USING INDUCTION TO DESIGN 使用归纳法设计算法【全文翻译】
2011-07-27 11:43
597 查看
英文版原文下载地址:http://download.csdn.net/source/3472764
这篇文章在进行组合算法设计和教学过程中展示了一种基于数学归纳法的方法,尽管这种方法并不能涵盖设计算法时的所有可能方法,但它包含了大部分已知的技术方法。同时这种方法也提供了一个极好的并且也是直观的结构,从而在解释算法设计的时候显得更有深度。这种方法的核心是通过对数学定理证明过程中和设计组合算法过程中的两种智力过程进行类比。尽管我们承认这两种过程是为不同的目的服务的并且取得的是不同类型的结果,但是这两者要比看上去的更加相似。这种说法可以通过一系列的算法例子得到验证,在这些算法中都可以采用这种方法进行设计和解释。我们相信通过学习这种方法,学生能够对算法产生更多的热情,也能更深入更好的理解算法。
数学归纳法是一个非常强大的证明方法。使用如下:让T是一个我们想证明的定理。假设T包含一个值可为任意自然数的参数n。我们不需要直接证明T对所有的n都成立,我们只需要证明以下两点:(1)T对n=1时成立 (2)对于任意的n>1,T对于n-1成立。第一点往往很容易证明,证明第二点在很多情况下要比直接证明定理要容易,因为此时我们可以假设T对n-1已经成立。(从某种意义上来说,我们无条件的获得这一假设)。换句话说,减小定理的规模使用一个更小的n值而不是从头开始证明是很有帮助的,我们关注的就是这种减小。
这一原则对于算法同样也适用。归纳法让人们关注于从较小的子问题延伸到那些更大的问题上。可以通过从问题的任意一个实例入手,通过假设规模较小的相同问题已经得到解决,然后再试图解决该问题。例如,给定一个n(n>1)的序列对其进行排序(排序一个序列显然没必要),我们可以假定已经知道如何对n-1个数进行排序。然后我们可以要么排序前n-1个数,然后把第n个数插入到正确位置(这引出了一个叫插入排序的算法),要么一开始把第n个数放在它的最终位置然后再排序剩下的数(这引出了一个叫选择排序的算法)。我们只需要解决对第n个数的操作(当然这并不是唯一的排序方法,也不是唯一一种使用归纳法进行排序的方法)。
上面介绍的使用归纳法的例子很直观,然后有许多不同的方法来使用归纳法,由此带来了不同的算法设计技巧。这是一个非常强大和灵活的方法。我们将证明,在使用这种想法时很多问题变得很简单,这一点会让你惊讶不已。我们将采用其中的几种方法,并显示它们在设计算法时的强大力量。在我们讨论的归纳法的各种变形方法中,我们主要讨论巧妙的选择归纳序列,增强归纳假设,更强的归纳法以及最大的反例四种方法。
我们的处理方法有两种新奇之处。首先我们把看上去不同的算法设计技术归到同一个类别下,这将使得对一个新算法的查找更有条理性。其次,我们利用已知的数学证明技巧来设计算法,这一点很重要,因为它开启了利用在别的学科多年发展过程中形成的强大的技术进行算法设计的时代。
一般而言,在算法领域使用归纳法和数学证明技巧并不是第一次见到。归纳法在证明算法正确性上已经使用了很长时间,人们通过把对算法执行步骤的断言,证明它们在最初情况下成立和它们在特定操作步骤下保持不变结合起来,从而验证算法的正确性。这种方法最初由哥特斯和冯诺依曼提出的,后来由弗洛伊德和其他人对其进一步发展。Dijkstra和格里斯提出了一种和我们开发程序相似的方法,同时他们也给出了对其正确性的证明。尽管在此我们借鉴了他们的一些技术,但我们的重点却不同:我们关注于高层次的算法理念而不必下降到实际的程序层面。PRL和NuPRL(这里不会翻译,建议看http://www.cs.cornell.edu/info/projects/nuprl/book/node2.html)使用数学证明作为一个程序开发系统的基本构成。当然递归也被广泛用于算法设计之中(对于递归的详细讨论请看...)
我们的目标主要是用于教学,我们假设读者对数学归纳法和基本的数据结构已经很熟悉。对于任意一种证明技巧我们会对其类比进行一个简要的解释,然后给出一个或多个算法例子。对于给出的算法例子我们重点关注于如何使用这种方法。我们的目的不是在于对一个算法进行解释从而帮助一个程序员更容易地将其转换为程序,而是通过一种更容易理解的方式对其进行解释。这些算法通过一种创造性的过程加以解释而不是以一种成品的方式出现。我们教算法的目标不仅仅是向学生展示如何解决当前特定的问题,同时也是帮助他们解决未来新的问题。教学生如何把想法融入到算法设计中和教学生解决方案的实现细节同样重要。但前者通常要更难一些。我们相信我们的方法能够加强对这种思维过程的理解。
尽管归纳法建议通过递归加以实现,但也未必如此。(事实上我们称这种方法为归纳而不是递归,从而淡化递归实现的概念)在很多情况下,迭代也很容易,甚至尽管在算法设计中我们心里想的是使用归纳法(递归),但迭代却更有效率。
本文中提到的这些算法是经过筛选的,以便能更好的展现这种方法的魅力。我们选择的是一些简单的问题,在后续部分选择一些更复杂的例子。我们发现很多固定的算法在算法设计课上第一次教授时可以使用这种方法。(使用这种方法的算法导论书很快就要出来了)我们首先从三个简单的例子入手,(至少使用归纳法让他们看上去简单了)然后我们展示一些数学证明技巧以及它们在算法设计中类似的技巧,在每种情况下这种类比都在一个或多个例子中得到了阐明。
问题:给定一个实数序列an,an-1,...a1,a0和一个实数x,计算下面这个多项式的值
Pn(x)=an*x^n+an-1*x^(n-1)+...a1*x+a0
这个问题看上去并不像是一个使用归纳法求解直观例子,尽管如此,我们将证明使用归纳法能够直接带来很不错的解决方法。我们首先使用最简单几乎微不足道的方法求解,然后通过发现其中的变化,从而找到更好的解决方案。
这个问题涉及到n+2个数字。使用归纳法解决该问题的依据是对一个更小的问题进行求解。换句话说,我们尽量减小问题的规模,然后使用递归求解。(或者我们称其为归纳)第一步尝试是移除an,这将导致问题中计算的表达式变成:
Pn-1(x)=an-1*x^(n-1)+an-2*x^(n-2)+...+a1*x+a0
除了规模外这是一个同样的问题。因此我们可以使用下面的假设运用归纳法对其进行求解:
归纳假设:我们已经知道如何去计算一个多项式,该多项式在x处的输入项有an-1,...a1,a0(即我们知道如何计算Pn-1(x))
我们现在可以使用这假设运用归纳法来解决该问题。首先我们需要解决最基本的情况,也就是计算a0;这是很简单的。然后我们必须表明如何通过借助规模较小的问题的解决方案(这里是Pn-1(x)的值)来解决原有问题(即计算Pn(x))。在该例子中这是很直观的。我们仅仅需要计算x^n,乘以an然后加上Pn-1(x)即可。
在这一点上看上去使用归纳法很无聊因为它仅仅是复杂了一个简单的解决方案,上面提到的算法仅仅是按照多项式的数学方式对多项式从右到左进行计算而已。然而,我们很快就会看见这种方法的强大之处。
尽管这个算法是正确的,但其并不是高效的。它需要n+n-1+n-2+...+1=n(n+1)/2次乘法和n次加法计算。现在我们略微改变一下归纳法的使用方法,从而得到一个更好的解决方案。
改进:第一个改进之处在于我们注意到在求解过程中存在很多冗余计算:x的指数是从头开始计算的。当我们计算x^n时通过使用x^(n-1)的值能够帮我们节省很多乘法运算。这些都是在归纳法假设中通过对x^n计算的归纳得以实现的:
更强的归纳假设:我们已经知道了如何去计算多项式Pn-1(x),同时我们也知道如何计算x^(n-1)的值。
这个归纳假设更强一些,因为它要求计算出x^(n-1),但是它拓展起来更容易。我们在计算x^n时仅仅需要进行一步乘法操作,然后在进行一步乘法操作得到an*x^n,然后进行一步加法操作完成整个计算。(其实这个假设并不是太强,因为我们还是需要计算x^(n-1)的值)。总而言之,这里需要进行2n次乘法和n次加法。尽管这个归纳假设需要更多的计算,但总的说来它减少了工作量。我们在后面再来讨论这一点。在各种层面上看来这个算法很好,它高效,简单也容易实现。然而存在一个更好的算法,它是通过用一种不同的方式使用归纳法得以实现的。
我们通过移去最后一个系数an来简化问题。(这是一个很直截了当的做法)但是我们也可以移去第一个系数a0。这个规模更小的问题变成了计算由an,an-1...a1这些系数组成的多项式,如下所示:
P'n-1(x)=an*x^(n-1)+an-1*x^(n-2)...+a1
(注意到an现在是n-1次的系数,后面依次改变)
新的归纳假设(倒序):我们知道如何去计算由系数an,an-1...a1构成的x多项式(即上面列出来的P'n-1(x))
由于这个假设更容易拓展,故其更符合我们的目的。很明显Pn(x)=x*P'n-1(x)+a0。因此这里仅仅只要一次乘法和一次加法就可以通过P'n-1(x)计算得出Pn(x)。完整的算法可以通过下面这个表达式加以描述:
an*x^n+an-1*x^(n-1)+...+a1*x+a0=((...((an*x+an-1)x+an-2)...)x+a1)x+a0
这个算法被称为霍纳归纳以W.G.Horner命名。(这也是牛顿提出来的)。下面给出了计算多项式的算法。
计算表达式算法
(a0,a1,a2...an,x:real); //输入a0至an,x,全为实数
begin
P:=an;
for i:=1 to n do
P:=x*P+an-i;
end;
复杂度:这个算法仅仅需要n次乘法,n次加法以及一个额外的内存空间。尽管原先的解决方法看上去简单并且高效,但追求一个更好的算法是值得的。这个算法不仅仅是速度更快,同时相应的程序也更简单。
总结:上面给出的简单例子阐明了归纳法使用过程中的灵活性。霍纳规则的技巧仅在于考虑到输入是从左向右的,而不是直观上看到的从右向左。
当然这里有使用归纳法的许多其他潜在性,我们将在更多的例子中看到这一点。
f是一个把有限集合A映射到其自身的函数。(例如A中的每一个元素都映射到A中的另一个元素)为了简化起见,我们把A中的元素表示为从1到n的数字。我们假定函数f以一个数组f[1..n]的形式出现,这样f[i]存放的是f(i)的值。(该值是一个位于1到n之间的整数)当A中的每一个元素都仅仅只有一个元素对应它时我们把函数f称为一一映射。函数f可以用图1中的图加以展示,在图中,两端数据都对应同一个集合,图中的边表示映射关系。(这种映射关系是从左至右的)
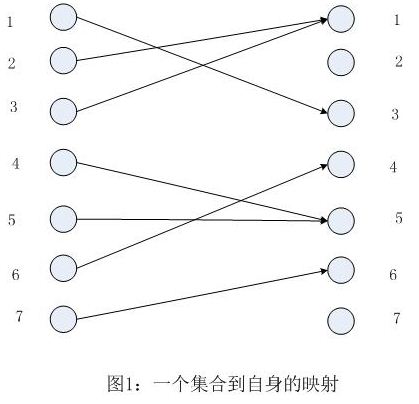
问题:找到一个包含最多元素的子集S(ScA),使得函数f能够把S中的任何元素映射到S中的其他元素。(即f让S映射到自身),同时S中的每一个元素仅仅只有唯一的一个S中的元素映射到自身。(即限制S让f成为一个一一映射)
如果f本来就是一个一一映射,那么全集A就满足了问题的条件,显然它也是最大的集合。在另一个方面来说,如果f(i)=f(j)存在且i≠j,那么集合S就不能同时包含i和j。例如在图1中S就不能同时包含2和3。不可能任意从两者中选择一个从集合中剔除出去。例如,假设我们决定删去3,由于1被映射到3,所以我们也必须删去1。(因为任意映射必须映射到S中而此时3已经不在S中了)。但是如果1被排除了,那么2也会因为同样的原因被删去。但是,这样得到的结果集不是最大的,因为我们很容易就能看到可以只删去2即可。这个问题其实是让我们去找到一种通用的方法来决定集合中包含哪些元素而已。
使用归纳法求解的思想集中在缩减问题的规模上,这种方法使用起来也很灵活。我们可以通过寻找一个要么属于S中的元素或要么不属于S中的元素来缩减问题规模。我们将在后面进行这一操作。我们先使用简洁明了的归纳假设:
归纳假设:我们已经知道如何去解决一个含n-1个元素集合的问题。
最基本的情况很简单:如果集合中只含有一个元素,集合必须映射到自身,这就是一个一一映射。假设我们已经有了一个含有n个元素的集合A,现在我们寻找一个满足问题条件的子集S。很显然找到一个不属于S集合的元素要比找到一个包含在S集合中元素简单。我们可以认为任何一个元素i如果没有被其他元素映射,那么i不可能包含在S中。(换句话说,在图右侧的元素i,如果没有一条边与之相连,那么i不可能在S中)否则的话,如果i∈S,假设S中有k个元素,那么这k个元素最多映射到k-1个元素,因此这个映射不可能时一一映射。如果存在这样的i,我们仅需要把i从集合中移除即可。我们现在有一个含有n-1个元素且让函数f映射到自身的集合A'=A-{i}。通过归纳假设我们知道如何去求解A'。如果不存在这样的i,那么映射就是一一映射,这样我们就解决了问题。
这种解法的关键在于我们必须移除i。我们在上面证明了i不可能属于S集。这是归纳法的优势之处。一旦我们移除了一个元素缩减了问题的规模我们就算完成了。然而我们必须格外小心,缩减后的问题和原问题几乎是一样的。(除了规模外)对于集合A和函数f的唯一条件就是f让A映射到自身。由于并没有元素映射到i,这个条件对于A-{i}后的集合依然成立。当没有元素可以移除的时候这个算法也就执行结束了。
实现:上面的算法是通过使用递归的过程加以描述的。在每一步中我们找到一个没有其他元素映射到它的元素,移除它,然后继续递归执行。然而实现方法并不需要用递归。我们可以对每一个元素i使用一个计数器c[i]。初始情况下c[i]需要和映射到i的元素数目相等。这可以通过扫描数组(进行n步)以及增加对应的计数器值而计算出来。然后我们把所有计数值为0的元素放在一个队列中。在每一步执行中,我们移除队列中的元素j(同时也移除集合中的对应值)。减小c[f(j)]的值,如果c[f(j)]=0,我们就把f(j)放在队列中。当队列为空时算法执行结束。算法描述如下:
映射算法(f:整型数组[1..n])
begin
S:=A{A是从1到n的数字构成的数组}
for j:=1 to n do c[j]:=0;
for j:=1 to n do increament(c[f(j)]);
for j:=1 to n do
if c[j]=0 then put j in Queue;
while Queue is not empty do
remove i from the top of the queue;
S:=S-{i};
decrement c[f(i)];
