Lucene索引阶段设置Document Boost和Field Boost 实现合理打分
2011-07-17 14:07
417 查看
在索引阶段设置Document Boost和Field Boost,存储在(.nrm)文件中。
如果希望某些文档和某些域比其他的域更重要,如果此文档和此域包含所要查询的词则应该得分较高,则可以在索引阶段设定文档的boost和域的boost值。这些值是在索引阶段就写入索引文件的,存储在标准化因子(.nrm)文件中,一旦设定,除非删除此文档,否则无法改变。如果不进行设定,则Document Boost和Field Boost默认为1。Document Boost及FieldBoost的设定方式如下:| Document doc = new Document();Field f = new Field("contents", "hello world", Field.Store.NO, Field.Index.ANALYZED);f.setBoost(100);doc.add(f);doc.setBoost(100); |
| score(q,d) = coord(q,d) · queryNorm(q) · ∑( tf(t in d) · idf(t)2 · t.getBoost() · norm(t,d)) t in q |
norm(t,d) = doc.getBoost()· lengthNorm(field)· ∏ f.getBoost()field f in d named as t |
Field boost:此域越大,说明此域越重要。
lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。
其中第三个参数可以在自己的Similarity中影响打分,下面会论述。当然,也可以在添加Field的时候,设置Field.Index.ANALYZED_NO_NORMS或Field.Index.NOT_ANALYZED_NO_NORMS,完全不用norm,来节约空间。根据Lucene的注释,No norms means that index-time field and document boosting and field length normalization are disabled. The benefit is less memory usage as norms take up one byte of RAM per indexed field for every document in the index, during searching. Note that once you index a given field with norms enabled, disabling norms will have no effect. 没有norms意味着索引阶段禁用了文档boost和域的boost及长度标准化。好处在于节省内存,不用在搜索阶段为索引中的每篇文档的每个域都占用一个字节来保存norms信息了。但是对norms信息的禁用是必须全部域都禁用的,一旦有一个域不禁用,则其他禁用的域也会存放默认的norms值。因为为了加快norms的搜索速度,Lucene是根据文档号乘以每篇文档的norms信息所占用的大小来计算偏移量的,中间少一篇文档,偏移量将无法计算。也即norms信息要么都保存,要么都不保存。下面几个试验可以验证norms信息的作用:试验一:Document Boost的作用
| public void testNormsDocBoost() throws Exception { File indexDir = new File("testNormsDocBoost"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello hello", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); doc1.setBoost(100); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); Document doc3 = new Document(); Field f3 = new Field("contents", "common common common", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc3.add(f3); writer.addDocument(doc3); writer.close(); IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); TopDocs docs = searcher.search(new TermQuery(new Term("contents", "common")), 10); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } } |
| docid : 2 score : 1.2337708 docid : 1 score : 1.0073696 docid : 0 score : 0.71231794 |
| docid : 0 score : 39.889805 docid : 2 score : 0.6168854 docid : 1 score : 0.5036848 |
| public void testNormsFieldBoost() throws Exception { File indexDir = new File("testNormsFieldBoost"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("title", "common hello hello", Field.Store.NO, Field.Index.ANALYZED); f1.setBoost(100); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); writer.close(); IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "contents", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse("title:common contents:common"); TopDocs docs = searcher.search(query, 10); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } } |
| docid : 1 score : 0.49999997 docid : 0 score : 0.35355338 |
| docid : 0 score : 19.79899 docid : 1 score : 0.49999997 |
| public void testNormsLength() throws Exception { File indexDir = new File("testNormsLength"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello hello hello hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); writer.close(); IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "contents", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse("title:common contents:common"); TopDocs docs = searcher.search(query, 10); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } } |
| docid : 1 score : 0.13928263 docid : 0 score : 0.09848769 |
| docid : 0 score : 0.09848769 docid : 1 score : 0.052230984 |
| public void testOmitNorms() throws Exception { File indexDir = new File("testOmitNorms"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("title", "common hello hello", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); for (int i = 0; i < 10000; i++) { Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello hello hello hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); } writer.close(); } |
当我们把第一篇文档设为Field.Index.ANALYZED,而其他10000篇文档都设为Field.Index.ANALYZED_NO_NORMS的时候,发现.nrm文件又10K,也即所有的文档都存储了norms信息,而非只有第一篇文档。
在搜索语句中,设置Query Boost.
