实例演示C++对象构造
2011-04-07 22:34
288 查看
5.数据库的设计
5.1分区视图
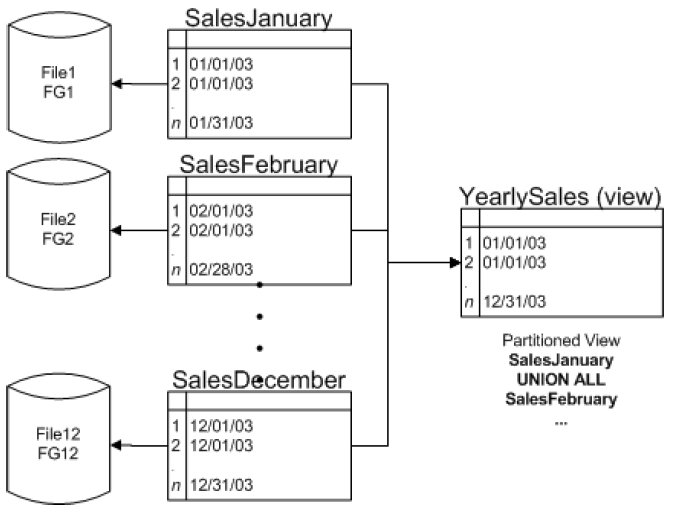
分区视图在一台或多台服务器间水平连接一组成员表中的分区数据,使数据看起来就像来自一个表。Microsoft SQL Server 2005 可以区分本地分区视图和分布式分区视图。在本地分区视图中,所有参与表和视图都位于同一个 SQL Server 实例上。在分布式分区视图中,至少有一个参与表位于不同的(远程)服务器上。另外,SQL Server 2005 还可以区分可更新分区视图和作为基础表只读副本的视图。请参见下图中的 YearlySales 视图。您可以定义十二个单独的表(如 SalesJanuary2003、SalesFebruary2003 等),然后定义每个季度的视图以及全年的视图 YearlySales,而不是将所有销售数据放到一个大型表中。
5.2分区表
a.分区表的诠释
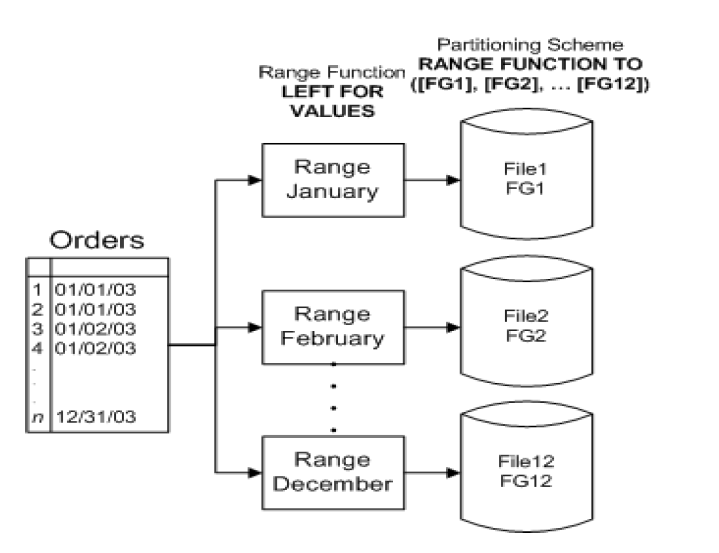
尽管 SQL Server 7.0 和 SQL Server 2000 中的改进大大改善了使用分区视图时的性能,但是并没有简化分区数据集的管理、设计或开发。使用分区视图时,必须单独创建和管理每个基础表(在其中定义视图的表)。尽管简化了应用程序设计并为用户带来了好处(用户不再需要知道直接访问哪个基础表),但是由于要管理的表太多,而且必须为每个表管理数据完整性约束,管理工作变得更复杂。