Hubble.net 搜索引擎分析三
2010-04-05 09:15
141 查看
3. Hubble.Net建立索引
通过前面的分析,我们知道一条记录(datarow)就是一个文档。所以实质是对datarow进行索引。我们根据Table类知道一条datarow有几个索引列,并通过其列名就可以后去对应的倒排索引对象,再使用倒排索引对象索引其对应值。对应的模型图如下:
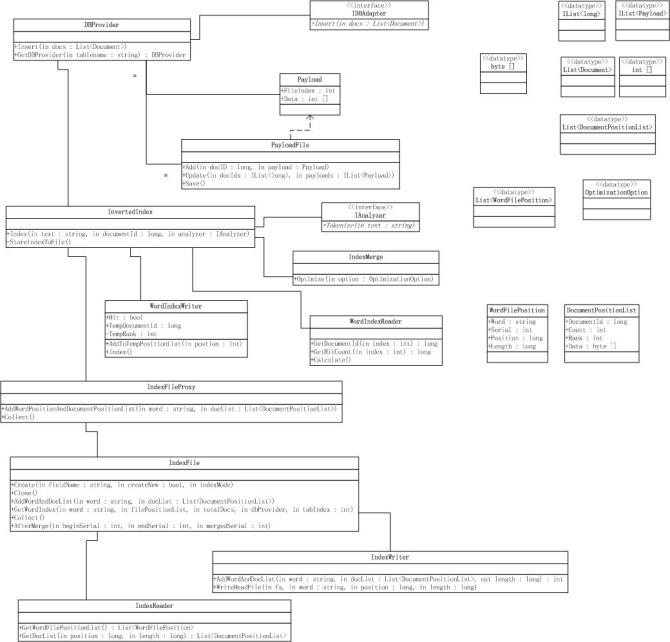
1.一个数据表对应一个DBProvider对象,需要对某个表建立索引时,只需要通过其表名称获取对应的DBProvider对象就可.调用DBProvider. GetDBProvider(tablename) 静态方法。
2.把DataRows转换成List<Document>,在调用DBProvider对象的Insert方法。
3. Insert方法内,首先调用IDBAdapter.Insert(docs); 插入文档到数据库中。其次创建索引信息,根据文档的数据列类型,获取对应的倒排索引(InvertedIndex)对象。调用倒排索引对象的Index方法,并传入对应列值,文档ID,IAnalyzer对象。根据各列索引返回值(fieldvalue分词个数),组成Payload对象,以便调用PayloadFile.Save()方法存储。注数据列类型为Untokenized,直接把其值转换为int[] 数组。
4. 倒排索引(InvertedIndex)对象Index方法内部:首先调用IAnalyzer.Tokenize(text)分词,其次根据词语获取对应的WordIndexWriter对象,如果不存在就新建一个并记录到索引词列表,初始化WordIndexWriter对象的临时文档ID,TempRank值,本词语在文档中的位置(wordIndex.AddToTempPositionList(wordInfo.Position))。最后根据缓存文档个数,判断是否调用存储索引文件方法(StoreIndexToFile())。
5. StoreIndexToFile方法内部,循环获取需要保存的索引信息,并调用索引文件代理类IndexFileProxy的AddWordPositionAndDocumentPositionList(wordIndex.Word, docList)方法保存索引信息。最后调用IndexFileProxy对象的Collect()方法重新初始化一对新的索引文件(.hdx和.idx)以便下次索引信息存放。
6. IndexFileProxy对戏的AddWordPositionAndDocumentPositionList()内部,首先调用索引类IndexFile.AddWordAndDocList(wl.Word, wl.DocList);记录索引词对应的索引信息。最后把刚存储的索引文件信息记录到内存,以便查询使用。
注:IndexFileProxy类是IndexFile类的代理类,这儿使用了代理(Proxy)设计模式,简单的说就是调用IndexFileProxy对象的方法,间接的是调用IndexFile对象的对应方法。我想最终分布式索引也依赖于此吧。
7. IndexFile.AddWordAndDocList方法内,首先调用_IndexWriter.AddWordAndDocList(word, docList, out length);把索引词在文档中的索引信息写入到.idx和.hdx文件中,并返回在.idx文件中的位置和长度,以便记录在内存中。
8. IndexWriter.AddWordAndDocList方法内,首先循环DocumentPositionList in docList写入.idx中,每项之间用0隔开,最后在把其开始位置和长度写入到.hdx中。
至此创建索引完成。注:对象模型图,中的对象方法等,不是全部。因为本章写的是创建索引,所以只画出了与创建有关的
通过前面的分析,我们知道一条记录(datarow)就是一个文档。所以实质是对datarow进行索引。我们根据Table类知道一条datarow有几个索引列,并通过其列名就可以后去对应的倒排索引对象,再使用倒排索引对象索引其对应值。对应的模型图如下:
1.一个数据表对应一个DBProvider对象,需要对某个表建立索引时,只需要通过其表名称获取对应的DBProvider对象就可.调用DBProvider. GetDBProvider(tablename) 静态方法。
2.把DataRows转换成List<Document>,在调用DBProvider对象的Insert方法。