在搜索中,我们可以指定,某些词对我们来说更重要,我们可以设置这个词的boost:common^4 hello |
| title:common^4 content:common |
| public void testQueryBoost() throws Exception { File indexDir = new File("TestQueryBoost"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); Document doc1 = new Document(); Field f1 = new Field("contents", "common1 hello hello", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common2 common2 hello", Field.Store.NO, Field.Index.ANALYZED); doc2.add(f2); writer.addDocument(doc2); writer.close(); IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "contents", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse("common1 common2"); TopDocs docs = searcher.search(query, 10); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } } |
| docid : 1 score : 0.24999999 docid : 0 score : 0.17677669 |
| docid : 0 score : 0.2499875 docid : 1 score : 0.0035353568 |
| score(q,d) = coord(q,d) · queryNorm(q) · ∑( tf(t in d) · idf(t)2 · t.getBoost() · norm(t,d) ) t in q |
继承并实现自己的Similarity
Similariy是计算Lucene打分的最主要的类,实现其中的很多借口可以干预打分的过程。(1) float computeNorm(String field, FieldInvertState state)(2) float lengthNorm(String fieldName, int numTokens)(3) float queryNorm(float sumOfSquaredWeights)(4) float tf(float freq)(5) float idf(int docFreq, int numDocs)(6) float coord(int overlap, int maxOverlap)(7) float scorePayload(int docId, String fieldName, int start, int end, byte [] payload, int offset, int length)它们分别影响Lucene打分计算的如下部分:| score(q,d) = (6)coord(q,d) · (3)queryNorm(q) · ∑( (4)tf(t in d) · (5)idf(t)2 · t.getBoost() · (1)norm(t,d) )t in q |
norm(t,d) = doc.getBoost()· (2) lengthNorm(field)· ∏ f.getBoost() field f in d named as t |
| public void testMultiIndex() throws Exception{ MultiIndexSimilarity sim = new MultiIndexSimilarity(); File indexDir01 = new File("TestMultiIndex/TestMultiIndex01"); File indexDir02 = new File("TestMultiIndex/TestMultiIndex02"); IndexReader reader01 = IndexReader.open(FSDirectory.open(indexDir01)); IndexReader reader02 = IndexReader.open(FSDirectory.open(indexDir02)); IndexSearcher searcher01 = new IndexSearcher(reader01); searcher01.setSimilarity(sim); IndexSearcher searcher02 = new IndexSearcher(reader02); searcher02.setSimilarity(sim); MultiSearcher multiseacher = new MultiSearcher(searcher01, searcher02); multiseacher.setSimilarity(sim); QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "contents", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse("common"); TopDocs docs = searcher01.search(query, 10); System.out.println("----------------------------------------------"); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } System.out.println("----------------------------------------------"); docs = searcher02.search(query, 10); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } System.out.println("----------------------------------------------"); docs = multiseacher.search(query, 20); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } |
| 结果为:------------------------------- docid : 0 score : 0.49317428 docid : 1 score : 0.49317428 docid : 2 score : 0.49317428 docid : 3 score : 0.49317428 docid : 4 score : 0.49317428 docid : 5 score : 0.49317428 docid : 6 score : 0.49317428 docid : 7 score : 0.49317428 ------------------------------- docid : 0 score : 0.45709616 docid : 1 score : 0.45709616 docid : 2 score : 0.45709616 docid : 3 score : 0.45709616 docid : 4 score : 0.45709616 ------------------------------- docid : 0 score : 0.5175894 docid : 1 score : 0.5175894 docid : 2 score : 0.5175894 docid : 3 score : 0.5175894 docid : 4 score : 0.5175894 docid : 5 score : 0.5175894 docid : 6 score : 0.5175894 docid : 7 score : 0.5175894 docid : 8 score : 0.5175894 docid : 9 score : 0.5175894 docid : 10 score : 0.5175894 docid : 11 score : 0.5175894 docid : 12 score : 0.5175894 |
| class MultiIndexSimilarity extends Similarity { @Override public float idf(int docFreq, int numDocs) { return 1.0f; } |
