[原]由clob引发的性能问题所想到的(不是解决方案的方案)
2010-01-04 14:10
399 查看
前文再续,书接上一回,今天回到单位,终于可以在生产机器上进一步观察了,由于烂糟的设计,通过调整索引来提供性能是行不通了(也许是我的火候还不够),于是把最终目的定为减少可怕的 physical read 上,也就是把那堆clob缓存到内存中。
将clob缓冲的语句是:
把那个烂糟语句所用到的表的 clob 都缓冲进内存里。
做完之后,使用系统的人没有打电话上来,证明没有对业务系统造成冲击。我们对比一下调整前后的情况:
调整前:
可以看到 sdb 的 tps 和 kB_read/s,都很大,这个还不是峰值呢,有时我能观察到100MB/s的传输率,如果按照我们以前的测试数据来看,最高的传输率能到140MB/s左右,没剩多少I/O能力让这个oracle 折腾的啦
调整之后:
注意这个基本上就是峰值了,可以看到这次调整大大地减少了 physical read 所产生的负面影响。
我们再看看AWR的对比报告:

明显 physical read 降低 71%。而内存方面,Buffer Cache 抢走了Shared Poll 100M左右的内存,约3%的波动。

再看看等待事件方面的变化:

CPU Time方面略有所降,估计原因是CPU在等待数据块的过程中,闩自旋的时间变短了所造成的,但是这个效果不太明显,毕竟这次调整没有调整到Top SQL的执行计划。direct path read 大大降低,但是db file sequential read 和 db file scattered read的比率上升了,我估计是由于对这些clob的缓存冲击了db buffer cache所造成的,但总的来说,在IO方面的改善还是成效显著的。
将clob缓冲的语句是:
alter table table_name modify lob(lob_column) ( nocache ) ;
把那个烂糟语句所用到的表的 clob 都缓冲进内存里。
做完之后,使用系统的人没有打电话上来,证明没有对业务系统造成冲击。我们对比一下调整前后的情况:
调整前:
[root@rac1-node01 ~]# iostat -k 5 5 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 1.98 0.00 47.52 0 48 sda1 0.00 0.00 0.00 0 0 sda2 1.98 0.00 47.52 0 48 sdb 2727.72 43097.03 50.00 43528 50*** sdc 0.00 0.00 0.00 0 0 sdc1 0.00 0.00 0.00 0 0 sdd 0.00 0.00 0.00 0 0 sde 0.00 0.00 0.00 0 0 sde1 0.00 0.00 0.00 0 0 sdf 0.00 0.00 0.00 0 0 sdg 0.00 0.00 0.00 0 0 sdg1 0.00 0.00 0.00 0 0 sdh 0.00 0.00 0.00 0 0 sdi 0.00 0.00 0.00 0 0 sdi1 0.00 0.00 0.00 0 0 dm-0 11.88 0.00 47.52 0 48 dm-1 0.00 0.00 0.00 0 0 dm-2 0.00 0.00 0.00 0 0 emcpowera 2.97 0.99 0.50 1 0 emcpowera1 2.97 0.99 0.50 1 0 emcpowerb 0.00 0.00 0.00 0 0
可以看到 sdb 的 tps 和 kB_read/s,都很大,这个还不是峰值呢,有时我能观察到100MB/s的传输率,如果按照我们以前的测试数据来看,最高的传输率能到140MB/s左右,没剩多少I/O能力让这个oracle 折腾的啦
调整之后:
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 1.98 0.00 51.49 0 52 sda1 0.00 0.00 0.00 0 0 sda2 1.98 0.00 51.49 0 52 sdb 147.52 2273.27 6.93 2296 7*** sdc 0.00 0.00 0.00 0 0 sdc1 0.00 0.00 0.00 0 0 sdd 0.00 0.00 0.00 0 0 sde 0.00 0.00 0.00 0 0 sde1 0.00 0.00 0.00 0 0 sdf 0.00 0.00 0.00 0 0 sdg 0.00 0.00 0.00 0 0 sdg1 0.00 0.00 0.00 0 0 sdh 0.00 0.00 0.00 0 0 sdi 0.00 0.00 0.00 0 0 sdi1 0.00 0.00 0.00 0 0 dm-0 12.87 0.00 51.49 0 52 dm-1 0.00 0.00 0.00 0 0 dm-2 0.00 0.00 0.00 0 0 emcpowera 4.95 1.98 0.99 2 1 emcpowera1 4.95 1.98 0.99 2 1 emcpowerb 0.00 0.00 0.00 0 0
注意这个基本上就是峰值了,可以看到这次调整大大地减少了 physical read 所产生的负面影响。
我们再看看AWR的对比报告:
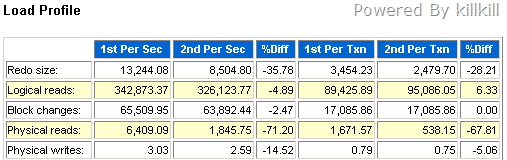
明显 physical read 降低 71%。而内存方面,Buffer Cache 抢走了Shared Poll 100M左右的内存,约3%的波动。

再看看等待事件方面的变化:
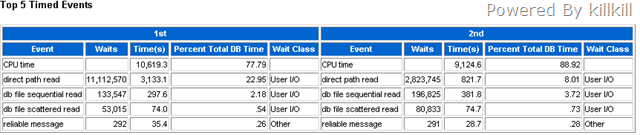
CPU Time方面略有所降,估计原因是CPU在等待数据块的过程中,闩自旋的时间变短了所造成的,但是这个效果不太明显,毕竟这次调整没有调整到Top SQL的执行计划。direct path read 大大降低,但是db file sequential read 和 db file scattered read的比率上升了,我估计是由于对这些clob的缓存冲击了db buffer cache所造成的,但总的来说,在IO方面的改善还是成效显著的。

相关文章推荐
- [原]由clob引发的性能问题所想到的
- 总结sublime c++编译环境搭建 | 中文乱码问题解决方案 |sidebar配置 |sublime最佳插件列表|最佳主题方案
- 千万级并发实现的秘密:内核不是解决方案,而是问题所在!
- “Visual Studio.net已检测到指定的Web服务器运行的不是Asp.net1.1版。您将无法运行Asp.net Web应用程序或服务”问题的解决方案
- cmos电池没电引发的电脑不能启动问题解决方案
- (转)Linux NUMA引发的性能问题
- 项目中 .net framework (v4.0 ->v3.5)降级引发的问题及解决方案
- 千万级并发实现的秘密:内核不是解决方案,而是问题所在!
- 致非技术开发者:先讨论问题,而不是解决方案
- 安装sql server 2005 遇到问题性能监视器计数器要求解决方案
- Spark性能优化的10大问题及其解决方案
- 千万级并发实现的秘密:内核不是解决方案,而是问题所在!
- MySQL 删除大表的性能问题解决方案
- Eclipse RCP 性能问题与解决方案
- 建议64:为循环增加Tester-Doer模式而不是将try-catch置于循环内 如果需要在循环中引发异常,你需要特别注意,应为抛出异常是一个相当影响性能的过程。应该尽量在循环当中对异常发生的一
- 一次误报引发的DNS检测方案的思考:DNS隧道检测平民解决方案
- redmine在linux上的mysql性能优化方法与问题排查方案
- SQL Server 2008 安装过程中遇到“性能计数器注册表配置单元一致性”检查失败 问题的解决方案
- 分布式部署下润乾报表调用、API调用、权限问题以及性能方案