if c[f(i)]=0 then put f(i) in Queue
end;
复杂度:初始化部分需要O(n)的操作时间,每一个元素最多有一次机会被放置到队列中,把元素从队列中移除只需要常数时间。步骤的总数是O(n)。
总结:在本例中减少问题的规模主要在从集合中删除元素上。因此我们试图在不改变问题条件的情况下寻找一种最简单的方法来移除元素。由于对于函数的唯一的要求是它必须把A映射到自身,故我们会很自然地选择一个没有其他元素映射到的元素。
问题:输入是一条线上一系列间断线段的集合I1,I2...In。对于每一个线段Ij都给出了它的两个端点Lj(左端点),Rj(右端点)。我们想标记出所有包含在其他线段中的线段。换句话说,一个线段Ij必须被标记出来,如果存在另一条线段Ik(k≠j)并且满足Lk≤Lj以及Rk≥Rj。为了简化起见我们假定所有的线段都是不一样的(例如任意两个线段都不可能同时具有相同的左端点和右端点,但是它们可能有两个端点中的某一个相同)。图2展示了这样的一个线段集合。(为了更好的展示,每一条线段都放在另一条线段上面而不是放在一条线上)

用直观的方法使用归纳法主要是移除一个线段I,对于剩下的线段使用递归的方法加以解决,然后在检查把I放回后的效果。问题在于把线段I放回需要检查所有其他的线段来判断他们中是否包含I或者被I所包含。这需要检查I和其余n-1条线段,算法中使用的比较将达到n-1+n-2+...+1=n(n-1)/2次。为了获得一个更好的算法我们需要做两件事:首先我们选择一条特殊的线段加以移除,其次我们尽可能多的使用从更小规模问题的解决方案中收集到的信息。
选定I为所有线段中具有最大左端点值的线段,由于其他线段左端点值都较之小,这样就不需要再检查左端点值了。因此,为了要检查I是否包含于其他线段之中,我们只需要检查其他线段中是否有右端点值比I右端点值更大的线段。为了找到这么一条具有最大左端点值的线段我们可以依据线段的左端点值对所有线段进行排序并且按照次序对其进行搜索。假定线段已经按照次序排好,L1≤L2≤...≤Ln。归纳假设如下:
归纳假设:我们已经知道如何去解决包含I1,I2...In-1条线段的问题。
最基本的问题很简单,如果只有一条线段,那么它肯定不会被标记。现在我们来考虑In。通过归纳假设我们知道已经确定了在线段I1到In-1中有哪些线段是包含在其他线段之中的,我们需要确定In是否包含其他(之前没有被标记过)的线段,以及In是否被包含在其他线段之中。让我们首先来检查In是否被包含在其他线段之中。如果In被包含在一条线段中,假如是Ij,j<n,于是Rj≥Rn。这是唯一的必要条件(因为排序已经确保了Lj≤Ln)。因此我们只需要在之前的线段中记录拥有的最大右端点值即可。把该右端点值与Rn进行比较就能给出我们答案。我们稍微改变一下归纳假设:
更强的归纳假设:我们已经知道如何解决I1,I2...In-1的问题,同时也找出了他们中右端点的最大值。
我们再一次让In作为拥有最大左端点值的线段,然后让MaxR作为前n-1条线段中右端点的最大值。如果MaxR≥Rn,那么In就应该被标记,否则(MaxR≤Rn)Rn就成为新的最大的最大值。(这最后一步是必要的,因为我们现在不仅仅是标记线段,同时我们也在寻找最大的右端点值。)我们现在仅通过一步检查就能确定In的状态。
为了完成这个算法我们需要检查In是否包含一条之前未被标记过的线段。In包含一条线段Ij,j<n,只有当满足条件Lj=Ln且Rj<Rn时才行。我们可以通过增强排序功能来处理这种情况。现在我们不仅按照左端点值进行排序,同时对于具有相同左端点值的线段,我们依据他们的右端点值的逆序来进行排序。这样能够排除上面提到的情况出现,因为Ij将会放置在In之后(右端点值较小),而且Ij的包含性将会被上一个算法找到。完整的算法如下所示:
线段包含性算法
(I1,I2,...In:线段)
{用一对Lj,Rj来给出一条线段Ij}
{我们假定没有两条线段是完全一样的}
{当Ij被包含在另一条线段中时,Mark[j]将会被标记为真}
begin
按照线段的左端点值递增次序对所有线段进行排序
具有相同左端点值的线段按照他们右端点值递减的次序进行排序
{for all j<k either Lj<Lk or Lj=Lk and Rj>Rk}
MaxR:=R1;
for j:=2 to n do
if Rj≤MaxR then
Mark[j]:=true;
else
Mark[j]:=false;
MaxR:=Rj;
end;
复杂度:除了排序外,这个算法包含一个涉及到O(n)步操作的循环。由于排序需要O(nlogn)步操作,故其占据了算法主要的运行时间。
总结:这个例子阐明了一个不是那么直接运用归纳法的方法。首先我们选择可以运用归纳法执行的序列。然后我们设计归纳假设,该假设能够暗示出期望的结果同时它也易拓展。重点放在这些步骤上就能让对很多算法的设计变得简单。
在前面的例子中,重点都放在寻找一个缩减问题规模的算法上。这是使用归纳法的本质。然而有很多方法也能实现这一点。首先,问题可能包含一些参数(例如图中的左端点右端点,顶点和边),我们必须决定对其中哪一个参数进行缩减。其次,我们可能能够排除掉许多可能元素,但我们想选择其中最容易的一个。(例如最左边的端点,最小的数字)第三,我们可能想对问题加强限制条件(例如线段是有序排列的)。当然还有其他很多变化。例如我们可以假设我们已经知道对一些小于n的值的问题如何解决而不是仅仅的n-1。这往往是一个有效的假设。任何缩减问题规模的做法都是值得考虑的,因为这种做法能够引导我们回到问题的最基本情况,而这时往往我们能够直接解决。回到在归纳法中讨论的排序例子,我们可以把对n个元素的排序缩减为对两个各含n/2个元素的子集的排序。然后可以对这两个排好序的集合进行合并(引出一个称为归并排序的算法)。把问题分解(归纳性的)为一些相同的部分是一个很有用的技巧(我们将会在后面进行讨论),该技巧称为分治。
一些问题的缩减很容易就能实现,然而一些却很难实现。一些规模的缩减能够带来很不错的算法,然而一些却不行。在很多情况下这就是问题中唯一的困难之处,一旦做出了正确的选择那么剩下的就很容易了(例如在映射问题中元素i的选择那样)。这在数学中极其重要。没有人能够不通过首先思考如何选择一个归纳序列就直接跳到归纳证明中去。正如估计的那样,这在算法设计中也是很重要的。在这一部分我们将给出两个例子,在这两个例子中,缩减序列的重要性得到了体现。特别是名人的例子,它说明了一种不同于一般的顺序。
问题:给定一个有n个顶点的有向无环图G=(V,E),这些顶点从1到n进行编号,因此如果顶点v被标记为k,那么顶点v可以通过一条直接路径到达所有编号大于k的顶点。(一条路径是一系列点的序列,这些点v1,v2...vk通过边(v1,v2),(v2,v3)...(vk-1,vk)相连)
我们再一次尝试依据规模更小的问题来解决这个问题。考虑一个更小问题的直接做法是移去一个顶点。换句话说,通过下面的方法可以看到归纳法蕴含在顶点的数量之中。
归纳假设1:我们已经知道如何按照上面描述的条件用n-1个顶点为所有的图做上标记。
只有一个顶点的最基本的情况是很简单的。如果n>1,我们可以移去一个顶点,然后尝试使用归纳假设,再尝试去拓展标记。我们首先需要核实的一点是移除一个顶点后的问题和原来的问题是一样的(除了更小的规模外)。拥有一个一样的问题很必要,否则归纳假设将无法使用。例子中唯一假设是图不是循环图。由于移除一个顶点不可能产生一个循环图,那么这种缩减是可行的。
这种缩减的问题在于尽管假设可以使用但我我们不清楚如何去拓展解决方法,即怎么去标记移除的顶点。我们解决该问题的方案是精心选择顶点v。由于移去任何一个顶点产生的规模更小的问题都是符合要求的,所以我们可以任意选择一个顶点作为第n个顶点。因此,我们应该移除那些最容易获取标记的点。一个明显的选择是那些没有依赖关系的顶点(任务),也就是该顶点的入度(指向该点的边数)为0。可以把该顶点标记为1,这不会带来什么错误。
但是,我们总能找到一个入度为0的点么?答案按直觉是肯定的,但我们必须从某个地方开始。毫无疑问的是,如果所有的顶点都有大于0的入度我们可以用各种方式遍历图而且永远不会停止。但是由于只有有限数量的顶点需要我们去循环查找,这与我们的假设是相矛盾的。(同理我们也可以从出度为0的顶点开始寻找,然后把该顶点标记为n)剩下的算法就很清晰了。移除选择的顶点的相邻边,剩下的图依然是无环图,再用2到n标记图的剩余部分。由于我们需要用2到n而不是1到n-1标记剩下的图,我们需要对归纳假设做点改动。
归纳假设2:我们知道依据问题的条件如何使用n-1不同标记的集合去标记一个拥有n-1个顶点的图。
下面给出与之对应的算法
拓扑排序算法
{G={V,E}:一个有向无环图};
begin
对所有的顶点的入度初始化;
{可以通过深度优先搜索}
G_label:=0;
for i:=1 to n do
if vi.indegree=0 then put vi in Queue;
repeat
remove vertex v from Queue;
G_label:=G_label + 1;
v_label:=G_label;
for all edges(v,w) do
w.indegree:=w.ingegree-1;
if w.indegree=0 then put w in Queue
until Queue is empty
end;
复杂度:初始化入度计数器需要O(|V|+|E|)时间(例如在例子中使用深度优先搜索)。找到一个入度为0的点要花费常数时间(访问队列)。每一条边(v,w)被考虑一次(当v从队列中被取出时)。因此,计数器需要更新的次数的多少就是图中边数目的多少。因此算法的执行时间就是输入规模的线性时间O(|V|+|E|)。
总结:这是另一个使用归纳法直接设计算法的例子。这里的技巧在于明智选择归纳序列。我们不是武断地缩减问题规模,而是选择移除一个特殊的顶点。任何给定的问题的规模都可以用很多可能的方法加以缩减。思想就在于探寻各种各样的选择然后测试产生的算法。我们从多项式计算这个例子中看到从左向右要比从右向左好。另一个通常的可能性是对从上往下和从下往上进行比较。同样也可能每次递增2而不是递增1,当然还有更多的可能情况。有时最好的归纳序列甚至对于所有的输入来说也是不尽相同的。设计一个特殊的算法去寻找一个对问题执行规模缩减的最好的方法有时是值得的。
在算法设计中有一个很流行的练习。这是一个非常好的例子,该例子的解答不需要扫描全部数据(甚至是数据的重要的组成部分)。在n个人中,一个名人被定义为其他人都认识但是自己却不认识其他人的人。该问题就是存在名人的情况下确定名人,只能通过以一种“您好,请问您认识站在那里的人么?”的方式提问。(假定所有的回答都是正确的,甚至是名人自己也会给出答案)我们的目标是让最小化提问的次数。由于存在n(n-1)/2对人,在最坏的情况下,如果问题被武断地提出,有可能需要询问n(n-1)次问题才行。我们不清楚我们能比最坏的情况做的更好。
在技术上,如果我们建立一个用顶点表示人的有向图,当A认识B就有一条从A到B的边,那么一个名人就对应一个汇点。(非有意的双关语)也就一个入度为n-1出度为0的顶点。该图可以用一个n×n邻接矩阵来表示,如果第i个人认识第j个人那么在该矩阵中位于第i行第j列的位置被标记为1,否则就为0。该问题也就是通过查找矩阵中尽可能少的条目确定汇点。
像往常一样,我们考虑有n-1个人和有n个人时问题的不同之处。既然由定义可知最多存在一个名人,那这里就有三种可能。其一,名人在前n-1个人中;其二,名人是第n个人;其三,这里没有名人。第一种情况最容易处理,我们只需要核对第n个人认识名人,但是名人并不认识第n个人的局面是否存在。其他两种情况就比较困难了,因为为了确定第n个人是否是名人,我们可能需要提2*(n-1)个问题。在最坏的情况下,这可能会导致n*(n-1)个问题(这是我们试图避免发生的)。我们需要另一种解法。
这里的技巧在于从逆向考虑这个问题。确定一个名人可能很难,但是确定某个人不是名人可能要简单很多。毕竟,很明显在这里非名人要比名人多。把某人排除出考虑对把问题规模从n缩减到n-1来说已经足够了。此外,我们不需要排除出特定的人,任何人都可以。假设我们问Alice她是否认识Bob,如果她认识她就不会是一个名人,如果她不认识
那Bob就不会是一个名人。我们可以通过一个问题排除出他们中间的一个。
现在考虑上面列出的三种情况。我们不只是任意挑选一个人作为第n个人。我们使用上面的思想去排除出Alice和Bob中的一个,然后对其余包含n-1个人的问题进行求解。我们保证情况2不会发生,因为排除出去的人不可能是名人。此外,如果情况3发生,也就是说在n-1个人中没有名人,那在n个人中也不会有名人。只有情况1存在,但是正如上面提到的,这种情况很简单。如果在n-1个人中存在一个名人,只需要提出两个问题就可以确定整个集合中是否存在名人了。否则就不会有名人存在。
所得到的算法如下。我们问A是否认识B,根据A的回答排除掉他们其中的一个。假设排除的是A,然后我们在剩下的n-1个人中寻找(通过归纳法)一个名人。如果没有名人,那么算法就终止。否则我们核实A认识名人但是名人不认识A这种局面。下面给出一个非递归的算法实现。
名人算法(已知n×n的布尔矩阵)
begin
i:=1;
j:=2;
next:=2;
{在第一步中我们排除了除了一个候选人以外的所有人}
while next≤n do
next:=next+1;
if Know[i,j] then i:=next;
else j:=next;
{我们排除i和j中的一个}
if i=n+1 then candidate:=j else candidate:=i;
{现在我们核实该候选人是否确实是名人}
wrong:=false;k:=1;
Know[candidate,candidate]:=false;
{只是一个用来测试的虚拟变量}
while not wrong and k≤n do
if Know[candidate,k] then wrong:=true;
if not Know[k,candidate] then
if candidate ≠ k then wrong:=true;
k:=k+1;
if not wrong then print"candidate is a celebrity!"