| ----------------------------- docid : 0 score : 0.559017 docid : 1 score : 0.559017 docid : 2 score : 0.559017 docid : 3 score : 0.559017 docid : 4 score : 0.559017 docid : 5 score : 0.559017 docid : 6 score : 0.559017 docid : 7 score : 0.559017 ----------------------------- docid : 0 score : 0.559017 docid : 1 score : 0.559017 docid : 2 score : 0.559017 docid : 3 score : 0.559017 docid : 4 score : 0.559017 ----------------------------- docid : 0 score : 0.559017 docid : 1 score : 0.559017 docid : 2 score : 0.559017 docid : 3 score : 0.559017 docid : 4 score : 0.559017 docid : 5 score : 0.559017 docid : 6 score : 0.559017 docid : 7 score : 0.559017 docid : 8 score : 0.559017 docid : 9 score : 0.559017 docid : 10 score : 0.559017 docid : 11 score : 0.559017 docid : 12 score : 0.559017 |
| public void TestCoord() throws Exception { MySimilarity sim = new MySimilarity(); File indexDir = new File("TestCoord"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello world", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common common", Field.Store.NO, Field.Index.ANALYZED); doc2.add(f2); writer.addDocument(doc2); for(int i = 0; i < 10; i++){ Document doc3 = new Document(); Field f3 = new Field("contents", "world", Field.Store.NO, Field.Index.ANALYZED); doc3.add(f3); writer.addDocument(doc3); } writer.close(); IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); searcher.setSimilarity(sim); QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "contents", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse("common world"); TopDocs docs = searcher.search(query, 2); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } } |
| class MySimilarity extends Similarity { @Override public float coord(int overlap, int maxOverlap) { return 1; }} |
| docid : 1 score : 1.9059997 docid : 0 score : 1.2936771 |
| class MySimilarity extends Similarity { @Override public float coord(int overlap, int maxOverlap) { return overlap / (float)maxOverlap; }} |
| docid : 0 score : 1.2936771 docid : 1 score : 0.95299983 |
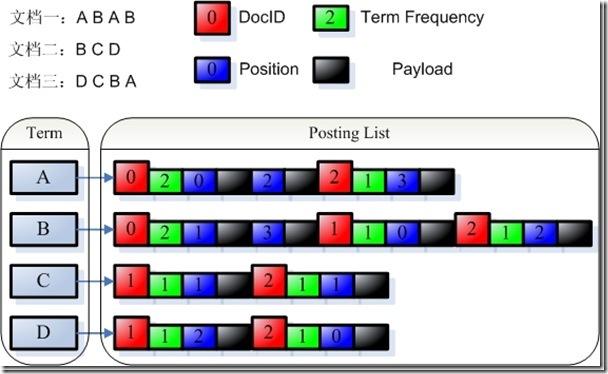
由payload的定义,我们可以看出,payload可以存储一些不但与文档相关,而且与查询词也相关的信息。比如某篇文档的某个词有特殊性,则可以在这个词的这个文档的position信息后存储payload信息,使得当搜索这个词的时候,这篇文档获得较高的分数。要利用payload来影响查询需要做到以下几点,下面举例用<b></b>标记的词在payload中存储1,否则存储0:首先要实现自己的Analyzer从而在Token中放入payload信息:
| class BoldAnalyzer extends Analyzer { @Override public TokenStream tokenStream(String fieldName, Reader reader) { TokenStream result = new WhitespaceTokenizer(reader); result = new BoldFilter(result); return result; }}class BoldFilter extends TokenFilter { public static int IS_NOT_BOLD = 0; public static int IS_BOLD = 1; private TermAttribute termAtt; private PayloadAttribute payloadAtt; protected BoldFilter(TokenStream input) { super(input); termAtt = addAttribute(TermAttribute.class); payloadAtt = addAttribute(PayloadAttribute.class); } @Override public boolean incrementToken() throws IOException { if (input.incrementToken()) { final char[] buffer = termAtt.termBuffer(); final int length = termAtt.termLength(); String tokenstring = new String(buffer, 0, length); if (tokenstring.startsWith("<b>") && tokenstring.endsWith("</b>")) { tokenstring = tokenstring.replace("<b>", ""); tokenstring = tokenstring.replace("</b>", ""); termAtt.setTermBuffer(tokenstring); payloadAtt.setPayload(new Payload(int2bytes(IS_BOLD))); } else { payloadAtt.setPayload(new Payload(int2bytes(IS_NOT_BOLD))); } return true; } else return false; } public static int bytes2int(byte[] b) { int mask = 0xff; int temp = 0; int res = 0; for (int i = 0; i < 4; i++) { res <<= 8; temp = b[i] & mask; res |= temp; } return res; } public static byte[] int2bytes(int num) { byte[] b = new byte[4]; for (int i = 0; i < 4; i++) { b[i] = (byte) (num >>> (24 - i * 8)); } return b; }} |
