[转]聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
2009-11-06 10:47
471 查看
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引。
不过这个定义太抽象了。在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。如下图:
CREATE TABLE [dbo].[tabTest] (
[ID] [int] IDENTITY (1, 1) NOT NULL ,
[unqValue] [uniqueidentifier] NOT NULL ,
[intValue] [int] NOT NULL
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tabTest] WITH NOCHECK ADD
CONSTRAINT [PK_tabTest] PRIMARY KEY CLUSTERED
(
[ID]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tabTest] ADD
CONSTRAINT [DF_tabTest_unqValue] DEFAULT (newid()) FOR [unqValue]
GO
CREATE INDEX [IX_tabTest_unqValue] ON [dbo].[tabTest]([unqValue]) ON [PRIMARY]
GO
declare @i int
declare @v int
set @i=0
while @i<10000
begin
set @v=rand()*1000
insert into tabTest ([intValue]) values (@v)
set @i=@i+1
end
然后我们执行两个查询并查看执行计划,如图:(在查询分析器的查询菜单中可以打开查询计划,同时图上第一个查询的GUID是我从数据库中找的,大家做实验的时候可以根据自己数据库中的值来定):
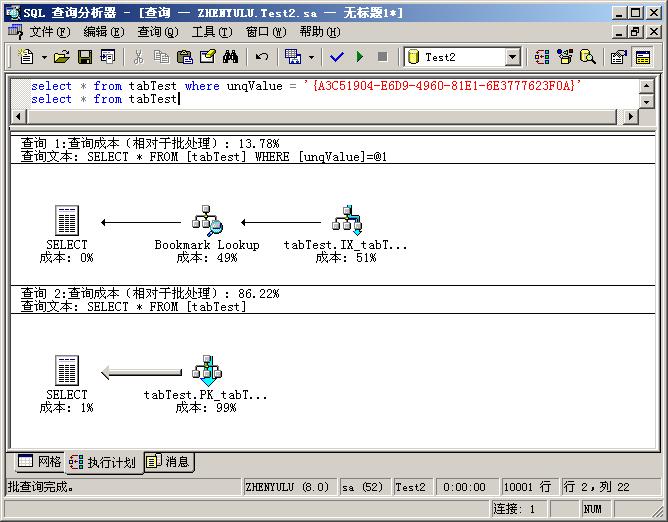
从图中可以看出,在第一个查询中,SQL Server使用了IX_tabTest_unqValue索引,根据箭头方向,计算机先在索引范围内找,找到后,使用Bookmark Lookup将索引节点映射到数据节点上,最后给出SELECT结果。在第二个查询中,系统直接遍历表给出结果,不过它使用了聚簇索引,为什么呢?不要忘了,聚簇索引的页节点就是数据节点!这样使用聚簇索引会更快一些(不受数据删除、更新留下的存储空洞的影响,直接遍历数据是要跳过这些空洞的)。
下面,我们在SQL Server中将ID字段的聚簇索引更改为非聚簇索引,然后再执行select * from tabTest,这回我们看到的执行计划变成了:

SQL Server没有使用任何索引,而是直接执行了Table Scan,因为只有这样,检索效率才是最高的。
三、聚簇索引与非聚簇索引的本质区别
现在可以讨论聚簇索引与非聚簇索引的本质区别了。正如本文最前面的两个图所示,聚簇索引的叶节点就是数据节点,而非聚簇索引的页节点仍然是索引检点,并保留一个链接指向对应数据块。
还是通过一道数学题来看看它们的区别吧:假设有一8000条记录的表,表中每条记录在磁盘上占用1000字节,如果在一个10字节长的字段上建立非聚簇索引主键,需要二叉树节点16000个(这16000个节点中有8000个叶节点,每个页节点都指向一个数据记录),这样数据将占用8000条×1000字节/8K字节=1000个页面;索引将占用16000个节点×10字节/8K字节=20个页面,共计1020个页面。
同样一张表,如果我们在对应字段上建立聚簇索引主键,由于聚簇索引的页节点就是数据节点,所以索引节点仅有8000个,占用10个页面,数据仍然占有1000个页面。
下面我们看看在执行插入操作时,非聚簇索引的主键为什么比聚簇索引主键要快。主键约束要求主键不能出现重复,那么SQL Server是怎么知道不出现重复的呢?唯一的方法就是检索。对于非聚簇索引,只需要检索20个页面中的16000个节点就知道是否有重复,因为所有主键键值在这16000个索引节点中都包含了。但对于聚簇索引,索引节点仅仅包含了8000个中间节点,至于会不会出现重复必须检索另外1000个页数据节点才知道,那么相当于检索10+1000=1010个页面才知道是否有重复。所以聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多。
让我们再来看看数据检索的效率,如果对上述两表进行检索,在使用索引的情况下(有些时候SQL Server执行计划会选择不使用索引,不过我们这里姑且假设一定使用索引),对于聚簇索引检索,我们可能会访问10个索引页面外加1000个数据页面得到结果(实际情况要比这个好),而对于非聚簇索引,系统会从20个页面中找到符合条件的节点,再映射到1000个数据页面上(这也是最糟糕的情况),比较一下,一个访问了1010个页面而另一个访问了1020个页面,可见检索效率差异并不是很大。所以不管非聚簇索引也好还是聚簇索引也好,都适合排序,聚簇索引仅仅比非聚簇索引快一点。
结语
好了,写了半天,手都累了。关于聚簇索引与非聚簇索引效率问题的实验就不做了,感兴趣的话可以自己使用查询分析器对查询计划进行分析。SQL Server是一个很复杂的系统,尤其是索引以及查询优化技术,Oracle就更复杂了。了解索引以及查询背后的事情不是什么坏事,它可以帮助我们更为深刻的了解我们的系统。
转自:http://www.cnblogs.com/zhenyulu/articles/25794.html
不过这个定义太抽象了。在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。如下图:
CREATE TABLE [dbo].[tabTest] (