end;
复杂度:这里最多只需要提3*(n-1)个问题。在第一步中提n-1个问题从而从候选人中排除掉n-1个人。为了确定那个候选人是否是名人最多只需要提2*(n-1)个问题。上面给出的解答表明可以在邻接矩阵中仅查找O(n)条记录就能确定一个名人,尽管从推理上认为问题的解法与n(n-1)项输入都密切相关。(这里也可能节省掉额外的log2(n)【取下限】次提问,只需要在验证过程中以及提问排除过程中注意避免重复即可)
总结:这个极佳的解法的核心思想在于用一种明智的方式把问题规模从n缩减到n-1。这个例子表明了有时候在更有效的进行问题规模的缩减上花一些努力(在该例子中提出一个疑问)是值得的。此外,逆向思维在本问题中显得很有用。与其去寻找一个名人我们不如尝试去排除非名人。这在数学证明时经常用到。一个人不需要直接去尝试解决问题。有时解决能够给原先问题带来解答的相关问题要简单一些。为了找到这些相关的问题,在开始时使用成品(数学证明中的得到的定理),然后逆向进行我们的工作看看实现这个成品需要什么东西,这往往是很有用的做法。
在用归纳法证明数学定理时,加强归纳假设被当做一种很重要的技巧使用。当尝试使用一个归纳证明时常常会遇到下面的情况。定理用P(n)表示,归纳假设可以用P(n-1)表示,要证明结论P(n-1)推导出P(n)。很多情况下可以加上另一个假设,称为Q,在这个假设下证明会变得更简单。也就是说,证明P(n-1)和Q推导出P(n)要更加容易。这种结合的假设看上去是正确的但是还不清楚如何去证明。技巧在于在归纳假设中加上Q(如果可能的话)。现在需要证明[P和Q](n-1)推导出[P和Q](n)。结合的定理[P和Q]和仅有P相比是一个更强的定理,但是有时候更强的定理却更容易去证明(Polya称这个原理为“发明家的悖论”)。这个过程可以反复,加上正确补充的假设,定理的证明变得简单。我们在表达式计算和线段包含问题中已经初步看到了这个原理。
在这部分中我们给出两个例子来展现加强归纳假设的运用。第一个问题很简单,但它阐明了使用这种技巧时最常见的错误,也就是忽视了加入额外假设这个事实从而忘记更新证明过程。换句话说,证明P(n-1)和Q推导出P(n)时没有注意到Q是被假设的。我们可以把这种转换类比与解决更小的问题,不过该问题和原先的问题已经不是完全一样的了。第二个例子更复杂一些。
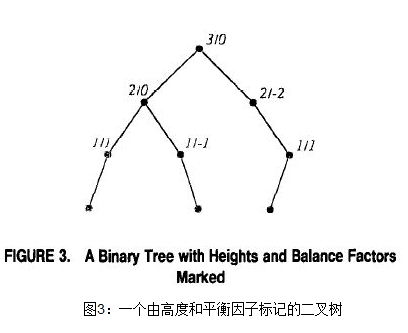
假设T是一个以r为根的二叉树。节点v的高度就是v和树中最底层的叶子之间的距离(应该是节点下方的树的最底层叶子)。节点v的平衡因子被定义为节点v的左孩子和它的右孩子(我们假设一个节点的孩子被标记为左和右)高度之差。图3给出了一棵树,在树中每个节点用h/b来标记,h是节点的高度,b是节点的平衡因子。
问题:给出一个拥有n个节点的树,计算它所有节点的平衡因子。
我们使用基本的归纳算法以及直截了当的归纳假设:
归纳假设:我们已经知道如何去计算小于n个节点的平衡因子。
最基本的n=1的例子很简单。给定一个拥有n>1节点的二叉树,我们移去根节点,然后用递归的方法解决剩下的子树。我们选择移去根节点因为一个节点的平衡因子仅仅依赖于节点下面的节点。我们现在已经知道出了根节点以外其他所有节点的平衡因子。但是根节点的平衡因子不是依赖于它的孩子的平衡因子而是依赖于它的孩子的高度。因此,一个简单的归纳法无法适用于这个例子。我们需要知道根节点孩子的高度。思想就在于在原先的问题中加上高度查询这个问题。
加强的归纳假设:我们已经知道如何计算小于n个节点的平衡因子以及它们的高度。
再一次的,基本问题很简单。现在考虑根节点时可以简单通过比较它的孩子的高度确定出它的平衡因子。此外,根节点的高度也能够被简单确定,也就是它两个孩子高度的最大值加上1。
这个算法的关键也就是解决一个简单拓展的问题。我们也计算高度而不只是计算平衡因子。拓展后的问题要更简单因为高度是很容易计算出来的。在很多情况下,解决一个更强的问题反而更简单。这对于归纳法说尤其正确。使用归纳法,我们仅需要把一个小问题拓展成一个更大的问题。如果解法更宽泛(因为问题被拓展了)那么归纳步骤可能要更简单因为我们有更多的东西可用。在该问题中常见的一个错误是忘记其中有两个不同的变量,而且这两个变量必须要单独计算。
问题:给定平面上一个点的即可,找出最近两点之间的距离。
最直接使用归纳法的方法是移去一个点,解决n-1个点的问题,然后再考虑那个额外的点。然而,如果从对n-1个点的情况的求解中仅仅知道他们中间的最小距离,那么从额外点到其余n-1个点的距离都需要被计算出来。这样使得计算距离的总次数变成n-1+n-2+...+1=n(n-1)/2。(这其实是一个直接比较每两点的算法)我们想找到一个更快的解法。
一种分治算法
归纳假设如下所示:
归纳假设:我们已经知道在平面上如何去查找少于n个点中任意两点之间的最短距离。
既然我们假设我们能够解决少于n个点的子问题,我们可以把问题缩减为两个含有n/2个点的子问题。我们假设n是2的幂,这样我们总可以把一个集合分成数量两个相等的集合。(我们再后面再讨论这个假设)有很多方法可以把一个点集分成两个相等的部分。我们可以自由选择最好的方法。我们想要从规模较小问题的解法中获得尽可能多有用的信息,因此我们想要在考虑整个问题时尽可能多的保持有效。看起来这里把问题分解为两个不相关各含一半元素的部分是有道理的。当我们找到每个子集中最小的距离后,我们只需要关心那些靠近集合边界的点之间的距离。距离来说,对所有点进行排序最简单的方法是按照它们的x坐标进行排序,把平面用一条垂直线进行分割从而把集合一分为2(见图4)。(如果有一些点位于垂直线上我们任意把它们分配给两个集合中的一个,从而确保两个集合有相等的元素)我们选择这样划分的原因是使得合并解答时要做的工作尽可能少。如果这两个部分以某种方式交叉着,那样会使得对最近对点的检查变得更复杂。排序需要仅被执行一次。
给定一个集合P,我们按照上面的做法把它分解为P1和P2两个数量相等的子集。然后我们通过归纳法去查找每个子集中最近的两点距离。我们假设P1中最短的距离是d1,P2中是d2。不失一般性的,我们进一步假设d1≤d2。我们需要找到整个集合中最小的距离,也就是说我们需要去查找P1中的一个点到P2中的一个点是否有小于d1的距离。首先我们注意到只需要考虑以两部分中间的垂直线为中心宽度为2d1的带状范围内的点就足够了(见图4)。在该区域外的点中任意两点之间不可能拥有比d1更小的距离。通过上面的观察我们通常能够把很多点从考虑中排除,但是在最坏的情况下所有的点都可能仍位于这条带状区域中,对于它们我们无法使用直接的算法。

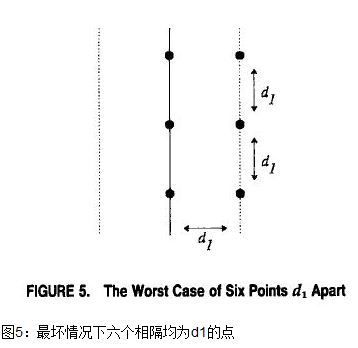
另一个不是那么明显的观察点是对于在带中的任意点p,在另一边有很少的点到p点的距离要比d1小。原因在于在带中一边的所有点至少间隔为d1.假设p是带中的一个点,它的y坐标为yp,那么只需要考虑在另一边有坐标yq且满足|yp-yq|<d1的点即可。在带的每一边最多有六个这样的点(见图5中最坏的情况)。结果是如果我们以点的y坐标针对所有带中的点进行排序并且按顺序扫描这些点,我们只需要检查每一个点和按序排列中它的常数个邻居即可(而不是全部n-1个点)。我们在这里省略这个事实的证明(见例子[15])。
最近对算法{首次尝试}
{p1,p2...pn:平面上的点}
begin
按照点的x坐标对点进行排序{该排序只在开始时运行一次}
把集合划分成两个相等的部分
递归计算每个部分中最小的距离
把d赋值为两个最小距离中的最小值
排除出分割线d距离范围外的点
按照y坐标对剩下的点进行排序
按照y顺序扫描这些点并计算每个点和它的五个邻居之间的距离{事实上,4个就够了}
if 这些距离中有小于d的 then
更新d值
end;
复杂度:按照x坐标进行排序需要花费O(nlogn)时间,但是这仅仅需要执行一次。然后我们解决规模为n/2的两个子问题。排除出带状区域以外的点可以在O(n)的时间内完成。接下来在最坏的情况下按照y坐标对剩下的点进行排序需要O(nlogn)步。最终,扫描带中的点并在序列中把它与常数个邻居进行比较需要O(n)步。总的来说,为了在n个点中查找最近对,我们在含有n/2个点的子集中找到两个最近对,然后花费O(nlogn)的时间去寻找两个子集之间的最近对(加上一次按照x坐标进行排序的时间O(nlogn))。带来的递推关系如下:
T(n)=2T(n/2)+O(nlogn), T(2)=1.
