nginx源码分析(1):hash的使用
2010-09-20 15:25
411 查看
在nginx源码中提供了一个比较重要的hash结构,可以为我们带来高效的kv查找。该hash的实现比较简单,但却非常的高效。该hash结构是只读的,在创建之后,以后只能提供查询功能。
该hash结构体,刚开始理解起来比较费劲,而且在使用时也会有不爽的感觉,需要好几个结构体,以及好几个函数配合才能完成初始化及查找。在本文中,对于通配符的使用,我们先不作介绍。
我们先看看如何使用吧。
创建一个hash结构体的过程是:
1. 构造一个ngx_hash_key_t为成员的数组,然后用我们需要hash的key、value以及计算出来的hash值来初始化该数组的每一个成员。
2. 构建一个 ngx_hash_init_t结构体的变量, 其中包含了ngx_hash_t 的成员, 为hash的结构体, 还包括一些其他初始设置,如bucket的大小,内存池等。该hash结构体会在ngx_hash_init中创建及初始化。
3. 调用 ngx_hash_init 传入 ngx_hash_init_t 结构, ngx_hash_key_t 的数组,和数组的长度, 进行初始化,这样 ngx_hash_init_t的hash成员就是我们要的hash结构体。
再看看查找:
1. 计算出key的hash值。
2. 使用 ngx_hash_find 进行查找,需要同时传入 hash值和key ,返回的就是value的指针。
看起来似乎还比较简单,示例代码来段:
接下来我们来分析下源码,先介绍几个结构体:
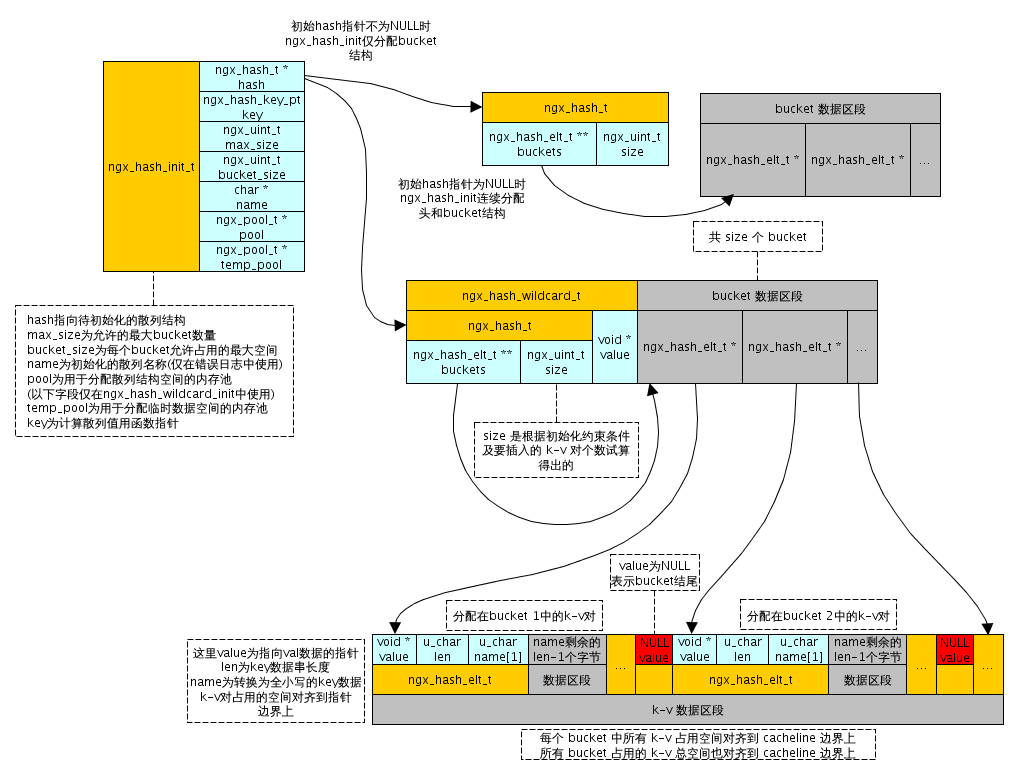
在熟悉了结构体之后,我先给大家看看hash在内存中的存放布局,看图:
接下来,我们来看看复杂的ngx_hash_init函数:
ngx_hash_find提供hash查找:
好,先介绍到这,最后感谢http://code.google.com/p/nginxsrp/wiki/NginxCodeReview所提供的帮助及图文!
