CUDA学习之CUDA本质和原理-CUDA技术深入解析
2009-12-29 19:20
671 查看
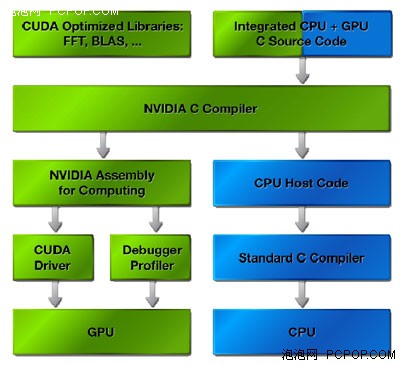
从NVIDIA官方网站上找的CUDA资料可以看出CUDA的实现流程如下图:

CUDA的实现流程
从图上我们可以看出CUDA在整个GPU计算中充当的就是翻译的角色,我们知道GPU的结构和CPU差别很大,GPU强调的是并行性重复性的计算工作,GPU因为结构和CPU不同,计算指令也不一样,而在GPU加速中,CUDA就是负责把CPU的计算指令翻译成GPU的计算指令,同时还负责显存和计算机系统内存中数据的交换操作.

我们可以形象的的把显卡也看成一台结构不一样的计算机,它以GPU为CPU,显存为内存,CUDA就负责把我们平常使用的CPU指令转换成这台显卡计算机所能接受的指令,并负责数据在这两台计算机之间的交换.而CUDA程序本身还是要靠CPU来执行的.

CUDA的计算流程
开发人员使用一种全新的编程模式将并行数据映射、安排到GPU中。CUDA程序则把要处理的数据细分成更小的区块,然后并行的执行它们。这种编程模式允许开发人员只需对GPU编程一次,无论是包含多处理器的GPU产品或是低成本、处理器数量较少的产品。当GPU计算程序运行的时候,开发者只是需要在主CPU上运行程序,CUDA驱动会自动在GPU上载入和执行程序。主机端程序可以通过高速的PCI Express总线与GPU进行信息交互。数据的传输、GPU运算功能的启动以及其它一些CPU 和GPU交互都可以通过调用专门的运行时驱动中的专门操作来完成。这些高级操作把程序员从手动管理GPU运算资源中解放出来。
编译过程
CUDA的核心部分是专门开发的C编译器。C语言对大多数开发人员都十分熟悉的,可以使编程人员专注于开发并行程序而不是处理负责的图形API。为了简化开发,CUDA的C编译器允许程序员将CPU 和 GPU的代码混合记录到一个程序文件中。一些简单代码被增加到的C程序中,通知CUDA编译器哪些函数由CPU处理,哪些为GPU编译。然后程序被CUDA编译器编译,而CPU处理的代码则由开发者的标准C编译器编。

PTX中间媒介语言
整个编译过程需要几个阶段。首先,所有的代码都要让CPU来处理,这些都会从文件中提取,并且他们都会通过标准的编译器。用于GPU处理的代码,首先要转换成中间媒介性语言——PTX。中间语言更像是一种汇编程序,并且能够中和潜在的无效代码。在最后的阶段,中间语言会转换成指令。这些指令会被GPU所认同,并且会以二进制的形式被执行。
NVIDIA CUDA技术基于一种全新的用于开拓GPU运算性能的软件架构,CUDA程序执行时,GPU作为主CPU的协处理器工作,GPU可以处理大量的并行信息,同时CPU组织、解释、与后台交流要处理的信息。应用程序的计算密集型部分要被执行很多次,每次由主应用程序提交的不同数据,经过编译后由GPU并行执行。

CUDA辅助CPU进行通用运算功能的示意图
CUDA可以用来生产资源,比如生成几何图形,在程序中进行材质贴图等等,同时这些也可以传递到传统的图形API来生成。3D图形API也可以将渲染后的结果发送到CUDA进行后续处理。CUDA本身就是基于图形芯片,而这种图形芯片也具备通用计算的能力。这里有许多交互性的例子,在GPU的显存中存储数据将更具优势,系统可以绕过速度相对较慢的PCI-Express总线,直接调用显存中的数据。
