PageRank算法研究初步
2011-03-11 16:21
225 查看
最近在研究位置数据分级,简化一点就是位置数据排名。先抛开其它因素不管,如:品牌价值、人为因素、地价等。只考虑位置与周边位置之间的关系,这就让我想到了PageRank算法,这篇博文就简要的说说PageRank算法吧。
1、PageRank算法简介
搜索引擎Google最初是斯坦福大学的博士研究生Sergey Brin谢尔盖-布林和Lawrence Page拉里-佩奇实现的一个原型系统,现在已经发展成为WWW上最好的搜索引擎之一。Google的体系结构类似于传统的搜索引擎,它与传统的搜索引擎最大的不同处在于对网页进行了基于权威值的排序处理,使最重要的网页出现在结果的最前面。Google通过PageRank元算法计算出网页的PageRank值,从而决定网页在结果集中的出现位置,PageRank值越高的网页,在结果中出现的位置越前。简单的说,PageRank是代表网络上某个页面重要性的一个数值。
一般情况下搜索引擎将PageRank值与网页搜索结果相似度共同作为搜索结果的排序依据。该值仅仅依赖于网络的链接结构(即有多少链接链入该网站,以及该网站有多少链出。同样和位置空间分布类似),而与具体的检索内容无关。就像后边即将阐述的一样,检索语句不会呈现在PageRank本身的计算式上。不管得到多少的检索语句,PageRank也是一定的、文件固有的评分量。
2、PageRank算法简单解析
PageRank算法简单点说,就是网页的PR值等于该网页的链入网站的PR值除以链入网页的链出数之和,即是将所有指向该网页的PR值平均后,分给该网页。
这就可以这样说,如果一个网页被多次引用,则它可能是很重要的;一个网页虽然没有被多次引用,但是被重要的网页引用,则它也可能是很重要的;一个网页的重要性被平均的传递到它所引用的网页。
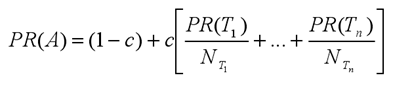
上面是PR值的迭代计算公式,C为阻尼因子,为了保证在迭代过程中,函数收敛(这个我还没有证明过)。PR(T1)是指向A网页的网页PR值,NT1是T1的出度。
当上述迭代公式运算次数越来越多的时候,PR值会接近一个固定值,精确计算次数是Google的商业机密,所以我们也无从得知。但是Lawrence Page拉里-佩奇发表的公开文献中说到,对3.22亿个链接进行的递归运算,52次即可得到稳定的PageRank值,且计算次数与页面是呈对数增长的。
3、原始PageRank算法的不足
最基础的的PageRank值有很多的不足,如:1)算法偏重旧网页,因为旧网页被其它网页链接到的可能性比较高,但事实上却不一定,长江后浪推前浪啊。2)算法容易造成主题偏移,比如说Google、Baidu等是互联网上很受欢迎的,相应的PR也肯定高。但是用户输入关键字的时候,如果这些网页也在结果集中,那么由于其高PR值,就会抢占靠前的位置,事实上,大伙要的结果并不一定是这样。
PageRank有很多很多的改进算法,比如说那个旧网页的问题,上海交大的张玲博士提出了一个加速评估算法,加入了网页最近一段时间网页PR的二次拟合曲线的斜率。考虑了时间因素……
针对不同问题有不同解决方法,有兴趣的可以看看相关的文献。
其实我的这个位置分级和PageRank本质也有不同的地方,比如那条:一个网页虽然没有被多次引用,但是被重要的网页引用,则它也可能是很重要的。这个在空间分布上却不相同,一个大酒店旁边有一个小报刊亭,那么这小报刊亭Rank值高?不见得……所以我还有很多需要考虑的地方咯!
