An Overview of C# 4.0
2010-08-18 10:28
246 查看
摘自:codeproject.com
Discusses the new features of C# 4.0 including dynamiclookup, covariance/contravariance generics, named and optional paramters
Introduction
The .NET framework
4.0 CTP has just been released, and I think it’s a good time to explore the new
features of C# 4.0. In this post, I will introduce about the following
features: dynamic lookup, generics covariance and contravariance support,
optional and named parameters.
Dynamic Lookup
If varin
C# 3.0 brings about type inference for local variables with the purpose of
saving a couple of key strokes, dynamic lookup adds much more to the dynamicity
of the C# language. When you declare a variable with dynamic, all of its method
invocations or member accesses will be resolved at runtime. For example, let’s
look at the following code:
public
static
void
Main() {
dynamic obj = "I'm
statically System.String";
obj.NotExistingMethod("param");
}
In the code, we create a string object, and instead of
assigning it to a variable of type
string
, we assign it to a
variable declared as
. This basically
instructs the compiler to not attempt to resolve any method call or member
access of the declared variable. Instead, all these resolutions will happen at
runtime. That being done, the next line in which we invoke a non-existing
method with an arbitrary parameter will compile just fine into CIL. At runtime,
when the method call is resolved and the runtime finds that there’s no such
method in the runtime type (which is a
String
), an exception is thrown. That being said, if we use a
valid method, then there would be no exception and the code will run fine till
completion. For example:
private
static
void
PrintID(dynamic obj) {
Console.WriteLine(obj.ID);
}
public
static
void
Main() {
var person =
new
{ID =
111
, Name =
"Buu"
};
PrintID(person);
var account =
new
{ID =
101
, Bank =
"Some Bank"
};
PrintID(account);
}
We basically create two anonymous types, for the sake of
convenience, both having a property called
ID, and then
instantiate objects out of these types. We then pass each of these two objects
to the method
PrintID, which accepts a dynamicobject and prints out the ID property. The code will print out “111” and “101”,
respectively. And yes, we’ve just seen duck typing in action. In C#.
That example also implies an interesting usage of
dynamicwith regard to anonymous types. Now, we can pass
objects of anonymous types out of their declaration scope (e.g., the method)
and still be able to invoke their methods or access their members without
resorting to verbose Reflection code.
We are not just limited to making statically typed .NETobjects become dynamic, we can use this dynamic lookup feature to conveniently
interact with “actual” dynamic objects available through the Dynamic Language
Runtime (DLR) included in .NET framework 4.0. In fact, we can implement such
dynamic objects in C# by implementing the
interface, which is also part of the DLR. Regardless of the actual
receiver of dynamic dispatch, the usage of dynamic lookup is exactly the same
from the caller’s perspective.
Some of you might wonder what code the compiler generates
and whether there is any change to the CLR to support dynamic lookup or not. To
answer that question, let’s look at the CIL generated from the very first code
fragment of this post. (Click on the image to see the full size.)