因为管理方面的问题,通常只有在需要存档或加载数据时才使用分区视图来分离表。当数据被移动到只读表或从只读表中删除后,操作的代价变得十分高昂,不仅花费时间、占据日志空间,通常还会导致系统阻塞。通过 SQL Server 2005 中的分区表,可以对表进行设计(使用函数和架构),从而将具有相同分区键的所有行都直接放置到(且总是转到)特定的位置。函数用于定义分区边界以及放置第一个值的分区。在使用 LEFT 分区函数时,第一个值将作为第一个分区中的上边界。在使用 RIGHT 分区函数时,第一个值将作为第二个分区的下边界(本文后面将更详细地介绍分区函数)。定义函数后即可创建分区架构,以定义分区到其数据库位置的物理映射(根据分区函数)。当多个表使用同一个函数(但不一定使用同一个架构)时,将按类似的方式对具有相同分区键的行进行分组。此概念称为对齐。通过将来自多个表但具有相同分区键的行对齐到相同或不同的物理磁盘上,SQL Server 可以(如果优化程序做出此选择)只处理每个表中必要的数据组。
分区简要图如下:
[/b]
b.分区表的分类
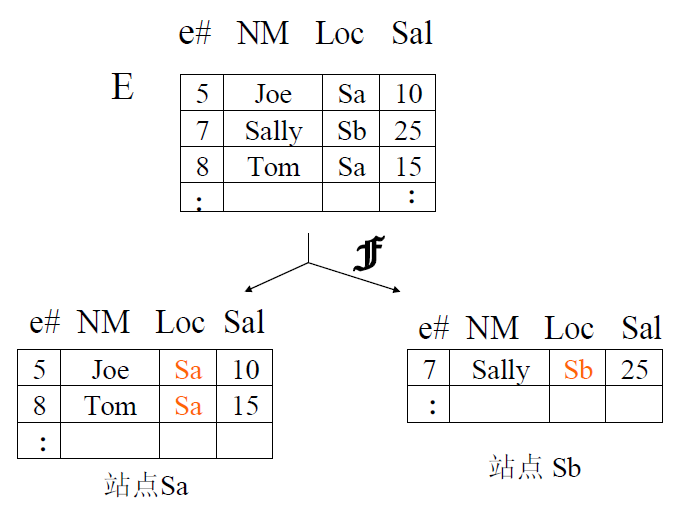
水平分区 : [/b]就是表结构一样.不同的记录根据分区,根据分区把不同的数据存储在硬盘不同位置(可以是不同硬盘),通过不同文件分组管理.[/b]图如下:[/b]
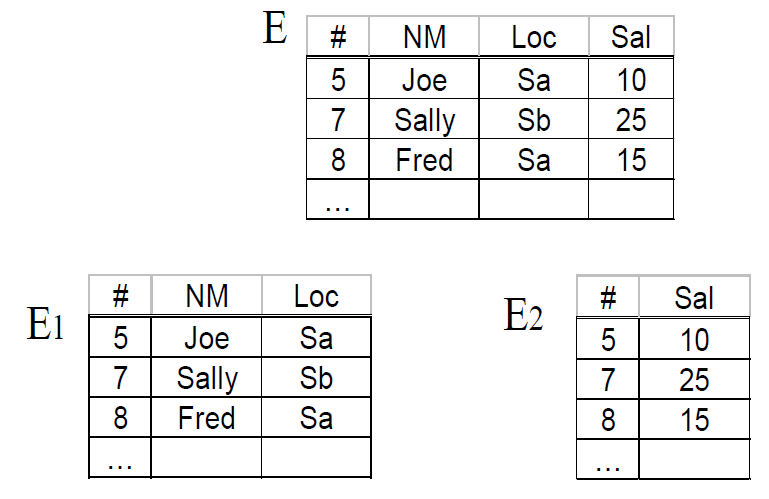
垂直分区 :[/b]通过”投影”操作把一个全局关系的属性分层若干组,垂直分区的基本目标是将使用频繁的属性聚集在一起.