这个关系的解答是T(n)=O(n(logn)^2)。这比一个二次的算法要好,但是我们可以做的更好。现在我们来看看归纳法更巧妙的使用方法。
一个O(nlogn)的算法
这里的关键思想是加强归纳假设。由于要排序我们在合并步骤需要花费O(nlogn)的时间。尽管我们知道如何直接解决这个问题,但是它耗时太长。我们能够做到在解决排序问题的同时解决最近对问题么?换句话说,我们想加强归纳假设把排序作为最近对问题的一部分包含进来从而得到一个更好的解法。
归纳假设:给定平面上一个少于n个点的集合,我们知道如何去寻找它们之间的最近距离也知道如何按照y坐标排序后输出该集合。
我们已经知道如果知道如何排序那该怎样去寻找最小距离。因此,唯一需要做的事情是如果我们知道两个含有n/2的子集排序顺序那该如何对整个集合进行排序。换句话说,我们需要把两个有序的子集合并成一个有序的集合。合并可以在线性的时间内完成(见例【1】)。因此,递归关系变成如下:
T(n)=2T(n/2)+O(n), T(2)=1,
这也意味着T(n)=O(nlogn)。该算法和上一个算法唯一的区别是按照y坐标排序时不必每次都从头开始进行。当我们执行时使用加强的归纳假设来进行排序。下面给出的是改进后的算法。该算法是由Shamo和Hoey(见[15])提出来的。
最近对算法 {一个改进的版本}
{p1,p2...pn:平面上的点}
begin
按照x坐标对点进行排序
{该排序只有在开始时执行一次}
把该集合划分为两个相等的部分;
递归的执行下面的步骤
计算每个部分中最小的距离;
按照y坐标对每个部分的点进行排序;
把两个有序的列表合并成一个有序列表;
{请注意我们必须在排除点之前合并,我们需要为下一阶段的递归提供有序的全集}
把d赋值为两个最小距离中的最小者;
排除出分割线d距离范围外的点
按照y坐标对剩下的点进行排序
按照y顺序扫描这些点并计算每个点和它的五个邻居之间的距离{事实上,4个就够了}
if 这些距离中有小于d的 then
更新d值
end;
更强的归纳法(有时也被称为结构化归纳法)的思想在于不仅仅使用定理对于n-1(或者其他小于n的值)成立的假设,也使用定理对所有k(1≤k<n)成立的更强假设。把这种技巧转换到算法设计中需要维持一个含有所有小问题解法的数据结构。因此,该技巧通常引起更多的空间占用。我们给出一个使用这种技巧的例子。
背包问题是一个很重要的优化问题。它也有很多不同的变种,但这里我们只讨论其中的一种变种。
问题:这里有n个不同大小的物品。第i个物品有一个整型的大小ki。问题是找到一个物品的子集使得该集合的大小总和正好为K,或者我们确定不存在这样的子集。换句话说,给我们一个大小为K的背包我们想把它装满物品。我们把这个问题表示为P(n,K),第一个参数表示物品的数目,第二个参数表示背包的大小。我们假设大小是固定的。我们用P(j,k)(j≤n且k≤K)表示有j个物品和大小为k的背包问题。为了简化,我们仅关心问题的结论,也就是决定是否存在这样的一个解答。在后面我们给出如何去寻找到一个解答。
我们首先从最直接的归纳法开始。
归纳假设:我们知道如何去解决P(n-1,K)的问题。
基本情况很简单,如果仅有一个大小为K的物品有办法解决。如果有解决P(n-1,K)的办法,也就是说如果有能够把n-1个物品放入背包的方法我们就算完成了。我们只需要简单的不使用第n个物品即可。然而,假设没有对P(n-1,K)的解决方法,我们能够使用这个否定的结论么?答案是可以的,这也意味着第n个物品必须被包含进去。在这种情况下,剩下的物品必须装入一个更小的容量为K-kn的背包。我们把问题简化为了两个更小的问题:如果P(n,K)有解那么P(n-1,K)或者P(n-1,K-kn)两者中间必须有一个有解。为了完成这个算法我们不仅需要求解容量为K的背包问题也需要求解对最大容量为K的所有背包的问题。(这里存在把背包容量限制在一些减去ki后的大小之中,但是也可能不存在这样的限制条件)
更强的归纳假设:我们已经知道对所有的0≤k≤K如何去求解P(n-1,k)。
上面的简化并不依赖于一个特定的k值,它对所有的k值都是有效的。我们可以使用这个归纳假设解决所有的0≤k≤K的P(n,k)问题。我们把P(n,k)简化为P(n-1,k)和P(n-1,k-kn)这两个问题。(如果k-kn<0我们就忽略第二个问题)这两个问题都可以用归纳法求解。这是一个有效的简化我们也能找到一个算法,但是该算法效率不高。我们得到的仅是规模稍小一点的两个子问题。因而在对规模的每步简化中子问题的个数也是翻倍增长。由于对规模的简化可能不是那么确切,算法可能是按照指数级增长。(根据ki的值来确定)
幸运的是,在很多情况下对这种问题提高运行效率是可行的。主要的观察是可能的问题的总数不是很多。事实上,我们引入P(n,k)这个记号来表示该问题。对第一个参数存在n种可能性,对于第二个参数存在K种可能性。总的来说,这里只有n*K种不同可能性的问题。在每次简化后对问题数目翻倍会带来指数运行时间,但是如果这里只有n*K个不同的问题我们肯定对同一个问题求解了多次。如果我们记下了所有的解答我们就不需要对同一个问题求解两次。这实际上是加强归纳假设和使用更强的归纳法(使用对所有已知的更小规模问题而不仅仅对n-1问题解答的假设)的结合。下面来看看我们如何实现该方法。
我们把所有已知的结果存放在一个n×K的矩阵中。矩阵中第ij个位置包含着P(i,j)的解答信息。使用上面更强的归纳假设后,问题简化为基本上计算矩阵的第n行值即可。第n行的每个条目是通过其上的两个条目计算得到的。如果我们对找到实际的集合感兴趣的话,我们可以在每个位置加上一个标记字段,该字段可以表示在那步操作中对应的物品是否被选中。标记字段可以从第(n,K)个位置倒推,集合也可以被复原。这个算法列在下一列顶部。
背包算法{k1,k2...kn,K:整型};
{如果对于前i个元素和容量为j的背包有解那么P[i,j].exist=true,如果第i个元素包含在解中那么P[i,j].belong=true}
begin
P[0,00].exist:=true;
for j:=1 to n do
P[0,j].exist:=false;
for i:=1 to n do
for j:=0 to K do
P[i,j].exist:=false;{默认值}
if P[i-1,j].exist then
P[i,j].exist:=true;
P[i,j].belong:=false;
else if j-ki≥0 then
P[i-1,j-ki].exist then
P[i,j].exist:=true;
P[i,j].belong:=true;
end;
复杂度:矩阵中有n×K个条目,从两个不同条目计算出一个条目需要常数时间。因此,总的运行时间是O(nK)。如果物品的大小不是特别大,那么K就不可能太大并且nK比n的指数表示要小很多。(如果K非常大或者是一个实数,那么这种方法就不高效)如果我们只关心确定是否存在一个解答那么答案就在P[n,K]中。如果我们对找到实际的集合感兴趣,我们可以从第(n,K)个条目倒推,例如使用背包程序中的belong标志位,在O(n)时间内复原这个集合。
结论:我们刚才使用的是一种常见技术方法的一个具体实例,该方法被称为动态规划,它的本质是建立一个巨大的表,在表中填入已知的之前的解答。该表是用迭代的方法进行构造的。矩阵中的每个条目都是从其上或左侧的其他条目计算得到的。主要的问题是用一种最有效的方法进行表的构造。动态规划在问题仅能被简化为几个不是足够小的子问题时是有效的。
在证明数学定理中一种有特色并且强大的技巧是假设定理的反面成立然后找到一个矛盾。通常这是用一种完成非建设性的方式实现的,这对于我们的类比不是很有用。虽然有时通过一种和归纳法类似的方法能够找到一个矛盾。假设我们想证明一个确定的变量P(在一个给定的问题中)能够取到一个确定的值n。第一步我们给出P能够取到一个小值(基本情况)。第二步我们假设P无法取到n,我们可以考虑它能取到的最大值k<n。最后以及最主要的步骤是给出一个矛盾,通常针对最大化的假设。我们给出一个算法设计的例子,在该例子中这种技术非常有用。
在无向图G=(V,E)中一个匹配也就是一个没有公共顶点的边的集合。(一条边对应于两个点,一个点不可能对应于多余一个顶点)最大匹配是一个无法拓展的问题,意味着所有其他的边都至少与一个匹配的顶点相连。一个最大匹配也就是一个最大集。(一个最大匹配总是最大的,但是反过来说却未必正确)在图中一个拥有n条边和2n个点的匹配被称为最优匹配。(显然也是最大的)在这个例子中我们考虑一种很有限的情况。我们假设图中有2n个点,所有顶点的度都至少为n。可知在这些条件下总存在一个最优匹配。我们首先给出这个事实的证明,然后展示如何去修改这个证明从而得到一个查找最优匹配的算法。
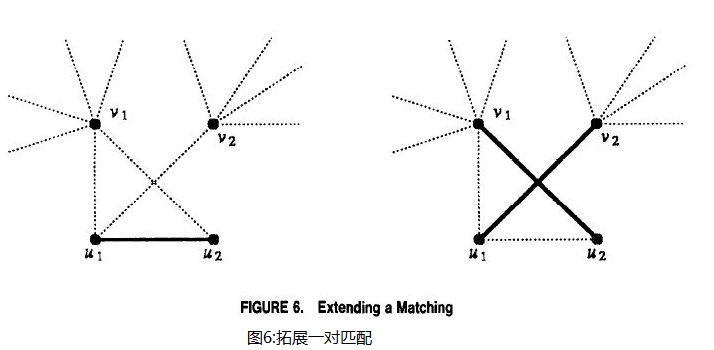
证明采用的是最大的反例。考虑一个图G=(V,E),其中|V|=2n每个顶点的度至少为n。如果n=1那么这个图仅仅有一条边连接两个顶点,这就是一个最优匹配。假设n>1时不存在这样一个最优匹配。考虑到最大匹配M属于E。由假设知|M|<n,同时由于任意一条边自己就是一个匹配显然有|M|≥1。既然M不是完全的(不包括所有的点),那么就存在至少两个不相邻点v1和v2不被包含在M中(即它们不对应M中的一条边)。这两个点至少有2n个不同的边从它们射出。所有这些边通向那些包含在M中的顶点,否则这样的边就不可能被加入到M中。由于M中边的数目小于n而且从v1到v2有2n条边与之相连,M中至少有一条边,假定为(u1,u2),与从v1到v2的三条边相连。为了不失一般性,我们假设这三条边是(u1,v1),(u1,v2)和(u2,v1)(见图6)。很容易可以看到通过从M中移除(u1,u2)加上边(u1,v2)和(u2,v1)我们能够得到一个更大的匹配,这与之前最大的假设相矛盾。
第一眼看上去这个证明好像无法产生一个算法,因为证明是从一个最大匹配开始的。一旦我们知道如何去寻找这样一个匹配我们就能够解决这个问题。然而,使用反证法适用于任何最大化的匹配,这里展示的只是用于最大匹配而已。查找一个最大化的匹配要比查找一个最大匹配简单。我们只需要简单的添加不相连的边(即那些没有公共顶点的边)直到不存在这样的边的可能。然后我们使用上面描述的步骤把该匹配转换为一个更大的匹配。通过上面的证明我们可以不断反复执行直到找到一个最优匹配。
在这篇论文中我们关注于基于归纳法的证明技巧。这里有很多其他的技巧和更多的类比,一些事很明显的,一些则不那么明显。许多数学定理的证明是使用一系列的前提得到的,这直接对应于在标准设计和结构化编程的思想。证明中使用反证法在算法设计中也有类似的地方。研究那些使用“类似的论据”证明的类比是很有趣的一件事。
我们这里简要列出四个证明技巧(其中的三个是基于归纳法的)以及它们的类比。更多的例子和类比可以在参考文献[12]中找到。
在证明定理和设计算法时,在问题之间使用缩减是一种很强大的技巧。如果问题A被指明是问题B的特例,那么解决B的算法可以被当成一个黑盒用来解决A。这个技巧对于解决下界和对问题进行分类也很有效(例如NP-完全问题)。如果已知问题A很难,那么问题B也至少一样难。
这是一种使用归纳法针对一次多余一个变量的方法。它可用于在归纳法最佳序列不明确的情况,同时在针对几个变量依据一个特定的步骤在其中进行选择时,该方法也很容易使用到。例如,如果问题包含n个物品和一个k维空间时,我们可能想在算法执行时减少物品的数量或者物品尺寸的数量【见例4】。
这个技巧在数学中不经常使用,但是在计算机科学领域却经常使用。普通的归纳法通过从一个基本情况(n=1)开始然后不断推广从而覆盖所有的自然数。假设我们想要逆推。我们假设它对n成立想要证明它对n-1也成立。我们称这种类型的证明为逆向归纳。但是,什么是最基本的情况呢?我们能够从一个n=M(M是一个非常大的数)的基本情况开始。如果我们证明它对n=M成立,然后我们就可以使用逆向归纳法从而证明对所有小于等于M的数也成立。尽管通常这样是不符合要求的,但在一些情况下却是满足要求的。例如,假设我们把双倍归纳法用于两个变量(即图中的顶点数和边数)。我们可以对一个变量应用普通的归纳法,如果第二个变量能够在第一个变量的范围内有界,那就对第二个变量使用逆向归纳法。例如,在一个有n个顶点的有向图中最多由n*(n-1)条边。对于n我们可以使用普通的归纳法并假设所有的边都是存在的(也就是说我们仅仅考虑完全图),然后对边的数目使用逆向归纳法。
一种更常见的使用逆向归纳法的做法如下。仅对n中一个值的基本情况证明能限制于对那些比该值更小的值的证明(补充:证明了一个值比它小的值也就可以证明了)。假设我们能够直接对一个n取值无限的定理加以证明。例如无限集中包含所有2的幂。那么我们就可以使用逆向归纳法覆盖n的所有值。这是一种有效证明技巧,因为对于每个n取值在基本集中都存在一个比其大的值(由于集合式无限的)。
使用这种技巧的一个非常好的例子是在算术平均不等式和几何平均不等式(柯西不等式)中用到的优雅的证明方法(例子见[3])。当证明数学定理时,从n到n-1往往不比从n-1到n简单,同时证明一个无限集的基本情况要比一个简单集的基本情况困难的多。在设计算法时,与之相反的是,从n到n-1总是很容易,也就是针对更小的输入规模的问题求解。例如,我们可以引入那些不影响输出的假数据。结论是,在很多情况下不根据输入量的各种大小而是根据从无限集中取得的大小来设计算法往往是充分的。最常见的使用这种原理的做法是在设计算法时仅考虑是2的幂的n的大小输入。这使得设计更简洁也排除了很多杂乱的细节。很显然这些细节最终也需要被解决,但是它们往往很容易处理。例如在最近对问题中,我们使用n是2的幂的假设。
很多递归算法(例如快排)对于小问题而言效果并不是很好。当问题被简化为一个小问题时,可以使用另一种简单的算法(例如插入排序)。从归纳法来看,这中做法符合选择一种n=k(k依据问题来定)基本情况然后使用一种直接的技巧来解决这种基本情况的思想。有些例子中这种做法甚至能够改善算法的渐近运行时间[12]。
我们展示了一种解释和使用组合算法设计的方法。使用这种普通的方法的好处是两方面的。首先,它给算法设计者们提供了一个更加统一的“进攻路线”(处理问题方法)。给定一个待解决的问题,一个人可以通过使用文章中描述和阐明的技巧尝试找到一个解法。由于这些技巧有一些相似的地方(也就是数学归纳法),对它们全部进行尝试的过程能够被更好的理解也更容易进行。第二点,它提供了一种解释现有算法的的更统一的方法,使得学生能更多的参与创造过程。同时,对于算法正确性的证明在描述中占更重要的部分。我们相信这种方法能够包含在对组合算法进行教学之中。
感谢:感谢Rachel Manber带来很多关于归纳法和算法极富启发式的对话。感谢Greg Andrews, Darrah Chavey, Irv Elshoff,Susan Horwitz, Sanjay Manchanda, Kirk Pruhs, and Sun Wu在手稿的改进方面提供了很多有益的意见。
使用归纳法设计算法
在数学定理证明和计算机算法设计之间采用类比的思想能够为算法设计提供一个极好的方法,通过解释这种做法来了解这种关键思想,从而对此有更深的理解。这篇文章在进行组合算法设计和教学过程中展示了一种基于数学归纳法的方法,尽管这种方法并不能涵盖设计算法时的所有可能方法,但它包含了大部分已知的技术方法。同时这种方法也提供了一个极好的并且也是直观的结构,从而在解释算法设计的时候显得更有深度。这种方法的核心是通过对数学定理证明过程中和设计组合算法过程中的两种智力过程进行类比。尽管我们承认这两种过程是为不同的目的服务的并且取得的是不同类型的结果,但是这两者要比看上去的更加相似。这种说法可以通过一系列的算法例子得到验证,在这些算法中都可以采用这种方法进行设计和解释。我们相信通过学习这种方法,学生能够对算法产生更多的热情,也能更深入更好的理解算法。
数学归纳法是一个非常强大的证明方法。使用如下:让T是一个我们想证明的定理。假设T包含一个值可为任意自然数的参数n。我们不需要直接证明T对所有的n都成立,我们只需要证明以下两点:(1)T对n=1时成立 (2)对于任意的n>1,T对于n-1成立。第一点往往很容易证明,证明第二点在很多情况下要比直接证明定理要容易,因为此时我们可以假设T对n-1已经成立。(从某种意义上来说,我们无条件的获得这一假设)。换句话说,减小定理的规模使用一个更小的n值而不是从头开始证明是很有帮助的,我们关注的就是这种减小。
这一原则对于算法同样也适用。归纳法让人们关注于从较小的子问题延伸到那些更大的问题上。可以通过从问题的任意一个实例入手,通过假设规模较小的相同问题已经得到解决,然后再试图解决该问题。例如,给定一个n(n>1)的序列对其进行排序(排序一个序列显然没必要),我们可以假定已经知道如何对n-1个数进行排序。然后我们可以要么排序前n-1个数,然后把第n个数插入到正确位置(这引出了一个叫插入排序的算法),要么一开始把第n个数放在它的最终位置然后再排序剩下的数(这引出了一个叫选择排序的算法)。我们只需要解决对第n个数的操作(当然这并不是唯一的排序方法,也不是唯一一种使用归纳法进行排序的方法)。
上面介绍的使用归纳法的例子很直观,然后有许多不同的方法来使用归纳法,由此带来了不同的算法设计技巧。这是一个非常强大和灵活的方法。我们将证明,在使用这种想法时很多问题变得很简单,这一点会让你惊讶不已。我们将采用其中的几种方法,并显示它们在设计算法时的强大力量。在我们讨论的归纳法的各种变形方法中,我们主要讨论巧妙的选择归纳序列,增强归纳假设,更强的归纳法以及最大的反例四种方法。
我们的处理方法有两种新奇之处。首先我们把看上去不同的算法设计技术归到同一个类别下,这将使得对一个新算法的查找更有条理性。其次,我们利用已知的数学证明技巧来设计算法,这一点很重要,因为它开启了利用在别的学科多年发展过程中形成的强大的技术进行算法设计的时代。
一般而言,在算法领域使用归纳法和数学证明技巧并不是第一次见到。归纳法在证明算法正确性上已经使用了很长时间,人们通过把对算法执行步骤的断言,证明它们在最初情况下成立和它们在特定操作步骤下保持不变结合起来,从而验证算法的正确性。这种方法最初由哥特斯和冯诺依曼提出的,后来由弗洛伊德和其他人对其进一步发展。Dijkstra和格里斯提出了一种和我们开发程序相似的方法,同时他们也给出了对其正确性的证明。尽管在此我们借鉴了他们的一些技术,但我们的重点却不同:我们关注于高层次的算法理念而不必下降到实际的程序层面。PRL和NuPRL(这里不会翻译,建议看http://www.cs.cornell.edu/info/projects/nuprl/book/node2.html)使用数学证明作为一个程序开发系统的基本构成。当然递归也被广泛用于算法设计之中(对于递归的详细讨论请看...)