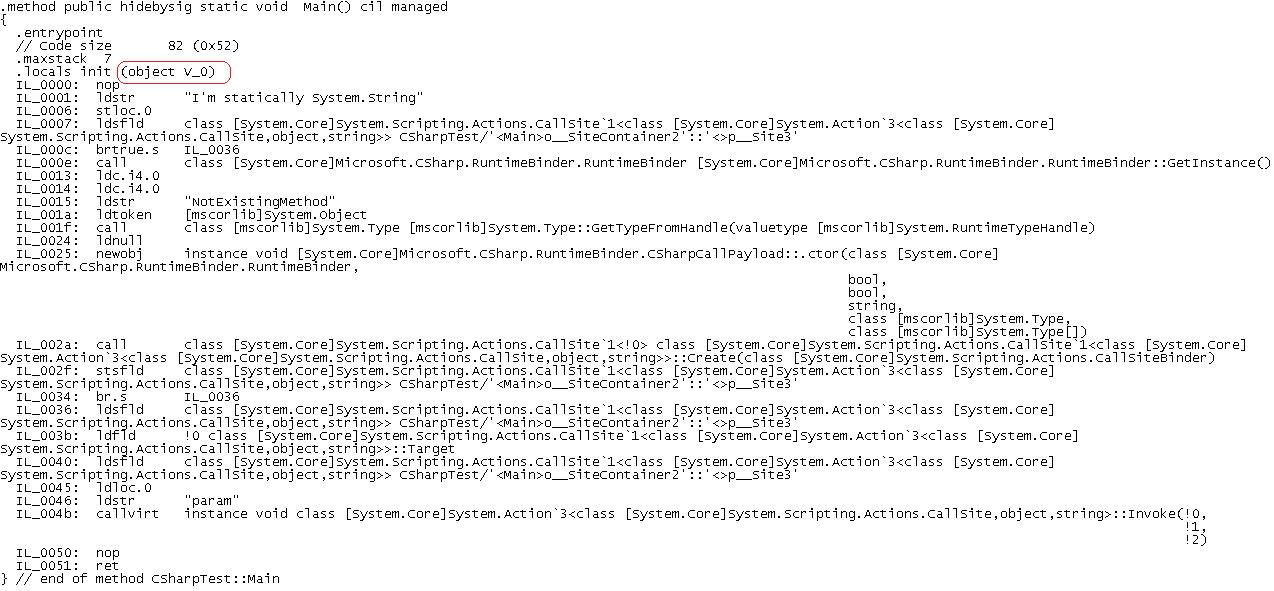
The generated CIL is pretty verbose, but a skim through it
reveals two important things. Firstly, our “dynamic variable” turns out to be a
plain old CLR
Object
instance. And secondly, there’s no new CIL directive or opcode to
support dynamic lookup. Instead, dynamic resolution and invocation is
completely handled by framework code. In fact, the above CIL is equivalent to
the following C# code, but now, without the
keyword.
object
obj =
"I'm statically
System.String"
;
var payload =
new
CSharpCallPayload(
RuntimeBinder.GetInstance(),
false
,
false
,
"NotExistingMethod"
,
typeof
(
object
),
null
);
var callSite = CallSite<Action<CallSite,
object
, string>>.Create(payLoad);
Action<CallSite,
object
,
string> action = callSite.Target;
action.Invoke(callSite, obj,
"param"
);
(In fact, I simplified the code a bit so that it can fit in
one method. The actual CIL generated does have a check at
, which basically looks at the
static field of a
nested class, which is generated automatically by the compiler to see if it’s
null
or not before going ahead and initializing it. In order words, the
is cached for
subsequent invocations of the same method.)
So, there’s really no magic behind the
keyword. What the compiler basically does is generate some payload
containing the information about the invocation so that it can be made at
runtime. If there’s any magic at all, it would be in the static method
which uses Reflection to invoke the
on the given object if it’s not an instance of
.
Now, we know that a “dynamic object” is actually a plain
old object; it should explain why a method can accept dynamic parameters. It
should also be of no surprise to know that dynamic lookup can also be applied
to the return value of an instance/static method or an instance/static field.
After all, unlike the
keyword which requires the compiler to infer the exact type at
compile time, the compiler in dynamic lookup scenarios can simply pick
Object
as the type.
Generics Covariance and Contravariance
In previous versions of C#, generic types are invariant.
That is, for any two types
<
>
and
<
>
, in which
is a subclass of
or
is a subclass of
,
<
>
and
<
>
have no inheritance relationship whatsoever to each other. On the
other hand, if
is a subclass of
and if C# supports
covariance,
<
>
is also a subclass of
<
>
, or if C# supports
contravariance,
<
>
is a superclass of
<
>
.