另一方面需要指出的是,针对这种在显存内的资源共享来说,图形数据并不总是短小精悍的,并且也会给程序员带来一些头痛的问题。例如,转换分辨率或者颜色深度时,图形数据就有优先权。因此,如果在缓冲中的资源需要增加的时候,驱动程序会毫不犹豫的将应用程序分配给CUDA来执行。这样CUDA计算和图形处理就不会产生冲突。对于数据的分配和管理,CUDA还有待于更进一步完善。尤其是当我们的系统中有几个GPU的时候,我们首先就无法使用SLI模式了,我们只能用一颗GPU来完成显示工作。不过这也是避免系统混乱的最好办法。
CUDA API其本质上来讲是由各种操作显存的函数组成的。cudaMalloc用来分配内存,cudaFree用来释放内存,cudaMemcpy用来互相拷贝内存和显存之间的数据。
名词解析
thread线程 在CUDA里定义thread线程的概念。因为这里所指的线程,与传统的“CPU线程”是有所区别的,同时也不是我们在GPU文章里所指的“线程”。在GPU中,线程是最基本的元素,它贯穿于数据处理的始终。与CPU中的线程不同,CUDA的线程是非常轻巧微小的,这就意味着,单独的线程处理起来会非常的简单快速。
warp 不要试图从字面理解warp的概念,因为它仅仅是一种象征性的比喻,一个由NVIDIA自创的术语罢了。NVIDIA的意思是CUDA的整个处理工作,就像是一架织布机,织物在织布机内快速的来回穿过。
在CUDA中的一个warp,是由32个线程组成的。这也是SIMD处理中,数据的最小封包单位。CUDA采用的是多处理并行架构,它的主旨就是尽量能并行处理更多的数据。
grid 栅格,将许多个block块封装起来。这种数据机制的优势就在于可以同时在GPU中处理多个block块。这种方式将GPU所有硬件资源都紧密的联系在一起。
从CUDA原理中得到的优化PC启示:
PhysX物理加速也是建立在CUDA技术之上的,CUDA运行时不但要占用CPU资源,还要在显卡的GPU和显存中划分出一定的资源来用做GUP计算如:物理加速,通用计算等.通过对CUDA的分析我们就不难理解为什么9500GT级别的显卡在开启物理加速以后为什么性能不升反降的原因.
随着,大量游戏对物理加速的支持和许多软件开始对GPU加速的支持,显卡将不单是图形处理,GPU的性能,流处理器的数量,和显存的大小将直接影响着使用者游戏和软件的运行速度.在新应用下我们选择显卡应该着重考虑以下几方面:
1.显卡的GPU性能,性能强大的GPU才能够更好的运行物理加速和CUDA通用计算,特别是在运行3D游戏时,GPU要同时负责图形加速和物理加速,对GPU性能有一定要求.
2.流处器的数量和频率,流处理器数目越多频率越高,并行计算能力越强
3.显存的大小和速度,大容量的高速显存在CUDA计算中能够在更短的时间内交换更多的数据,在3D游戏中也不会因为显存太小而影响性能.
NVIDIA推荐的CUDA和物理加速显示256M的9600GT以上的显卡,但是在目前来看,物理加速和CUDA要能够流畅运行的话,一块512M DDR3的9600GT是基本的要求,512M显存才有足够的显存空间给CUDA作为GPU计算内存使用.而如果显存只有256M,在CUDA计算量大的时候将直接影响性能,如果是3D游戏,图形处理也将受到影响.
