渲染管线
2010-03-29 14:53
183 查看
渲染管线也称为渲染流水线,是显示芯片内部处理图形信号相互独立的的并行处理单元。在某种程度上可以把渲染管线比喻为工厂里面常见的各种生产流水线,工厂里的生产流水线是为了提高产品的生产能力和效率,而渲染管线则是提高显卡的工作能力和效率。
渲染管线的数量一般是以 像素渲染流水线的数量×每管线的纹理单元数量 来表示。例如,GeForce 6800Ultra的渲染管线是16×1,就表示其具有16条像素渲染流水线,每管线具有1个纹理单元;GeForce4 MX440的渲染管线是2×2,就表示其具有2条像素渲染流水线,每管线具有2个纹理单元等等,其余表示方式以此类推。
渲染管线的数量是决定显示芯片性能和档次的最重要的参数之一,在相同的显卡核心频率下,更多的渲染管线也就意味着更大的像素填充率和纹理填充率,从显卡的渲染管线数量上可以大致判断出显卡的性能高低档次。但显卡性能并不仅仅只是取决于渲染管线的数量,同时还取决于显示核心架构、渲染管线的的执行效率、顶点着色单元的数量以及显卡的核心频率和显存频率等等方面。一般来说在相同的显示核心架构下,渲染管线越多也就意味着性能越高,例如16×1架构的GeForce 6800GT其性能要强于12×1架构的GeForce 6800,就象工厂里的采用相同技术的2条生产流水线的生产能力和效率要强于1条生产流水线那样;而在不同的显示核心架构下,渲染管线的数量多就并不意味着性能更好,例如4×2架构的GeForce2 GTS其性能就不如2×2架构的GeForce4 MX440,就象工厂里的采用了先进技术的1条流水线的生产能力和效率反而还要强于只采用了老技术的2条生产流水线那样。
-------------------
D3D10 可编程渲染管道是为实时应用设计的。它被分成7个阶段,其中3个阶段是可编程的。数据流图如下:
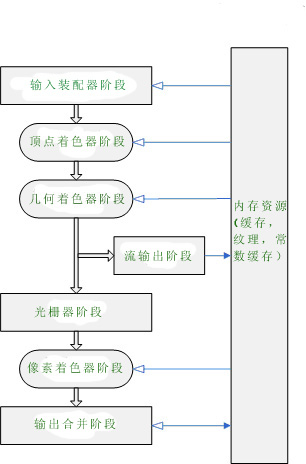
所有阶段都可以通过D3D10API进行配置。三个可编程阶段都建立在通用着色器内核(common shader core)之上,都使用HLSL编写。各部分功能简述如下:
1 . 输入装配器阶段(IA)
为管线提供数据(三角面,线或点)
2 . 顶点着色器阶段(VS)
输入一个顶点,执行坐标变换、蒙皮(Skinning)和光照计算,输出一个顶点。
3. 几何着色器阶段(GS)
处理整个图元(对于三角形是三个顶点,对于线是两个顶点,对于点是一个顶点),还包括相邻图元的顶点数据(对于三角形有三个相邻三角形,即额外的三个顶点,对于线则有额外两个顶点)。支持有限的几何放大和缩小。输入一个图元,GS可能丢弃该图元或输出一个至多个图元。
4. 流输出阶段(SO)
在图元数据传输到光栅器的过程中,将图元数据从管线中输出至内存。可以将图元数据同时输出至光栅器和内存,或者只输出到内存。输出到内存的数据可以作为输入返回到管线,也可以被CPU访问。
5. 光栅器阶段(RS)
光栅器执行裁剪,为PS准备数据,并决定如何调用PS。
6. 象素着色器阶段(PS)
接收经RS插值过的数据,计算逐顶点的数据
7. 输出合并阶段(OM)
将输出数据(PS输出值,深度及模板数据)与渲染目标和深度模板缓存中的数据进行合并来生成最终的管线结果。
渲染管线的数量一般是以 像素渲染流水线的数量×每管线的纹理单元数量 来表示。例如,GeForce 6800Ultra的渲染管线是16×1,就表示其具有16条像素渲染流水线,每管线具有1个纹理单元;GeForce4 MX440的渲染管线是2×2,就表示其具有2条像素渲染流水线,每管线具有2个纹理单元等等,其余表示方式以此类推。