To understand why pre-4.0 C# disallows covariance and
contravariance, let’s look at some code:
var strList =
new
List<string>();
List<object> objList = strList;
// compile-error, with cast or
not
The code in line 2 can be error-prone. Consider what we can
write after line 2, assuming it is allowed:
// BOOM: we're adding an arbitrary AnyObject to what,
// at runtime, is a list of strings
objList.add(
new
AnyObject());
On the other hand, if C# supported contravariance, we could
have written the following problematic code:
var objList =
new
List<object>;
objList.add(
3
);
objList.add(
new
AnyObject());
List<string> strList = objList;
// BOOM: we're getting an arbitrary object thinking it’s
a string
string
element =
strList.
get
(
0
);
Due to this invariant restriction, although for the good
purpose, we can’t easily reuse variables and methods to respectively get
assigned to or accept various generic types. It’s somewhat unfortunate because
the key thing to realize is that covariance is fine as long as
<
>
does not have any
method or member accepting arguments of type
(e.g., if we can’t add
a bunch of objects into the
, which is indeed an instance of
<
string
>
, we’ll be safe).
Besides, contravariance is just as safe if
does not appear in any
return value from a member or method (e.g., if we can’t get any string out from
, which is indeed an instance of
<
object
>
, we’ll be safe).
Fortunately, C# 4.0 provides us an option: if a
generic
interface
or
generic
delegate
has a
reference
type
as its type parameter
and does not have any method or member that takes in a parameter of type
, we can declare it to be covariant on
. On the other hand, if that interface or delegate does not have
any method or member that returns
, we can declare it to be contravariant on
. (Notice the emphases, only interfaces and delegates have
covariance and contravariance support, and the type parameter must be a
reference type. On the other hand, C# arrays have been supporting covariance
from the very beginning.)
Let’s look at an example. We have a
delegate which
basically returns random instances of objects of a certain type (e.g.,
string
). Its declaration is as follows:
delegate
TGenerator<out T>();
Because this delegate does not take in any
as its argument, we
can safely make it covariant on
. And indeed, the compiler will allow us to do so by adding
the modifier
out
before the type parameter. However, if this delegate is declared
as, say,
delegate
, then the compiler will complain since it’s no longer safe for
covariance. Now, let’s look at the usage:
Generator<string> strGen =
new
Generator<string>(StringGenerator);
// Below line is compiled now because
Generator<string> is
// subclass of Generator<object> under covariant
rule
Generator<object> objGen = strGen;
// Downcast is also allowed for the same reason
strGen = (Generator<String>)objGen;
...
private
string
StringGenerator(){
return
"I'm a random string"
;
}
With contravariance, you need to use the
in
keyword. Let’s look at an example that makes use of both contravariance
and covariance:
delegate
KConverter<in T,
out
K>(Tparam);
This converter takes an object of type
and converts it to an
object of type
(e.g., convert
String
to
Object
). Since it does not take in any
, it can safely be declared to be covariant on
. Similarly, since it exposes no
, it can safely be
declared to be contravariant on
. Its usage is as follows:
var converter =
new
Converter<object, string>( ConvertImpl);
Converter<string, object> string2ObjectConverter =
converter;
object
result =
string2ObjectConverter(
"A"
);
...
private
string
ConvertImpl(
object
o) {
return
o.ToString();
}
Note that although the above examples show how to declare
covariance and contravariance for delegate types, it’s not different to do so
with interfaces.
Before we finish with covariance and contravariance, let’s
look at what code the compiler generates. After all, we know that the compiler
must encode something to the CIL to denote covariant and/or contravariant
generic types so that they can be consumed properly by client code. And, this
is what the definitions of our
and
delegates are when viewed from ILDASM.

Do you notice anything? Those little minus and addition
signs are used to denote contravariance and covariance, respectively. And
interestingly enough, it turns out that the CLR has been supporting such CIL
since the introduction of Generics in .NET 2.0. Therefore, it’s possible to
write CIL using covariance and contravariance under .NET 2.0+. Only by now is
it possible to do so using C#.
A final thought about this feature. While this is a good
enhancement to the language, I like the generics covariance/contravariance
implementation, enabled via wildcards, in Java, better for its flexibility.
Anyway, let’s just be happy with it for now, we can’t have everything.