[/b]图如下:[/b]
5.3分区表实现的步骤
a.创建文件组
建立分区表先要创建文件组,而创建多个文件组主要是为了获得好的 I/O 平衡。一般情况下,文件组数最好与分区数相同,并且这些文件组通常位于不同的磁盘上。每个文件组可以由一个或多个文件构成,而每个分区必须映射到一个文件 组。一个文件组可以由多个分区使用。为了更好地管理数据(例如,为了获得更精确的备份控制),对分区表应进行设计,以便只有相关数据或逻辑分组的数据位于 同一个文件组中。使用 ALTER DATABASE,添加逻辑文件组名:ALTER DATABASE [DeanDB] ADD FILEGROUP [FG1]
DeanDB为数据库名称,FG1文件组名。创建文件组后,再使用 ALTER DATABASE 将文件添加到该文件组中:
ALTER DATABASE [DeanDB] ADD FILE ( NAME = N'FG1', FILENAME = N'C:\DeanDataFG1.ndf' , SIZE = 3072KB , FILEGROWTH = 1024KB ) TO FILEGROUP [FG1]
类似的建立四个文件和文件组,并把每一个存储数据的文件放在不同的磁盘驱动器里。
b.创建分区函数
创建分区表必须先确定分区的功能机制,表进行分区的标准是通过分区函数来决定的。创建数据分区函数有RANGE “LEFT | / RIGHT”两种选择。代表每个边界值在局部的哪一边。例如存在四个分区,则定义三个边界点值,并指定每个值是第一个分区的上边界 (LEFT) 还是第二个分区的下边界 (RIGHT)[1]。代码如下:CREATE PARTITION FUNCTION [SendSMSPF](datetime) AS RANGE RIGHT FOR VALUES ('20070401', '20070701', '20071001')
c.创建分区方案
创建分区函数后,必须将其与分区方案相关联,以便将分区指向至特定的文件组。就是定义实际存放数据的媒体与各数据块的对应关系。多个数据表可以 共用相同的数据分区函数,一般不共用相同的数据分区方案。可以通过不同的分区方案,使用相同的分区函数,使不同的数据表有相同的分区条件,但存放在不同的 媒介上。创建分区方案的代码如下:CREATE PARTITION SCHEME [SendSMSPS] AS PARTITION [SendSMSPF] TO ([FG1], [FG2], [FG3], [FG4])
d.创建分区表
建立好分区函数和分区方案后,就可以创建分区表了。分区表是通过定义分区键值和分区方案相联系的。插入记录时,SQL Server会根据分区键值的不同,通过分区函数的定义将数据放到相应的分区。从而把分区函数、分区方案和分区表三者有机的结合起来。创建分区表的代码如 下:CREATE TABLE SendSMSLog
([ID] [int] IDENTITY(1,1) NOT NULL,
[IDNum] [nvarchar](50) NULL,
[SendContent] [text] NULL
[SendDate] [datetime] NOT NULL,
) ON SendSMSPS(SendDate)
e.查看分区信息
系统运行一段时间或者把以前的数据导入分区表后,我们需要查看数据的具体存储情况,即每个分区存取的记录数,那些记录存取在那个分区等。我们可以通过$partition.SendSMSPF来查看,代码如下:SELECT $partition.SendSMSPF(o.SendDate)