CUDA的实现流程
从图上我们可以看出CUDA在整个GPU计算中充当的就是翻译的角色,我们知道GPU的结构和CPU差别很大,GPU强调的是并行性重复性的计算工作,GPU因为结构和CPU不同,计算指令也不一样,而在GPU加速中,CUDA就是负责把CPU的计算指令翻译成GPU的计算指令,同时还负责显存和计算机系统内存中数据的交换操作.
我们可以形象的的把显卡也看成一台结构不一样的计算机,它以GPU为CPU,显存为内存,CUDA就负责把我们平常使用的CPU指令转换成这台显卡计算机所能接受的指令,并负责数据在这两台计算机之间的交换.而CUDA程序本身还是要靠CPU来执行的.
CUDA的计算流程
开发人员使用一种全新的编程模式将并行数据映射、安排到GPU中。CUDA程序则把要处理的数据细分成更小的区块,然后并行的执行它们。这种编程模式允许开发人员只需对GPU编程一次,无论是包含多处理器的GPU产品或是低成本、处理器数量较少的产品。当GPU计算程序运行的时候,开发者只是需要在主CPU上运行程序,CUDA驱动会自动在GPU上载入和执行程序。主机端程序可以通过高速的PCI Express总线与GPU进行信息交互。数据的传输、GPU运算功能的启动以及其它一些CPU 和GPU交互都可以通过调用专门的运行时驱动中的专门操作来完成。这些高级操作把程序员从手动管理GPU运算资源中解放出来。
编译过程
CUDA的核心部分是专门开发的C编译器。C语言对大多数开发人员都十分熟悉的,可以使编程人员专注于开发并行程序而不是处理负责的图形API。为了简化开发,CUDA的C编译器允许程序员将CPU 和 GPU的代码混合记录到一个程序文件中。一些简单代码被增加到的C程序中,通知CUDA编译器哪些函数由CPU处理,哪些为GPU编译。然后程序被CUDA编译器编译,而CPU处理的代码则由开发者的标准C编译器编。
PTX中间媒介语言
整个编译过程需要几个阶段。首先,所有的代码都要让CPU来处理,这些都会从文件中提取,并且他们都会通过标准的编译器。用于GPU处理的代码,首先要转换成中间媒介性语言——PTX。中间语言更像是一种汇编程序,并且能够中和潜在的无效代码。在最后的阶段,中间语言会转换成指令。这些指令会被GPU所认同,并且会以二进制的形式被执行。
NVIDIA CUDA技术基于一种全新的用于开拓GPU运算性能的软件架构,CUDA程序执行时,GPU作为主CPU的协处理器工作,GPU可以处理大量的并行信息,同时CPU组织、解释、与后台交流要处理的信息。应用程序的计算密集型部分要被执行很多次,每次由主应用程序提交的不同数据,经过编译后由GPU并行执行。
CUDA辅助CPU进行通用运算功能的示意图
CUDA可以用来生产资源,比如生成几何图形,在程序中进行材质贴图等等,同时这些也可以传递到传统的图形API来生成。3D图形API也可以将渲染后的结果发送到CUDA进行后续处理。CUDA本身就是基于图形芯片,而这种图形芯片也具备通用计算的能力。这里有许多交互性的例子,在GPU的显存中存储数据将更具优势,系统可以绕过速度相对较慢的PCI-Express总线,直接调用显存中的数据。
另一方面需要指出的是,针对这种在显存内的资源共享来说,图形数据并不总是短小精悍的,并且也会给程序员带来一些头痛的问题。例如,转换分辨率或者颜色深度时,图形数据就有优先权。因此,如果在缓冲中的资源需要增加的时候,驱动程序会毫不犹豫的将应用程序分配给CUDA来执行。这样CUDA计算和图形处理就不会产生冲突。对于数据的分配和管理,CUDA还有待于更进一步完善。尤其是当我们的系统中有几个GPU的时候,我们首先就无法使用SLI模式了,我们只能用一颗GPU来完成显示工作。不过这也是避免系统混乱的最好办法。
CUDA API其本质上来讲是由各种操作显存的函数组成的。cudaMalloc用来分配内存,cudaFree用来释放内存,cudaMemcpy用来互相拷贝内存和显存之间的数据。
名词解析