Optional and Named Parameters
The last two features of C# 4.0 that we’ll discuss about
are optional parameters and named parameters. These features have been with
VB.NET since forever, and I’m glad they are finally implemented in C#.
With optional parameters, we can provide default values for
methods’ and constructors’ parameters. That way, we don’t have to write a bunch
of overloaded methods and constructors. For example, we can define a
constructor like this:
public
Cart(
int
id,
String
name = "default
cart",
double
amount = 0d) {…}
Now, you can invoke this constructor with any of these
calls:
new
Cart(
1
);
new
Cart(
1
, "my
cart");
new
Cart(
1
, "my
cart",
105
.
5
);
How exactly does C# implement this feature? If we look at
the CIL generated for this code, we’ll see there’s no magic at all. Basically,
the default values will be injected to the call site so that the method
invocation happens normally. Here’s the CIL generated by the compiler:
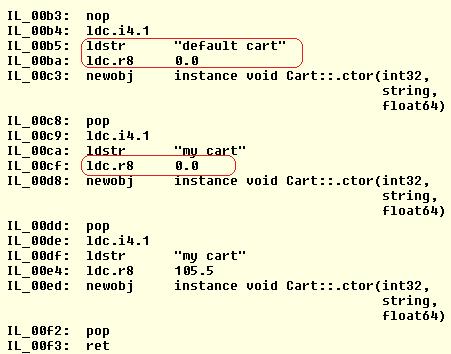
Some might think that the compiler gets the default values
in the source code to inject into the caller’s code. However, that will not
work if a method with optional parameters is published as a library. In that
case, there’s no way the compiler can get the default values to inject to the
code of the library’s client. Therefore, what the compiler actually does is to
encode the default parameters right into the method itself. This is the CIL for
’s constructor:
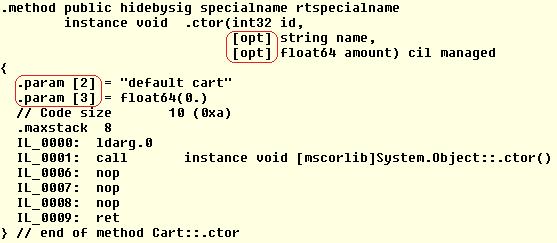
Notice the
directive which basically tells the compiler about the default
values for the optional parameters. These parameters are also annotated by the
attribute.
While being a great feature, there’s a caveat when using
optional parameters: since the compiler inlines the default values at the
caller site, changes to default values at the library site won’t be reflected
unless the caller is recompiled. In order words, you should consider default
values of parameters as part of the published API of a method, and you’d better
make them right the first time.
Now, let’s say we want to call the
’s constructor with the
and
specified but not the
, how would we do that?
To avoid ambiguity (for example, when two optional
parameters are both strings), C# won’t allow us to simply skip a parameter like
this:
new
Cart(
1
,
15
.5d);
// compile-error
An approach C# could take is to allow this syntax:
new
Cart(
1
, ,
15
.5d);
However, this looks terrible enough with just one missing
parameter, much less than with more of them. (How do you like to read this
code:
15
?)
For this particular situation, named parameters is an
excellent solution:
new
Cart(
1
,
amount:
15
.5d);
This is not the only use of named parameters though. A very
important purpose of named parameters is to enhance the readability of code.
Let’s say you have a class having a bunch of fields that are to be initialized
in a constructor. Without named parameters, a constructor of such a class will
look very ugly, and will be hard to understand without resorting to the
documentation, source code, or Intellisense.
One approach is to create a builder to create an instance
of such a class. For example:
new
BigClass.Builder().attr1(“value”).attr2(“value”)...attrN(“value”);
This will make the code more explicit about what values are
to be assigned to what fields. However, the drawback is that we need to
implement a builder class, which is quite a tedious task if we have to repeat
that for many classes in our application.
With C# 3.0, it’s not that bad because we can use an object
initializer to do something like this:
new
BigClass
{Attr1 = “value”, Attr2 = “value”, …, AttrN = “value”}
This looks good, but we have to define all the necessary
properties for it to work, which is also a tedious thing to do if we don’t
really need properties for the class, or if the class itself is immutable.