该hash结构体,刚开始理解起来比较费劲,而且在使用时也会有不爽的感觉,需要好几个结构体,以及好几个函数配合才能完成初始化及查找。在本文中,对于通配符的使用,我们先不作介绍。
我们先看看如何使用吧。
创建一个hash结构体的过程是:
1. 构造一个ngx_hash_key_t为成员的数组,然后用我们需要hash的key、value以及计算出来的hash值来初始化该数组的每一个成员。
2. 构建一个 ngx_hash_init_t结构体的变量, 其中包含了ngx_hash_t 的成员, 为hash的结构体, 还包括一些其他初始设置,如bucket的大小,内存池等。该hash结构体会在ngx_hash_init中创建及初始化。
3. 调用 ngx_hash_init 传入 ngx_hash_init_t 结构, ngx_hash_key_t 的数组,和数组的长度, 进行初始化,这样 ngx_hash_init_t的hash成员就是我们要的hash结构体。
再看看查找:
1. 计算出key的hash值。
2. 使用 ngx_hash_find 进行查找,需要同时传入 hash值和key ,返回的就是value的指针。
看起来似乎还比较简单,示例代码来段:
#include <stdio.h>
#include "ngx_config.h"
#include "ngx_conf_file.h"
#include "nginx.h"
#include "ngx_core.h"
#include "ngx_string.h"
#include "ngx_palloc.h"
#include "ngx_array.h"
#include "ngx_hash.h"
volatile ngx_cycle_t *ngx_cycle;
void ngx_log_error_core(ngx_uint_t level, ngx_log_t *log, ngx_err_t err, const char *fmt, ...) { }
static ngx_str_t names[] = {ngx_string("rainx"),
ngx_string("xiaozhe"),
ngx_string("zhoujian")};
static char* descs[] = {"rainx's id is 1","xiaozhe's id is 2","zhoujian's id is 3"};
// hash table的一些基本操作
int main()
{
ngx_uint_t k; //, p, h;
ngx_pool_t* pool;
ngx_hash_init_t hash_init;
ngx_hash_t* hash;
ngx_array_t* elements;
ngx_hash_key_t* arr_node;
char* find;
int i;
ngx_cacheline_size = 32;
// hash key cal start
ngx_str_t str = ngx_string("hello, world");
k = ngx_hash_key_lc( str.data, str.len);
pool = ngx_create_pool(1024*10, NULL);
printf("caculated key is %u /n", k);
// hask key cal end
//
hash = (ngx_hash_t*) ngx_pcalloc(pool, sizeof(hash));
hash_init.hash = hash; // hash结构
hash_init.key = &ngx_hash_key_lc; // hash算法函数
hash_init.max_size = 1024*10; // max_size
hash_init.bucket_size = 64; // ngx_align(64, ngx_cacheline_size);
hash_init.name = "yahoo_guy_hash"; // 在log里会用到
hash_init.pool = pool; // 内存池
hash_init.temp_pool = NULL;
// 创建数组
elements = ngx_array_create(pool, 32, sizeof(ngx_hash_key_t));
for(i = 0; i < 3; i++) {
arr_node = (ngx_hash_key_t*) ngx_array_push(elements);
arr_node->key = (names[i]);
arr_node->key_hash = ngx_hash_key_lc(arr_node->key.data, arr_node->key.len);
arr_node->value = (void*) descs[i];
//
printf("key: %s , key_hash: %u/n", arr_node->key.data, arr_node->key_hash);
}
if (ngx_hash_init(&hash_init, (ngx_hash_key_t*) elements->elts, elements->nelts)!=NGX_OK){
return 1;
}
// 查找
k = ngx_hash_key_lc(names[0].data, names[0].len);
printf("%s key is %d/n", names[0].data, k);
find = (char*)
ngx_hash_find(hash, k, (u_char*) names[0].data, names[0].len);
if (find) {
printf("get desc of rainx: %s/n", (char*) find);
}
ngx_array_destroy(elements);
ngx_destroy_pool(pool);
return 0;
}接下来我们来分析下源码,先介绍几个结构体:
// 存放在桶中的每个元素
typedef struct {
void *value; // 具体存放的值,对应于value
u_char len; // name的长度
u_char name[1]; // 对应于小写的key
} ngx_hash_elt_t;
// hash结构体
typedef struct {
ngx_hash_elt_t **buckets; // 指向桶的实际空间
ngx_uint_t size;
} ngx_hash_t;
/* 通配符 */
typedef struct {
ngx_hash_t hash; // 这里会包含hash,所以在分配空间是不需特别分配给他
void *value;
} ngx_hash_wildcard_t;
/* kv对,包含 hash值 */
typedef struct {
ngx_str_t key;
ngx_uint_t key_hash;