我们的目标主要是用于教学,我们假设读者对数学归纳法和基本的数据结构已经很熟悉。对于任意一种证明技巧我们会对其类比进行一个简要的解释,然后给出一个或多个算法例子。对于给出的算法例子我们重点关注于如何使用这种方法。我们的目的不是在于对一个算法进行解释从而帮助一个程序员更容易地将其转换为程序,而是通过一种更容易理解的方式对其进行解释。这些算法通过一种创造性的过程加以解释而不是以一种成品的方式出现。我们教算法的目标不仅仅是向学生展示如何解决当前特定的问题,同时也是帮助他们解决未来新的问题。教学生如何把想法融入到算法设计中和教学生解决方案的实现细节同样重要。但前者通常要更难一些。我们相信我们的方法能够加强对这种思维过程的理解。
尽管归纳法建议通过递归加以实现,但也未必如此。(事实上我们称这种方法为归纳而不是递归,从而淡化递归实现的概念)在很多情况下,迭代也很容易,甚至尽管在算法设计中我们心里想的是使用归纳法(递归),但迭代却更有效率。
本文中提到的这些算法是经过筛选的,以便能更好的展现这种方法的魅力。我们选择的是一些简单的问题,在后续部分选择一些更复杂的例子。我们发现很多固定的算法在算法设计课上第一次教授时可以使用这种方法。(使用这种方法的算法导论书很快就要出来了)我们首先从三个简单的例子入手,(至少使用归纳法让他们看上去简单了)然后我们展示一些数学证明技巧以及它们在算法设计中类似的技巧,在每种情况下这种类比都在一个或多个例子中得到了阐明。
三个例子
计算多项式的值【Q1】
问题:给定一个实数序列an,an-1,...a1,a0和一个实数x,计算下面这个多项式的值
Pn(x)=an*x^n+an-1*x^(n-1)+...a1*x+a0
这个问题看上去并不像是一个使用归纳法求解直观例子,尽管如此,我们将证明使用归纳法能够直接带来很不错的解决方法。我们首先使用最简单几乎微不足道的方法求解,然后通过发现其中的变化,从而找到更好的解决方案。
这个问题涉及到n+2个数字。使用归纳法解决该问题的依据是对一个更小的问题进行求解。换句话说,我们尽量减小问题的规模,然后使用递归求解。(或者我们称其为归纳)第一步尝试是移除an,这将导致问题中计算的表达式变成:
Pn-1(x)=an-1*x^(n-1)+an-2*x^(n-2)+...+a1*x+a0
除了规模外这是一个同样的问题。因此我们可以使用下面的假设运用归纳法对其进行求解:
归纳假设:我们已经知道如何去计算一个多项式,该多项式在x处的输入项有an-1,...a1,a0(即我们知道如何计算Pn-1(x))
我们现在可以使用这假设运用归纳法来解决该问题。首先我们需要解决最基本的情况,也就是计算a0;这是很简单的。然后我们必须表明如何通过借助规模较小的问题的解决方案(这里是Pn-1(x)的值)来解决原有问题(即计算Pn(x))。在该例子中这是很直观的。我们仅仅需要计算x^n,乘以an然后加上Pn-1(x)即可。
在这一点上看上去使用归纳法很无聊因为它仅仅是复杂了一个简单的解决方案,上面提到的算法仅仅是按照多项式的数学方式对多项式从右到左进行计算而已。然而,我们很快就会看见这种方法的强大之处。
尽管这个算法是正确的,但其并不是高效的。它需要n+n-1+n-2+...+1=n(n+1)/2次乘法和n次加法计算。现在我们略微改变一下归纳法的使用方法,从而得到一个更好的解决方案。
改进:第一个改进之处在于我们注意到在求解过程中存在很多冗余计算:x的指数是从头开始计算的。当我们计算x^n时通过使用x^(n-1)的值能够帮我们节省很多乘法运算。这些都是在归纳法假设中通过对x^n计算的归纳得以实现的:
更强的归纳假设:我们已经知道了如何去计算多项式Pn-1(x),同时我们也知道如何计算x^(n-1)的值。
这个归纳假设更强一些,因为它要求计算出x^(n-1),但是它拓展起来更容易。我们在计算x^n时仅仅需要进行一步乘法操作,然后在进行一步乘法操作得到an*x^n,然后进行一步加法操作完成整个计算。(其实这个假设并不是太强,因为我们还是需要计算x^(n-1)的值)。总而言之,这里需要进行2n次乘法和n次加法。尽管这个归纳假设需要更多的计算,但总的说来它减少了工作量。我们在后面再来讨论这一点。在各种层面上看来这个算法很好,它高效,简单也容易实现。然而存在一个更好的算法,它是通过用一种不同的方式使用归纳法得以实现的。
我们通过移去最后一个系数an来简化问题。(这是一个很直截了当的做法)但是我们也可以移去第一个系数a0。这个规模更小的问题变成了计算由an,an-1...a1这些系数组成的多项式,如下所示:
P'n-1(x)=an*x^(n-1)+an-1*x^(n-2)...+a1
(注意到an现在是n-1次的系数,后面依次改变)
新的归纳假设(倒序):我们知道如何去计算由系数an,an-1...a1构成的x多项式(即上面列出来的P'n-1(x))
由于这个假设更容易拓展,故其更符合我们的目的。很明显Pn(x)=x*P'n-1(x)+a0。因此这里仅仅只要一次乘法和一次加法就可以通过P'n-1(x)计算得出Pn(x)。完整的算法可以通过下面这个表达式加以描述:
an*x^n+an-1*x^(n-1)+...+a1*x+a0=((...((an*x+an-1)x+an-2)...)x+a1)x+a0
这个算法被称为霍纳归纳以W.G.Horner命名。(这也是牛顿提出来的)。下面给出了计算多项式的算法。
计算表达式算法
(a0,a1,a2...an,x:real); //输入a0至an,x,全为实数
begin
P:=an;
for i:=1 to n do
P:=x*P+an-i;
end;
复杂度:这个算法仅仅需要n次乘法,n次加法以及一个额外的内存空间。尽管原先的解决方法看上去简单并且高效,但追求一个更好的算法是值得的。这个算法不仅仅是速度更快,同时相应的程序也更简单。
总结:上面给出的简单例子阐明了归纳法使用过程中的灵活性。霍纳规则的技巧仅在于考虑到输入是从左向右的,而不是直观上看到的从右向左。
当然这里有使用归纳法的许多其他潜在性,我们将在更多的例子中看到这一点。
找到一一映射关系【Q2】
f是一个把有限集合A映射到其自身的函数。(例如A中的每一个元素都映射到A中的另一个元素)为了简化起见,我们把A中的元素表示为从1到n的数字。我们假定函数f以一个数组f[1..n]的形式出现,这样f[i]存放的是f(i)的值。(该值是一个位于1到n之间的整数)当A中的每一个元素都仅仅只有一个元素对应它时我们把函数f称为一一映射。函数f可以用图1中的图加以展示,在图中,两端数据都对应同一个集合,图中的边表示映射关系。(这种映射关系是从左至右的)
问题:找到一个包含最多元素的子集S(ScA),使得函数f能够把S中的任何元素映射到S中的其他元素。(即f让S映射到自身),同时S中的每一个元素仅仅只有唯一的一个S中的元素映射到自身。(即限制S让f成为一个一一映射)
如果f本来就是一个一一映射,那么全集A就满足了问题的条件,显然它也是最大的集合。在另一个方面来说,如果f(i)=f(j)存在且i≠j,那么集合S就不能同时包含i和j。例如在图1中S就不能同时包含2和3。不可能任意从两者中选择一个从集合中剔除出去。例如,假设我们决定删去3,由于1被映射到3,所以我们也必须删去1。(因为任意映射必须映射到S中而此时3已经不在S中了)。但是如果1被排除了,那么2也会因为同样的原因被删去。但是,这样得到的结果集不是最大的,因为我们很容易就能看到可以只删去2即可。这个问题其实是让我们去找到一种通用的方法来决定集合中包含哪些元素而已。
使用归纳法求解的思想集中在缩减问题的规模上,这种方法使用起来也很灵活。我们可以通过寻找一个要么属于S中的元素或要么不属于S中的元素来缩减问题规模。我们将在后面进行这一操作。我们先使用简洁明了的归纳假设:
归纳假设:我们已经知道如何去解决一个含n-1个元素集合的问题。
最基本的情况很简单:如果集合中只含有一个元素,集合必须映射到自身,这就是一个一一映射。假设我们已经有了一个含有n个元素的集合A,现在我们寻找一个满足问题条件的子集S。很显然找到一个不属于S集合的元素要比找到一个包含在S集合中元素简单。我们可以认为任何一个元素i如果没有被其他元素映射,那么i不可能包含在S中。(换句话说,在图右侧的元素i,如果没有一条边与之相连,那么i不可能在S中)否则的话,如果i∈S,假设S中有k个元素,那么这k个元素最多映射到k-1个元素,因此这个映射不可能时一一映射。如果存在这样的i,我们仅需要把i从集合中移除即可。我们现在有一个含有n-1个元素且让函数f映射到自身的集合A'=A-{i}。通过归纳假设我们知道如何去求解A'。如果不存在这样的i,那么映射就是一一映射,这样我们就解决了问题。
这种解法的关键在于我们必须移除i。我们在上面证明了i不可能属于S集。这是归纳法的优势之处。一旦我们移除了一个元素缩减了问题的规模我们就算完成了。然而我们必须格外小心,缩减后的问题和原问题几乎是一样的。(除了规模外)对于集合A和函数f的唯一条件就是f让A映射到自身。由于并没有元素映射到i,这个条件对于A-{i}后的集合依然成立。当没有元素可以移除的时候这个算法也就执行结束了。
实现:上面的算法是通过使用递归的过程加以描述的。在每一步中我们找到一个没有其他元素映射到它的元素,移除它,然后继续递归执行。然而实现方法并不需要用递归。我们可以对每一个元素i使用一个计数器c[i]。初始情况下c[i]需要和映射到i的元素数目相等。这可以通过扫描数组(进行n步)以及增加对应的计数器值而计算出来。然后我们把所有计数值为0的元素放在一个队列中。在每一步执行中,我们移除队列中的元素j(同时也移除集合中的对应值)。减小c[f(j)]的值,如果c[f(j)]=0,我们就把f(j)放在队列中。当队列为空时算法执行结束。算法描述如下:
映射算法(f:整型数组[1..n])
begin
S:=A{A是从1到n的数字构成的数组}
for j:=1 to n do c[j]:=0;
for j:=1 to n do increament(c[f(j)]);
for j:=1 to n do
if c[j]=0 then put j in Queue;
while Queue is not empty do
remove i from the top of the queue;
S:=S-{i};
decrement c[f(i)];
if c[f(i)]=0 then put f(i) in Queue
end;
复杂度:初始化部分需要O(n)的操作时间,每一个元素最多有一次机会被放置到队列中,把元素从队列中移除只需要常数时间。步骤的总数是O(n)。
总结:在本例中减少问题的规模主要在从集合中删除元素上。因此我们试图在不改变问题条件的情况下寻找一种最简单的方法来移除元素。由于对于函数的唯一的要求是它必须把A映射到自身,故我们会很自然地选择一个没有其他元素映射到的元素。
检查线段的包含情况【Q3】
问题:输入是一条线上一系列间断线段的集合I1,I2...In。对于每一个线段Ij都给出了它的两个端点Lj(左端点),Rj(右端点)。我们想标记出所有包含在其他线段中的线段。换句话说,一个线段Ij必须被标记出来,如果存在另一条线段Ik(k≠j)并且满足Lk≤Lj以及Rk≥Rj。为了简化起见我们假定所有的线段都是不一样的(例如任意两个线段都不可能同时具有相同的左端点和右端点,但是它们可能有两个端点中的某一个相同)。图2展示了这样的一个线段集合。(为了更好的展示,每一条线段都放在另一条线段上面而不是放在一条线上)
用直观的方法使用归纳法主要是移除一个线段I,对于剩下的线段使用递归的方法加以解决,然后在检查把I放回后的效果。问题在于把线段I放回需要检查所有其他的线段来判断他们中是否包含I或者被I所包含。这需要检查I和其余n-1条线段,算法中使用的比较将达到n-1+n-2+...+1=n(n-1)/2次。为了获得一个更好的算法我们需要做两件事:首先我们选择一条特殊的线段加以移除,其次我们尽可能多的使用从更小规模问题的解决方案中收集到的信息。
选定I为所有线段中具有最大左端点值的线段,由于其他线段左端点值都较之小,这样就不需要再检查左端点值了。因此,为了要检查I是否包含于其他线段之中,我们只需要检查其他线段中是否有右端点值比I右端点值更大的线段。为了找到这么一条具有最大左端点值的线段我们可以依据线段的左端点值对所有线段进行排序并且按照次序对其进行搜索。假定线段已经按照次序排好,L1≤L2≤...≤Ln。归纳假设如下:
归纳假设:我们已经知道如何去解决包含I1,I2...In-1条线段的问题。