AS [Partition Number]
, min(o.SendDate) AS [Min SendDate]
, max(o.SendDate) AS [Max SendDate]
, count(*) AS [Rows In Partition]
FROM dbo.SendSMSLog AS o
GROUP BY $partition.SendSMSPF(o.SendDate)
ORDER BY [Partition Number]
在查询分析器里执行以上脚本,结果如图1所示:
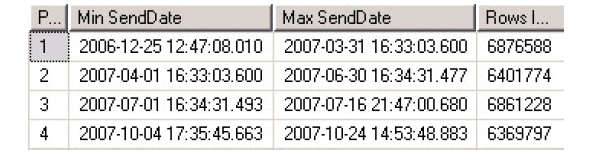
f.维护分区
分区的维护主要设计分区的添加、减少、合并和在分区间转换。可以通过ALTER PARTITION FUNCTION的选项SPLIT,MERGE和ALTER TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。g.性能对比
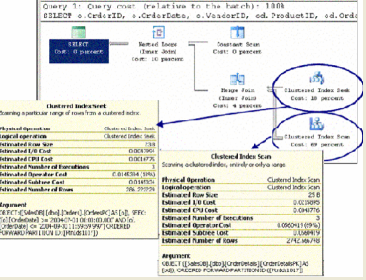
我们对2650万数据,存储空间占用约4G的单表进行性能对比如下图所示:
5.4示例说明(引用SQL Server连接帮助)
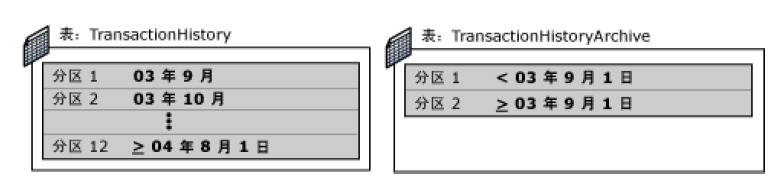
在 AdventureWorks 示例数据库的分区方案下,Adventure Works Cycles 通过在 TransactionHistory 表与 TransactionHistoryArchive 表之间切换分区将位于前一个表中的旧数据存档到后一个表中。可通过根据 TransactionDate 字段对 TransactionHistory 进行分区来执行此操作。每个分区的值范围为一个月。TransactionHistory 表维护年度中最新的事务,而 TransactionHistoryArchive 维护以前的事务。通过按这种方式对表进行分区,可以将一年期数据的单月值每月从 TransactionHistory 传输到 TransactionHistoryArchive。在每个月开始,TransactionHistory 表中当前具有的最早一个月的数据将被切换到 TransactionHistoryArchive 表中。若要完成此任务,应符合以下要求:
1. TransactionHistoryArchive 表必须与 TransactionHistory 表具有相同的设计架 构。还必须具有空白分区用来接收新数据。在这种情况下,TransactionHistoryArchive 是一个仅由两个分区组成的已分区表 - o。一个分区包含 2003 年 9 月之前的所有数据,另一个分区包含 2003 年 9 月及以后的所有数据。后一个分区是空的。
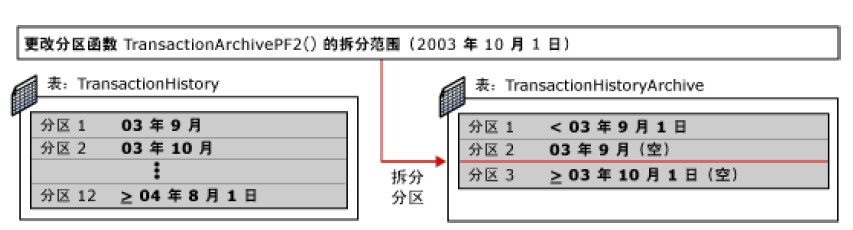
2. 修改 TransactionHistoryArchive 表的分区函数,以便将该表的空白分区拆分为两个分区,并将其中一个分区定义为接收 2003 年 9 月数据的新分区。
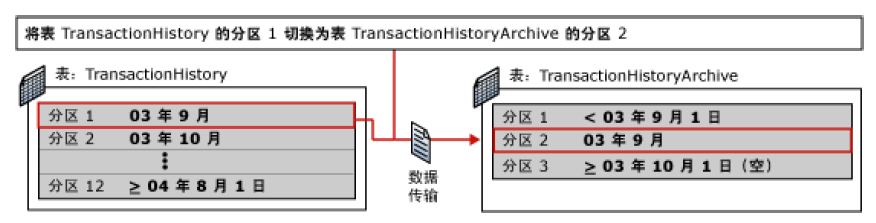