void *value;
} ngx_hash_key_t;
/* hash 函数指针 */
typedef ngx_uint_t (*ngx_hash_key_pt) (u_char *data, size_t len);// 包含hash的初始化信息
typedef struct {
ngx_hash_t *hash; // 指向我们实际的hash结构体
ngx_hash_key_pt key; // hash 函数
ngx_uint_t max_size; // 最大元素个数
ngx_uint_t bucket_size;// 桶的大小
char *name; // 在log中会用到
ngx_pool_t *pool; // 内存池
ngx_pool_t *temp_pool;
} ngx_hash_init_t;在熟悉了结构体之后,我先给大家看看hash在内存中的存放布局,看图:
接下来,我们来看看复杂的ngx_hash_init函数:
// 初始化一个hash结构体,第一个参数是我们hash结构体的一些参数,第二个参数是我们需要hash的kv值数组
// 第三个是元素个数
// 对齐之后的元素大小
#define NGX_HASH_ELT_SIZE(name) /
(sizeof(void *) + ngx_align((name)->key.len + 1, sizeof(void *)))
// 初始化一个hash
ngx_int_t
ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)
{
u_char *elts;
size_t len;
u_short *test;
ngx_uint_t i, n, key, size, start, bucket_size;
ngx_hash_elt_t *elt, **buckets;
for (n = 0; n < nelts; n++) {
// key不能大于255
if (names
.key.len >= 255) {
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"the /"%V/" value to hash is to long: %uz bytes, "
"the maximum length can be 255 bytes only",
&names
.key, names
.key.len);
return NGX_ERROR;
}
// 判断每个元素所占的空间是否都小于桶的大小
if (hinit->bucket_size < NGX_HASH_ELT_SIZE(&names
) + sizeof(void *))
{
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should "
"increase %s_bucket_size: %i",
hinit->name, hinit->name, hinit->bucket_size);
return NGX_ERROR;
}
}
// 用于记录每个桶的临时大小
test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log);
if (test == NULL) {
return NGX_ERROR;
}
// 得到每个桶去掉指针之后的实际大小
// 为什么会多一个指针大小呢?这里主要还是为了后面将每个元素对齐到指针
bucket_size = hinit->bucket_size - sizeof(void *);
// 这里我还没有弄懂呢!!高人指教一下
start = nelts / (bucket_size / (2 * sizeof(void *)));
start = start ? start : 1;
if (hinit->max_size > 10000 && hinit->max_size / nelts < 100) {
start = hinit->max_size - 1000;
}
// 以下为计算实际用桶数
for (size = start; size < hinit->max_size; size++) {
ngx_memzero(test, size * sizeof(u_short));
// 处理每一个key
for (n = 0; n < nelts; n++) {
// key为空
if (names
.key.data == NULL) {
continue;
}
// 得到该key应该存放的桶
key = names
.key_hash % size;
// 增加该桶的test的大小
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names
));
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"%ui: %ui %ui /"%V/"",
size, key, test[key], &names
.key);
#endif
// 如果当前桶存放的元素过多,则表明应该放到下一个桶中去
// 跳出后,继续执行循环,并将实际用桶个数增加
if (test[key] > (u_short) bucket_size) {
goto next;
}
}
// 当前桶数可以满足要求
goto found;
// 应该增加实际用桶的个数
next:
continue;
}
// 否是,最大桶数也不能满足实际用桶数的需求,出错
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should increase "
"either %s_max_size: %i or %s_bucket_size: %i",
hinit->name, hinit->name, hinit->max_size,
hinit->name, hinit->bucket_size);
ngx_free(test);
return NGX_ERROR;
found:
//
for (i = 0; i < size; i++) {
test[i] = sizeof(void *);
}
// 得到每个桶的实际使用大小
for (n = 0; n < nelts; n++) {
if (names
.key.data == NULL) {
continue;
}
key = names
.key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names
));
}
len = 0;
// 向每个桶的实际大小对应到cacheline上,并得到所有桶的总大小
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
test[i] = (u_short) (ngx_align(test[i], ngx_cacheline_size));