最基本的问题很简单,如果只有一条线段,那么它肯定不会被标记。现在我们来考虑In。通过归纳假设我们知道已经确定了在线段I1到In-1中有哪些线段是包含在其他线段之中的,我们需要确定In是否包含其他(之前没有被标记过)的线段,以及In是否被包含在其他线段之中。让我们首先来检查In是否被包含在其他线段之中。如果In被包含在一条线段中,假如是Ij,j<n,于是Rj≥Rn。这是唯一的必要条件(因为排序已经确保了Lj≤Ln)。因此我们只需要在之前的线段中记录拥有的最大右端点值即可。把该右端点值与Rn进行比较就能给出我们答案。我们稍微改变一下归纳假设:
更强的归纳假设:我们已经知道如何解决I1,I2...In-1的问题,同时也找出了他们中右端点的最大值。
我们再一次让In作为拥有最大左端点值的线段,然后让MaxR作为前n-1条线段中右端点的最大值。如果MaxR≥Rn,那么In就应该被标记,否则(MaxR≤Rn)Rn就成为新的最大的最大值。(这最后一步是必要的,因为我们现在不仅仅是标记线段,同时我们也在寻找最大的右端点值。)我们现在仅通过一步检查就能确定In的状态。
为了完成这个算法我们需要检查In是否包含一条之前未被标记过的线段。In包含一条线段Ij,j<n,只有当满足条件Lj=Ln且Rj<Rn时才行。我们可以通过增强排序功能来处理这种情况。现在我们不仅按照左端点值进行排序,同时对于具有相同左端点值的线段,我们依据他们的右端点值的逆序来进行排序。这样能够排除上面提到的情况出现,因为Ij将会放置在In之后(右端点值较小),而且Ij的包含性将会被上一个算法找到。完整的算法如下所示:
线段包含性算法
(I1,I2,...In:线段)
{用一对Lj,Rj来给出一条线段Ij}
{我们假定没有两条线段是完全一样的}
{当Ij被包含在另一条线段中时,Mark[j]将会被标记为真}
begin
按照线段的左端点值递增次序对所有线段进行排序
具有相同左端点值的线段按照他们右端点值递减的次序进行排序
{for all j<k either Lj<Lk or Lj=Lk and Rj>Rk}
MaxR:=R1;
for j:=2 to n do
if Rj≤MaxR then
Mark[j]:=true;
else
Mark[j]:=false;
MaxR:=Rj;
end;
复杂度:除了排序外,这个算法包含一个涉及到O(n)步操作的循环。由于排序需要O(nlogn)步操作,故其占据了算法主要的运行时间。
总结:这个例子阐明了一个不是那么直接运用归纳法的方法。首先我们选择可以运用归纳法执行的序列。然后我们设计归纳假设,该假设能够暗示出期望的结果同时它也易拓展。重点放在这些步骤上就能让对很多算法的设计变得简单。
明智的选择归纳序列
在前面的例子中,重点都放在寻找一个缩减问题规模的算法上。这是使用归纳法的本质。然而有很多方法也能实现这一点。首先,问题可能包含一些参数(例如图中的左端点右端点,顶点和边),我们必须决定对其中哪一个参数进行缩减。其次,我们可能能够排除掉许多可能元素,但我们想选择其中最容易的一个。(例如最左边的端点,最小的数字)第三,我们可能想对问题加强限制条件(例如线段是有序排列的)。当然还有其他很多变化。例如我们可以假设我们已经知道对一些小于n的值的问题如何解决而不是仅仅的n-1。这往往是一个有效的假设。任何缩减问题规模的做法都是值得考虑的,因为这种做法能够引导我们回到问题的最基本情况,而这时往往我们能够直接解决。回到在归纳法中讨论的排序例子,我们可以把对n个元素的排序缩减为对两个各含n/2个元素的子集的排序。然后可以对这两个排好序的集合进行合并(引出一个称为归并排序的算法)。把问题分解(归纳性的)为一些相同的部分是一个很有用的技巧(我们将会在后面进行讨论),该技巧称为分治。
一些问题的缩减很容易就能实现,然而一些却很难实现。一些规模的缩减能够带来很不错的算法,然而一些却不行。在很多情况下这就是问题中唯一的困难之处,一旦做出了正确的选择那么剩下的就很容易了(例如在映射问题中元素i的选择那样)。这在数学中极其重要。没有人能够不通过首先思考如何选择一个归纳序列就直接跳到归纳证明中去。正如估计的那样,这在算法设计中也是很重要的。在这一部分我们将给出两个例子,在这两个例子中,缩减序列的重要性得到了体现。特别是名人的例子,它说明了一种不同于一般的顺序。
拓扑排序【Q4】
假设这里有一系列的任务,这些任务每次只能执行其中一个。其中有一些任务要依赖其他任务的完成,如果其他任务没有完成则这些任务不可能开始执行。已知所有的依赖关系,我们想找到一个符合依赖关系的任务安排计划表。(即每一个被计划执行的任务只有在它依赖的任务全部完成时才可以开始执行)我们想要设计一种能够迅速产生出这么一个计划表的算法。该问题也就是拓扑排序。任务和他们的依赖关系能够通过一幅有向图得到展现。一个有向图拥有一个顶点的集合V(与例子中的任务相对应),以及一个由一对顶点构成的边的集合E。如果一个与v对应的任务必须在一个与w对应的任务之前执行,那么图中就存在一条从v到w的边(表示(v,w)∈E)。该图一定为无环图,否则环上的任务将永远不可能开始执行。这里给出了使用图来说明问题的简单描述。问题:给定一个有n个顶点的有向无环图G=(V,E),这些顶点从1到n进行编号,因此如果顶点v被标记为k,那么顶点v可以通过一条直接路径到达所有编号大于k的顶点。(一条路径是一系列点的序列,这些点v1,v2...vk通过边(v1,v2),(v2,v3)...(vk-1,vk)相连)
我们再一次尝试依据规模更小的问题来解决这个问题。考虑一个更小问题的直接做法是移去一个顶点。换句话说,通过下面的方法可以看到归纳法蕴含在顶点的数量之中。
归纳假设1:我们已经知道如何按照上面描述的条件用n-1个顶点为所有的图做上标记。
只有一个顶点的最基本的情况是很简单的。如果n>1,我们可以移去一个顶点,然后尝试使用归纳假设,再尝试去拓展标记。我们首先需要核实的一点是移除一个顶点后的问题和原来的问题是一样的(除了更小的规模外)。拥有一个一样的问题很必要,否则归纳假设将无法使用。例子中唯一假设是图不是循环图。由于移除一个顶点不可能产生一个循环图,那么这种缩减是可行的。
这种缩减的问题在于尽管假设可以使用但我我们不清楚如何去拓展解决方法,即怎么去标记移除的顶点。我们解决该问题的方案是精心选择顶点v。由于移去任何一个顶点产生的规模更小的问题都是符合要求的,所以我们可以任意选择一个顶点作为第n个顶点。因此,我们应该移除那些最容易获取标记的点。一个明显的选择是那些没有依赖关系的顶点(任务),也就是该顶点的入度(指向该点的边数)为0。可以把该顶点标记为1,这不会带来什么错误。
但是,我们总能找到一个入度为0的点么?答案按直觉是肯定的,但我们必须从某个地方开始。毫无疑问的是,如果所有的顶点都有大于0的入度我们可以用各种方式遍历图而且永远不会停止。但是由于只有有限数量的顶点需要我们去循环查找,这与我们的假设是相矛盾的。(同理我们也可以从出度为0的顶点开始寻找,然后把该顶点标记为n)剩下的算法就很清晰了。移除选择的顶点的相邻边,剩下的图依然是无环图,再用2到n标记图的剩余部分。由于我们需要用2到n而不是1到n-1标记剩下的图,我们需要对归纳假设做点改动。
归纳假设2:我们知道依据问题的条件如何使用n-1不同标记的集合去标记一个拥有n-1个顶点的图。
下面给出与之对应的算法
拓扑排序算法
{G={V,E}:一个有向无环图};
begin
对所有的顶点的入度初始化;
{可以通过深度优先搜索}
G_label:=0;
for i:=1 to n do
if vi.indegree=0 then put vi in Queue;
repeat
remove vertex v from Queue;
G_label:=G_label + 1;
v_label:=G_label;
for all edges(v,w) do
w.indegree:=w.ingegree-1;
if w.indegree=0 then put w in Queue
until Queue is empty
end;
复杂度:初始化入度计数器需要O(|V|+|E|)时间(例如在例子中使用深度优先搜索)。找到一个入度为0的点要花费常数时间(访问队列)。每一条边(v,w)被考虑一次(当v从队列中被取出时)。因此,计数器需要更新的次数的多少就是图中边数目的多少。因此算法的执行时间就是输入规模的线性时间O(|V|+|E|)。
总结:这是另一个使用归纳法直接设计算法的例子。这里的技巧在于明智选择归纳序列。我们不是武断地缩减问题规模,而是选择移除一个特殊的顶点。任何给定的问题的规模都可以用很多可能的方法加以缩减。思想就在于探寻各种各样的选择然后测试产生的算法。我们从多项式计算这个例子中看到从左向右要比从右向左好。另一个通常的可能性是对从上往下和从下往上进行比较。同样也可能每次递增2而不是递增1,当然还有更多的可能情况。有时最好的归纳序列甚至对于所有的输入来说也是不尽相同的。设计一个特殊的算法去寻找一个对问题执行规模缩减的最好的方法有时是值得的。
名人问题【Q5】(不知道业界如何翻译)
在算法设计中有一个很流行的练习。这是一个非常好的例子,该例子的解答不需要扫描全部数据(甚至是数据的重要的组成部分)。在n个人中,一个名人被定义为其他人都认识但是自己却不认识其他人的人。该问题就是存在名人的情况下确定名人,只能通过以一种“您好,请问您认识站在那里的人么?”的方式提问。(假定所有的回答都是正确的,甚至是名人自己也会给出答案)我们的目标是让最小化提问的次数。由于存在n(n-1)/2对人,在最坏的情况下,如果问题被武断地提出,有可能需要询问n(n-1)次问题才行。我们不清楚我们能比最坏的情况做的更好。
在技术上,如果我们建立一个用顶点表示人的有向图,当A认识B就有一条从A到B的边,那么一个名人就对应一个汇点。(非有意的双关语)也就一个入度为n-1出度为0的顶点。该图可以用一个n×n邻接矩阵来表示,如果第i个人认识第j个人那么在该矩阵中位于第i行第j列的位置被标记为1,否则就为0。该问题也就是通过查找矩阵中尽可能少的条目确定汇点。
像往常一样,我们考虑有n-1个人和有n个人时问题的不同之处。既然由定义可知最多存在一个名人,那这里就有三种可能。其一,名人在前n-1个人中;其二,名人是第n个人;其三,这里没有名人。第一种情况最容易处理,我们只需要核对第n个人认识名人,但是名人并不认识第n个人的局面是否存在。其他两种情况就比较困难了,因为为了确定第n个人是否是名人,我们可能需要提2*(n-1)个问题。在最坏的情况下,这可能会导致n*(n-1)个问题(这是我们试图避免发生的)。我们需要另一种解法。
这里的技巧在于从逆向考虑这个问题。确定一个名人可能很难,但是确定某个人不是名人可能要简单很多。毕竟,很明显在这里非名人要比名人多。把某人排除出考虑对把问题规模从n缩减到n-1来说已经足够了。此外,我们不需要排除出特定的人,任何人都可以。假设我们问Alice她是否认识Bob,如果她认识她就不会是一个名人,如果她不认识
那Bob就不会是一个名人。我们可以通过一个问题排除出他们中间的一个。
现在考虑上面列出的三种情况。我们不只是任意挑选一个人作为第n个人。我们使用上面的思想去排除出Alice和Bob中的一个,然后对其余包含n-1个人的问题进行求解。我们保证情况2不会发生,因为排除出去的人不可能是名人。此外,如果情况3发生,也就是说在n-1个人中没有名人,那在n个人中也不会有名人。只有情况1存在,但是正如上面提到的,这种情况很简单。如果在n-1个人中存在一个名人,只需要提出两个问题就可以确定整个集合中是否存在名人了。否则就不会有名人存在。
所得到的算法如下。我们问A是否认识B,根据A的回答排除掉他们其中的一个。假设排除的是A,然后我们在剩下的n-1个人中寻找(通过归纳法)一个名人。如果没有名人,那么算法就终止。否则我们核实A认识名人但是名人不认识A这种局面。下面给出一个非递归的算法实现。
名人算法(已知n×n的布尔矩阵)
begin
i:=1;
j:=2;
next:=2;
{在第一步中我们排除了除了一个候选人以外的所有人}
while next≤n do
next:=next+1;
if Know[i,j] then i:=next;
else j:=next;
{我们排除i和j中的一个}
if i=n+1 then candidate:=j else candidate:=i;
{现在我们核实该候选人是否确实是名人}
wrong:=false;k:=1;
Know[candidate,candidate]:=false;
{只是一个用来测试的虚拟变量}
while not wrong and k≤n do
if Know[candidate,k] then wrong:=true;
if not Know[k,candidate] then
if candidate ≠ k then wrong:=true;
k:=k+1;
if not wrong then print"candidate is a celebrity!"
