OCP认证考试指南(15):监视Oracle
2010-05-19 15:50
549 查看
1、自动工作负荷仓库
Oracle收集了大量与性能和动作相关的统计信息。这些信息在内存中累加,并且有规律地写入磁盘(也就是写入构成AWR的表)。最终,这些信息会过期并被重写。
1.1、收集统计量
统计量收集的级别由实例参数STATISTICS_LEVEL控制。这个参数可能被设置为BASIC、TYPICAL或ALL。(默认TYPICAL)
TYPICAL:允许收集正常调整所需的所有统计量,同时不会收集对性能有不良影响的统计量集合。
BASIC:事实上禁止收集统计量,并且不存在可评估的性能优势。
ALL:收集与SQL执行相关的、极其详细的统计量。进行高级的SQL语句调整,就可以使用ALL级别,不过在收集统计量时会导致性能稍有退化。
统计量在内存中(SGA内的数据结构中)累积。统计量只反映实例所作的动作,所以并不影响实例的性能。统计量被定时(默认每小时一次)写入磁盘,也就是写入AWR。这被称为一次“快照(snapshot)”。统计量被写入磁盘的操作由后台进程(可管理的监视器或MMON进程)完成。
MMON进程直接访问构成SGA的内存结构,从而也可以访问这些内存结构中的统计量。这个进程可以在不需要通过会话的情况下从SGA内抽取数据。此时唯一的系统开销是将数据实际写入AWR。在默认情况下,这个操作每小时执行一次,因此应当不会对运行时性能产生明显的影响。
1.2、AWR的大小与位置
AWR是位于SYSAUX表空间内的一组表。这些表不能被重新定位,并且存在于SYSMAN模式中。虽然我们可以作为用户SYSMAN登录数据库,但是无法查看AWR。访问AWR最简单的方式是Database Control。
快照默认在AWR中保存7天,这个时间周期是可配置的。作为一条用于分配存储空间大小的大致原则,如果每小时进行一次快照收集并且快照保留时间为7天,那么AWR在SYSAUX表空间内可能需要200~300的空间。不过,这个数据总是会变化,根据会话数会被大幅提高。
1.3、快照的保存
快照会在特定时间周期后被清除,在默认情况下,这个时间周期为7天。为了进行长期的调整,就必须在更长的时间周期内保存快照。在默认情况下,AWR快照保存7天,ADDM报告保存30天。
2、诊断与调整顾问程序
7个顾问程序:
Automatic Database Diagnostic Monitor(数据库自动诊断监视程序,简写为ADDM)
SQL Tuning Advisor(SQL调整顾问程序)
SQL Access Advisor(SQL访问顾问程序)
Memory Advisor(内存顾问程序)
Mean Time to Recover(MTTR)Advisor(平均恢复时间顾问程序)
Segment Advisor(段顾问程序)
Undo Advisor(撤销顾问程序)
2.1、ADDM顾问程序
只要生成快照,MMON进程就会自动运行ADDM。
查看报告
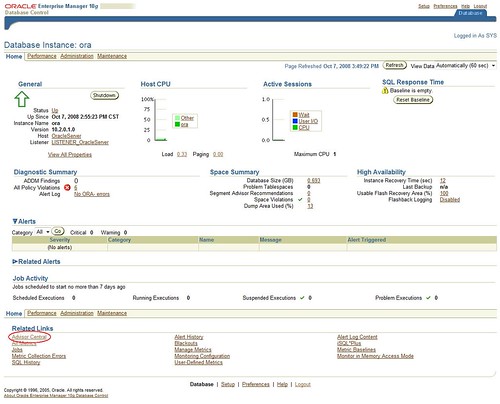
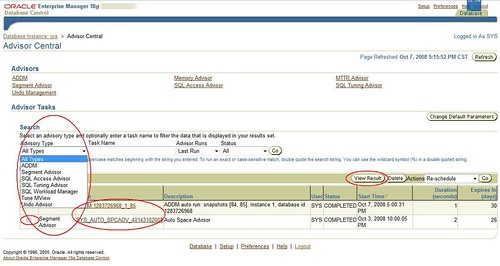
这里会显示所有顾问程序的最近运行情况。
2.2、SQL Tuning Advisor与SQL Access Advisor
SQL Tuning Advisor将一条或多条SQL语句作为输入,并且研究这些语句的结构与执行方式。这些SQL语句被称为SQL Tuning Set,这个顾问程序涉及下列内容:
收集所涉及对象的优化器统计量
使用与语句执行相关的统计量生成SQL配置文件
修改代码,从而更有效地使用SQL构造
重写代码,从而去除可能的设计错误
SQL Access Advisor也将SQL Tuning Set作为其输入。这个顾问程序研究通过添加索引或物化视图是否能够改善SQL执行性能,此外还研究某些索引与物化视图实际上是否会妨碍改善性能以及是否应当被删除。
2.3、Memory Advisor
内存顾问程序通常能实现:如果为SGA结构或PGA分配更多的内存,那么性能会得到进一步改善,不过效益会递减。如果可能因为交换系统而需要减少内存的使用,那么就能够节约内存。但是,如果节省的内存过多,那么性能将会退化。
2.4、 MTTR Advisor
某个实例在崩溃之后必须被恢复,因此可能耗费相当长的时间,这个时间就是平均恢复时间(Mean Time to Recover,简写为MTTR)。
以秒为单位进行设置的实例参数FAST_START_RECOVERY_TARGET能够控制MTTR。这个参数设置的时间越短,在实例崩溃后就越能更快地打开数据库,不过联机性能会更差。
2.5、Segment Advisor