With named parameters, we have a very nice solution without
having to write any builder or property if we don’t want to. (Note the
semicolon after the field name.)
new
BigClass{attr1: "value", attr2: "value", …, attrN: "value");
// The below does the same thing
new
BigClass{attrN: "value", attr1: "value", …, attr2: "value");
Regarding the implementation of this at the CIL level, the
compiler is smart enough to infer the correct argument order and simply perform
a plain old method invocation.
Conclusion
That’s it. The key features of C# 4.0. I am personally glad
that C# has come to support these. Some people say that C# has become so
complex and has started losing its original beauty. While I can understand that
view, I think the situation is not that bad. While it’s obvious that C# has
more and more constructs to support functional and dynamic programming, the
statically typed nature and the old constructs of the language are still there,
and no developer is forced to use the new features if they don’t need to. On
the other hand, these features bring more options for those who need them, and
I’d rather have more options than to be handcuffed.
Discusses the new features of C# 4.0 including dynamiclookup, covariance/contravariance generics, named and optional paramters
Introduction
The .NET framework4.0 CTP has just been released, and I think it’s a good time to explore the new
features of C# 4.0. In this post, I will introduce about the following
features: dynamic lookup, generics covariance and contravariance support,
optional and named parameters.
Dynamic Lookup
If varinC# 3.0 brings about type inference for local variables with the purpose of
saving a couple of key strokes, dynamic lookup adds much more to the dynamicity
of the C# language. When you declare a variable with dynamic, all of its method
invocations or member accesses will be resolved at runtime. For example, let’s
look at the following code:
public
static
void
Main() {
dynamic obj = "I'm
statically System.String";
obj.NotExistingMethod("param");
}
In the code, we create a string object, and instead of
assigning it to a variable of type
string
, we assign it to a
variable declared as
dynamic
. This basically
instructs the compiler to not attempt to resolve any method call or member
access of the declared variable. Instead, all these resolutions will happen at
runtime. That being done, the next line in which we invoke a non-existing
method with an arbitrary parameter will compile just fine into CIL. At runtime,
when the method call is resolved and the runtime finds that there’s no such
method in the runtime type (which is a
System.
String
), an exception is thrown. That being said, if we use a
valid method, then there would be no exception and the code will run fine till
completion. For example:
private
static
void
PrintID(dynamic obj) {
Console.WriteLine(obj.ID);
}
public
static
void
Main() {
var person =
new
{ID =
111
, Name =
"Buu"
};
PrintID(person);
var account =
new
{ID =
101
, Bank =
"Some Bank"
};
PrintID(account);
}
We basically create two anonymous types, for the sake of
convenience, both having a property called
ID, and then
instantiate objects out of these types. We then pass each of these two objects
to the method
PrintID, which accepts a dynamicobject and prints out the ID property. The code will print out “111” and “101”,
respectively. And yes, we’ve just seen duck typing in action. In C#.
That example also implies an interesting usage of
dynamicwith regard to anonymous types. Now, we can pass
objects of anonymous types out of their declaration scope (e.g., the method)
and still be able to invoke their methods or access their members without
resorting to verbose Reflection code.
We are not just limited to making statically typed .NETobjects become dynamic, we can use this dynamic lookup feature to conveniently
interact with “actual” dynamic objects available through the Dynamic Language
Runtime (DLR) included in .NET framework 4.0. In fact, we can implement such
dynamic objects in C# by implementing the
System.Scripting.Actions.IdynamicObject
interface, which is also part of the DLR. Regardless of the actual
receiver of dynamic dispatch, the usage of dynamic lookup is exactly the same
from the caller’s perspective.
Some of you might wonder what code the compiler generates
and whether there is any change to the CLR to support dynamic lookup or not. To
answer that question, let’s look at the CIL generated from the very first code
fragment of this post. (Click on the image to see the full size.)
The generated CIL is pretty verbose, but a skim through it
reveals two important things. Firstly, our “dynamic variable” turns out to be a
plain old CLR
System.