参考文献:
黄德才, 戚华春. PageRank算法研究[J]. 计算机工程. 2006
张巍. 基于PageRank算法的搜索引擎优化策略研究[M]. 四川大学. 2005
1、PageRank算法简介
搜索引擎Google最初是斯坦福大学的博士研究生Sergey Brin谢尔盖-布林和Lawrence Page拉里-佩奇实现的一个原型系统,现在已经发展成为WWW上最好的搜索引擎之一。Google的体系结构类似于传统的搜索引擎,它与传统的搜索引擎最大的不同处在于对网页进行了基于权威值的排序处理,使最重要的网页出现在结果的最前面。Google通过PageRank元算法计算出网页的PageRank值,从而决定网页在结果集中的出现位置,PageRank值越高的网页,在结果中出现的位置越前。简单的说,PageRank是代表网络上某个页面重要性的一个数值。
一般情况下搜索引擎将PageRank值与网页搜索结果相似度共同作为搜索结果的排序依据。该值仅仅依赖于网络的链接结构(即有多少链接链入该网站,以及该网站有多少链出。同样和位置空间分布类似),而与具体的检索内容无关。就像后边即将阐述的一样,检索语句不会呈现在PageRank本身的计算式上。不管得到多少的检索语句,PageRank也是一定的、文件固有的评分量。
2、PageRank算法简单解析
PageRank算法简单点说,就是网页的PR值等于该网页的链入网站的PR值除以链入网页的链出数之和,即是将所有指向该网页的PR值平均后,分给该网页。
这就可以这样说,如果一个网页被多次引用,则它可能是很重要的;一个网页虽然没有被多次引用,但是被重要的网页引用,则它也可能是很重要的;一个网页的重要性被平均的传递到它所引用的网页。

上面是PR值的迭代计算公式,C为阻尼因子,为了保证在迭代过程中,函数收敛(这个我还没有证明过)。PR(T1)是指向A网页的网页PR值,NT1是T1的出度。
当上述迭代公式运算次数越来越多的时候,PR值会接近一个固定值,精确计算次数是Google的商业机密,所以我们也无从得知。但是Lawrence Page拉里-佩奇发表的公开文献中说到,对3.22亿个链接进行的递归运算,52次即可得到稳定的PageRank值,且计算次数与页面是呈对数增长的。
3、原始PageRank算法的不足
最基础的的PageRank值有很多的不足,如:1)算法偏重旧网页,因为旧网页被其它网页链接到的可能性比较高,但事实上却不一定,长江后浪推前浪啊。2)算法容易造成主题偏移,比如说Google、Baidu等是互联网上很受欢迎的,相应的PR也肯定高。但是用户输入关键字的时候,如果这些网页也在结果集中,那么由于其高PR值,就会抢占靠前的位置,事实上,大伙要的结果并不一定是这样。
PageRank有很多很多的改进算法,比如说那个旧网页的问题,上海交大的张玲博士提出了一个加速评估算法,加入了网页最近一段时间网页PR的二次拟合曲线的斜率。考虑了时间因素……
针对不同问题有不同解决方法,有兴趣的可以看看相关的文献。
其实我的这个位置分级和PageRank本质也有不同的地方,比如那条:一个网页虽然没有被多次引用,但是被重要的网页引用,则它也可能是很重要的。这个在空间分布上却不相同,一个大酒店旁边有一个小报刊亭,那么这小报刊亭Rank值高?不见得……所以我还有很多需要考虑的地方咯!
参考文献:
黄德才, 戚华春. PageRank算法研究[J]. 计算机工程. 2006
张巍. 基于PageRank算法的搜索引擎优化策略研究[M]. 四川大学. 2005

相关文章推荐
- 经典算法研究系列:六、教你初步了解KMP算法、updated
- 算法分析与设计课程资料:蚂蚁算法的初步研究与计算机模拟
- 经典算法研究系列:六、教你初步了解KMP算法、updated
- 经典算法研究系列:六、教你初步了解KMP算法、updated
- 经典算法研究系列:六、教你初步了解KMP算法、updated
- k-近邻算法的初步研究
- OpenStack中的调度(Scheduler)算法初步研究
- 经典算法研究系列:六、教你初步了解KMP算法、updated
- 经典算法研究系列:六、教你初步了解KMP算法、updated
- 中文分词算法的初步研究
- 对LCS算法及其变种的初步研究
- 对LCS算法及其变种的初步研究
- OpenStack中的调度(Scheduler)算法初步研究
- 基于DM642的图像边缘检测算法的研究
- JSSDK taobao js 研究 之 js sign的算法
- iOS多线程的初步研究(三)-- NSRunLoop
- 背景差分算法研究资源分享
- 算法竞赛入门10.1数论初步例题代码
- 边缘文本检测:快速的和健壮的场景文本定位算法的研究
- 图像去雾算法(一)相关研究及链接