end;
复杂度:这里最多只需要提3*(n-1)个问题。在第一步中提n-1个问题从而从候选人中排除掉n-1个人。为了确定那个候选人是否是名人最多只需要提2*(n-1)个问题。上面给出的解答表明可以在邻接矩阵中仅查找O(n)条记录就能确定一个名人,尽管从推理上认为问题的解法与n(n-1)项输入都密切相关。(这里也可能节省掉额外的log2(n)【取下限】次提问,只需要在验证过程中以及提问排除过程中注意避免重复即可)
总结:这个极佳的解法的核心思想在于用一种明智的方式把问题规模从n缩减到n-1。这个例子表明了有时候在更有效的进行问题规模的缩减上花一些努力(在该例子中提出一个疑问)是值得的。此外,逆向思维在本问题中显得很有用。与其去寻找一个名人我们不如尝试去排除非名人。这在数学证明时经常用到。一个人不需要直接去尝试解决问题。有时解决能够给原先问题带来解答的相关问题要简单一些。为了找到这些相关的问题,在开始时使用成品(数学证明中的得到的定理),然后逆向进行我们的工作看看实现这个成品需要什么东西,这往往是很有用的做法。
加强归纳假设
在用归纳法证明数学定理时,加强归纳假设被当做一种很重要的技巧使用。当尝试使用一个归纳证明时常常会遇到下面的情况。定理用P(n)表示,归纳假设可以用P(n-1)表示,要证明结论P(n-1)推导出P(n)。很多情况下可以加上另一个假设,称为Q,在这个假设下证明会变得更简单。也就是说,证明P(n-1)和Q推导出P(n)要更加容易。这种结合的假设看上去是正确的但是还不清楚如何去证明。技巧在于在归纳假设中加上Q(如果可能的话)。现在需要证明[P和Q](n-1)推导出[P和Q](n)。结合的定理[P和Q]和仅有P相比是一个更强的定理,但是有时候更强的定理却更容易去证明(Polya称这个原理为“发明家的悖论”)。这个过程可以反复,加上正确补充的假设,定理的证明变得简单。我们在表达式计算和线段包含问题中已经初步看到了这个原理。
在这部分中我们给出两个例子来展现加强归纳假设的运用。第一个问题很简单,但它阐明了使用这种技巧时最常见的错误,也就是忽视了加入额外假设这个事实从而忘记更新证明过程。换句话说,证明P(n-1)和Q推导出P(n)时没有注意到Q是被假设的。我们可以把这种转换类比与解决更小的问题,不过该问题和原先的问题已经不是完全一样的了。第二个例子更复杂一些。
在二叉树中计算平衡因子【Q6】
假设T是一个以r为根的二叉树。节点v的高度就是v和树中最底层的叶子之间的距离(应该是节点下方的树的最底层叶子)。节点v的平衡因子被定义为节点v的左孩子和它的右孩子(我们假设一个节点的孩子被标记为左和右)高度之差。图3给出了一棵树,在树中每个节点用h/b来标记,h是节点的高度,b是节点的平衡因子。
问题:给出一个拥有n个节点的树,计算它所有节点的平衡因子。
我们使用基本的归纳算法以及直截了当的归纳假设:
归纳假设:我们已经知道如何去计算小于n个节点的平衡因子。
最基本的n=1的例子很简单。给定一个拥有n>1节点的二叉树,我们移去根节点,然后用递归的方法解决剩下的子树。我们选择移去根节点因为一个节点的平衡因子仅仅依赖于节点下面的节点。我们现在已经知道出了根节点以外其他所有节点的平衡因子。但是根节点的平衡因子不是依赖于它的孩子的平衡因子而是依赖于它的孩子的高度。因此,一个简单的归纳法无法适用于这个例子。我们需要知道根节点孩子的高度。思想就在于在原先的问题中加上高度查询这个问题。
加强的归纳假设:我们已经知道如何计算小于n个节点的平衡因子以及它们的高度。
再一次的,基本问题很简单。现在考虑根节点时可以简单通过比较它的孩子的高度确定出它的平衡因子。此外,根节点的高度也能够被简单确定,也就是它两个孩子高度的最大值加上1。
这个算法的关键也就是解决一个简单拓展的问题。我们也计算高度而不只是计算平衡因子。拓展后的问题要更简单因为高度是很容易计算出来的。在很多情况下,解决一个更强的问题反而更简单。这对于归纳法说尤其正确。使用归纳法,我们仅需要把一个小问题拓展成一个更大的问题。如果解法更宽泛(因为问题被拓展了)那么归纳步骤可能要更简单因为我们有更多的东西可用。在该问题中常见的一个错误是忘记其中有两个不同的变量,而且这两个变量必须要单独计算。
最近对【Q7】
问题:给定平面上一个点的即可,找出最近两点之间的距离。
最直接使用归纳法的方法是移去一个点,解决n-1个点的问题,然后再考虑那个额外的点。然而,如果从对n-1个点的情况的求解中仅仅知道他们中间的最小距离,那么从额外点到其余n-1个点的距离都需要被计算出来。这样使得计算距离的总次数变成n-1+n-2+...+1=n(n-1)/2。(这其实是一个直接比较每两点的算法)我们想找到一个更快的解法。
一种分治算法
归纳假设如下所示:
归纳假设:我们已经知道在平面上如何去查找少于n个点中任意两点之间的最短距离。
既然我们假设我们能够解决少于n个点的子问题,我们可以把问题缩减为两个含有n/2个点的子问题。我们假设n是2的幂,这样我们总可以把一个集合分成数量两个相等的集合。(我们再后面再讨论这个假设)有很多方法可以把一个点集分成两个相等的部分。我们可以自由选择最好的方法。我们想要从规模较小问题的解法中获得尽可能多有用的信息,因此我们想要在考虑整个问题时尽可能多的保持有效。看起来这里把问题分解为两个不相关各含一半元素的部分是有道理的。当我们找到每个子集中最小的距离后,我们只需要关心那些靠近集合边界的点之间的距离。距离来说,对所有点进行排序最简单的方法是按照它们的x坐标进行排序,把平面用一条垂直线进行分割从而把集合一分为2(见图4)。(如果有一些点位于垂直线上我们任意把它们分配给两个集合中的一个,从而确保两个集合有相等的元素)我们选择这样划分的原因是使得合并解答时要做的工作尽可能少。如果这两个部分以某种方式交叉着,那样会使得对最近对点的检查变得更复杂。排序需要仅被执行一次。
给定一个集合P,我们按照上面的做法把它分解为P1和P2两个数量相等的子集。然后我们通过归纳法去查找每个子集中最近的两点距离。我们假设P1中最短的距离是d1,P2中是d2。不失一般性的,我们进一步假设d1≤d2。我们需要找到整个集合中最小的距离,也就是说我们需要去查找P1中的一个点到P2中的一个点是否有小于d1的距离。首先我们注意到只需要考虑以两部分中间的垂直线为中心宽度为2d1的带状范围内的点就足够了(见图4)。在该区域外的点中任意两点之间不可能拥有比d1更小的距离。通过上面的观察我们通常能够把很多点从考虑中排除,但是在最坏的情况下所有的点都可能仍位于这条带状区域中,对于它们我们无法使用直接的算法。
另一个不是那么明显的观察点是对于在带中的任意点p,在另一边有很少的点到p点的距离要比d1小。原因在于在带中一边的所有点至少间隔为d1.假设p是带中的一个点,它的y坐标为yp,那么只需要考虑在另一边有坐标yq且满足|yp-yq|<d1的点即可。在带的每一边最多有六个这样的点(见图5中最坏的情况)。结果是如果我们以点的y坐标针对所有带中的点进行排序并且按顺序扫描这些点,我们只需要检查每一个点和按序排列中它的常数个邻居即可(而不是全部n-1个点)。我们在这里省略这个事实的证明(见例子[15])。
最近对算法{首次尝试}
{p1,p2...pn:平面上的点}
begin
按照点的x坐标对点进行排序{该排序只在开始时运行一次}
把集合划分成两个相等的部分
递归计算每个部分中最小的距离
把d赋值为两个最小距离中的最小值
排除出分割线d距离范围外的点
按照y坐标对剩下的点进行排序
按照y顺序扫描这些点并计算每个点和它的五个邻居之间的距离{事实上,4个就够了}
if 这些距离中有小于d的 then
更新d值
end;
复杂度:按照x坐标进行排序需要花费O(nlogn)时间,但是这仅仅需要执行一次。然后我们解决规模为n/2的两个子问题。排除出带状区域以外的点可以在O(n)的时间内完成。接下来在最坏的情况下按照y坐标对剩下的点进行排序需要O(nlogn)步。最终,扫描带中的点并在序列中把它与常数个邻居进行比较需要O(n)步。总的来说,为了在n个点中查找最近对,我们在含有n/2个点的子集中找到两个最近对,然后花费O(nlogn)的时间去寻找两个子集之间的最近对(加上一次按照x坐标进行排序的时间O(nlogn))。带来的递推关系如下:
T(n)=2T(n/2)+O(nlogn), T(2)=1.