Segment Advisor会查看段,并且能够确定为未被使用的段所分配的空间大小是否足够用于执行SHRINK SPACE操作。
2.6、Undo Advisor
所有DML命令都会生成撤销数据。撤销数据的保留时间至少是事务的时间长度,通常需要事务结束后相当长的时间内仍然存储撤销数据。
决定撤销表空间大小的算法基于下列方面:每秒钟生成撤销的速度,存储满足查询运行时间最长需求的数据的秒数,并且可能使用闪回查询。
3、服务器生成的告警
3.1、告警系统体系结构
10G版本的Oracle数据库能够监视自身。MMON后台进程是一个易管理的监视器,该进程可以观察实例与数据库。如果某种指标过于偏离期望值,那么MMON进程就会生成一个告警。MMON进程生成的所有告警都被置入SYS模式中的队列ALERT_QUE。
告警有两种形式:阈值(有状态的)或无阈值(无状态的)。配置阈值告警时,必须设置某些要监视的指示值(例如表空间中所用空间的百分比)。当越过阈值时,就会引发一个告警,并且这个告警在采用使指标值低于触发值的某些动作(例如为表空间添加更多的空间)之前会一直持续。无阈值告警由某个发生后并不持久的事件触发,例如一个“ORA-1555:snapshot too old”错误。
3.2、设置阈值
某些告警被预配置了阈值,其他告警则必须在启用之前进行设置。例如,对于“Tablespace percent full”告警来说,默认是在85%的表空间被填满时发送一个警告告警以及在97%的表空间被填满时发送一个临界告警。但是,“Average File Read Time”告警没有默认的配置。
3.3、使用基线
在不比较指标值与手动选定值的情况下,允许Oracle在性能上可接受的性能产生偏差时引发告警,这样可以不必计算出准确的阈值。为了完成上述操作,需要创建一个“基线”。
Oracle收集了大量与性能和动作相关的统计信息。这些信息在内存中累加,并且有规律地写入磁盘(也就是写入构成AWR的表)。最终,这些信息会过期并被重写。
1.1、收集统计量
统计量收集的级别由实例参数STATISTICS_LEVEL控制。这个参数可能被设置为BASIC、TYPICAL或ALL。(默认TYPICAL)
TYPICAL:允许收集正常调整所需的所有统计量,同时不会收集对性能有不良影响的统计量集合。
BASIC:事实上禁止收集统计量,并且不存在可评估的性能优势。
ALL:收集与SQL执行相关的、极其详细的统计量。进行高级的SQL语句调整,就可以使用ALL级别,不过在收集统计量时会导致性能稍有退化。
统计量在内存中(SGA内的数据结构中)累积。统计量只反映实例所作的动作,所以并不影响实例的性能。统计量被定时(默认每小时一次)写入磁盘,也就是写入AWR。这被称为一次“快照(snapshot)”。统计量被写入磁盘的操作由后台进程(可管理的监视器或MMON进程)完成。
MMON进程直接访问构成SGA的内存结构,从而也可以访问这些内存结构中的统计量。这个进程可以在不需要通过会话的情况下从SGA内抽取数据。此时唯一的系统开销是将数据实际写入AWR。在默认情况下,这个操作每小时执行一次,因此应当不会对运行时性能产生明显的影响。
1.2、AWR的大小与位置
AWR是位于SYSAUX表空间内的一组表。这些表不能被重新定位,并且存在于SYSMAN模式中。虽然我们可以作为用户SYSMAN登录数据库,但是无法查看AWR。访问AWR最简单的方式是Database Control。
快照默认在AWR中保存7天,这个时间周期是可配置的。作为一条用于分配存储空间大小的大致原则,如果每小时进行一次快照收集并且快照保留时间为7天,那么AWR在SYSAUX表空间内可能需要200~300的空间。不过,这个数据总是会变化,根据会话数会被大幅提高。
1.3、快照的保存
快照会在特定时间周期后被清除,在默认情况下,这个时间周期为7天。为了进行长期的调整,就必须在更长的时间周期内保存快照。在默认情况下,AWR快照保存7天,ADDM报告保存30天。
2、诊断与调整顾问程序
7个顾问程序:
Automatic Database Diagnostic Monitor(数据库自动诊断监视程序,简写为ADDM)
SQL Tuning Advisor(SQL调整顾问程序)
SQL Access Advisor(SQL访问顾问程序)
Memory Advisor(内存顾问程序)
Mean Time to Recover(MTTR)Advisor(平均恢复时间顾问程序)
Segment Advisor(段顾问程序)
Undo Advisor(撤销顾问程序)
2.1、ADDM顾问程序
只要生成快照,MMON进程就会自动运行ADDM。
查看报告