[ID] [int] IDENTITY (1, 1) NOT NULL ,
[unqValue] [uniqueidentifier] NOT NULL ,
[intValue] [int] NOT NULL
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tabTest] WITH NOCHECK ADD
CONSTRAINT [PK_tabTest] PRIMARY KEY CLUSTERED
(
[ID]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tabTest] ADD
CONSTRAINT [DF_tabTest_unqValue] DEFAULT (newid()) FOR [unqValue]
GO
CREATE INDEX [IX_tabTest_unqValue] ON [dbo].[tabTest]([unqValue]) ON [PRIMARY]
GO
declare @i int
declare @v int
set @i=0
while @i<10000
begin
set @v=rand()*1000
insert into tabTest ([intValue]) values (@v)
set @i=@i+1
end
然后我们执行两个查询并查看执行计划,如图:(在查询分析器的查询菜单中可以打开查询计划,同时图上第一个查询的GUID是我从数据库中找的,大家做实验的时候可以根据自己数据库中的值来定):
从图中可以看出,在第一个查询中,SQL Server使用了IX_tabTest_unqValue索引,根据箭头方向,计算机先在索引范围内找,找到后,使用Bookmark Lookup将索引节点映射到数据节点上,最后给出SELECT结果。在第二个查询中,系统直接遍历表给出结果,不过它使用了聚簇索引,为什么呢?不要忘了,聚簇索引的页节点就是数据节点!这样使用聚簇索引会更快一些(不受数据删除、更新留下的存储空洞的影响,直接遍历数据是要跳过这些空洞的)。
下面,我们在SQL Server中将ID字段的聚簇索引更改为非聚簇索引,然后再执行select * from tabTest,这回我们看到的执行计划变成了:
SQL Server没有使用任何索引,而是直接执行了Table Scan,因为只有这样,检索效率才是最高的。
三、聚簇索引与非聚簇索引的本质区别
现在可以讨论聚簇索引与非聚簇索引的本质区别了。正如本文最前面的两个图所示,聚簇索引的叶节点就是数据节点,而非聚簇索引的页节点仍然是索引检点,并保留一个链接指向对应数据块。
还是通过一道数学题来看看它们的区别吧:假设有一8000条记录的表,表中每条记录在磁盘上占用1000字节,如果在一个10字节长的字段上建立非聚簇索引主键,需要二叉树节点16000个(这16000个节点中有8000个叶节点,每个页节点都指向一个数据记录),这样数据将占用8000条×1000字节/8K字节=1000个页面;索引将占用16000个节点×10字节/8K字节=20个页面,共计1020个页面。
同样一张表,如果我们在对应字段上建立聚簇索引主键,由于聚簇索引的页节点就是数据节点,所以索引节点仅有8000个,占用10个页面,数据仍然占有1000个页面。
下面我们看看在执行插入操作时,非聚簇索引的主键为什么比聚簇索引主键要快。主键约束要求主键不能出现重复,那么SQL Server是怎么知道不出现重复的呢?唯一的方法就是检索。对于非聚簇索引,只需要检索20个页面中的16000个节点就知道是否有重复,因为所有主键键值在这16000个索引节点中都包含了。但对于聚簇索引,索引节点仅仅包含了8000个中间节点,至于会不会出现重复必须检索另外1000个页数据节点才知道,那么相当于检索10+1000=1010个页面才知道是否有重复。所以聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多。
让我们再来看看数据检索的效率,如果对上述两表进行检索,在使用索引的情况下(有些时候SQL Server执行计划会选择不使用索引,不过我们这里姑且假设一定使用索引),对于聚簇索引检索,我们可能会访问10个索引页面外加1000个数据页面得到结果(实际情况要比这个好),而对于非聚簇索引,系统会从20个页面中找到符合条件的节点,再映射到1000个数据页面上(这也是最糟糕的情况),比较一下,一个访问了1010个页面而另一个访问了1020个页面,可见检索效率差异并不是很大。所以不管非聚簇索引也好还是聚簇索引也好,都适合排序,聚簇索引仅仅比非聚簇索引快一点。
结语
好了,写了半天,手都累了。关于聚簇索引与非聚簇索引效率问题的实验就不做了,感兴趣的话可以自己使用查询分析器对查询计划进行分析。SQL Server是一个很复杂的系统,尤其是索引以及查询优化技术,Oracle就更复杂了。了解索引以及查询背后的事情不是什么坏事,它可以帮助我们更为深刻的了解我们的系统。
转自:http://www.cnblogs.com/zhenyulu/articles/25794.html

相关文章推荐
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术(转)
- (转)聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术(转)
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术(评论很精彩)
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- (收藏)聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术(转)
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术
- 聚簇索引与非聚簇索引的区别以及SQL Server查询优化技术