3. Insert方法内,首先调用IDBAdapter.Insert(docs); 插入文档到数据库中。其次创建索引信息,根据文档的数据列类型,获取对应的倒排索引(InvertedIndex)对象。调用倒排索引对象的Index方法,并传入对应列值,文档ID,IAnalyzer对象。根据各列索引返回值(fieldvalue分词个数),组成Payload对象,以便调用PayloadFile.Save()方法存储。注数据列类型为Untokenized,直接把其值转换为int[] 数组。
4. 倒排索引(InvertedIndex)对象Index方法内部:首先调用IAnalyzer.Tokenize(text)分词,其次根据词语获取对应的WordIndexWriter对象,如果不存在就新建一个并记录到索引词列表,初始化WordIndexWriter对象的临时文档ID,TempRank值,本词语在文档中的位置(wordIndex.AddToTempPositionList(wordInfo.Position))。最后根据缓存文档个数,判断是否调用存储索引文件方法(StoreIndexToFile())。
5. StoreIndexToFile方法内部,循环获取需要保存的索引信息,并调用索引文件代理类IndexFileProxy的AddWordPositionAndDocumentPositionList(wordIndex.Word, docList)方法保存索引信息。最后调用IndexFileProxy对象的Collect()方法重新初始化一对新的索引文件(.hdx和.idx)以便下次索引信息存放。
6. IndexFileProxy对戏的AddWordPositionAndDocumentPositionList()内部,首先调用索引类IndexFile.AddWordAndDocList(wl.Word, wl.DocList);记录索引词对应的索引信息。最后把刚存储的索引文件信息记录到内存,以便查询使用。
注:IndexFileProxy类是IndexFile类的代理类,这儿使用了代理(Proxy)设计模式,简单的说就是调用IndexFileProxy对象的方法,间接的是调用IndexFile对象的对应方法。我想最终分布式索引也依赖于此吧。
7. IndexFile.AddWordAndDocList方法内,首先调用_IndexWriter.AddWordAndDocList(word, docList, out length);把索引词在文档中的索引信息写入到.idx和.hdx文件中,并返回在.idx文件中的位置和长度,以便记录在内存中。
8. IndexWriter.AddWordAndDocList方法内,首先循环DocumentPositionList in docList写入.idx中,每项之间用0隔开,最后在把其开始位置和长度写入到.hdx中。
至此创建索引完成。注:对象模型图,中的对象方法等,不是全部。因为本章写的是创建索引,所以只画出了与创建有关的

相关文章推荐
- Hubble.Net 搜索引擎分析一
- Hubble.net 搜索引擎分析二
- Hubble.net 搜索引擎分析四
- HubbleDotNet+Mongodb 构建高性能搜索引擎
- (转)HubbleDotNet+Mongodb 构建高性能搜索引擎--概述
- HubbleDotNet+Mongodb 构建高性能搜索引擎--概述
- HubbleDotNet+Mongodb 构建高性能搜索引擎--概述
- HubbleDotNet搜索引擎+盘古分词在站内搜索中的应用实战
- 上周技术关注:ASP.NET 2.0运行时简要分析
- 网页去重:搜索引擎重复网页发现技术分析(转载)
- ASP.net 中的Static/ Application /Session/ Cookie /ViewState /Cache /Hidden 概要分析
- net_device 结构分析
- 简要分析VB6.0和VB.NET区别
- ASP.NET缓存方法分析和实践示例代码第1/2页
- HubbleDotNet 开源全文搜索数据库项目--数据表的数据类型和索引类型
- Project Silk – Mileage Stats 项目架构初步分析(ASP.NET MVC 3) [转]
- Nutch搜索引擎分析
- ADO.net连接数据库步骤及分析
- ADO.net,Linq to SQL和Entity Framework性能实测分析(转)
- Asp.net MVC 示例项目"Suteki.Shop"分析之---安装篇(转)