Object
instance. And secondly, there’s no new CIL directive or opcode to
support dynamic lookup. Instead, dynamic resolution and invocation is
completely handled by framework code. In fact, the above CIL is equivalent to
the following C# code, but now, without the
dynamic
keyword.
object
obj =
"I'm statically
System.String"
;
var payload =
new
CSharpCallPayload(
RuntimeBinder.GetInstance(),
false
,
false
,
"NotExistingMethod"
,
typeof
(
object
),
null
);
var callSite = CallSite<Action<CallSite,
object
, string>>.Create(payLoad);
Action<CallSite,
object
,
string> action = callSite.Target;
action.Invoke(callSite, obj,
"param"
);
(In fact, I simplified the code a bit so that it can fit in
one method. The actual CIL generated does have a check at
IL_000c
, which basically looks at the
callSite
static field of a
nested class, which is generated automatically by the compiler to see if it’s
null
or not before going ahead and initializing it. In order words, the
callSite
is cached for
subsequent invocations of the same method.)
So, there’s really no magic behind the
dynamic
keyword. What the compiler basically does is generate some payload
containing the information about the invocation so that it can be made at
runtime. If there’s any magic at all, it would be in the static method
CallSite.Create()
which uses Reflection to invoke the
NotExistingMethod
on the given object if it’s not an instance of
IDynamicObject
.
Now, we know that a “dynamic object” is actually a plain
old object; it should explain why a method can accept dynamic parameters. It
should also be of no surprise to know that dynamic lookup can also be applied
to the return value of an instance/static method or an instance/static field.
After all, unlike the
var
keyword which requires the compiler to infer the exact type at
compile time, the compiler in dynamic lookup scenarios can simply pick
System.
Object
as the type.
Generics Covariance and Contravariance
In previous versions of C#, generic types are invariant.That is, for any two types
GenericType
<
T
>
and
GenericType
<
K
>
, in which
T
is a subclass of
K
or
K
is a subclass of
T
,
GenericType
<
T
>
and
GenericType
<
K
>
have no inheritance relationship whatsoever to each other. On the
other hand, if
T
is a subclass of
K
and if C# supports
covariance,
GenericType
<
T
>
is also a subclass of
GenericType
<
K
>
, or if C# supports
contravariance,
GenericType
<
T
>
is a superclass of
GenericType
<
K
>
.
To understand why pre-4.0 C# disallows covariance and
contravariance, let’s look at some code:
var strList =
new
List<string>();
List<object> objList = strList;
// compile-error, with cast or
not
The code in line 2 can be error-prone. Consider what we can
write after line 2, assuming it is allowed:
// BOOM: we're adding an arbitrary AnyObject to what,
// at runtime, is a list of strings
objList.add(
new
AnyObject());
On the other hand, if C# supported contravariance, we could
have written the following problematic code:
var objList =
new
List<object>;
objList.add(
3
);
objList.add(
new
AnyObject());
List<string> strList = objList;
// BOOM: we're getting an arbitrary object thinking it’s
a string
string
element =
strList.
get
(
0
);
Due to this invariant restriction, although for the good
purpose, we can’t easily reuse variables and methods to respectively get
assigned to or accept various generic types. It’s somewhat unfortunate because
the key thing to realize is that covariance is fine as long as
GenericType
<
T
>
does not have any
method or member accepting arguments of type
T
(e.g., if we can’t add
a bunch of objects into the
objList
, which is indeed an instance of
List
<
string
>
, we’ll be safe).
Besides, contravariance is just as safe if
T
does not appear in any
return value from a member or method (e.g., if we can’t get any string out from
strList
, which is indeed an instance of
List
<
object
>
, we’ll be safe).
Fortunately, C# 4.0 provides us an option: if a
generic
interface
or
generic
delegate
has a
reference
type
T
as its type parameter
and does not have any method or member that takes in a parameter of type
T
, we can declare it to be covariant on
T
. On the other hand, if that interface or delegate does not have
any method or member that returns
T
, we can declare it to be contravariant on
T
. (Notice the emphases, only interfaces and delegates have
covariance and contravariance support, and the type parameter must be a
reference type. On the other hand, C# arrays have been supporting covariance
from the very beginning.)