3. 将 TransactionHistory 表的第一个分区(其中包含 2003 年 9 月期间创建的所有数据)切换为 TransactionHistoryArchive 表的第二个分区。请注意,必须对 TransactionHistory 表定义检查约束以指定没有早于 9 月 1 日 (
TransactionDate >= '9/01/2003') 的数据。此约束可确保分区 1 仅包含 2003 年 9 月的数据,并确保该分区已准备好切换为 TransactionHistoryArchive 表的仅包含 2003 年 9 月的数据的分区。还请注意,在切换之前必须删除或禁用任何与它们各自的表未对齐的索引。但在切换之后可以重新创建这些索引。有关对齐已分区索引的详细信息,请参阅已分区索引的特殊指导原则。
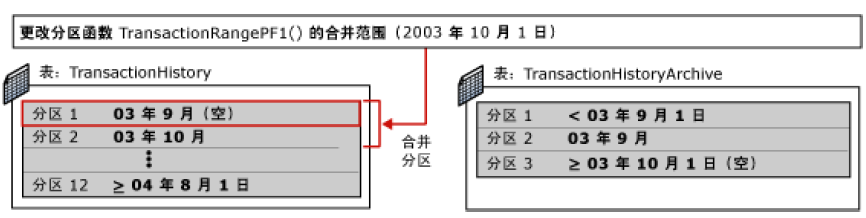
4. 修改 TransactionHistory 表的分区函数,以便将其前两个分区合并为一个分区。假设现有检查约束被更改为指定没有早于 10 月 1 日 (
TransactionDate >= '10/01/2003') 的数据,则此分区(现在为分区 1)包含 2003 年 10 月创建的所有数据并将在下个月准备好切换为 TransactionHistoryArchive。
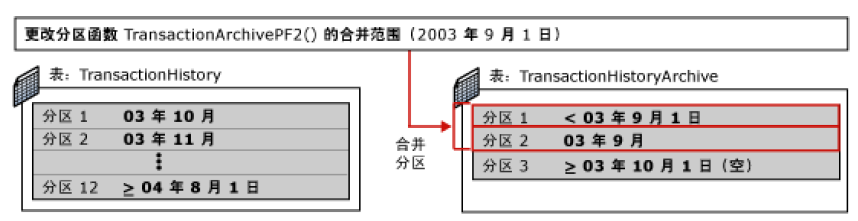
5. 再次修改 TransactionHistoryArchive 表的分区函数,以便将其第二个分区(包含刚刚添加的 9 月份数据)与第一个分区合并。此操作将使 TransactionHistoryArchive 表回到其初始状态,即第一个分区包含所有数据而第二个分区为空。
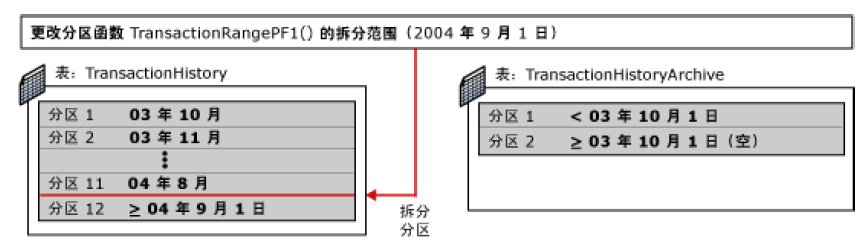
6. 再次修改 TransactionHistory 表的分区函数,以便将其最后一个分区拆分为两个分区,以使最新月份的数据与以前月份的数据分开并使分区准备好接收新数据。

相关文章推荐
- 经典实例演示C++对象构造
- C++对象数组的实例学习
- 最简短的拖动对象代码实例演示
- C++对象数组调用构造/析构函数的方法
- C++返回类实例,以及访问其他对象的私有成员
- 屏幕蒙层效果、图层对象绝对居中、拖拽图层对象三个功能实例演示剖析
- [笔记]C++代码演示SingletonMap 单类Map实例
- C++ 对象构造, 拷贝, 赋值和隐式类型转换总结
- C++对象的构造、赋值和析构
- C++ 对象和实例的区别,以及用new和不用new创建类对象区别
- C++对象模型之默认构造函数的构造操作,拷贝构造函数同
- c++关于类和对象的实例
- c++在调用类的时候不一定非得实例化对象哦,有时候你不写系统会为你默认生成一个临时实例对象哦~
- C++对象模型——继承体系下的对象构造(第五章)
- C++ 将对象的构造和析构函数声明为Protected的作用
- JAVA之旅(十二)——Thread,run和start的特点,线程运行状态,获取线程对象和名称,多线程实例演示,使用Runnable接口
- 卓越班暑假培训笔记(一)----java(类和对象的概念、实例变量、方法重载、构造方法、数据类型)
- C++ 回忆录5 对象的构造方法
- c#调用C++ dll 报未将对象引用到设置对象的实例 的解决方案
- C++面向对象笔记:构造、析构函数、成员函数