它开始于 iov_base (在用户空间)并且有 iov_len 字节长. count 参数告诉有多少 iovec 结构. 这些结构由应用程序创建, 但是内核在调用驱动之前拷贝它们到内核空间.
矢量操作的最简单实现是一个直接的循环, 只是传递出去每个 iovec 的地址和长度给驱动的 read 和 write 函数. 然而, 有效的和正确的行为常常需要驱动更聪明. 例如, 一个磁带驱动上的 writev 应当将全部 iovec 结构中的内容作为磁带上的单个记录.
很多驱动, 但是, 没有从自己实现这些方法中获益. 因此, scull 省略它们. 内核使用 read 和 write 来模拟它们, 最终结果是相同的.
七、模块实验
这次模块实验的使用是友善之臂SBC2440V4,使用Linux2.6.22.2内核。
模块程序链接:
scull模块源程序
模块测试程序链接:模块测试程序
测试结果:
| 量子大小为6: [Tekkaman2440@SBC2440V4]#cd /lib/modules/ [Tekkaman2440@SBC2440V4]#insmod scull.ko scull_quantum=6 [Tekkaman2440@SBC2440V4]#cat /proc/devices Character devices: 1 mem 2 pty 3 ttyp 4 /dev/vc/0 4 tty 4 ttyS 5 /dev/tty 5 /dev/console 5 /dev/ptmx 7 vcs 10 misc 13 input 14 sound 81 video4linux 89 i2c 90 mtd 116 alsa 128 ptm 136 pts 180 usb 189 usb_device 204 s3c2410_serial 252 scull 253 usb_endpoint 254 rtc Block devices: 1 ramdisk 256 rfd 7 loop 31 mtdblock 93 nftl 96 inftl 179 mmc [Tekkaman2440@SBC2440V4]#mknod -m 666 scull0 c 252 0 [Tekkaman2440@SBC2440V4]#mknod -m 666 scull1 c 252 1 [Tekkaman2440@SBC2440V4]#mknod -m 666 scull2 c 252 2 [Tekkaman2440@SBC2440V4]#mknod -m 666 scull3 c 252 3   启动测试程序 [Tekkaman2440@SBC2440V4]#./scull_test write error! code=6 write error! code=6 write error! code=6 write ok! code=2 read error! code=6 read error! code=6 read error! code=6 read ok! code=2 [0]=0 [1]=1 [2]=2 [3]=3 [4]=4 [5]=5 [6]=6 [7]=7 [8]=8 [9]=9 [10]=10 [11]=11 [12]=12 [13]=13 [14]=14 [15]=15 [16]=16 [17]=17 [18]=18 [19]=19   改变量子大小为默认值4000: [Tekkaman2440@SBC2440V4]#cd /lib/modules/ [Tekkaman2440@SBC2440V4]#rmmod scull [Tekkaman2440@SBC2440V4]#insmod scull.ko   启动测试程序 [Tekkaman2440@SBC2440V4]#./scull_test write ok! code=20 read ok! code=20 [0]=0 [1]=1 [2]=2 [3]=3 [4]=4 [5]=5 [6]=6 [7]=7 [8]=8 [9]=9 [10]=10 [11]=11 [12]=12 [13]=13 [14]=14 [15]=15 [16]=16 [17]=17 [18]=18 [19]=19 [Tekkaman2440@SBC2440V4]#   改变量子大小为6,量子集大小为2: [Tekkaman2440@SBC2440V4]#cd /lib/modules/ [Tekkaman2440@SBC2440V4]#rmmod scull [Tekkaman2440@SBC2440V4]#insmod scull.ko scull_quantum=6 scull_qset=2   启动测试程序 [Tekkaman2440@SBC2440V4]#./scull_test write error! code=6 write error! code=6 write error! code=6 write ok! code=2 read error! code=6 read error! code=6 read error! code=6 read ok! code=2 [0]=0 [1]=1 [2]=2 [3]=3 [4]=4 [5]=5 [6]=6 [7]=7 [8]=8 [9]=9 [10]=10 [11]=11 [12]=12 [13]=13 [14]=14 [15]=15 [16]=16 [17]=17 [18]=18 [19]=19 |

相关文章推荐
- 跟着韦东山老师学习嵌入式----字符设备驱动程序之poll机制
- Linux设备驱动程序学习笔记05:字符设备驱动程序III
- linux字符设备驱动程序(一)----------分配设备号并注册设备
- 11.LED驱动程序设计(1)-字符设备控制
- Linux设备驱动程序学习(5)-高级字符驱动程序操作[(2)阻塞型I/O和休眠]
- Linux设备驱动程序第三版学习(1)(2)-字符设备驱动程序源码分析
- 第12课第2.3节 字符设备驱动程序之LED驱动程序_操作LED
- Linux设备驱动程序——高级字符驱动程序操作(poll机制)
- 字符设备驱动程序的编写_点亮LED灯
- Linux 字符设备驱动程序流程
- 一个简单的演示用的Linux字符设备驱动程序
- 第12课第5节 字符设备驱动程序之poll机制
- Linux字符设备驱动程序的编写框架
- Linux字符设备驱动程序实例
- 从零开始写linux字符设备驱动程序(三)(基于友善之臂tiny4412开发板)
- 字符设备驱动程序之异步通知
- 一个简单的字符设备驱动程序和测试程序
- Linux驱动程序开发 004- 字符设备驱动
- 字符设备驱动程序学习笔记四
- Linux字符设备驱动程序编写基本流程