Spring.net整合Lucene.net 实现全文检索(附例程)
2009-11-09 21:53
585 查看
什么是Lucene.net?
引用wikipedia上的介绍:“Lucene是一套用于全文检索和搜尋的開放源碼程式庫,由Apache软件基金会支持和提供。Lucene提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜尋...”
而Lucene.net便是Lucene在dot net平台上的移植版本。关于Lucene的一些概念,有兴趣的朋友可以参考这里。
要实现Spring.net与Lucene.net的整合,关键点在于:
1、查询时,使用Spring.net集成的nHibernate来管理Lucene.net使用的Session;
2、对数据实体的CRUD进行事件监控,以便动态更新索引
经过一番尝试,决定将原有的框架进行升级——spring.net 1.2.0 + nHibernaet 2.0.1 + Lucene.net 2.0 + nHibernate.Search。
ok,看看都需要进行哪些调整:
一、实体生成模板加上索引
在model层引用nHibernate.Search程序集,它的作用是根据实体上的元标记,选择是否为实体开启存储空间,以及索引的字段范围。
修改codeSmith中的nHibernate Template,像这样,用以将主键和字符型字段进行索引:
/**//// <summary>
IList FullTextSearch(string query)#region IList<T> FullTextSearch<T>(string query)
public IList<T> FullTextSearch<T>(string query)
{
//生成字段列表
object objTarget = Assembly.GetAssembly(typeof(T)).CreateInstance(typeof(T).ToString());
PropertyInfo[] pps = objTarget.GetType().GetProperties();
string fs = "";
foreach(PropertyInfo p in pps)
{
var fieldAttr = p.GetCustomAttributes
(typeof(FieldAttribute),false);
if (fieldAttr!=null && fieldAttr.Length>0)
{
fs += p.Name + ",";
}
}
string[] fields = fs.TrimEnd(',').Split(',');
//中文拆词
ChineseAnalyzer cnAnalyzer = new ChineseAnalyzer();
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, cnAnalyzer);
Query queryObj;
try
{
queryObj = parser.Parse(query);
}
catch (ParseException)
{
return null;
}
//使用当前Session
IFullTextSession fullTextSession = NHibernate.Search.Search.CreateFullTextSession(Session);
IQuery nhQuery = fullTextSession.CreateFullTextQuery(queryObj, typeof(T));
//结果
IList<T> results = nhQuery.List<T>();
return results;
}
#endregion
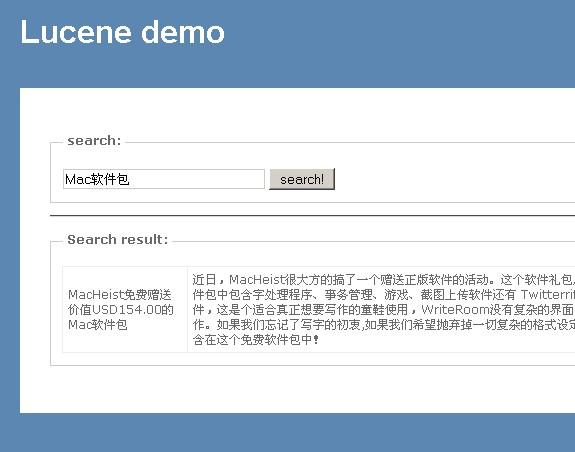
四、运行一下
Insert对象:

Search:
随笔写得很粗糙,大部分细节在附件的例程包中(包括数据库备份,模板,项目文件),如果有兴趣,还是参考实例吧:
lucenedemo.rar
引用wikipedia上的介绍:“Lucene是一套用于全文检索和搜尋的開放源碼程式庫,由Apache软件基金会支持和提供。Lucene提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜尋...”
而Lucene.net便是Lucene在dot net平台上的移植版本。关于Lucene的一些概念,有兴趣的朋友可以参考这里。
要实现Spring.net与Lucene.net的整合,关键点在于:
1、查询时,使用Spring.net集成的nHibernate来管理Lucene.net使用的Session;
2、对数据实体的CRUD进行事件监控,以便动态更新索引
经过一番尝试,决定将原有的框架进行升级——spring.net 1.2.0 + nHibernaet 2.0.1 + Lucene.net 2.0 + nHibernate.Search。
ok,看看都需要进行哪些调整:
一、实体生成模板加上索引
在model层引用nHibernate.Search程序集,它的作用是根据实体上的元标记,选择是否为实体开启存储空间,以及索引的字段范围。
修改codeSmith中的nHibernate Template,像这样,用以将主键和字符型字段进行索引:
/**//// <summary>
IList FullTextSearch(string query)#region IList<T> FullTextSearch<T>(string query)
public IList<T> FullTextSearch<T>(string query)
{
//生成字段列表
object objTarget = Assembly.GetAssembly(typeof(T)).CreateInstance(typeof(T).ToString());
PropertyInfo[] pps = objTarget.GetType().GetProperties();
string fs = "";
foreach(PropertyInfo p in pps)
{
var fieldAttr = p.GetCustomAttributes
(typeof(FieldAttribute),false);
if (fieldAttr!=null && fieldAttr.Length>0)
{
fs += p.Name + ",";
}
}
string[] fields = fs.TrimEnd(',').Split(',');
//中文拆词
ChineseAnalyzer cnAnalyzer = new ChineseAnalyzer();
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, cnAnalyzer);
Query queryObj;
try
{
queryObj = parser.Parse(query);
}
catch (ParseException)
{
return null;
}
//使用当前Session
IFullTextSession fullTextSession = NHibernate.Search.Search.CreateFullTextSession(Session);
IQuery nhQuery = fullTextSession.CreateFullTextQuery(queryObj, typeof(T));
//结果
IList<T> results = nhQuery.List<T>();
return results;
}
#endregion
四、运行一下
Insert对象:
Search:
随笔写得很粗糙,大部分细节在附件的例程包中(包括数据库备份,模板,项目文件),如果有兴趣,还是参考实例吧:
lucenedemo.rar

相关文章推荐
- Spring.net整合Lucene.net 实现全文检索(附例程)转载
- 使用Lucene.Net实现全文检索
- 火力全开——仿造Baidu简单实现基于Lucene.net的全文检索的功能
- 使用Lucene.Net实现全文检索
- 使用Lucene.Net实现全文检索
- 火力全开——仿造Baidu简单实现基于Lucene.net的全文检索的功能
- 使用Lucene.Net实现全文检索
- 仿造百度实现基于Lucene.net全文检索
- 使用Lucene.Net实现全文检索
- 仿造Baidu简单实现基于Lucene.net的全文检索的功能
- 站内搜索------仿造Baidu简单实现基于Lucene.net的全文检索的功能
- Lucene.net 实现全文检索
- 火力全开——仿造Baidu简单实现基于Lucene.net的全文检索的功能
- ]NET Core Lucene.net和PanGu分词实现全文检索
- 仿造Baidu简单实现基于Lucene.net的全文检索的功能
- 使用Lucene对doc、docx、pdf、txt文档进行全文检索功能的实现
- 用PHP调用Lucene包来实现全文检索(转)
- Lucene.net 实现全文搜索
- Lucene .NET 全文检索
- lucene实现全文检索的示例代码