实战开发经验: 软件中的缓冲区管理
2010-02-01 21:19
323 查看
1. 前言
什么是缓冲区管理策略?为什么要使用缓冲区管理策略,这里首先引用几段《生产者/消费者模式》中的文字作为引子吧。在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的“模块”是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者 。
单单抽象出生产者和消费者,还够不上是生产者/消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。大概的结构如下图:
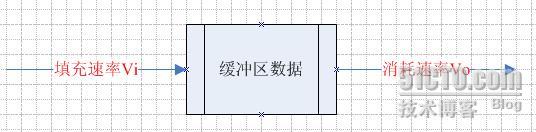
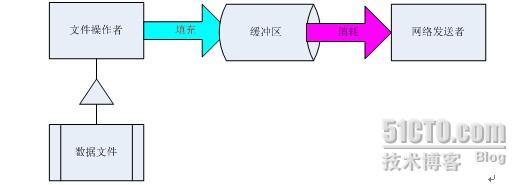
这种模式最典型的应用就是网络数据的传送,对应的生产者为文件操作者,只负责读取数据文件填充到缓冲区中,对应的消费者为网络发送者,只管从缓冲区中取出数据,发送到对应的接收端,大概结构如下:
这样做有什么好处呢?
(1) 解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
(2)支持并发
生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者就会白白糟蹋大好时光。
使用了生产者/消费者模式之后,生产者和消费者可以是两个独立的并发主体。生产者把制造出来的数据往缓冲区一丢,就可以再去生产下一个数据。基本上不用依赖消费者的处理速度。
(3)支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
当然,还有很多其他的好处,这里就不一一列举了。下面进行本文讨论的重点,即怎么样实现和管理这样一个缓冲区呢?怎样才能很好的保证缓冲区容量的平衡,不至于溢出也不会经常性为空?
2. 什么是缓冲区管理策略
典型的缓冲区如下图: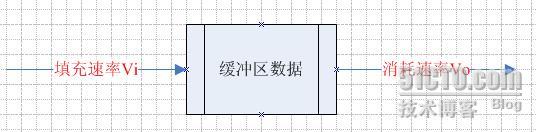
If(Vi > Vo)则一定时间后,缓冲区肯定会溢出(如果你说将缓冲区设得足够大就没问题,但那样会占用太多系统资源,并不可取);同理,If(Vi < Vo),则一定时间后,缓冲区肯定会为空,导致数据消耗者得不到数据。而且在实际的应用中,Vi和Vo也不是定值,也常常会动态的变化(例如:假设消费者是网络发送者,在网络状况比较差的情况时,它消耗缓冲区的速率可能就小于我们设定的Vo),故我们是无法通过实现Vi = Vo这种方式来保证缓冲区的平衡,那么,怎样保证消费者每次都能取到数据、生产者填充数据不会导致溢出呢?
这里,我们需要的就不仅仅是一个简简单单静态的缓冲区,而是一个缓冲区管理者,由该缓冲区使用一定的策略管理该缓冲区,以避免上述情况的发生。
3. 怎么样实现缓冲区管理策略
如上所述,我们不能保证Vi准确地等于Vo,那么我们可以换一个思路,假设缓冲区满记为100%,缓冲区空记为0%,那么我们其实可以通过保证缓冲区的数据容量在50%左右这样一个指标来实现缓冲区不为空又不至于溢出这样一个梦想,如下图所示: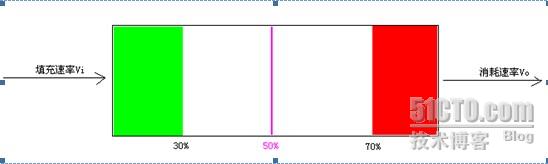
我们称当前缓冲区填充的数据量百分比为“水位”,设计两个门限值,当水位低于30%时,我们称为“低水位”状态,当水位高于70%时,我们称为“高水位”状态。我们的目标是使缓冲区中的水位保持在30%到70%之间,一旦到达“低水位”或者“高水位”状态,则启用“水位管理”,通知生产者加快或者减慢生产速率,或者通知消费者减慢或者加快消费速率,以便达到维持缓冲区平衡的目的。