渲染管线的数量是决定显示芯片性能和档次的最重要的参数之一,在相同的显卡核心频率下,更多的渲染管线也就意味着更大的像素填充率和纹理填充率,从显卡的渲染管线数量上可以大致判断出显卡的性能高低档次。但显卡性能并不仅仅只是取决于渲染管线的数量,同时还取决于显示核心架构、渲染管线的的执行效率、顶点着色单元的数量以及显卡的核心频率和显存频率等等方面。一般来说在相同的显示核心架构下,渲染管线越多也就意味着性能越高,例如16×1架构的GeForce 6800GT其性能要强于12×1架构的GeForce 6800,就象工厂里的采用相同技术的2条生产流水线的生产能力和效率要强于1条生产流水线那样;而在不同的显示核心架构下,渲染管线的数量多就并不意味着性能更好,例如4×2架构的GeForce2 GTS其性能就不如2×2架构的GeForce4 MX440,就象工厂里的采用了先进技术的1条流水线的生产能力和效率反而还要强于只采用了老技术的2条生产流水线那样。
-------------------
D3D10 可编程渲染管道是为实时应用设计的。它被分成7个阶段,其中3个阶段是可编程的。数据流图如下:
所有阶段都可以通过D3D10API进行配置。三个可编程阶段都建立在通用着色器内核(common shader core)之上,都使用HLSL编写。各部分功能简述如下:
1 . 输入装配器阶段(IA)
为管线提供数据(三角面,线或点)
2 . 顶点着色器阶段(VS)
输入一个顶点,执行坐标变换、蒙皮(Skinning)和光照计算,输出一个顶点。
3. 几何着色器阶段(GS)
处理整个图元(对于三角形是三个顶点,对于线是两个顶点,对于点是一个顶点),还包括相邻图元的顶点数据(对于三角形有三个相邻三角形,即额外的三个顶点,对于线则有额外两个顶点)。支持有限的几何放大和缩小。输入一个图元,GS可能丢弃该图元或输出一个至多个图元。
4. 流输出阶段(SO)
在图元数据传输到光栅器的过程中,将图元数据从管线中输出至内存。可以将图元数据同时输出至光栅器和内存,或者只输出到内存。输出到内存的数据可以作为输入返回到管线,也可以被CPU访问。
5. 光栅器阶段(RS)
光栅器执行裁剪,为PS准备数据,并决定如何调用PS。
6. 象素着色器阶段(PS)
接收经RS插值过的数据,计算逐顶点的数据
7. 输出合并阶段(OM)
将输出数据(PS输出值,深度及模板数据)与渲染目标和深度模板缓存中的数据进行合并来生成最终的管线结果。

相关文章推荐
- 传统渲染管线与可编程Shader着色器
- 渲染管线
- OpenGL—渲染管线
- OpenGL-渲染管线的流程(有图有真相)
- OpenGL系列教程之三:OpenGL渲染管线
- [OpenGL ES 02]OpenGL ES渲染管线与着色器
- 固定渲染管线与可编程渲染管线
- 渲染流水管线
- OpenGL渲染管线
- Direct 3D绘制流水线(渲染管线)
- 实时渲染(一)——图形渲染管线
- OpenGL渲染管线
- GPU渲染管线与可编程着色器
- 红宝书阅读笔记——OPENGL渲染管线
- 三维图形渲染管线
- 渲染管线
- 将Shader嵌入Ogre(固定渲染管线到可编程渲染管线)
- GPU概念以及D3D渲染流水线(管线)
- Doom3 引擎渲染管线分析
- VTK学习(十三)图形渲染管线