len += test[i];
}
if (hinit->hash == NULL) {
// 这里似乎看起来很奇怪,既然是hash,为什么分配空间的大小又跟hash结构体一点关联都没有呢
// 这里很有意思,因为ngx_hash_wildchard_t包含hash这个结构体,所以就一起分配了
// 并且把每个桶的指针也分配在一起了,这种思考跟以前学的面向对象思想很不一样,但这样会很高效
hinit->hash = ngx_pcalloc(hinit->pool, sizeof(ngx_hash_wildcard_t)
+ size * sizeof(ngx_hash_elt_t *));
if (hinit->hash == NULL) {
ngx_free(test);
return NGX_ERROR;
}
buckets = (ngx_hash_elt_t **)
((u_char *) hinit->hash + sizeof(ngx_hash_wildcard_t));
} else {
buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *));
if (buckets == NULL) {
ngx_free(test);
return NGX_ERROR;
}
}
// 内存对齐到cache行
elts = ngx_palloc(hinit->pool, len + ngx_cacheline_size);
if (elts == NULL) {
ngx_free(test);
return NGX_ERROR;
}
elts = ngx_align_ptr(elts, ngx_cacheline_size);
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
// 指向每个桶的空间
buckets[i] = (ngx_hash_elt_t *) elts;
elts += test[i];
}
// 清空重新计算
for (i = 0; i < size; i++) {
test[i] = 0;
}
// 向每个kv对应到相应的桶中相应的位置上去
for (n = 0; n < nelts; n++) {
if (names
.key.data == NULL) {
continue;
}
// 得到当前桶,及当前桶应该存放的内存地址
key = names
.key_hash % size;
elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]);
// 设置当前元素的值与大小
elt->value = names
.value;
elt->len = (u_char) names
.key.len;
// 得到key的小写,并保存到桶中去
ngx_strlow(elt->name, names
.key.data, names
.key.len);
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names
));
}
// 设置每个桶的结束元素为NULL
for (i = 0; i < size; i++) {
if (buckets[i] == NULL) {
continue;
}
elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]);
elt->value = NULL;
}
ngx_free(test);
hinit->hash->buckets = buckets;
hinit->hash->size = size;
return NGX_OK;
}ngx_hash_find提供hash查找:
// 查找,第一个参数是我们的hash结构体,第二个参数是我们根据hash函数生成的hash值,
// 第三个参数是我们要查找的key,第四个参数是key的长度
void *
ngx_hash_find(ngx_hash_t *hash, ngx_uint_t key, u_char *name, size_t len)
{
ngx_uint_t i;
ngx_hash_elt_t *elt;
#if 0
ngx_log_error(NGX_LOG_ALERT, ngx_cycle->log, 0, "hf:/"%*s/"", len, name);
#endif
// 得到该元素可能存在的桶
elt = hash->buckets[key % hash->size];
// 如查没找到,则返回空
if (elt == NULL) {
return NULL;
}
// 遍历该桶的每个元素
while (elt->value) {
// 如果长度不对,则查找下一个
if (len != (size_t) elt->len) {
goto next;
}
// 然后比较key
for (i = 0; i < len; i++) {
if (name[i] != elt->name[i]) {
goto next;
}
}
return elt->value;
next:
elt = (ngx_hash_elt_t *) ngx_align_ptr(&elt->name[0] + elt->len,
sizeof(void *));
continue;
}
return NULL;
}好,先介绍到这,最后感谢http://code.google.com/p/nginxsrp/wiki/NginxCodeReview所提供的帮助及图文!

相关文章推荐
- nginx 基本hash的初始化 源码分析
- Nginx源码分析 - 基础数据结构篇 - hash表结构 ngx_hash.c
- nginx源码分析—hash结构
- Nginx源码分析-定时器的实现及使用
- nginx源码分析--数据结构 哈希 ngx_hash_t
- nginx源码分析--使用GDB调试
- Nginx源码分析---hash结构ngx_hash_t(v1.0.4)
- nginx源码分析2———基础数据结构六(ngx_hash_keys_arrays_t)
- nginx源码分析之hash的实现
- nginx的源码分析--间接回调机制的使用和类比
- nginx的源码分析--间接回调机制的使用和类比
- nginx源码分析--使用GDB调试
- nginx源码分析—hash结构ngx_hash_t(v1.0.4)
- Nginx 单元测试自动化浅析之一-Test::Nginx源码分析和使用
- nginx源码分析--使用GDB调试(strace、 pstack )
- nginx源码分析2———基础数据结构五(ngx_hash_wildcard_t)
- nginx源码分析—信号初始化和使用
- nginx源码分析—hash结构ngx_hash_t(v1.0.4)
- Nginx源码分析之ngx_hash_t
- [nginx源码分析]hash 和header 回调初始化