Let’s look at an example. We have a
Generator
delegate which
basically returns random instances of objects of a certain type (e.g.,
string
). Its declaration is as follows:
delegate
TGenerator<out T>();
Because this delegate does not take in any
T
as its argument, we
can safely make it covariant on
T
. And indeed, the compiler will allow us to do so by adding
the modifier
out
before the type parameter. However, if this delegate is declared
as, say,
delegate
T Generator<out T>(Tseed)
, then the compiler will complain since it’s no longer safe for
covariance. Now, let’s look at the usage:
Generator<string> strGen =
new
Generator<string>(StringGenerator);
// Below line is compiled now because
Generator<string> is
// subclass of Generator<object> under covariant
rule
Generator<object> objGen = strGen;
// Downcast is also allowed for the same reason
strGen = (Generator<String>)objGen;
...
private
string
StringGenerator(){
return
"I'm a random string"
;
}
With contravariance, you need to use the
in
keyword. Let’s look at an example that makes use of both contravariance
and covariance:
delegate
KConverter<in T,
out
K>(Tparam);
This converter takes an object of type
T
and converts it to an
object of type
K
(e.g., convert
String
to
Object
). Since it does not take in any
K
, it can safely be declared to be covariant on
K
. Similarly, since it exposes no
T
, it can safely be
declared to be contravariant on
T
. Its usage is as follows:
var converter =
new
Converter<object, string>( ConvertImpl);
Converter<string, object> string2ObjectConverter =
converter;
object
result =
string2ObjectConverter(
"A"
);
...
private
string
ConvertImpl(
object
o) {
return
o.ToString();
}
Note that although the above examples show how to declare
covariance and contravariance for delegate types, it’s not different to do so
with interfaces.
Before we finish with covariance and contravariance, let’s
look at what code the compiler generates. After all, we know that the compiler
must encode something to the CIL to denote covariant and/or contravariant
generic types so that they can be consumed properly by client code. And, this
is what the definitions of our
Generator
and
Converter
delegates are when viewed from ILDASM.
Do you notice anything? Those little minus and addition
signs are used to denote contravariance and covariance, respectively. And
interestingly enough, it turns out that the CLR has been supporting such CIL
since the introduction of Generics in .NET 2.0. Therefore, it’s possible to
write CIL using covariance and contravariance under .NET 2.0+. Only by now is
it possible to do so using C#.
A final thought about this feature. While this is a good
enhancement to the language, I like the generics covariance/contravariance
implementation, enabled via wildcards, in Java, better for its flexibility.
Anyway, let’s just be happy with it for now, we can’t have everything.
Optional and Named Parameters
The last two features of C# 4.0 that we’ll discuss aboutare optional parameters and named parameters. These features have been with
VB.NET since forever, and I’m glad they are finally implemented in C#.
With optional parameters, we can provide default values for
methods’ and constructors’ parameters. That way, we don’t have to write a bunch
of overloaded methods and constructors. For example, we can define a
constructor like this:
public
Cart(
int
id,
String
name = "default
cart",
double
amount = 0d) {…}
Now, you can invoke this constructor with any of these
calls:
new
Cart(
1
);
new
Cart(
1
, "my
cart");
new
Cart(
1
, "my
cart",
105
.
5
);
How exactly does C# implement this feature? If we look at
the CIL generated for this code, we’ll see there’s no magic at all. Basically,
the default values will be injected to the call site so that the method
invocation happens normally. Here’s the CIL generated by the compiler:
Some might think that the compiler gets the default values
in the source code to inject into the caller’s code. However, that will not
work if a method with optional parameters is published as a library. In that
case, there’s no way the compiler can get the default values to inject to the
code of the library’s client. Therefore, what the compiler actually does is to
encode the default parameters right into the method itself. This is the CIL for
Cart
’s constructor:
Notice the
.param
directive which basically tells the compiler about the default
values for the optional parameters. These parameters are also annotated by the
[opt]
attribute.