这个关系的解答是T(n)=O(n(logn)^2)。这比一个二次的算法要好,但是我们可以做的更好。现在我们来看看归纳法更巧妙的使用方法。
一个O(nlogn)的算法
这里的关键思想是加强归纳假设。由于要排序我们在合并步骤需要花费O(nlogn)的时间。尽管我们知道如何直接解决这个问题,但是它耗时太长。我们能够做到在解决排序问题的同时解决最近对问题么?换句话说,我们想加强归纳假设把排序作为最近对问题的一部分包含进来从而得到一个更好的解法。
归纳假设:给定平面上一个少于n个点的集合,我们知道如何去寻找它们之间的最近距离也知道如何按照y坐标排序后输出该集合。
我们已经知道如果知道如何排序那该怎样去寻找最小距离。因此,唯一需要做的事情是如果我们知道两个含有n/2的子集排序顺序那该如何对整个集合进行排序。换句话说,我们需要把两个有序的子集合并成一个有序的集合。合并可以在线性的时间内完成(见例【1】)。因此,递归关系变成如下:
T(n)=2T(n/2)+O(n), T(2)=1,
这也意味着T(n)=O(nlogn)。该算法和上一个算法唯一的区别是按照y坐标排序时不必每次都从头开始进行。当我们执行时使用加强的归纳假设来进行排序。下面给出的是改进后的算法。该算法是由Shamo和Hoey(见[15])提出来的。
最近对算法 {一个改进的版本}
{p1,p2...pn:平面上的点}
begin
按照x坐标对点进行排序
{该排序只有在开始时执行一次}
把该集合划分为两个相等的部分;
递归的执行下面的步骤
计算每个部分中最小的距离;
按照y坐标对每个部分的点进行排序;
把两个有序的列表合并成一个有序列表;
{请注意我们必须在排除点之前合并,我们需要为下一阶段的递归提供有序的全集}
把d赋值为两个最小距离中的最小者;
排除出分割线d距离范围外的点
按照y坐标对剩下的点进行排序
按照y顺序扫描这些点并计算每个点和它的五个邻居之间的距离{事实上,4个就够了}
if 这些距离中有小于d的 then
更新d值
end;
更强的归纳法
更强的归纳法(有时也被称为结构化归纳法)的思想在于不仅仅使用定理对于n-1(或者其他小于n的值)成立的假设,也使用定理对所有k(1≤k<n)成立的更强假设。把这种技巧转换到算法设计中需要维持一个含有所有小问题解法的数据结构。因此,该技巧通常引起更多的空间占用。我们给出一个使用这种技巧的例子。
背包问题【Q8】
背包问题是一个很重要的优化问题。它也有很多不同的变种,但这里我们只讨论其中的一种变种。
问题:这里有n个不同大小的物品。第i个物品有一个整型的大小ki。问题是找到一个物品的子集使得该集合的大小总和正好为K,或者我们确定不存在这样的子集。换句话说,给我们一个大小为K的背包我们想把它装满物品。我们把这个问题表示为P(n,K),第一个参数表示物品的数目,第二个参数表示背包的大小。我们假设大小是固定的。我们用P(j,k)(j≤n且k≤K)表示有j个物品和大小为k的背包问题。为了简化,我们仅关心问题的结论,也就是决定是否存在这样的一个解答。在后面我们给出如何去寻找到一个解答。
我们首先从最直接的归纳法开始。
归纳假设:我们知道如何去解决P(n-1,K)的问题。
基本情况很简单,如果仅有一个大小为K的物品有办法解决。如果有解决P(n-1,K)的办法,也就是说如果有能够把n-1个物品放入背包的方法我们就算完成了。我们只需要简单的不使用第n个物品即可。然而,假设没有对P(n-1,K)的解决方法,我们能够使用这个否定的结论么?答案是可以的,这也意味着第n个物品必须被包含进去。在这种情况下,剩下的物品必须装入一个更小的容量为K-kn的背包。我们把问题简化为了两个更小的问题:如果P(n,K)有解那么P(n-1,K)或者P(n-1,K-kn)两者中间必须有一个有解。为了完成这个算法我们不仅需要求解容量为K的背包问题也需要求解对最大容量为K的所有背包的问题。(这里存在把背包容量限制在一些减去ki后的大小之中,但是也可能不存在这样的限制条件)
更强的归纳假设:我们已经知道对所有的0≤k≤K如何去求解P(n-1,k)。
上面的简化并不依赖于一个特定的k值,它对所有的k值都是有效的。我们可以使用这个归纳假设解决所有的0≤k≤K的P(n,k)问题。我们把P(n,k)简化为P(n-1,k)和P(n-1,k-kn)这两个问题。(如果k-kn<0我们就忽略第二个问题)这两个问题都可以用归纳法求解。这是一个有效的简化我们也能找到一个算法,但是该算法效率不高。我们得到的仅是规模稍小一点的两个子问题。因而在对规模的每步简化中子问题的个数也是翻倍增长。由于对规模的简化可能不是那么确切,算法可能是按照指数级增长。(根据ki的值来确定)
幸运的是,在很多情况下对这种问题提高运行效率是可行的。主要的观察是可能的问题的总数不是很多。事实上,我们引入P(n,k)这个记号来表示该问题。对第一个参数存在n种可能性,对于第二个参数存在K种可能性。总的来说,这里只有n*K种不同可能性的问题。在每次简化后对问题数目翻倍会带来指数运行时间,但是如果这里只有n*K个不同的问题我们肯定对同一个问题求解了多次。如果我们记下了所有的解答我们就不需要对同一个问题求解两次。这实际上是加强归纳假设和使用更强的归纳法(使用对所有已知的更小规模问题而不仅仅对n-1问题解答的假设)的结合。下面来看看我们如何实现该方法。
我们把所有已知的结果存放在一个n×K的矩阵中。矩阵中第ij个位置包含着P(i,j)的解答信息。使用上面更强的归纳假设后,问题简化为基本上计算矩阵的第n行值即可。第n行的每个条目是通过其上的两个条目计算得到的。如果我们对找到实际的集合感兴趣的话,我们可以在每个位置加上一个标记字段,该字段可以表示在那步操作中对应的物品是否被选中。标记字段可以从第(n,K)个位置倒推,集合也可以被复原。这个算法列在下一列顶部。
背包算法{k1,k2...kn,K:整型};
{如果对于前i个元素和容量为j的背包有解那么P[i,j].exist=true,如果第i个元素包含在解中那么P[i,j].belong=true}
begin
P[0,00].exist:=true;
for j:=1 to n do
P[0,j].exist:=false;
for i:=1 to n do
for j:=0 to K do
P[i,j].exist:=false;{默认值}
if P[i-1,j].exist then
P[i,j].exist:=true;
P[i,j].belong:=false;
else if j-ki≥0 then
P[i-1,j-ki].exist then
P[i,j].exist:=true;
P[i,j].belong:=true;
end;
复杂度:矩阵中有n×K个条目,从两个不同条目计算出一个条目需要常数时间。因此,总的运行时间是O(nK)。如果物品的大小不是特别大,那么K就不可能太大并且nK比n的指数表示要小很多。(如果K非常大或者是一个实数,那么这种方法就不高效)如果我们只关心确定是否存在一个解答那么答案就在P[n,K]中。如果我们对找到实际的集合感兴趣,我们可以从第(n,K)个条目倒推,例如使用背包程序中的belong标志位,在O(n)时间内复原这个集合。
结论:我们刚才使用的是一种常见技术方法的一个具体实例,该方法被称为动态规划,它的本质是建立一个巨大的表,在表中填入已知的之前的解答。该表是用迭代的方法进行构造的。矩阵中的每个条目都是从其上或左侧的其他条目计算得到的。主要的问题是用一种最有效的方法进行表的构造。动态规划在问题仅能被简化为几个不是足够小的子问题时是有效的。
最大的反例
在证明数学定理中一种有特色并且强大的技巧是假设定理的反面成立然后找到一个矛盾。通常这是用一种完成非建设性的方式实现的,这对于我们的类比不是很有用。虽然有时通过一种和归纳法类似的方法能够找到一个矛盾。假设我们想证明一个确定的变量P(在一个给定的问题中)能够取到一个确定的值n。第一步我们给出P能够取到一个小值(基本情况)。第二步我们假设P无法取到n,我们可以考虑它能取到的最大值k<n。最后以及最主要的步骤是给出一个矛盾,通常针对最大化的假设。我们给出一个算法设计的例子,在该例子中这种技术非常有用。
稠密图中的最优匹配【Q9】
在无向图G=(V,E)中一个匹配也就是一个没有公共顶点的边的集合。(一条边对应于两个点,一个点不可能对应于多余一个顶点)最大匹配是一个无法拓展的问题,意味着所有其他的边都至少与一个匹配的顶点相连。一个最大匹配也就是一个最大集。(一个最大匹配总是最大的,但是反过来说却未必正确)在图中一个拥有n条边和2n个点的匹配被称为最优匹配。(显然也是最大的)在这个例子中我们考虑一种很有限的情况。我们假设图中有2n个点,所有顶点的度都至少为n。可知在这些条件下总存在一个最优匹配。我们首先给出这个事实的证明,然后展示如何去修改这个证明从而得到一个查找最优匹配的算法。
证明采用的是最大的反例。考虑一个图G=(V,E),其中|V|=2n每个顶点的度至少为n。如果n=1那么这个图仅仅有一条边连接两个顶点,这就是一个最优匹配。假设n>1时不存在这样一个最优匹配。考虑到最大匹配M属于E。由假设知|M|<n,同时由于任意一条边自己就是一个匹配显然有|M|≥1。既然M不是完全的(不包括所有的点),那么就存在至少两个不相邻点v1和v2不被包含在M中(即它们不对应M中的一条边)。这两个点至少有2n个不同的边从它们射出。所有这些边通向那些包含在M中的顶点,否则这样的边就不可能被加入到M中。由于M中边的数目小于n而且从v1到v2有2n条边与之相连,M中至少有一条边,假定为(u1,u2),与从v1到v2的三条边相连。为了不失一般性,我们假设这三条边是(u1,v1),(u1,v2)和(u2,v1)(见图6)。很容易可以看到通过从M中移除(u1,u2)加上边(u1,v2)和(u2,v1)我们能够得到一个更大的匹配,这与之前最大的假设相矛盾。
第一眼看上去这个证明好像无法产生一个算法,因为证明是从一个最大匹配开始的。一旦我们知道如何去寻找这样一个匹配我们就能够解决这个问题。然而,使用反证法适用于任何最大化的匹配,这里展示的只是用于最大匹配而已。查找一个最大化的匹配要比查找一个最大匹配简单。我们只需要简单的添加不相连的边(即那些没有公共顶点的边)直到不存在这样的边的可能。然后我们使用上面描述的步骤把该匹配转换为一个更大的匹配。通过上面的证明我们可以不断反复执行直到找到一个最优匹配。
其他证明技巧
在这篇论文中我们关注于基于归纳法的证明技巧。这里有很多其他的技巧和更多的类比,一些事很明显的,一些则不那么明显。许多数学定理的证明是使用一系列的前提得到的,这直接对应于在标准设计和结构化编程的思想。证明中使用反证法在算法设计中也有类似的地方。研究那些使用“类似的论据”证明的类比是很有趣的一件事。
我们这里简要列出四个证明技巧(其中的三个是基于归纳法的)以及它们的类比。更多的例子和类比可以在参考文献[12]中找到。
缩减法
在证明定理和设计算法时,在问题之间使用缩减是一种很强大的技巧。如果问题A被指明是问题B的特例,那么解决B的算法可以被当成一个黑盒用来解决A。这个技巧对于解决下界和对问题进行分类也很有效(例如NP-完全问题)。如果已知问题A很难,那么问题B也至少一样难。
双倍归纳法
这是一种使用归纳法针对一次多余一个变量的方法。它可用于在归纳法最佳序列不明确的情况,同时在针对几个变量依据一个特定的步骤在其中进行选择时,该方法也很容易使用到。例如,如果问题包含n个物品和一个k维空间时,我们可能想在算法执行时减少物品的数量或者物品尺寸的数量【见例4】。
逆向归纳法
这个技巧在数学中不经常使用,但是在计算机科学领域却经常使用。普通的归纳法通过从一个基本情况(n=1)开始然后不断推广从而覆盖所有的自然数。假设我们想要逆推。我们假设它对n成立想要证明它对n-1也成立。我们称这种类型的证明为逆向归纳。但是,什么是最基本的情况呢?我们能够从一个n=M(M是一个非常大的数)的基本情况开始。如果我们证明它对n=M成立,然后我们就可以使用逆向归纳法从而证明对所有小于等于M的数也成立。尽管通常这样是不符合要求的,但在一些情况下却是满足要求的。例如,假设我们把双倍归纳法用于两个变量(即图中的顶点数和边数)。我们可以对一个变量应用普通的归纳法,如果第二个变量能够在第一个变量的范围内有界,那就对第二个变量使用逆向归纳法。例如,在一个有n个顶点的有向图中最多由n*(n-1)条边。对于n我们可以使用普通的归纳法并假设所有的边都是存在的(也就是说我们仅仅考虑完全图),然后对边的数目使用逆向归纳法。
一种更常见的使用逆向归纳法的做法如下。仅对n中一个值的基本情况证明能限制于对那些比该值更小的值的证明(补充:证明了一个值比它小的值也就可以证明了)。假设我们能够直接对一个n取值无限的定理加以证明。例如无限集中包含所有2的幂。那么我们就可以使用逆向归纳法覆盖n的所有值。这是一种有效证明技巧,因为对于每个n取值在基本集中都存在一个比其大的值(由于集合式无限的)。
使用这种技巧的一个非常好的例子是在算术平均不等式和几何平均不等式(柯西不等式)中用到的优雅的证明方法(例子见[3])。当证明数学定理时,从n到n-1往往不比从n-1到n简单,同时证明一个无限集的基本情况要比一个简单集的基本情况困难的多。在设计算法时,与之相反的是,从n到n-1总是很容易,也就是针对更小的输入规模的问题求解。例如,我们可以引入那些不影响输出的假数据。结论是,在很多情况下不根据输入量的各种大小而是根据从无限集中取得的大小来设计算法往往是充分的。最常见的使用这种原理的做法是在设计算法时仅考虑是2的幂的n的大小输入。这使得设计更简洁也排除了很多杂乱的细节。很显然这些细节最终也需要被解决,但是它们往往很容易处理。例如在最近对问题中,我们使用n是2的幂的假设。
明智的选择归纳法的基本情况
很多递归算法(例如快排)对于小问题而言效果并不是很好。当问题被简化为一个小问题时,可以使用另一种简单的算法(例如插入排序)。从归纳法来看,这中做法符合选择一种n=k(k依据问题来定)基本情况然后使用一种直接的技巧来解决这种基本情况的思想。有些例子中这种做法甚至能够改善算法的渐近运行时间[12]。
结论
我们展示了一种解释和使用组合算法设计的方法。使用这种普通的方法的好处是两方面的。首先,它给算法设计者们提供了一个更加统一的“进攻路线”(处理问题方法)。给定一个待解决的问题,一个人可以通过使用文章中描述和阐明的技巧尝试找到一个解法。由于这些技巧有一些相似的地方(也就是数学归纳法),对它们全部进行尝试的过程能够被更好的理解也更容易进行。第二点,它提供了一种解释现有算法的的更统一的方法,使得学生能更多的参与创造过程。同时,对于算法正确性的证明在描述中占更重要的部分。我们相信这种方法能够包含在对组合算法进行教学之中。
感谢:感谢Rachel Manber带来很多关于归纳法和算法极富启发式的对话。感谢Greg Andrews, Darrah Chavey, Irv Elshoff,Susan Horwitz, Sanjay Manchanda, Kirk Pruhs, and Sun Wu在手稿的改进方面提供了很多有益的意见。

相关文章推荐
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [7/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [6/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [10/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [5/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [4/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [11/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [13-14/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [8/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [1/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [9/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [12/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [2/14]
- USING INDUCTION TO DESIGN 使用归纳法设计算法 [3/14]
- 状态模式在领域驱动设计中的使用(Using the State pattern in a Domain Driven Design)
- introdution_to_design_pattern_了解设计模式-翻译
- (译)Getting Started——1.3.2 Using Design Patterns(使用设计模式)
- 【翻译】使用Ext JS设计响应式应用程序
- 【Python错误】windows下使用pip/easy_install提示Fatal error in launcher: Unable to create process using...
- Sencha Touch 2 官方文档翻译之 Using Models(使用数据模型)