thread线程 在CUDA里定义thread线程的概念。因为这里所指的线程,与传统的“CPU线程”是有所区别的,同时也不是我们在GPU文章里所指的“线程”。在GPU中,线程是最基本的元素,它贯穿于数据处理的始终。与CPU中的线程不同,CUDA的线程是非常轻巧微小的,这就意味着,单独的线程处理起来会非常的简单快速。
warp 不要试图从字面理解warp的概念,因为它仅仅是一种象征性的比喻,一个由NVIDIA自创的术语罢了。NVIDIA的意思是CUDA的整个处理工作,就像是一架织布机,织物在织布机内快速的来回穿过。
在CUDA中的一个warp,是由32个线程组成的。这也是SIMD处理中,数据的最小封包单位。CUDA采用的是多处理并行架构,它的主旨就是尽量能并行处理更多的数据。
grid 栅格,将许多个block块封装起来。这种数据机制的优势就在于可以同时在GPU中处理多个block块。这种方式将GPU所有硬件资源都紧密的联系在一起。
从CUDA原理中得到的优化PC启示:
PhysX物理加速也是建立在CUDA技术之上的,CUDA运行时不但要占用CPU资源,还要在显卡的GPU和显存中划分出一定的资源来用做GUP计算如:物理加速,通用计算等.通过对CUDA的分析我们就不难理解为什么9500GT级别的显卡在开启物理加速以后为什么性能不升反降的原因.
随着,大量游戏对物理加速的支持和许多软件开始对GPU加速的支持,显卡将不单是图形处理,GPU的性能,流处理器的数量,和显存的大小将直接影响着使用者游戏和软件的运行速度.在新应用下我们选择显卡应该着重考虑以下几方面:
1.显卡的GPU性能,性能强大的GPU才能够更好的运行物理加速和CUDA通用计算,特别是在运行3D游戏时,GPU要同时负责图形加速和物理加速,对GPU性能有一定要求.
2.流处器的数量和频率,流处理器数目越多频率越高,并行计算能力越强
3.显存的大小和速度,大容量的高速显存在CUDA计算中能够在更短的时间内交换更多的数据,在3D游戏中也不会因为显存太小而影响性能.
NVIDIA推荐的CUDA和物理加速显示256M的9600GT以上的显卡,但是在目前来看,物理加速和CUDA要能够流畅运行的话,一块512M DDR3的9600GT是基本的要求,512M显存才有足够的显存空间给CUDA作为GPU计算内存使用.而如果显存只有256M,在CUDA计算量大的时候将直接影响性能,如果是3D游戏,图形处理也将受到影响.

相关文章推荐
- Spring技术内幕——深入解析Spring架构与设计原理(四)Web MVC的实现
- 《Spring技术内幕——深入解析Spring架构与设计原理》连载2
- 一起谈.NET技术,DataTable 深入解析数据源绑定原理之高级篇
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- Spring技术内幕——深入解析Spring架构与设计原理(五)Spring与远端调用
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- Spring技术内幕——深入解析Spring架构与设计原理(二)AOP
- 读书笔记--Spring技术内幕深入解析Spring架构与设计原理--Spring源码的编译(一)
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- Spring技术内幕——深入解析Spring架构与设计原理收藏
- Spring技术内幕——深入解析Spring架构与设计原理(二)AOP
- 《Spring技术内幕——深入解析Spring架构与设计原理》连载4
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- 深入学习----Servlet工作原理解析
- 同一个ip通一个80端口部署多个网站的原理-虚拟主机技术本质解析
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
- Spring技术内幕——深入解析Spring架构与设计原理(六)Spring ACEGI
- 【读过的书,留下的迹】Spring技术内幕——深入解析Spring架构与设计原理