| class PayloadSimilarity extends DefaultSimilarity { @Override public float scorePayload(int docId, String fieldName, int start, int end, byte[] payload, int offset, int length) { int isbold = BoldFilter.bytes2int(payload); if(isbold == BoldFilter.IS_BOLD){ System.out.println("It is a bold char."); } else { System.out.println("It is not a bold char."); } return 1; } } |
| public void testPayloadScore() throws Exception { PayloadSimilarity sim = new PayloadSimilarity(); File indexDir = new File("TestPayloadScore"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new BoldAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello world", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common <b>hello</b> world", Field.Store.NO, Field.Index.ANALYZED); doc2.add(f2); writer.addDocument(doc2); writer.close(); IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); searcher.setSimilarity(sim); PayloadTermQuery query = new PayloadTermQuery(new Term("contents", "hello"), new MaxPayloadFunction()); TopDocs docs = searcher.search(query, 10); for (ScoreDoc doc : docs.scoreDocs) { System.out.println("docid : " + doc.doc + " score : " + doc.score); } } |
| It is not a bold char. It is a bold char. docid : 0 score : 0.2101998 docid : 1 score : 0.2101998 |
| class PayloadSimilarity extends DefaultSimilarity { @Override public float scorePayload(int docId, String fieldName, int start, int end, byte[] payload, int offset, int length) { int isbold = BoldFilter.bytes2int(payload); if(isbold == BoldFilter.IS_BOLD){ System.out.println("It is a bold char."); return 10; } else { System.out.println("It is not a bold char."); return 1; } } } |
| It is not a bold char. It is a bold char. docid : 1 score : 2.101998 docid : 0 score : 0.2101998 |
继承并实现自己的collector
以上各种方法,已经把Lucene score计算公式的所有变量都涉及了,如果这还不能满足您的要求,还可以继承实现自己的collector。在Lucene 2.4中,HitCollector有个函数public abstract void collect(int doc, float score),用来收集搜索的结果。其中TopDocCollector的实现如下:| public void collect(int doc, float score) { if (score > 0.0f) { totalHits++; if (reusableSD == null) { reusableSD = new ScoreDoc(doc, score); } else if (score >= reusableSD.score) { reusableSD.doc = doc; reusableSD.score = score; } else { return; } reusableSD = (ScoreDoc) hq.insertWithOverflow(reusableSD); } } |
| public static long milisecondsOneDay = 24L * 3600L * 1000L;public static long millisecondsOneWeek = 7L * 24L * 3600L * 1000L;public static long millisecondsOneMonth = 30L * 24L * 3600L * 1000L;public void collect(int doc, float score) { if (score > 0.0f) { long time = getTimeByDocId(doc); if(time < milisecondsOneDay) { score = score * 1.0; } else if (time < millisecondsOneWeek){ score = score * 0.8; } else if (time < millisecondsOneMonth) { score = score * 0.3; } else { score = score * 0.1; } totalHits++; if (reusableSD == null) { reusableSD = new ScoreDoc(doc, score); } else if (score >= reusableSD.score) { reusableSD.doc = doc; reusableSD.score = score; } else { return; } reusableSD = (ScoreDoc) hq.insertWithOverflow(reusableSD); } } |
| public void collect(int doc) throws IOException { float score = scorer.score(); totalHits++; if (score <= pqTop.score) { return; } pqTop.doc = doc + docBase; pqTop.score = score; pqTop = pq.updateTop(); } |

相关文章推荐
- Lucene索引阶段设置Document Boost和Field Boost 实现合理打分
- Lucene索引阶段设置Document Boost和Field Boost 实现合理打分
- Lucene 评分(score)机制--Document Boost和Field Boost
- Document Boost和Field Boost (Lucene相关)
- 搜索引擎lucene实现--二半吊子的论调之Document和Field
- 使用Lucene.Net管理索引实现搜索
- Lucene Document getBoost(float) 和 setBoost(float)
- Lucene深入学习(5)Lucene的Document与Field
- js设置document.domain实现跨域的注意点分析
- 一个lucene索引初始化,添加,删除,修改功能的实现
- lucene.net 2.9.2 实现索引生成,修改,查询,删除功
- c#使用Lucene.net创建索引,实现搜索的代码示例
- lucene与sql server数据库实现索引的简单实例(vs.net2008)
- Lucene3.4实现从mysql数据库中导出数据,建立索引
- Solr之查询时设置字段的boost值,改变默认打分排序
- Lucene.net 实现近实时搜索(NRT)和增量索引
- Beta笔记——搜索引擎的设计与实现(1):使用Lucene.Net建立索引与中文分词
- lucene全文搜索之四:创建索引搜索器、6种文档搜索器实现以及搜索结果分析(结合IKAnalyzer分词器的搜索器)基于lucene5.5.3
- lucene中Field.Index,Field.Store的一些设置
- Lucene 深入学习(4)Lucene索引实现方式