这里会显示所有顾问程序的最近运行情况。
2.2、SQL Tuning Advisor与SQL Access Advisor
SQL Tuning Advisor将一条或多条SQL语句作为输入,并且研究这些语句的结构与执行方式。这些SQL语句被称为SQL Tuning Set,这个顾问程序涉及下列内容:
收集所涉及对象的优化器统计量
使用与语句执行相关的统计量生成SQL配置文件
修改代码,从而更有效地使用SQL构造
重写代码,从而去除可能的设计错误
SQL Access Advisor也将SQL Tuning Set作为其输入。这个顾问程序研究通过添加索引或物化视图是否能够改善SQL执行性能,此外还研究某些索引与物化视图实际上是否会妨碍改善性能以及是否应当被删除。
2.3、Memory Advisor
内存顾问程序通常能实现:如果为SGA结构或PGA分配更多的内存,那么性能会得到进一步改善,不过效益会递减。如果可能因为交换系统而需要减少内存的使用,那么就能够节约内存。但是,如果节省的内存过多,那么性能将会退化。
2.4、 MTTR Advisor
某个实例在崩溃之后必须被恢复,因此可能耗费相当长的时间,这个时间就是平均恢复时间(Mean Time to Recover,简写为MTTR)。
以秒为单位进行设置的实例参数FAST_START_RECOVERY_TARGET能够控制MTTR。这个参数设置的时间越短,在实例崩溃后就越能更快地打开数据库,不过联机性能会更差。
2.5、Segment Advisor
Segment Advisor会查看段,并且能够确定为未被使用的段所分配的空间大小是否足够用于执行SHRINK SPACE操作。
2.6、Undo Advisor
所有DML命令都会生成撤销数据。撤销数据的保留时间至少是事务的时间长度,通常需要事务结束后相当长的时间内仍然存储撤销数据。
决定撤销表空间大小的算法基于下列方面:每秒钟生成撤销的速度,存储满足查询运行时间最长需求的数据的秒数,并且可能使用闪回查询。
3、服务器生成的告警
3.1、告警系统体系结构
10G版本的Oracle数据库能够监视自身。MMON后台进程是一个易管理的监视器,该进程可以观察实例与数据库。如果某种指标过于偏离期望值,那么MMON进程就会生成一个告警。MMON进程生成的所有告警都被置入SYS模式中的队列ALERT_QUE。
告警有两种形式:阈值(有状态的)或无阈值(无状态的)。配置阈值告警时,必须设置某些要监视的指示值(例如表空间中所用空间的百分比)。当越过阈值时,就会引发一个告警,并且这个告警在采用使指标值低于触发值的某些动作(例如为表空间添加更多的空间)之前会一直持续。无阈值告警由某个发生后并不持久的事件触发,例如一个“ORA-1555:snapshot too old”错误。
3.2、设置阈值
某些告警被预配置了阈值,其他告警则必须在启用之前进行设置。例如,对于“Tablespace percent full”告警来说,默认是在85%的表空间被填满时发送一个警告告警以及在97%的表空间被填满时发送一个临界告警。但是,“Average File Read Time”告警没有默认的配置。
3.3、使用基线
在不比较指标值与手动选定值的情况下,允许Oracle在性能上可接受的性能产生偏差时引发告警,这样可以不必计算出准确的阈值。为了完成上述操作,需要创建一个“基线”。

相关文章推荐
- OCP认证考试指南(5):管理Oracle进程
- OCP认证考试指南(12):配置Oracle互联
- Oracle之监视和解决锁定冲突(认证考试指南)
- OCP认证考试指南(1):Oracle的基本概念
- OCP认证考试指南(6):管理Oracle存储结构
- 【OCP认证考试指南】oracle 10G 安装
- OCP认证考试指南(10):使用PL/SQL进行Oracle编程
- OCP认证考试指南(3):创建Oracle数据库(3)
- OCP认证考试指南(8):管理数据库对象
- Oracle OCP认证考试题库解析052-8
- 分享一下大家关心的Oracle OCP认证考试流程
- OCP认证考试指南(4):接合Oracle数据库
- OCP认证考试指南(9):操纵数据库数据(2)
- OCP认证考试指南(11):保护Oracle数据库的安全(1)
- OCP认证考试指南(21):管理Oracle数据库中的全球化特性
- Oracle之子查询(认证考试指南)
- Oracle之专有名词(认证考试指南)
- Oracle之条件函数(DECODE函数/COALESCE函数/NVL函数)(认证考试指南全册)
- Oracle OCP认证考试题库解析052-1
- oracle 认证考试信息 ocp