While being a great feature, there’s a caveat when using
optional parameters: since the compiler inlines the default values at the
caller site, changes to default values at the library site won’t be reflected
unless the caller is recompiled. In order words, you should consider default
values of parameters as part of the published API of a method, and you’d better
make them right the first time.
Now, let’s say we want to call the
Cart
’s constructor with the
ID
and
amount
specified but not the
name
, how would we do that?
To avoid ambiguity (for example, when two optional
parameters are both strings), C# won’t allow us to simply skip a parameter like
this:
new
Cart(
1
,
15
.5d);
// compile-error
An approach C# could take is to allow this syntax:
new
Cart(
1
, ,
15
.5d);
However, this looks terrible enough with just one missing
parameter, much less than with more of them. (How do you like to read this
code:
MethodWithManyFields(,,,
15
,,"param",,)
?)
For this particular situation, named parameters is an
excellent solution:
new
Cart(
1
,
amount:
15
.5d);
This is not the only use of named parameters though. A very
important purpose of named parameters is to enhance the readability of code.
Let’s say you have a class having a bunch of fields that are to be initialized
in a constructor. Without named parameters, a constructor of such a class will
look very ugly, and will be hard to understand without resorting to the
documentation, source code, or Intellisense.
One approach is to create a builder to create an instance
of such a class. For example:
new
BigClass.Builder().attr1(“value”).attr2(“value”)...attrN(“value”);
This will make the code more explicit about what values are
to be assigned to what fields. However, the drawback is that we need to
implement a builder class, which is quite a tedious task if we have to repeat
that for many classes in our application.
With C# 3.0, it’s not that bad because we can use an object
initializer to do something like this:
new
BigClass
{Attr1 = “value”, Attr2 = “value”, …, AttrN = “value”}
This looks good, but we have to define all the necessary
properties for it to work, which is also a tedious thing to do if we don’t
really need properties for the class, or if the class itself is immutable.
With named parameters, we have a very nice solution without
having to write any builder or property if we don’t want to. (Note the
semicolon after the field name.)
new
BigClass{attr1: "value", attr2: "value", …, attrN: "value");
// The below does the same thing
new
BigClass{attrN: "value", attr1: "value", …, attr2: "value");
Regarding the implementation of this at the CIL level, the
compiler is smart enough to infer the correct argument order and simply perform
a plain old method invocation.
Conclusion
That’s it. The key features of C# 4.0. I am personally gladthat C# has come to support these. Some people say that C# has become so
complex and has started losing its original beauty. While I can understand that
view, I think the situation is not that bad. While it’s obvious that C# has
more and more constructs to support functional and dynamic programming, the
statically typed nature and the old constructs of the language are still there,
and no developer is forced to use the new features if they don’t need to. On
the other hand, these features bring more options for those who need them, and
I’d rather have more options than to be handcuffed.

相关文章推荐
- An overview of gradient descent optimization algorithms
- Concept Of Optional Parameter in C# 4.0
- An overview of LTE & LTE-A PHY layer
- An Overview of File System Architectures
- 【论文阅读笔记】Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique
- An overview of gradient descent optimization algorithm
- An Overview of Complex Event Processing
- An overview of Android
- EF 6.0 The conversion of a datetime2 data type to a datetime data type resulted in an out-of-range value. c#中的时间
- C# Convert an enum to other type of enum
- An overview of Stagefright player
- An overview of Stagefright player
- Calculate the Factorial of an Integer in C# 转
- An Overview of Team Foundation Build
- Philosophies Of Arguments Feature in C# 4.0
- chapter 25 An Overview of the C API
- An Overview of Cisco IOS Versions and Naming
- An Overview of Authentication Mechanisms on Windows
- An Overview of Tomcat 6 Servlet Container : Part 1
- Framework Fundamentals(Chapter 6 of C# 4.0 in a nutshell)