“水位管理”方案
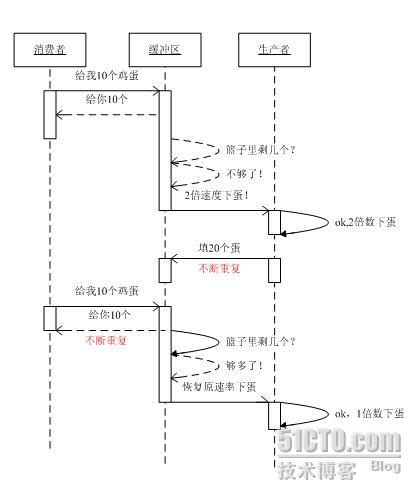
(1)缓冲区刚开始为空时,由于处于“低水位”状态,故采用的是“低水位门限控制方案”,即若消费者消耗速率为Vo,生产者则以速率Vo的n倍(例如2倍)填充缓冲区,直到水位到达50%时,再回到消费的速率Vo来填充缓冲区。
(2)缓冲区由于填充速率过低,或者消耗速率过高,导致进入“低水位”状态时,处理方法同上,依然采用低水位门限控制方案。
(3)当缓冲区由于消耗过慢,或者填充过快,导致进入“高水位”状态时,则采用“高水位门限控制方案”,即若消费者消耗的速率为Vo,生产者则以速率Vo的1/n倍(例如1/2倍)来填充缓冲区,直到水位降到50%时,再回到消费的速率Vo来填充缓冲区。
请思考:为什么要在50%处才将恢复原速率?
在此,为了方便理解,形象地用下面这张图来描述上面的管理策略之“低水位门限控制方案”:
4. 其他说明
下面就几个可能的疑问做出一些解释。(1) 程序中如何实现速率控制,比如读取文件数据的速率?
一般生产者要自动生产数据是靠线程实现的,而在线程中读取文件并且填充缓冲区一般是靠定时器来实现的(当然,也可以使用Sleep的方式)。这样一来,其实有两种控制速率的方案,一种是通过改变填充缓冲区的定时器的定时时间间隔来实现速率的控制,另外一种是改变每次读取和填充的字节数,来间接实现改变填充缓冲区的速率。
(2) 生产者和消费者同时访问缓冲区会有问题吗?
当然,缓冲区的访问肯定要使用加锁或者信号量这样的保护措施。
(3) 其他疑问欢迎大家提出来。
4. 小结
关于软件中的缓冲区管理策略就解释到这儿了,有任何疑问或者建议欢迎留言或者来信lujun.hust@gmail.com交流,或者关注我的新浪微博 @卢_俊 获取最新的文章和资讯。本文出自 “Jhuster的专栏” 博客,请务必保留此出处http://ticktick.blog.51cto.com/823160/273133

相关文章推荐
- Linux之父Linus Torvalds谈软件开发管理经验
- 5年以前开发一个消费场所会员管理软件的开发经验分享,小项目一般人折腾不起,靠小项目比较难创业成功
- 5年以前开发一个消费场所会员管理软件的开发经验分享,小项目一般人折腾不起,靠小项目比较难创业成功
- 5年以前开发一个消费场所会员管理软件的开发经验分享,小项目一般人折腾不起,靠小项目比较难创业成功
- Linus 谈软件开发管理经验(转载)
- 实战开发经验: 软件中的错误收集策略
- 实战开发经验: 软件系统设计思路
- Linux之父Linus Torvalds谈软件开发管理经验
- FoxPro在网络环境下开发数据库管理软件的一些经验
- Linus 谈软件开发管理经验
- 如何管理软件项目?22位专家实战经验分享
- Linux平台下基于BitTorrent应用层协议的下载软件开发--缓冲管理模块(data.c)
- 《scrum实战-敏捷软件项目管理与开发》读书笔记
- Linux平台下基于BitTorrent应用层协议的下载软件开发--缓冲管理模块(data.h)
- 5年以前开发一个消费场所会员管理软件的开发经验分享,小项目一般人折腾不起,靠小项目比较难创业成功
- Linus Torvalds谈软件开发管理经验
- Android实战开发租赁管理软件(适配UI,数据的存储,多线程下载)课程分享
- Linus Torvalds谈软件开发管理经验
- Android实战开发租赁管理软件视频教程 Android项目实战教程
- Linux之父Linus Torvalds谈软件开发管理经验