python技巧31[python文件的encoding和str的decode]
2011-01-06 22:43
489 查看
一 python文件的encoding
默认地,python的.py文件以标准的7位ASCII码存储,然而如果有的时候用户需要在.py文件中包含很多的unicode字符,例如.py文件中需要包含中文的字符串,这时可以在.py文件的第一行或第二行增加encoding注释来将.py文件指定为unicode格式。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
s = "中国" # String in quotes is directly encoded in UTF-8.
但是如果你的py文件是文本文件,且是unicode格式的,不指定# -*- coding: UTF-8 -*-也可以的。
(通过notepad++下的format->encode in utf-8来确保为utf-8)
如下:
import sys
print (sys.getdefaultencoding())
mystr = "test unicode 中国"
print (mystr)
还有奇怪的是好像sys.getdefaultencoding()总是返回utf-8,不管文件是ascii还是utf8的。
可以使用下面的设置python文件编码:
#encoding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
二 str的encode
在python3以后的版本中,str默认已经为unicode格式。当然也可以使用b''来定义bytes的string。
但是有的时候我们需要对str进行ASCII和Unicode间转化,unicode的str的转化bytes时使用str.encode(),bytes的str转化为unicode时使用str.decode()。
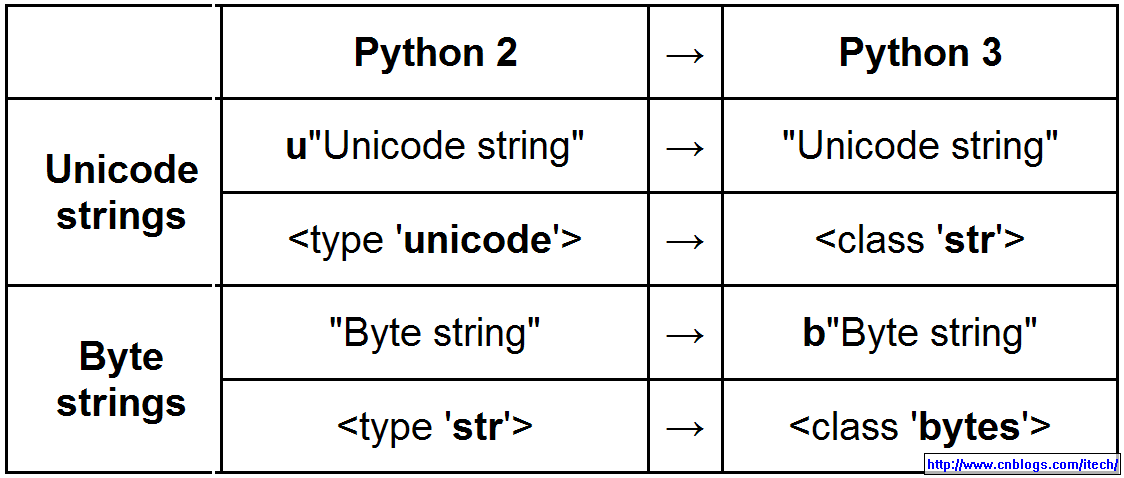
python2和python3中str的比较:
python3中的str的转化函数:

可能需要str的转化的情况:

可能需要str的转化的情况:

完!
默认地,python的.py文件以标准的7位ASCII码存储,然而如果有的时候用户需要在.py文件中包含很多的unicode字符,例如.py文件中需要包含中文的字符串,这时可以在.py文件的第一行或第二行增加encoding注释来将.py文件指定为unicode格式。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
s = "中国" # String in quotes is directly encoded in UTF-8.
但是如果你的py文件是文本文件,且是unicode格式的,不指定# -*- coding: UTF-8 -*-也可以的。
(通过notepad++下的format->encode in utf-8来确保为utf-8)
如下:
import sys
print (sys.getdefaultencoding())
mystr = "test unicode 中国"
print (mystr)
还有奇怪的是好像sys.getdefaultencoding()总是返回utf-8,不管文件是ascii还是utf8的。
可以使用下面的设置python文件编码:
#encoding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
二 str的encode
在python3以后的版本中,str默认已经为unicode格式。当然也可以使用b''来定义bytes的string。
但是有的时候我们需要对str进行ASCII和Unicode间转化,unicode的str的转化bytes时使用str.encode(),bytes的str转化为unicode时使用str.decode()。
python2和python3中str的比较:
python3中的str的转化函数:
可能需要str的转化的情况:
可能需要str的转化的情况:
完!

相关文章推荐
- python技巧31[python文件的encoding和str的decode]
- Python3 批量转换文件编码 Encoding
- src/MD2.c:31:20: 错误:Python.h:没有那个文件或目录
- python中文件操作技巧
- python通过zlib实现压缩文件内容(str),和解压缩还原文件内容
- python selenium系列(10)实战技巧之文件上传
- python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multib
- python技巧31[判断操作系统类型]
- 小甲鱼python第30,31讲--python文件系统/模块 笔记及习题答案
- python技巧31[判断操作系统类型]
- [Python] 中文编码问题:raw_input输入、文件读取、变量比较等str、unicode、utf-8转换问题
- 【Python】Python读取文件报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0x99 in position 20: illegal multibyte sequence
- python技巧31[python Tip2]
- python | 读文件编码问题 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 34: illegal mu
- python基础31[list+tuple+set+dict+str+file的成员方法]
- Python中用encoding声明的文件编码和文件的实际编码之间的关系
- Python:文件操作技巧(File operation)
- python3.6报错:AttributeError: 'str' object has no attribute 'decode'
- python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multib
- Python:文件操作技巧(File operation)